Ti stai chiedendo cosa sono gli schemi Postgresql e perché sono importanti e come puoi utilizzare gli schemi per rendere le implementazioni del tuo database più robuste e manutenibili? Questo articolo introdurrà le basi degli schemi in Postgresql e ti mostrerà come crearli con alcuni esempi di base. Gli articoli futuri approfondiranno esempi di come proteggere e utilizzare schemi per applicazioni reali.
In primo luogo, per chiarire una potenziale confusione terminologica, capiamo che nel mondo Postgresql, il termine "schema" è forse un po' purtroppo sovraccaricato. Nel più ampio contesto dei sistemi di gestione di database relazionali (RDBMS), il termine "schema" potrebbe essere inteso in riferimento alla progettazione logica o fisica complessiva del database, ovvero la definizione di tutte le tabelle, colonne, viste e altri oggetti che costituiscono la definizione del database. In tale contesto più ampio, uno schema potrebbe essere espresso in un diagramma entità-relazione (ER) o in uno script di istruzioni DDL (Data Definition Language) utilizzato per creare un'istanza del database dell'applicazione.
Nel mondo Postgresql, il termine "schema" potrebbe essere meglio inteso come "spazio dei nomi". Infatti, nelle tabelle di sistema Postgresql, gli schemi sono registrati in colonne di tabella chiamate "spazio dei nomi", che, IMHO, è una terminologia più accurata. In pratica, ogni volta che vedo "schema" nel contesto di Postgresql, lo reinterpreto silenziosamente dicendo "spazio dei nomi".
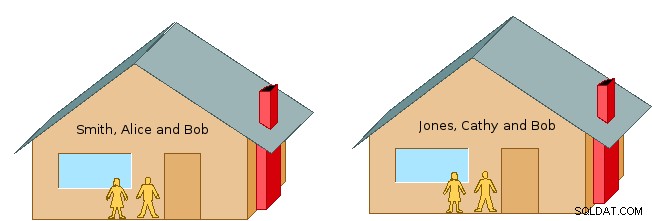
Ma potresti chiedere:"Cos'è uno spazio dei nomi?" In genere, uno spazio dei nomi è un mezzo piuttosto flessibile per organizzare e identificare le informazioni in base al nome. Ad esempio, immagina due famiglie vicine, gli Smith, Alice e Bob, e i Jones, Bob e Cathy (cfr. Figura 1). Se usiamo solo i nomi di battesimo, potrebbe creare confusione su quale persona intendessimo quando parliamo di Bob. Ma aggiungendo il cognome, Smith o Jones, identifichiamo in modo univoco quale persona intendiamo.
Spesso, gli spazi dei nomi sono organizzati in una gerarchia nidificata. Ciò consente una classificazione efficiente di grandi quantità di informazioni in una struttura a grana molto fine, come ad esempio il sistema dei nomi di dominio Internet. Al livello superiore, “.com”, “.net”, “.org”, “.edu” e così via, definiscono ampi spazi dei nomi all'interno dei quali sono registrati i nomi di entità specifiche, ad esempio “diverselnines.com” e "postgresql.org" sono definiti in modo univoco. Ma sotto ognuno di questi ci sono un certo numero di sottodomini comuni come "www", "mail" e "ftp", ad esempio, che da soli sono duplicati, ma all'interno dei rispettivi nomi gli spazi sono univoci.
