Introduzione
Agli sviluppatori viene spesso detto di utilizzare le procedure memorizzate per evitare le cosiddette query ad hoc che può causare un inutile rigonfiamento della cache del piano. Vedete, quando il codice SQL ricorrente viene scritto in modo incoerente o quando c'è codice che genera SQL dinamico al volo, SQL Server ha la tendenza a creare un piano di esecuzione per ogni singola esecuzione. Ciò potrebbe ridurre le prestazioni complessive di:
Richiede una fase di compilazione per ogni esecuzione di codice.
Rigonfiamento della cache dei piani con troppi handle di piani che potrebbero non essere riutilizzati.
Ottimizza per carichi di lavoro ad hoc
Un modo in cui questo problema è stato gestito in passato è l'ottimizzazione dell'istanza per i carichi di lavoro ad hoc. Questa operazione può essere utile solo se la maggior parte dei database o dei database più significativi sull'istanza eseguono prevalentemente SQL ad hoc.
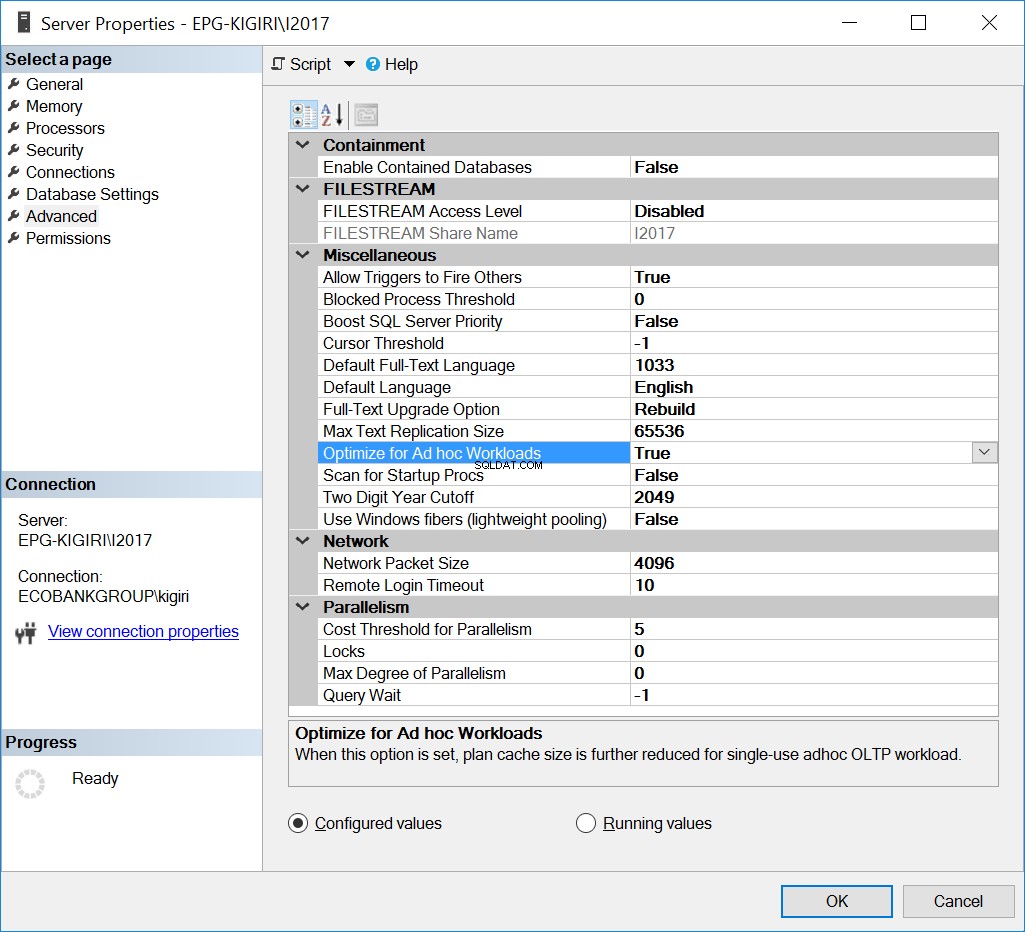
Fig. 1 Ottimizza per carichi di lavoro ad hoc
--Enable OFAW Using T-SQL EXEC sys.sp_configure N'show advanced options', N'1' RECONFIGURE WITH OVERRIDE GO EXEC sys.sp_configure N'optimize for ad hoc workloads', N'1' GO RECONFIGURE WITH OVERRIDE GO EXEC sys.sp_configure N'show advanced options', N'0' RECONFIGURE WITH OVERRIDE GO
In sostanza, questa opzione indica a SQL Server di salvare una versione parziale del piano nota come stub del piano compilato. Lo stub occupa molto meno spazio dell'intero piano.
