La replica del database è la tecnologia per distribuire i dati dal server primario ai server secondari. La replica funziona sul concetto Master-slave in cui il database Master distribuisce i dati a uno o più server slave. La replica può essere configurata tra più istanze di SQL Server sullo stesso server OPPURE può essere configurata tra più server di database all'interno di data center uguali o geograficamente separati.
L'utilizzo della replica di SQL Server presenta due vantaggi principali:
- Utilizzando la replica, possiamo ottenere dati quasi in tempo reale che possono essere utilizzati a scopo di reporting. Ad esempio, quando desideri separare il carico OLTP ad alta intensità di scrittura su un server e il carico ad alta intensità di lettura su un altro server, puoi configurare la replica per mantenere i dati sincronizzati su entrambi i server.
- Il secondo vantaggio è che puoi pianificare la replica in modo che venga eseguita a un'ora specifica. Ad esempio, se si desidera che il server di report contenga i dati del giorno completato, è possibile pianificare lo snapshot di replica di conseguenza. Non è necessario scrivere una logica aggiuntiva per gestire i dati correnti.
La replica offre molta flessibilità. Usando la replica, possiamo filtrare le righe e anche replicare il sottoinsieme di dati di qualsiasi tabella. Possiamo modificare i dati replicati o replicare solo aggiornare e inserire e ignorare le eliminazioni. Possiamo anche replicare i dati da un altro sistema di database come Oracle.
Componenti della replica
Esistono sette componenti principali di Replica di SQL Server. Di seguito l'elenco:
- Editore.
- Distributore.
- Abbonato.
- Articoli.
- Pubblicazione.
- Abbonamento push.
- Ritira abbonamento.
Di seguito i dettagli:
Articoli
Un articolo è un oggetto di database, ad esempio una tabella SQL o una stored procedure. Come accennato in precedenza, utilizzando la replica possiamo filtrare i dati o replicare la colonna della tabella selezionata, quindi le colonne o le righe della tabella sono considerate articoli.
Pubblicazione
Gli articoli non possono essere replicati finché non diventano parte della pubblicazione. La pubblicazione è il gruppo degli oggetti Articoli/Database. Rappresenta anche il set di dati che verrà replicato da SQL Server.
Editore
Publisher contiene un database principale che contiene i dati che devono essere pubblicati. Determina quali dati devono essere distribuiti a tutti gli abbonati.
Distributore
Il distributore è il ponte tra editore e abbonato. Il distributore raccoglie tutti i dati pubblicati e li conserva fino all'invio a tutti gli abbonati. È un ponte tra editore e abbonato. Supporta più editori e concetto di abbonato. Non è obbligatorio configurare il distributore su un'istanza SQL separata o un server separato. Se non lo configuriamo, l'editore può fungere da distributore. Le organizzazioni che dispongono di repliche su larga scala possono configurare il distributore su un sistema separato.
Abbonati
L'abbonato è la fine della fonte o della destinazione a cui verranno trasmessi i dati o la pubblicazione replicata. Nella replica, esiste un editore, può avere più abbonati.
Abbonamento push
In un abbonamento push, l'editore aggiorna i dati all'abbonato. In un abbonamento Push, l'abbonato è passivo. L'editore invia articoli o pubblicazioni a tutti i suoi abbonati. In base alle esigenze dell'organizzazione, nella creazione guidata replica, sullo schermo, è possibile selezionare l'abbonamento da utilizzare. La replica delle transazioni e la replica peer-to-peer utilizza l'abbonamento Push per mantenere la disponibilità in tempo reale dei dati.
Ritira abbonamento
In un abbonamento Pull, tutti gli abbonati richiedono i nuovi dati o i dati aggiornati al relativo editore. In un abbonamento pull, possiamo controllare quali dati o modifiche ai dati sono necessari agli abbonati. È utile quando non abbiamo bisogno dei dati modificati immediatamente.
