Il database è una parte critica e vitale di qualsiasi azienda o organizzazione. Le tendenze in crescita prevedono che l'82% delle imprese prevede un aumento del numero di database nei prossimi 12 mesi. Una delle principali sfide di ogni DBA è scoprire come affrontare la massiccia crescita dei dati e questo sarà un obiettivo molto importante. Come puoi aumentare le prestazioni del database, ridurre i costi ed eliminare i tempi di inattività per offrire ai tuoi utenti la migliore esperienza possibile? La compressione dei dati è un'opzione? Iniziamo e vediamo come alcune delle funzionalità esistenti possono essere utili per gestire tali situazioni.
In questo articolo, impareremo come la soluzione di compressione dei dati può aiutarci a ottimizzare la soluzione di gestione dei dati. In questa guida tratteremo i seguenti argomenti:
- Una panoramica della compressione
- Vantaggi della compressione
- Uno schema sui dati sono le tecniche di compressione
- Discussione di vari tipi di compressione dei dati
- Fatti sulla compressione dei dati
- Considerazioni sull'implementazione
- e altro...
Compressione
La compressione è una tecnica e, quindi, un'operazione sensibile alle risorse, ma con compromessi hardware. Bisogna pensare di implementare la compressione dei dati per i seguenti vantaggi:
- Gestione efficace dello spazio
- Tecnica efficiente di riduzione dei costi
- Facilità di gestione del backup del database
- Utilizzo effettivo della larghezza di banda N/W
- Recupero o ripristino sicuro e più rapido
- Prestazioni migliori:riduce l'ingombro di memoria del sistema
Nota: Se SQL Server è limitato dalla CPU o dalla memoria, la compressione potrebbe non essere adatta al tuo ambiente.
La compressione dei dati si applica a:
- Un mucchio
- Indici raggruppati
- Indici non cluster
- Partizioni
- Viste indicizzate
Nota: Gli oggetti di grandi dimensioni non vengono compressi (ad esempio, LOB e BLOB)
Particolarmente adatto per le seguenti applicazioni:
- Tabelle log
- Tabelle di controllo
- Tabelle dei fatti
- Segnalazione
Introduzione
La compressione dei dati è una tecnologia in uso da SQL Server 2008. L'idea della compressione dei dati è che puoi scegliere selettivamente tabelle, indici o partizioni all'interno di un database. L'I/O continua a rappresentare un collo di bottiglia nello spostamento delle informazioni tra l'interno e l'esterno del database. La compressione dei dati sfrutta questo tipo e aiuta ad aumentare l'efficienza di un database. Poiché sappiamo che le velocità della rete sono molto più lente della velocità di elaborazione, è possibile ottenere guadagni di efficienza utilizzando la potenza di elaborazione per comprimere i dati in un database, in modo che viaggi più velocemente. E poi usa di nuovo la potenza di elaborazione per decomprimere i dati dall'altra parte. In generale, la compressione dei dati riduce lo spazio occupato dai dati. La tecnica di compressione dei dati è disponibile per ogni database ed è supportata da tutte le edizioni di SQL Server 2016 SP1. In precedenza, era disponibile solo nelle edizioni SQL Server Enterprise o Developer, non in Standard o Express.
Supporto per le funzionalità

Tipi di compressione dei dati
Sono disponibili due tipi di compressione dei dati in SQL Server, a livello di riga ea livello di pagina.
La compressione a livello di riga funziona dietro le quinte e converte qualsiasi tipo di dati a lunghezza fissa in tipi a lunghezza variabile. Il presupposto qui è che spesso i dati sono archiviati a un tipo di lunghezza fissa, come char 100, e in realtà non riempiono tutti i 100 caratteri per ogni record. Piccoli guadagni possono essere ottenuti rimuovendo questo spazio extra dal tavolo. Ovviamente, se le tue tabelle di dati non utilizzano testo a lunghezza fissa e campi numerici, o se lo fanno e memorizzi effettivamente il numero di caratteri e cifre completamente consentito, i guadagni di compressione con lo schema a livello di riga saranno minimi al massimo.