In alternativa a questo metodo, alcune persone affrontano il problema in modo piuttosto brutale e svuotano la cache del piano di tanto in tanto. Oppure, in modo più attento, svuotare i "piani monouso" utilizzando DBCC FREESYSTEMCACHE. Lo svuotamento dell'intera cache del piano ha i suoi svantaggi, come forse già saprai.
Utilizzo di stored procedure e parametri
Utilizzando le procedure memorizzate, è possibile eliminare virtualmente il problema causato da SQL Ad Hoc. Una stored procedure viene compilata solo una volta e lo stesso piano viene riutilizzato per le successive esecuzioni delle query SQL uguali o simili. Quando le stored procedure vengono utilizzate per implementare la logica aziendale, la differenza fondamentale nelle query SQL che verranno eseguite in modo eventi da SQL Server risiede nei parametri passati al momento dell'esecuzione. Poiché il piano è già attivo e pronto per l'uso, SQL Server utilizzerà lo stesso piano indipendentemente dal parametro passato.
Dati distorti
In alcuni scenari, i dati con cui abbiamo a che fare non sono distribuiti uniformemente. Possiamo dimostrarlo:prima dovremo creare una tabella:
--Create Table with Skewed Data
use Practice2017
go
create table Skewed (
ID int identity (1,1)
, FirstName varchar(50)
, LastName varchar(50)
, CountryCode char(2)
);
insert into Skewed values ('Kwaku','Amoako','GH')
go 10000
insert into Skewed values ('Kenneth','Igiri','NG')
go 10
insert into Skewed values ('Steve','Jones','US')
go 2
create clustered index CIX_ID on Skewed(ID);
create index IX_CountryCode on Skewed (CountryCode); La nostra tabella contiene i dati dei soci del club di diversi paesi. Un gran numero di soci del club proviene dal Ghana, mentre altre due nazioni hanno rispettivamente dieci e due soci. Per rimanere concentrato sull'agenda e per semplicità, ho usato solo tre paesi e lo stesso nome per membri provenienti dallo stesso paese paese. Inoltre, ho aggiunto un indice cluster nella colonna ID e un indice non cluster nella colonna CountryCode per dimostrare l'effetto di piani di esecuzione diversi per valori diversi.
