PostgreSQL è un progetto fantastico e si evolve a un ritmo incredibile. Ci concentreremo sull'evoluzione delle capacità di tolleranza agli errori in PostgreSQL in tutte le sue versioni con una serie di post sul blog. Questo è il terzo post della serie e parleremo dei problemi della sequenza temporale e dei loro effetti sulla tolleranza agli errori e sull'affidabilità di PostgreSQL.
Se desideri assistere ai progressi dell'evoluzione dall'inizio, controlla i primi due post del blog della serie:
- Evoluzione della tolleranza agli errori in PostgreSQL
- Evoluzione della tolleranza ai guasti in PostgreSQL:fase di replica

Linee temporali
La possibilità di ripristinare il database a un punto precedente crea alcune complessità di cui tratteremo alcuni casi spiegando il failover (Fig. 1), passaggio (Fig. 2) e pg_rewind (Fig. 3) casi più avanti in questo argomento.
Ad esempio, nella cronologia originale del database, supponiamo di aver eliminato un tavolo critico alle 17:15 di martedì sera, ma di non aver realizzato l'errore fino a mercoledì a mezzogiorno. Impassibile, esci dal backup, ripristini fino alle 17:14 di martedì sera e sei pronto e funzionante. In questa storia dell'universo del database, non hai mai abbandonato la tabella. Ma supponiamo che in seguito ti rendi conto che questa non è stata una grande idea e vorresti tornare a un mercoledì mattina nella storia originale. Non sarai in grado di farlo se, mentre il tuo database era attivo e funzionante, ha sovrascritto alcuni dei file del segmento WAL che hanno portato al momento in cui ora vorresti poter tornare.
Pertanto, per evitare ciò, è necessario distinguere la serie di record WAL generati dopo aver eseguito un ripristino point-in-time da quelli generati nella cronologia del database originale.
Per affrontare questo problema, PostgreSQL ha una nozione di linee temporali. Ogni volta che viene completato un ripristino dell'archivio, viene creata una nuova sequenza temporale per identificare la serie di record WAL generati dopo tale ripristino. Il numero ID della sequenza temporale fa parte dei nomi dei file dei segmenti WAL, quindi una nuova sequenza temporale non sovrascrive i dati WAL generati dalle sequenze temporali precedenti. È infatti possibile archiviare molte linee temporali differenti.
Considera la situazione in cui non sei abbastanza sicuro in quale momento recuperare, e quindi devi eseguire diversi recuperi puntuali per tentativi ed errori finché non trovi il posto migliore per staccare dalla vecchia storia. Senza scadenze questo processo genererebbe presto un pasticcio ingestibile. Con le sequenze temporali, puoi ripristinare qualsiasi stato precedente, inclusi gli stati nei rami della sequenza temporale che hai abbandonato in precedenza.
Ogni volta che viene creata una nuova sequenza temporale, PostgreSQL crea un file di "cronologia della sequenza temporale" che mostra da quale sequenza temporale si è diramata e quando. Questi file di cronologia sono necessari per consentire al sistema di selezionare i file di segmento WAL corretti durante il ripristino da un archivio che contiene più linee temporali. Pertanto, vengono archiviati nell'area di archivio WAL proprio come i file di segmento WAL. I file di cronologia sono solo piccoli file di testo, quindi è economico e appropriato tenerli in giro a tempo indeterminato (a differenza dei file di segmento che sono di grandi dimensioni). Puoi, se lo desideri, aggiungere commenti a un file di cronologia per registrare le tue note su come e perché questa particolare sequenza temporale è stata creata. Tali commenti saranno particolarmente preziosi quando si dispone di un insieme di linee temporali diverse come risultato della sperimentazione.
Il comportamento predefinito del ripristino prevede il ripristino lungo la stessa sequenza temporale corrente al momento dell'esecuzione del backup di base. Se si desidera eseguire il ripristino in una sequenza temporale figlio (ovvero, si desidera tornare a uno stato che è stato generato a sua volta dopo un tentativo di ripristino), è necessario specificare l'ID sequenza temporale di destinazione in recovery.conf. Non puoi eseguire il ripristino in sequenze temporali che si sono ramificate prima del backup di base.