Il concetto di compressione è esteso a tutti i tipi di dati a lunghezza fissa, inclusi char, int e float. SQL Server consente di risparmiare spazio archiviando i dati come se fosse un tipo di dimensioni variabili; i dati appariranno e si comporteranno come una lunghezza fissa.
Ad esempio, se hai memorizzato il valore di 100 in un int colonna, SQL Server non deve utilizzare tutti i 32 bit, ma utilizza semplicemente 8 bit (1 byte).
La compressione a livello di pagina porta le cose a un altro livello. Innanzitutto, applica automaticamente la compressione a livello di riga sui campi di dati a lunghezza fissa, in modo da ottenere automaticamente quei guadagni per impostazione predefinita. Inoltre, applica qualcosa chiamato compressione del prefisso e un'altra tecnica chiamata compressione del dizionario.
Compressione di riga
La compressione di riga è un livello interno di compressione che memorizza le stringhe di caratteri fisse utilizzando il formato a lunghezza variabile senza memorizzare i caratteri vuoti. I seguenti passaggi vengono eseguiti nella compressione a livello di riga.
- Tutti i tipi di dati numerici come int , galleggiante , decimale, e denaro vengono convertiti in tipi di dati a lunghezza variabile. Ad esempio, 125 archiviato nella colonna e il tipo di dati della colonna è un numero intero. Quindi sappiamo che 4 byte vengono utilizzati per memorizzare il valore intero. Ma 125 può essere memorizzato in 1 byte perché 1 byte può memorizzare valori da 0 a 255. Quindi, 125 può essere memorizzato come un minuscolo int , in modo tale da poter salvare 3 byte.
- Caro e Nchar i tipi di dati vengono memorizzati come tipi di dati a lunghezza variabile. Ad esempio, "SQL" è archiviato in un char (20) tipo di colonna. Ma dopo la compressione, verranno utilizzati solo 3 byte. Dopo la compressione dei dati, nessun carattere vuoto viene memorizzato con questo tipo di dati.
- I metadati del record sono ridotti.
- I valori NULL e 0 sono ottimizzati e non viene consumato spazio.
Compressione della pagina
La compressione della pagina è un livello avanzato di compressione dei dati. Per impostazione predefinita, una compressione di pagina implementa anche la compressione a livello di riga. La compressione della pagina è classificata in due tipi
- Prefisso compressione e
- Compressione dizionario.
Compressione del prefisso
Nella compressione del prefisso per ogni pagina, per ogni colonna della pagina, un valore comune viene recuperato da tutte le righe e memorizzato sotto l'intestazione in ciascuna colonna. Ora in ogni riga viene memorizzato un riferimento a quel valore invece del valore comune.
Compressione del dizionario
La compressione del dizionario è simile alla compressione del prefisso, ma i valori comuni vengono recuperati da tutte le colonne e archiviati nella seconda riga dopo l'intestazione. La compressione del dizionario cerca le corrispondenze esatte dei valori in tutte le colonne e le righe di ogni pagina.
Possiamo eseguire la compressione a livello di riga e pagina per i seguenti oggetti di database.
- Una tabella archiviata in un heap.
- Un'intera tabella archiviata come indice cluster.
- Vista indicizzata.
- Indice non cluster.
- Indici e tabelle partizionati.
Nota: Possiamo eseguire la compressione dei dati sia al momento della creazione come CREATE TABLE, CREATE INDEX o dopo la creazione utilizzando il comando ALTER con opzione REBUILD come ALTER TABLE …. RICOSTRUI CON.
Dimostrazione
Gli WideWorldImporters il database viene utilizzato durante l'intera demo. Inoltre, un DW in tempo reale database viene considerato per l'operazione di compressione.