Tipi di replica
SQL Server supporta tre tipi di replica:
- Replica transazionale.
- Replica snapshot.
- Unisci replica.
Replica transazionale
La replica transazionale, tutte le modifiche allo schema e le modifiche ai dati che si verificano nel database dell'editore verranno replicate nel database dell'abbonato. Ogni volta che si verificano operazioni di aggiornamento, eliminazione o inserimento nel database dell'editore, le modifiche vengono tracciate e tali modifiche vengono inviate ai database degli abbonati. La replica transazionale invia solo una quantità limitata di dati su una rete. Inoltre, le modifiche sono quasi in tempo reale, quindi possono essere utilizzate per impostare il sito DR, oppure possono essere utilizzate per scalare le operazioni di reporting. La replica transazionale è ideale per le seguenti situazioni:
- Quando desideri impostare un sistema in cui le modifiche apportate al publisher devono essere applicate immediatamente agli iscritti.
- Il publisher ha INSERT, AGGIORNAMENTI ed ELIMINA alti bassi.
- Quando si desidera impostare una replica eterogenea significato, editore o sottoscrittori per database non SQL Server, come Oracle.
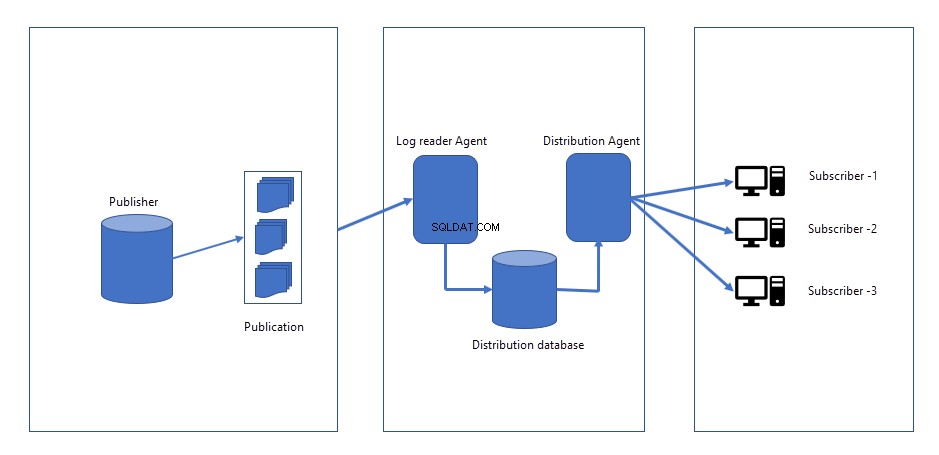
Quando vengono apportate modifiche al database dell'editore, le modifiche vengono registrate in un file di registro nel database dell'editore. Sito distributore/editore, verranno creati due lavori.
- Agente per istantanee :Il lavoro dell'agente snapshot genera l'istantanea dello schema, i dati degli oggetti che vogliamo replicare o pubblicare. I file dell'istantanea possono essere salvati sul server di pubblicazione o sul percorso di rete. Quando avviamo la replica per la prima volta, crea uno snapshot e lo applica a tutti gli abbonati. L'agente snapshot rimane inattivo finché non viene attivato manualmente o pianificato per l'esecuzione a un'ora specifica.
- Agente per la lettura dei log :il lavoro dell'agente di lettura log viene eseguito continuamente. Legge le modifiche (INSERT, UPDATES e DELETES) avvenute dal registro delle transazioni del database dell'editore e le invia a un agente di distribuzione.
- Agente di distribuzione :una volta recuperate le modifiche dall'agente di lettura del registro, l'agente di distribuzione invia tutte le modifiche agli abbonati.
Quando configuriamo la replica transazionale, esegue le seguenti attività
- Si avvia acquisendo il primo snapshot dei dati di pubblicazione e degli oggetti del database e lo snapshot applicato agli abbonati.
- L'agente del lettore di log monitora continuamente il T-Log dell'editore e, se si verificano modifiche, le invia al distributore o direttamente agli abbonati.