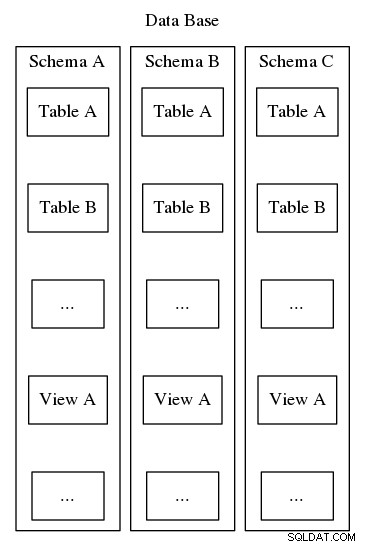
Gli schemi Postgresql servono allo stesso scopo di organizzazione e identificazione, tuttavia, a differenza del secondo esempio sopra, gli schemi Postgresql non possono essere nidificati in una gerarchia. Sebbene un database possa contenere molti schemi, esiste sempre un solo livello e quindi all'interno di un database i nomi degli schemi devono essere univoci. Inoltre, ogni database deve includere almeno uno schema. Ogni volta che viene creata un'istanza di un nuovo database, viene creato uno schema predefinito denominato "pubblico". Il contenuto di uno schema include tutti gli altri oggetti del database come tabelle, viste, stored procedure, trigger e così via. Per visualizzare, fare riferimento alla Figura 2, che illustra un annidamento simile a una bambola matrioska che mostra dove gli schemi si inseriscono nella struttura di un Database Postgresql.
Oltre a organizzare semplicemente gli oggetti del database in gruppi logici per renderli più gestibili, gli schemi servono allo scopo pratico di evitare la collisione dei nomi. Un paradigma operativo prevede la definizione di uno schema per ciascun utente del database in modo da fornire un certo grado di isolamento, uno spazio in cui gli utenti possono definire le proprie tabelle e viste senza interferire tra loro. Un altro approccio consiste nell'installare strumenti di terze parti o estensioni di database in schemi individuali in modo da mantenere tutti i componenti correlati logicamente insieme. Un articolo successivo di questa serie descriverà in dettaglio un nuovo approccio alla progettazione di applicazioni robuste, utilizzando gli schemi come mezzo indiretto per limitare l'esposizione della progettazione fisica del database e presentando invece un'interfaccia utente che risolve le chiavi sintetiche e facilita la manutenzione a lungo termine e la gestione della configurazione man mano che i requisiti di sistema evolvono.
Facciamo un po' di codice!
Scarica il whitepaper oggi Gestione e automazione di PostgreSQL con ClusterControlScopri cosa devi sapere per distribuire, monitorare, gestire e ridimensionare PostgreSQLScarica il whitepaperIl comando più semplice per creare uno schema all'interno di un database è
CREATE SCHEMA hollywood;Questo comando richiede la creazione dei privilegi nel database e lo schema "hollywood" appena creato sarà di proprietà dell'utente che invoca il comando. Una chiamata più complessa può includere elementi facoltativi che specificano un proprietario diverso e può anche includere istruzioni DDL che istanziano oggetti di database all'interno dello schema, tutto in un unico comando!
Il formato generale è
CREATE SCHEMA schemaname [ AUTHORIZATION username ] [ schema_element [ ... ] ]dove "username" è chi sarà il proprietario dello schema e "schema_element" potrebbe essere uno di alcuni comandi DDL (fare riferimento alla documentazione di Postgresql per i dettagli). I privilegi di superutente sono necessari per utilizzare l'opzione AUTORIZZAZIONE.
Quindi, ad esempio, per creare uno schema chiamato "hollywood" contenente una tabella denominata "films" e visualizzare i "winners" in un comando, potresti farlo
CREATE SCHEMA hollywood
CREATE TABLE films (title text, release date, awards text[])
CREATE VIEW winners AS
SELECT title, release FROM films WHERE awards IS NOT NULL;Ulteriori oggetti database possono essere successivamente creati direttamente, ad esempio una tabella aggiuntiva verrebbe aggiunta allo schema con
CREATE TABLE hollywood.actors (name text, dob date, gender text);Nota nell'esempio precedente il prefisso del nome della tabella con il nome dello schema. Ciò è necessario perché per impostazione predefinita, ovvero senza una specifica esplicita dello schema, vengono creati nuovi oggetti di database all'interno di qualunque sia lo schema corrente, di cui parleremo in seguito.