Per semplificare il concetto di timeline in PostgreSQL, problemi relativi alla timeline in caso di failover , passaggio e pg_rewind sono riassunti e spiegati con Fig.1, Fig.2 e Fig.3.
Scenario di failover:
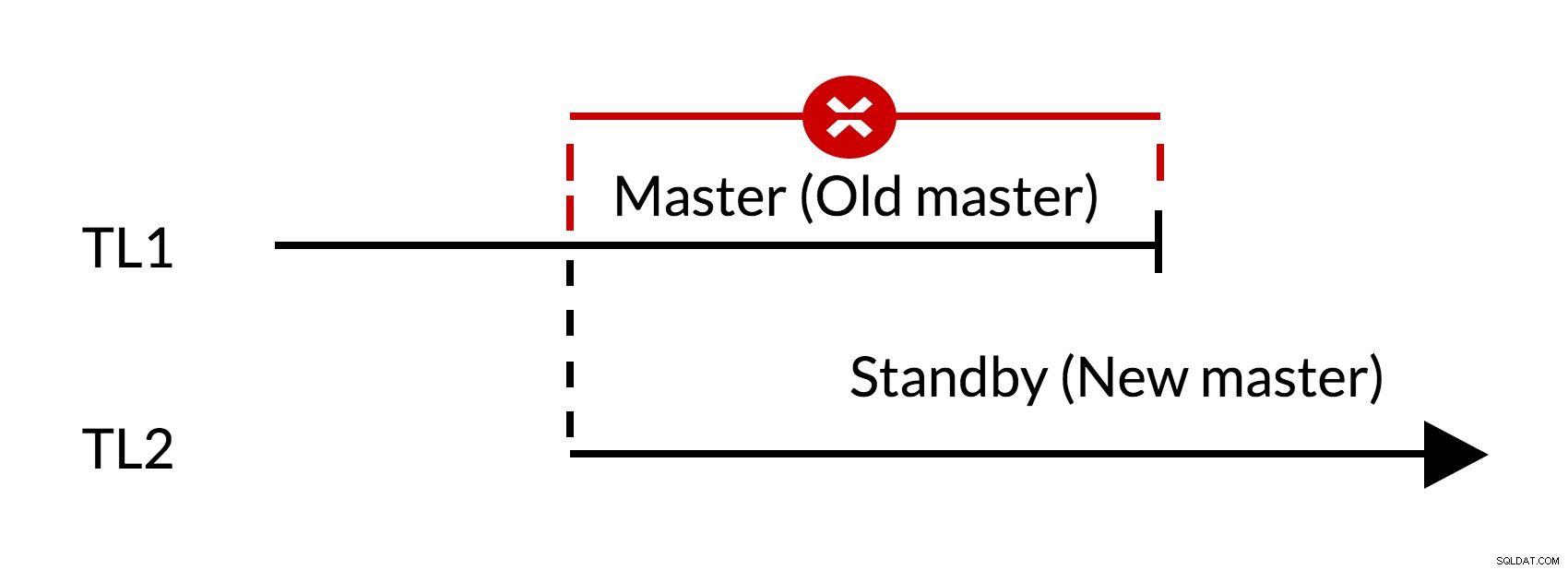
Fig.1 Failover
- Ci sono modifiche in sospeso nel vecchio master (TL1)
- L'aumento della sequenza temporale rappresenta la nuova cronologia delle modifiche (TL2)
- Le modifiche dalla vecchia sequenza temporale non possono essere riprodotte sui server che sono passati alla nuova sequenza temporale
- Il vecchio maestro non può seguire il nuovo maestro
Scenario di commutazione:
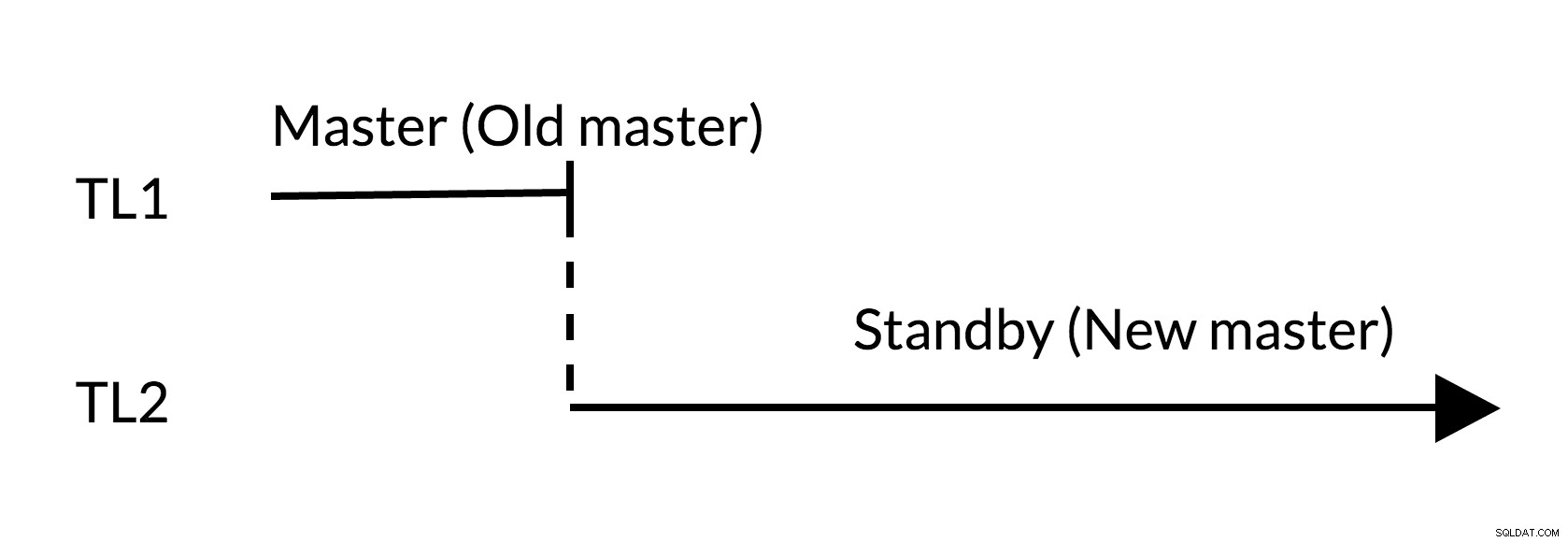 Fig.2 Passaggio
Fig.2 Passaggio
- Non ci sono modifiche in sospeso nel vecchio master (TL1)
- L'aumento della sequenza temporale rappresenta la nuova cronologia delle modifiche (TL2)
- Il vecchio master può diventare standby per il nuovo master
scenario pg_rewind:
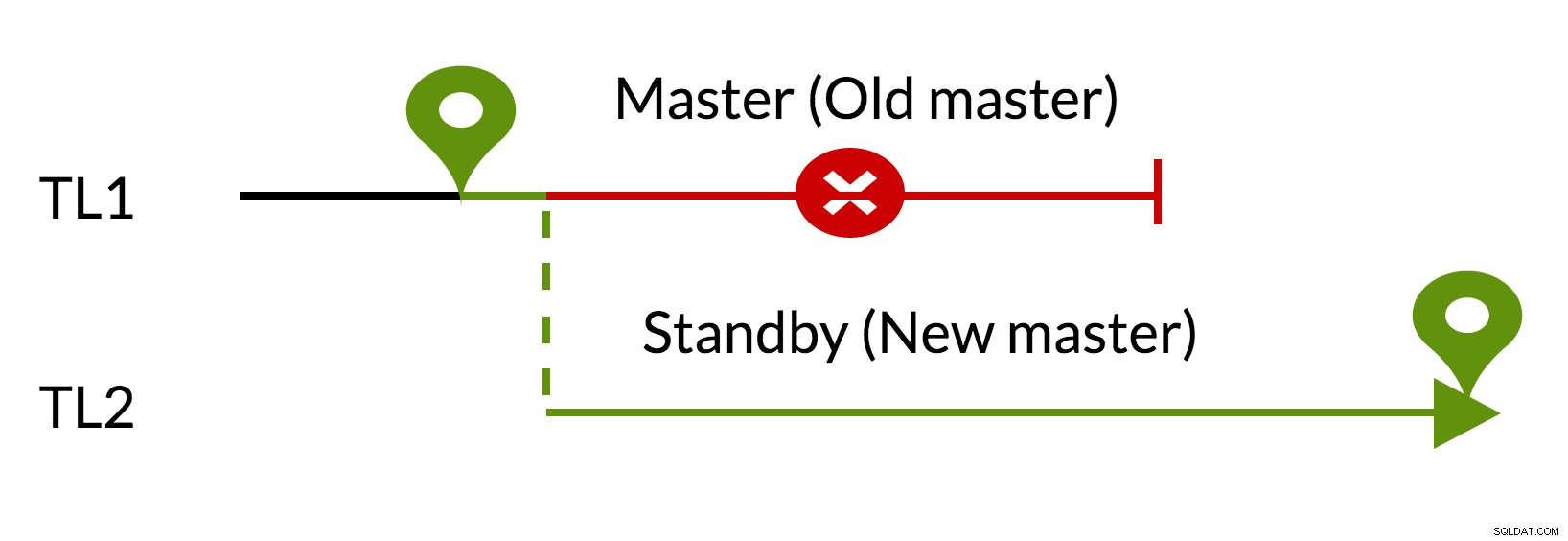 Fig.3 pg_rewind
Fig.3 pg_rewind
- Le modifiche in sospeso vengono rimosse utilizzando i dati del nuovo master (TL1)
- Il vecchio master può seguire il nuovo master (TL2)
pg_rewind