Esaminiamo i passaggi in dettaglio:
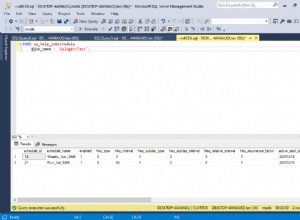
1. Per visualizzare le impostazioni di compressione per gli oggetti nel database, eseguire il seguente T-SQL:
USE WideWorldImporters; GO SELECT S.name AS SchemaName, O.name AS ObjectName, I.name AS IndexName, I.type_desc AS IndexType, P.data_compression_desc AS Compression FROM sys.schemas AS S JOIN sys.objects AS O ON S.schema_id = O.schema_id JOIN sys.indexes AS I ON O.object_id = I.object_id JOIN sys.partitions AS P ON I.object_id = P.object_id AND I.index_id = P.index_id WHERE O.TYPE = 'U' ORDER BY S.name, O.name, I.index_id; GO
L'output seguente mostra il tipo di compressione come PAGE, ROW e per diverse tabelle è NONE. Ciò significa che non è configurato per la compressione.
2. Per stimare la compressione, eseguire la seguente procedura memorizzata di sistema sp_stimate_data_compression_savings . In questo caso, la procedura memorizzata viene eseguita sulle tabelle PurchaseOrderLines.
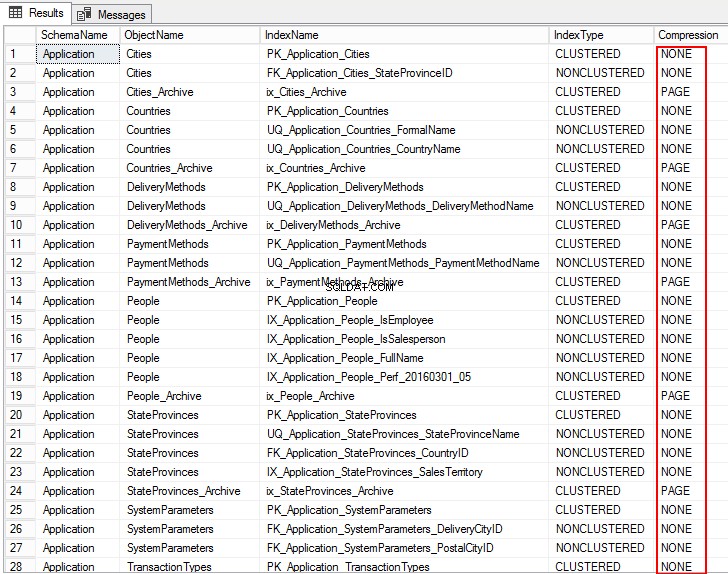
3. Scopriamo l'impostazione di compressione PurchaseOrderLines eseguendo il seguente T-SQL:
USE WideWorldImporters; GO SELECT S.name AS SchemaName, O.name AS ObjectName, I.name AS IndexName, I.type_desc AS IndexType, P.data_compression_desc AS Compression FROM sys.schemas AS S JOIN sys.objects AS O ON S.schema_id = O.schema_id JOIN sys.indexes AS I ON O.object_id = I.object_id JOIN sys.partitions AS P ON I.object_id = P.object_id AND I.index_id = P.index_id WHERE O.TYPE = 'U' and o.name ='PurchaseOrderLines' ORDER BY S.name, O.name, I.index_id;
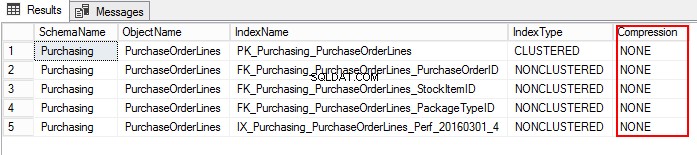
EXEC sp_estimate_data_compression_savings @schema_name = 'Purchasing', @object_name = 'PurchaseOrderLines', @index_id = NULL, @partition_number = NULL, @data_compression = 'Page'; GO

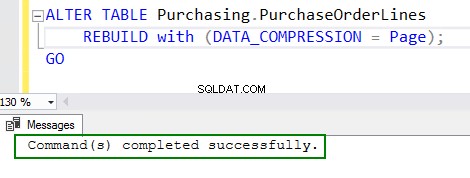
4. Abilita la compressione eseguendo il comando ALTER table:
ALTER TABLE Purchasing.PurchaseOrderLines REBUILD with (DATA_COMPRESSION = Page); GO
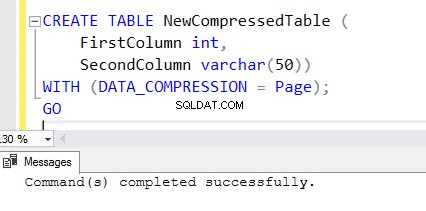
5. Per creare una nuova tabella con la funzione di compressione abilitata, aggiungere la clausola WITH alla fine dell'istruzione CREATE TABLE. Puoi vedere l'istruzione CREATE TABLE di seguito utilizzata per creare NewCompressedTable .