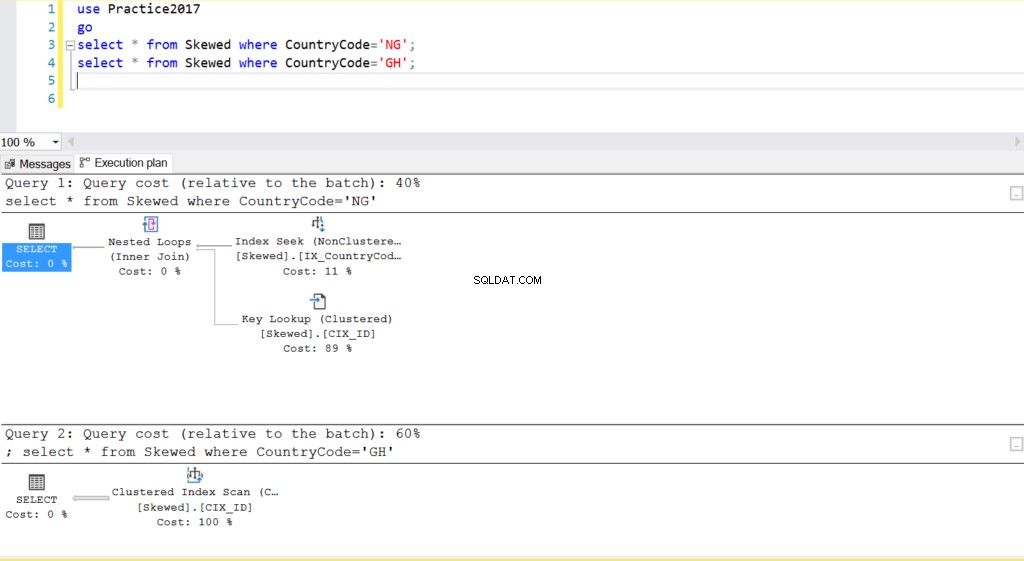
Fig. 2 Piani di esecuzione per due query
Quando eseguiamo query nella tabella per i record in cui CountryCode è NG e GH, scopriamo che SQL Server utilizza due piani di esecuzione diversi in questi casi. Ciò accade perché il numero previsto di righe per CountryCode='NG' è 10, mentre quello per CountryCode='GH' è 10000. SQL Server determina il piano di esecuzione preferibile in base alle statistiche della tabella. Se il numero previsto di righe è elevato rispetto al numero totale di righe nella tabella, SQL Server decide che è meglio eseguire semplicemente un'analisi completa della tabella anziché fare riferimento a un indice. Con un numero stimato di righe molto inferiore, l'indice diventa utile.