pg_rewind è uno strumento per sincronizzare un cluster PostgreSQL con un'altra copia dello stesso cluster, dopo che le linee temporali dei cluster si sono discostate. Uno scenario tipico consiste nel riportare online un vecchio server master dopo il failover, come standby che segue il nuovo master.
Il risultato equivale a sostituire la directory dei dati di destinazione con quella di origine. Tutti i file vengono copiati, inclusi i file di configurazione. Il vantaggio di pg_rewind rispetto a un nuovo backup di base, o strumenti come rsync, è che pg_rewind non richiede la lettura di tutti i file non modificati nel cluster. Ciò lo rende molto più veloce quando il database è grande e solo una piccola parte differisce tra i cluster.
Come funziona?
L'idea di base è copiare tutto dal nuovo cluster al vecchio cluster, ad eccezione dei blocchi che sappiamo essere gli stessi.
- Esegui la scansione del registro WAL del vecchio cluster, a partire dall'ultimo checkpoint prima del punto in cui la cronologia della sequenza temporale del nuovo cluster si è biforcata dal vecchio cluster. Per ogni record WAL, prendere nota dei blocchi di dati che sono stati toccati. Questo produce un elenco di tutti i blocchi di dati che sono stati modificati nel vecchio cluster, dopo il fork del nuovo cluster.