CREATE TABLE NewCompressedTable (
FirstColumn int,
SecondColumn varchar(50))
WITH (DATA_COMPRESSION = Page);
GO
Fatti sulla compressione dei dati
Esaminiamo alcune delle informazioni effettive sulla compressione
- La compressione non può essere applicata alle tabelle di sistema
- Non è possibile abilitare una tabella per la compressione quando la dimensione della riga supera 8060 byte.
- I dati compressi vengono memorizzati nella cache nel buffer pool; significa tempi di risposta più rapidi
- L'abilitazione della compressione può causare la modifica dei piani di query poiché i dati vengono archiviati utilizzando un numero diverso di pagine e un numero di righe per pagina.
- Gli indici non cluster non ereditano la proprietà di compressione
- Quando un indice cluster viene creato su un heap, l'indice cluster eredita lo stato di compressione dell'heap a meno che non venga specificato uno stato di compressione alternativo.
- Le compressioni a livello di RIGA e PAGINA possono essere abilitate e disabilitate, offline o online.
- Se l'impostazione dell'heap viene modificata, tutti gli indici non in cluster devono essere ricostruiti.
- I requisiti di spazio su disco per abilitare o disabilitare la compressione di righe o pagine sono gli stessi che per creare o ricostruire un indice.
- Quando le partizioni vengono suddivise utilizzando l'istruzione ALTER PARTITION, entrambe le partizioni ereditano l'attributo di compressione dei dati della partizione originale.
- Quando due partizioni vengono unite, la partizione risultante eredita l'attributo di compressione dei dati della partizione di destinazione.
- Per cambiare una partizione, la proprietà di compressione dei dati della partizione deve corrispondere alla proprietà di compressione della tabella.
- Le tabelle e gli indici del Columnstore vengono sempre archiviati con la compressione Columnstore.
- La compressione dei dati non è compatibile con le colonne sparse, quindi la tabella non può essere compressa.
Scenario in tempo reale
Esaminiamo la tecnica di compressione dei dati e comprendiamo i parametri chiave della compressione dei dati.
Per controllare lo spazio utilizzato da ciascuna tabella, eseguire il seguente T-SQL. L'output della query fornisce informazioni dettagliate sull'utilizzo di ciascuna tabella. Questo sarebbe il fattore decisivo per l'implementazione della compressione dei dati.