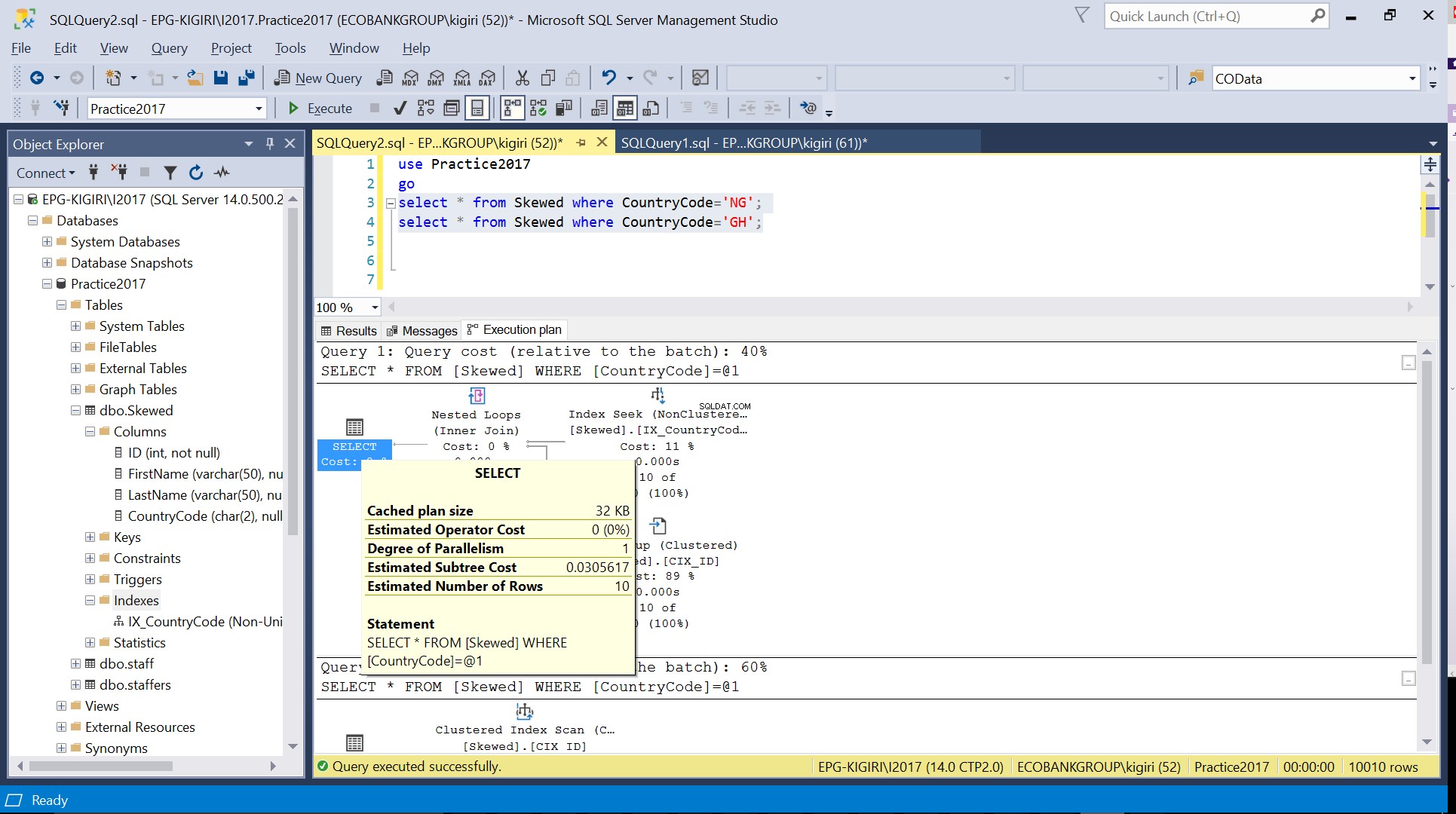
Fig. 3 Numero stimato di righe per CountryCode='NG'
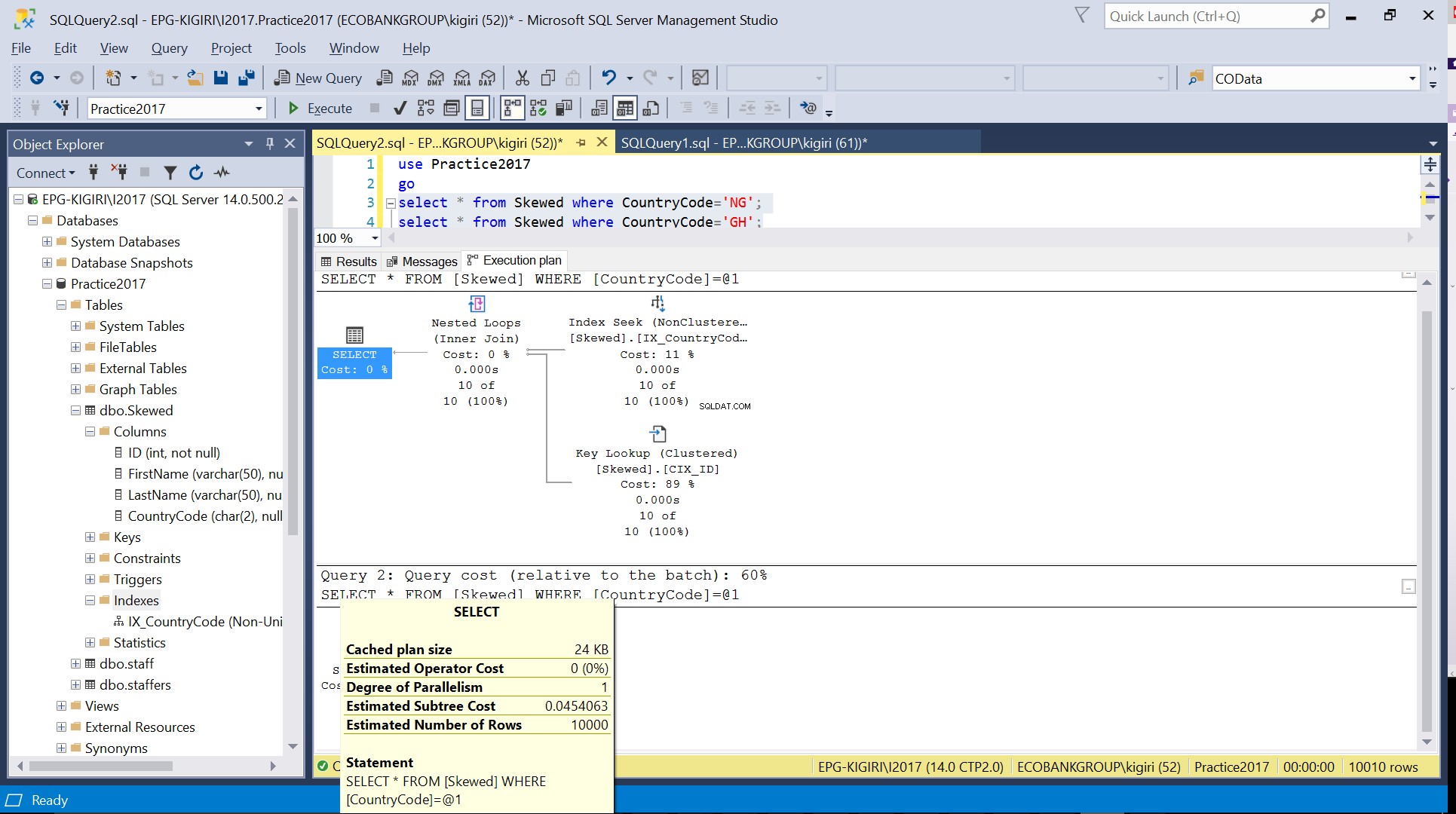
Fig. 4 Numero stimato di righe per CountryCode='GH'
Inserisci procedure archiviate
Possiamo creare una procedura memorizzata per recuperare i record che vogliamo utilizzando la stessa query. L'unica differenza questa volta è che passiamo CountryCode come parametro (vedi Listato 3). Facendo ciò, scopriamo che il piano di esecuzione è lo stesso indipendentemente dal parametro che passiamo. Il piano di esecuzione che verrà utilizzato è determinato dal piano di esecuzione restituito alla prima chiamata della stored procedure. Ad