L'immagine seguente rappresenta il funzionamento della replica transazionale:
Vantaggi:
- La replica delle transazioni può essere utilizzata come server SQL in standby oppure può essere utilizzata per il bilanciamento del carico o la separazione del sistema di reporting e del sistema OLTP.
- Il server dell'editore replica i dati sul server dell'abbonato con bassa latenza.
- Utilizzando la replica transazionale, è possibile implementare la replica a livello di oggetto.
- La replica transazionale può essere applicata quando hai meno dati da proteggere e dovresti disporre di un piano di ripristino rapido dei dati.
Svantaggi:
- Una volta stabilita la replica, le modifiche allo schema nell'editore non si applicano al server dell'abbonato. Dobbiamo apportare queste modifiche manualmente generando una nuova istantanea e applicandola agli iscritti.
- Se cambiamo i server, dobbiamo riconfigurare la replica.
- Se la replica transazionale viene utilizzata come configurazione di ripristino di emergenza, è necessario eseguire il failover manualmente.
Replica snapshot
La replica di snapshot genera un'immagine/un'istantanea completa della pubblicazione in base a una pianificazione definita e invia i file di snapshot agli abbonati. Quando si verifica la replica dello snapshot, i dati di destinazione verranno sostituiti con un nuovo snapshot. La replica di snapshot è l'opzione migliore quando i dati sono meno volatili. Ad esempio, le tabelle principali come City, CAP, Pincode sono i migliori candidati per la replica di snapshot.
Durante la configurazione della replica degli snapshot, vengono definiti i seguenti componenti importanti:
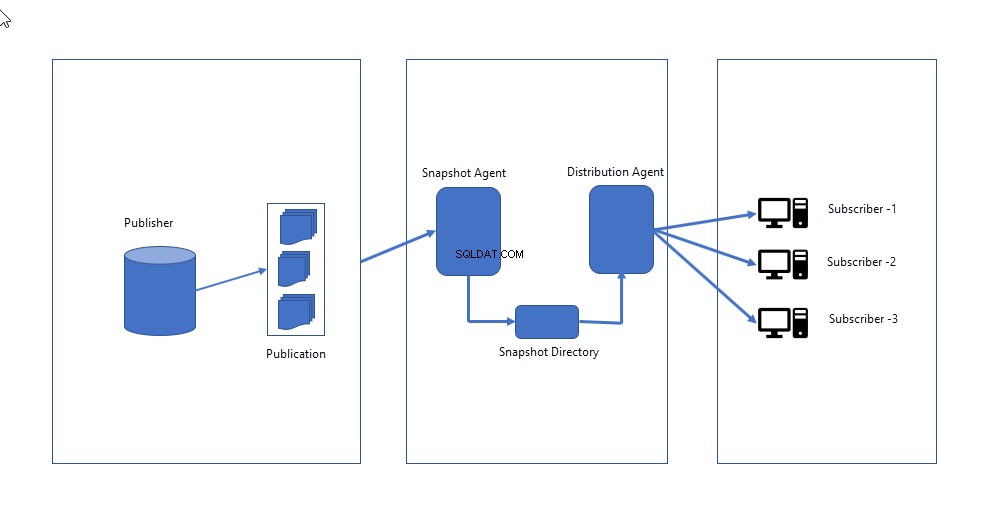
- Agente per istantanee :crea un'immagine completa dello schema e dei dati definiti nella pubblicazione e la invia al distributore. L'agente snapshot rimane inattivo fino a quando non viene attivato manualmente OPPURE pianificato per l'esecuzione a un'ora specifica.
- Agente distributore :invia i file snapshot agli abbonati e applica schema e dati sostituendo quello esistente.
La replica dello snapshot esegue le seguenti attività:
- Nella pianificazione definita, l'agente snapshot inserisce un blocco condiviso sullo schema e sui dati da pubblicare.