SELECT
t.NAME AS TableName,
i.name as indexName,
sum(p.rows) as RowCounts,
sum(a.total_pages) as TotalPages,
sum(a.used_pages) as UsedPages,
sum(a.data_pages) as DataPages,
(sum(a.total_pages) * 8) / 1024 as TotalSpaceMB,
(sum(a.used_pages) * 8) / 1024 as UsedSpaceMB,
(sum(a.data_pages) * 8) / 1024 as DataSpaceMB
FROM
sys.tables t
INNER JOIN
sys.indexes i ON t.OBJECT_ID = i.object_id
INNER JOIN
sys.partitions p ON i.object_id = p.OBJECT_ID AND i.index_id = p.index_id
INNER JOIN
sys.allocation_units a ON p.partition_id = a.container_id
WHERE
t.NAME NOT LIKE 'dt%' AND
i.OBJECT_ID > 255 AND
i.index_id <= 1
GROUP BY
t.NAME, i.object_id, i.index_id, i.name
ORDER BY
TotalSpaceMB desc
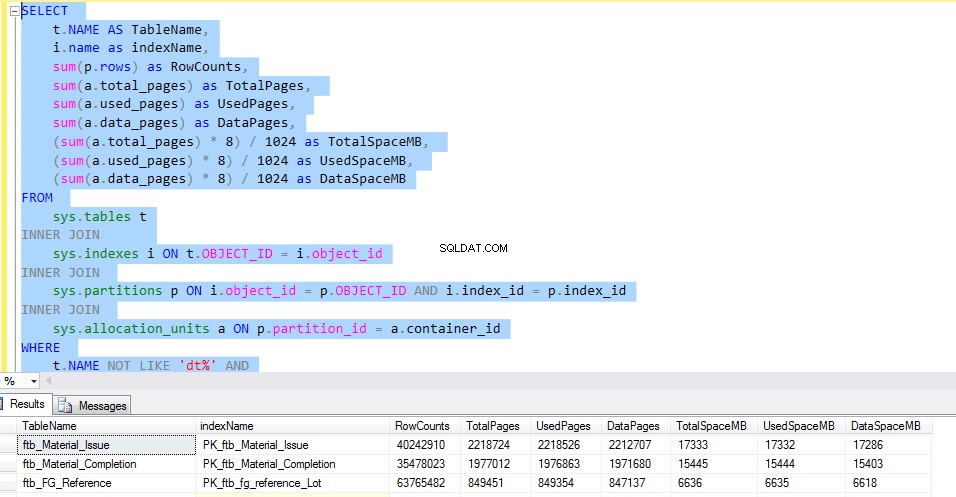
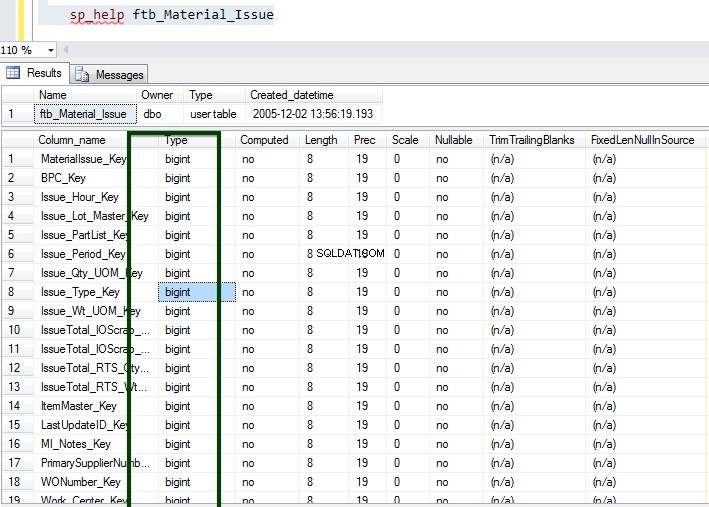
Consideriamo il ftb_material_Issue tabella dei fatti. La tabella dei fatti ha tipi di dati BIGINT numerici.
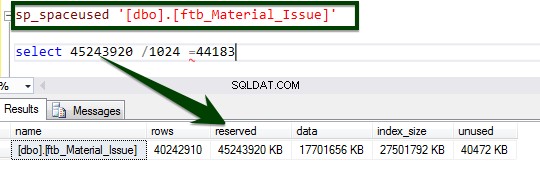
Ora, eseguire la stored procedure sp_spaceused per comprendere i dettagli della tabella. Puoi saperne di più sul comando sp_spaceused qui.