esempio, se eseguiamo prima la procedura con CountryCode='GH', da quel momento in poi utilizzerà una scansione completa della tabella. Se quindi cancelliamo la cache della procedura ed eseguiamo prima la procedura con CountryCode='NG', in futuro utilizzerà scansioni basate su indici.
--Create a Stored Procedure to Fetch the Data use Practice2017 go select * from Skewed where CountryCode='NG'; select * from Skewed where CountryCode='GH'; create procedure FetchMembers ( @countrycode char(2) ) as begin select * from Skewed where example@sqldat.com end; exec FetchMembers 'NG'; exec FetchMembers 'GH'; DBCC FREEPROCCACHE exec FetchMembers 'GH'; exec FetchMembers 'NG';
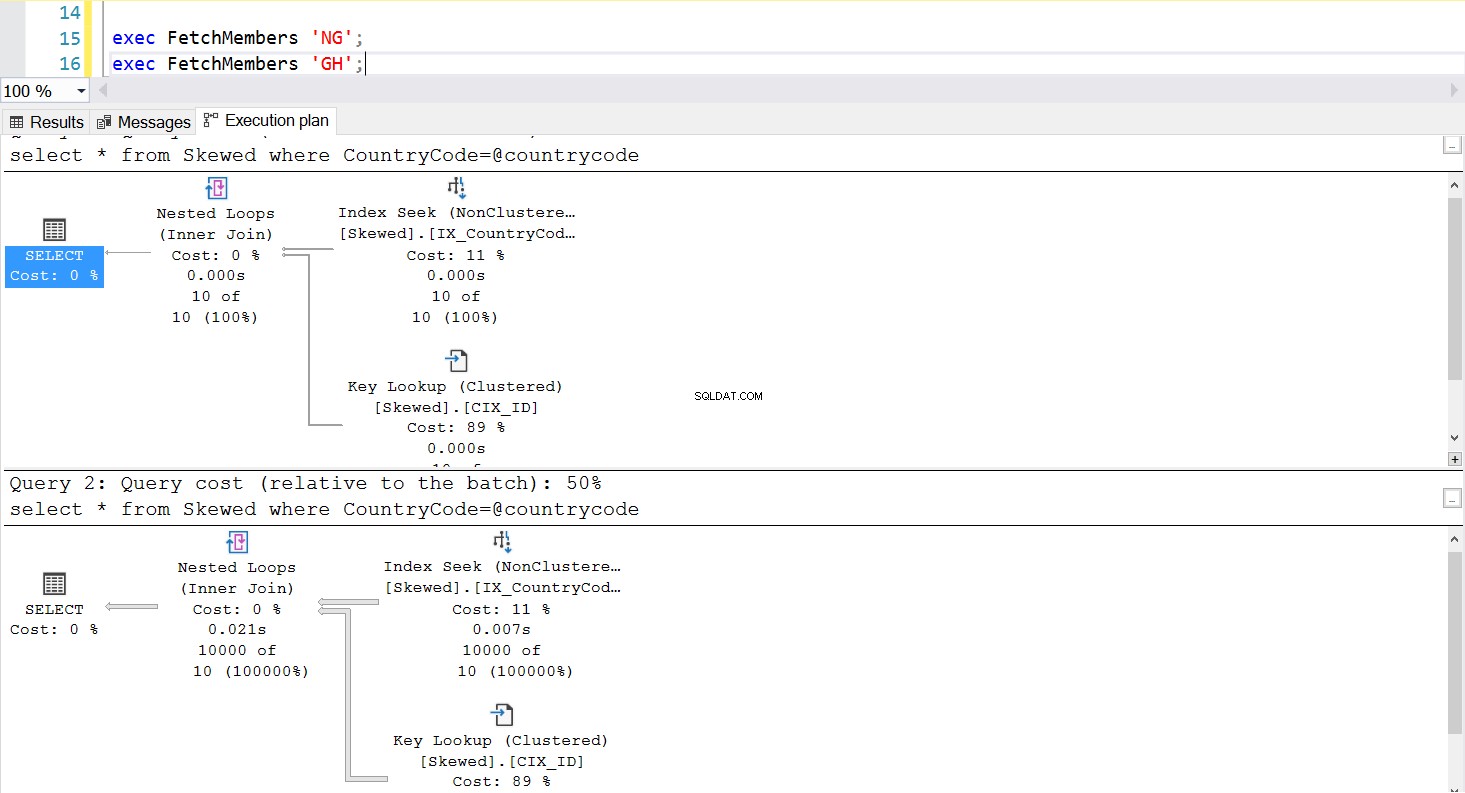