- Intero snapshot dei dati pubblicati copiato sul lato distributore. L'agente snapshot crea tre file
- File per creare lo schema del database dei dati pubblicati.
- File BCP per esportare dati all'interno di tabelle SQL
- File di indice per esportare i dati di indice.
- Una volta creati i file, l'agente snapshot rilascia i blocchi condivisi sui dati e sui dati pubblicati.
- Gli agenti del distributore avviano e sostituiscono lo schema ei dati dell'abbonato utilizzando i file creati dall'agente snapshot.
L'immagine seguente illustra come funziona la replica degli snapshot.
Vantaggi
- La replica di snapshot è molto semplice da configurare. Se i dati vengono modificati non di frequente, la replica degli snapshot è un'opzione molto adatta.
- Puoi controllare quando inviare i dati. Ad esempio, una tabella master che ha un volume di dati elevato, ma cambia meno frequentemente di quanto tu possa replicare i dati quando il traffico è basso.
Svantaggi
- L'istantanea generata dall'agente snapshot contiene dati pubblicati modificati e invariati, pertanto l'istantanea trasmessa sulla rete può produrre latenza e influire su altre operazioni.
- Con l'aumento dei dati, la dimensione dell'istantanea aumenta e ci vuole più tempo per creare e distribuire l'istantanea agli iscritti.
Unisci replica
La replica di tipo merge può essere utilizzata quando dobbiamo gestire le modifiche su più server e queste modifiche devono essere consolidate.
Quando configuriamo la replica di tipo merge, verranno creati i seguenti componenti:
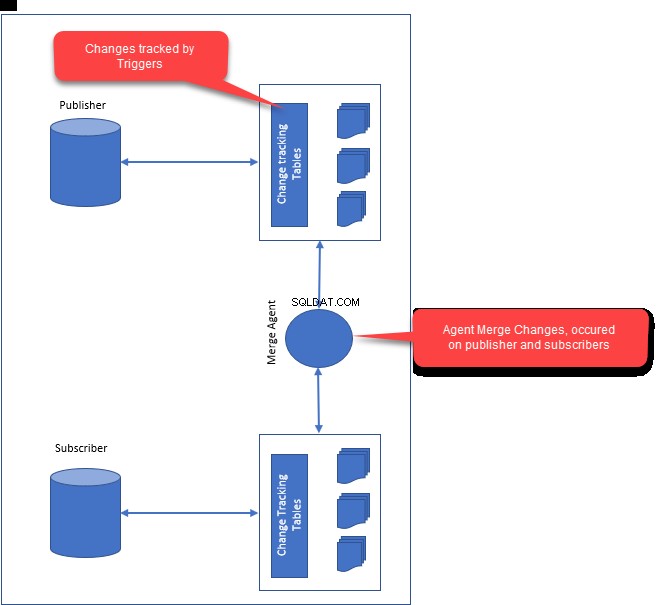
- Agente per istantanee :l'agente snapshot genera il primo snapshot dei dati di pubblicazione e degli oggetti del database. Una volta creata, l'istantanea verrà distribuita a tutti gli iscritti.
- Agente di fusione :l'agente di fusione è responsabile della risoluzione dei conflitti tra editore e abbonati. Eventuali conflitti vengono risolti tramite l'agente di unione che utilizza la risoluzione dei conflitti. A seconda di come hai configurato la risoluzione dei conflitti, i conflitti vengono risolti dall'agente di unione.
Quando configuriamo la replica di tipo merge, esegue le seguenti attività:
- Si avvia acquisendo uno snapshot dei dati di pubblicazione e degli oggetti del database e lo snapshot applicato agli abbonati.
- Durante la configurazione della replica di tipo merge, crea trigger sull'editore e sull'abbonato. I trigger sono responsabili di tenere traccia delle modifiche successive e delle modifiche alle tabelle su editore e abbonati.