Abilita la compressione a livello di tabella eseguendo il seguente T-SQL. Il seguente T-SQL è stato eseguito sul server e ci sono voluti 34 minuti e 14 secondi per comprimere la pagina a livello di tabella.
ALTER TABLE dbo.ftb_material_Issue REBUILD with (DATA_COMPRESSION = Page);
È possibile visualizzare le fluttuazioni della CPU e degli I/O durante l'esecuzione del comando ALTER table.
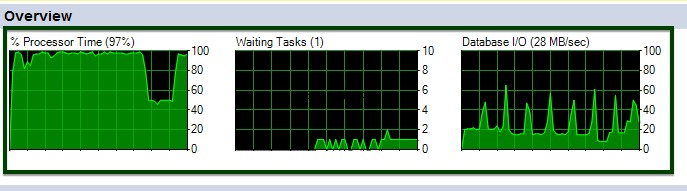
Ora, eseguiamo il confronto della compressione dei dati Before v/s After. La dimensione della tabella di circa ~45 GB viene ridotta a ~15 GB.
Il processo viene implementato sulla maggior parte degli oggetti utilizzando uno script automatizzato ed ecco il risultato finale del confronto.
Confronto dei dati tra Prima e Dopo l'operazione di compressione dell'indice.

Riepilogo
La compressione dei dati è una tecnica molto efficace per ridurre le dimensioni dei dati; dati ridotti richiedono meno processi di I/O. L'aggiunta di compressione al database aumenta il carico sui requisiti della CPU. Dovrai assicurarti di disporre della capacità di elaborazione disponibile per accogliere queste modifiche in modo efficiente. Quindi è meglio fare prima una piccola ricerca e vedere i tipi di guadagni che ci si possono aspettare prima di applicare le modifiche per abilitare la compressione dei dati. È molto vantaggioso nella configurazione del database cloud in cui sono coinvolti i costi.
Metti in scena le compressioni (non eseguirle tutte in una volta) e comprimi durante i periodi di bassa attività. La compressione dei dati e la compressione del backup coesistono bene e possono comportare un ulteriore risparmio di spazio di archiviazione, quindi vai avanti e divertiti.
La compressione non solo riduce le dimensioni dei file fisici, ma riduce anche l'I/O del disco, il che può migliorare notevolmente le prestazioni di molte applicazioni di database, insieme ai backup dei database.
Decidere di implementare la compressione è più facile se conosciamo l'infrastruttura sottostante e i requisiti aziendali. Possiamo sicuramente utilizzare la procedura di sistema disponibile per comprendere e stimare i risparmi di compressione. Questa procedura memorizzata non fornisce tali dettagli che indicano in che modo la compressione influirà positivamente o negativamente sul tuo sistema. È evidente che esistono compromessi con qualsiasi tipo di compressione. Se hai gli stessi modelli di dati enormi, la compressione è la chiave per risparmiare spazio. Con la potenza della CPU in aumento e ogni sistema legato a strutture multi-core, la compressione potrebbe adattarsi a molti sistemi. Consiglierei di testare i tuoi sistemi. Testare per assicurarsi che le prestazioni non siano influenzate negativamente. Se un indice ha molti aggiornamenti ed eliminazioni, il costo della CPU per comprimere e decomprimere i dati potrebbe superare i risparmi di I/O e RAM derivanti dalla compressione dei dati. Non tutti i database o le tabelle saranno automaticamente un buon candidato a cui applicare la compressione, quindi è meglio fare prima una piccola ricerca per vedere i tipi di guadagni che ci si possono aspettare prima di applicare le modifiche per abilitare la compressione dei dati sui database. Devi testare la compressione per vedere se funziona bene nel tuo ambiente, perché potrebbe non funzionare bene nei database con inserimento pesante.
Riferimenti
Edizioni e funzionalità supportate di SQL Server 2016
Compressione dei dati
Implementazione della compressione delle righe
Implementazione della compressione delle pagine