Fig. 5 Piano di esecuzione della ricerca dell'indice quando viene utilizzato per primo "NG"
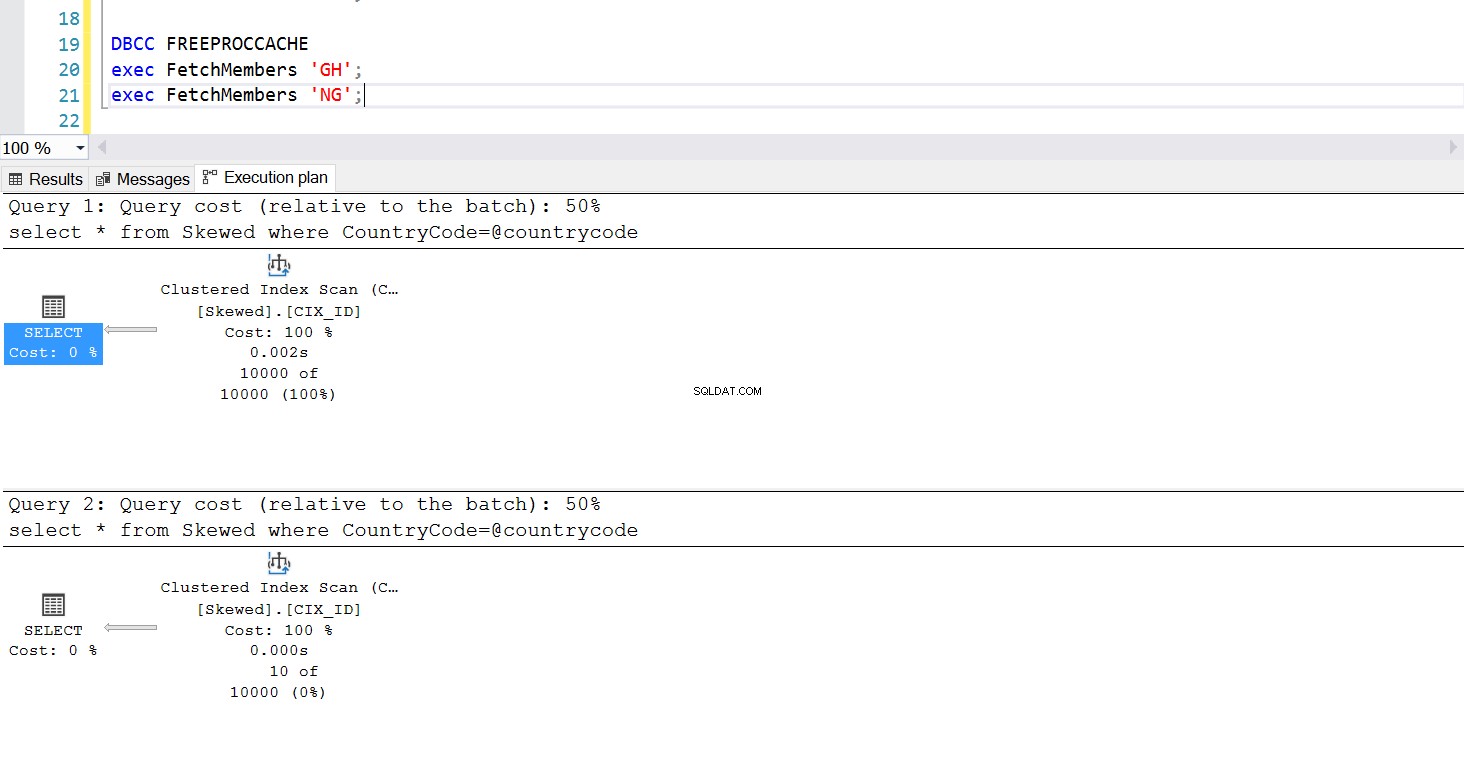
Fig. 6 Piano di esecuzione della scansione dell'indice in cluster quando viene utilizzato per primo 'GH'
L'esecuzione della procedura memorizzata si sta comportando come previsto:il piano di esecuzione richiesto viene utilizzato in modo coerente. Tuttavia, questo può essere un problema perché un piano di esecuzione non è adatto per tutte le query se i dati sono distorti. L'utilizzo di un indice per recuperare una raccolta di righe grande quasi quanto l'intera tabella non è efficiente, né l'utilizzo di una scansione completa per recuperare solo un numero ridotto di righe. Questo è il problema dello sniffing dei parametri.
Possibili soluzioni
Un modo comune per gestire il problema dello sniffing dei parametri consiste nell'invocare deliberatamente la ricompilazione ogni volta che viene eseguita la procedura memorizzata. Questo è molto meglio che svuotare la Plan Cache, tranne se si desidera svuotare la cache di questa specifica query SQL, il che è del tutto possibile. Dai un'occhiata a una versione aggiornata della stored procedure. Questa volta, utilizza OPTION (RICIMPILA) per gestire il problema. La Fig.6 ci mostra che, ogni volta che viene eseguita la nuova stored procedure, utilizza un piano appropriato al parametro che stiamo passando.