- Copia tutti i blocchi modificati dal nuovo cluster al vecchio cluster.
- Copia tutti gli altri file come clog e file di configurazione dal nuovo cluster al vecchio cluster, tutto tranne i file di relazione.
- Applica il WAL dal nuovo cluster, partendo dal checkpoint creato al failover. (A rigor di termini, pg_rewind non applica il WAL, crea solo un file di etichetta di backup che indica che all'avvio di PostgreSQL, inizierà la riproduzione da quel checkpoint e applicherà tutto il WAL richiesto.)
Nota: wal_log_hints deve essere impostato in postgresql.conf affinché pg_rewind possa funzionare. Questo parametro può essere impostato solo all'avvio del server. Il valore predefinito è off .
Conclusione
In questo post del blog, abbiamo discusso delle tempistiche in Postgres e di come gestiamo i casi di failover e switchover. Abbiamo anche parlato di come funziona pg_rewind e dei suoi vantaggi per la tolleranza agli errori e l'affidabilità di Postgres. Continueremo con il commit sincrono nel prossimo post del blog.
Riferimenti
Documentazione PostgreSQL
Libro di cucina per l'amministrazione di PostgreSQL 9 – Seconda edizione
pg_rewind Presentazione Nordic PGDay di Heikki Linnakangas