Ricordiamo come nell'esempio dello spazio dei nomi sopra, avevamo due persone di nome Bob e abbiamo descritto come deconfliggere o distinguerle includendo il cognome. Ma all'interno di ciascuna delle famiglie Smith e Jones separatamente, ogni famiglia intende "Bob" per riferirsi a quella che si accompagna a quella particolare famiglia. Quindi, ad esempio, nel contesto di ciascuna rispettiva famiglia, Alice non ha bisogno di chiamare suo marito Bob Jones, e Cathy non ha bisogno di riferirsi a suo marito come Bob Smith:ognuno può semplicemente dire "Bob".
Lo schema attuale di Postgresql è un po' come la famiglia nell'esempio sopra. Gli oggetti nello schema corrente possono essere referenziati non qualificati, ma fare riferimento a oggetti con nomi simili in altri schemi richiede la qualificazione del nome anteponendo il nome dello schema come sopra.
Lo schema corrente è derivato dal parametro di configurazione "percorso_ricerca". Questo parametro memorizza un elenco di nomi di schema separati da virgole e può essere esaminato con il comando
SHOW search_path;oppure imposta un nuovo valore con
SET search_path TO schema [, schema, ...];Il primo nome dello schema nell'elenco è lo "schema corrente" ed è il punto in cui vengono creati nuovi oggetti se specificato senza la qualifica del nome dello schema.
L'elenco separato da virgole dei nomi degli schemi serve anche a determinare l'ordine di ricerca in base al quale il sistema individua gli oggetti con nome non qualificati esistenti. Ad esempio, tornando al quartiere di Smith and Jones, la consegna di un pacco indirizzato solo a "Bob" richiederebbe una visita in ciascuna famiglia fino a quando non viene trovato il primo residente chiamato "Bob". Nota, questo potrebbe non essere il destinatario previsto. La stessa logica si applica a Postgresql. Il sistema ricerca tabelle, viste e altri oggetti all'interno degli schemi nell'ordine del percorso_ricerca, quindi viene utilizzato il primo oggetto di corrispondenza del nome trovato. Gli oggetti con nome qualificati dallo schema vengono utilizzati direttamente senza riferimento al percorso_ricerca.
Nella configurazione predefinita, l'interrogazione della variabile di configurazione search_path rivela questo valore
SHOW search_path;
Search_path
--------------
"$user", publicIl sistema interpreta il primo valore mostrato sopra come il nome utente attualmente connesso e soddisfa il caso d'uso menzionato in precedenza in cui a ciascun utente viene assegnato uno schema con nome utente per uno spazio di lavoro separato dagli altri utenti. Se non è stato creato alcuno schema con nome utente, tale voce viene ignorata e lo schema "pubblico" diventa lo schema corrente in cui vengono creati i nuovi oggetti.
Pertanto, tornando al nostro precedente esempio di creazione della tabella "hollywood.acters", se non avessimo qualificato il nome della tabella con il nome dello schema, la tabella sarebbe stata creata nello schema pubblico. Se abbiamo previsto la creazione di tutti gli oggetti all'interno di uno schema specifico, potrebbe essere conveniente impostare la variabile search_path come
SET search_path TO hollywood,public;facilitando l'abbreviazione di digitare nomi non qualificati per creare o accedere a oggetti di database.
C'è anche una funzione di informazioni di sistema che restituisce lo schema corrente con una query
select current_schema();In caso di diteggiatura dell'ortografia, il proprietario di uno schema può cambiare il nome, a condizione che l'utente disponga anche dei privilegi di creazione per il database, con il
ALTER SCHEMA old_name RENAME TO new_name;Infine, per eliminare uno schema da un database, c'è un comando drop
DROP SCHEMA schema_name;Il comando DROP fallirà se lo schema contiene oggetti, quindi devono essere eliminati prima, oppure puoi opzionalmente eliminare uno schema ricorsivamente tutto il suo contenuto con l'opzione CASCADE
DROP SCHEMA schema_name CASCADE;Queste nozioni di base ti consentiranno di iniziare a comprendere gli schemi!