- Quando l'editore e gli abbonati si connettono alla rete, le modifiche alle righe di dati e allo schema verranno sincronizzate tra loro. Durante l'unione delle modifiche dell'editore e degli abbonati, l'agente di unione risolve i conflitti in base alle condizioni definite nell'agente di unione.
La replica di tipo merge viene utilizzata negli ambienti da server a client ed è ideale per le situazioni in cui gli abbonati devono recuperare i dati dall'editore, apportare modifiche offline e quindi sincronizzare le modifiche con l'editore e altri abbonati.
Possono verificarsi situazioni pratiche in cui la stessa riga viene modificata da editori e abbonati diversi. A quel punto, l'agente di fusione esaminerà quale risoluzione dei conflitti è definita e apporterà le modifiche di conseguenza.
SQL Server identifica in modo univoco una colonna utilizzando un identificatore univoco globale per ogni riga in una tabella pubblicata. Se la tabella dispone già di una colonna identificatore univoco, SQL Server utilizza automaticamente tale colonna. In caso contrario, aggiungerà una colonna rowguid nella tabella e creerà un indice basato sulla colonna.
I trigger verranno creati nelle tabelle pubblicate sia per gli editori che per gli abbonati. Vengono utilizzati per tenere traccia delle modifiche in base alle modifiche di riga o colonna.
L'immagine seguente illustra come funziona la replica di tipo merge:
Vantaggi:
- Questo è l'unico modo per riuscire a consolidare le modifiche sui dati di più server.
Svantaggi:
- Ci vuole molto tempo per replicare e sincronizzare entrambe le estremità.
- La coerenza è bassa poiché molte parti devono essere sincronizzate.
- Potrebbero esserci conflitti durante l'unione della replica se le stesse righe sono interessate in più di un sottoscrittore e di un editore. Può essere risolto utilizzando la risoluzione dei conflitti, ma rende più complicata la configurazione della replica.
Codice T-SQL per rivedere la configurazione della replica
Ho configurato la replica dello snapshot e la replica transazionale su due istanze della mia macchina. Utilizzando la gestione dinamica SQL (DMV), possiamo verificare la configurazione della replica. Per rivedere la configurazione della replica possiamo usare il codice T-SQL. Il codice dello script popola quanto segue:
- Nome database abbonato.
- Nome dell'editore.
- Tipo di abbonamento.
- Database editore.
- Nome agente di replica.
Di seguito lo script:
SELECT DistributionAgent.subscriber_db [Subscriber DB], DistributionAgent.publication [PUB Name], RIGHT(LEFT(DistributionAgent.NAME, Len(DistributionAgent.NAME) - ( Len( DistributionAgent.id) + 1 )), Len(LEFT( DistributionAgent.NAME, Len(DistributionAgent.NAME) - ( Len( DistributionAgent.id) + 1 ))) - ( 10 + Len(DistributionAgent.publisher_db) + ( CASE WHEN DistributionAgent.publisher_db = 'ALL' THEN 1 ELSE Len( DistributionAgent.publication) + 2 END ) )) [SUBSCRIBER], ( CASE WHEN DistributionAgent.subscription_type = '0' THEN 'Push' WHEN DistributionAgent.subscription_type = '1' THEN 'Pull' WHEN DistributionAgent.subscription_type = '2' THEN 'Anonymous' ELSE Cast(DistributionAgent.subscription_type AS VARCHAR) END ) [Subscrition Type], DistributionAgent.publisher_db + ' - ' + Cast(DistributionAgent.publisher_database_id AS VARCHAR) [Publisher Database], DistributionAgent.NAME [Pub - DB - Publication - SUB - AgentID] FROM distribution.dbo.msdistribution_agents DistributionAgent WHERE DistributionAgent.subscriber_db <> 'virtual'
Di seguito è riportato l'output:

Riepilogo
In questo articolo ho spiegato:
- Le basi ei vantaggi della replica e dei suoi componenti.
- Replica transazionale.
- Replica istantanea.
- Unisci replica.