--Create a New Stored Procedure to Fetch the Data create procedure FetchMembers_Recompile ( @countrycode char(2) ) as begin select * from Skewed where example@sqldat.com OPTION (RECOMPILE) end; exec FetchMembers_Recompile 'GH'; exec FetchMembers_Recompile 'NG';
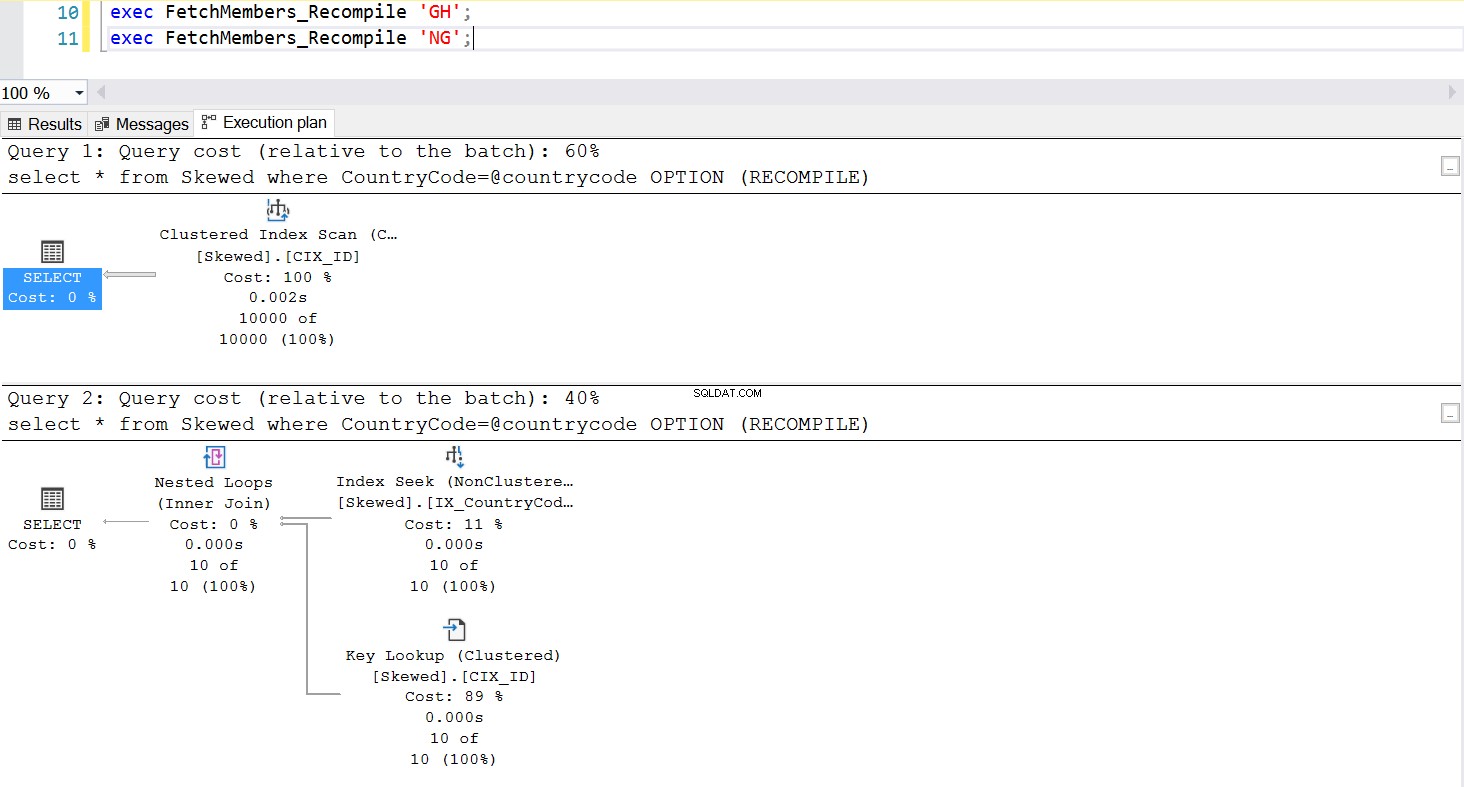
Fig. 7 Comportamento della stored procedure con OPTION (RICIMPILA)
Conclusione
In questo articolo, abbiamo esaminato in che modo i piani di esecuzione coerenti per le procedure archiviate possono diventare un problema quando i dati con cui abbiamo a che fare sono distorti. Lo abbiamo anche dimostrato nella pratica e abbiamo appreso una soluzione comune al problema. Oserei dire che questa conoscenza è preziosa per gli sviluppatori che utilizzano SQL Server. Ci sono una serie di altre soluzioni a questo problema:Brent Ozar ha approfondito l'argomento e ha evidenziato alcuni dettagli e soluzioni più profondi allo SQLDay Poland 2017. Ho elencato il collegamento corrispondente nella sezione di riferimento.
Riferimenti
Pianifica la cache e ottimizza i carichi di lavoro ad hoc
Identificazione e risoluzione dei problemi di sniffing dei parametri