Stai lavorando con uno sviluppatore che segnala prestazioni lente per la seguente chiamata di stored procedure:
EXEC [dbo].[charge_by_date] '2/28/2013';
Chiedi quale problema sta vedendo lo sviluppatore, ma l'unica informazione aggiuntiva che senti è che "sta funzionando lentamente". Quindi salti sull'istanza di SQL Server e dai un'occhiata a effettivo progetto esecutivo. Lo fai perché sei interessato non solo all'aspetto del piano di esecuzione, ma anche al numero di righe stimato rispetto a quello effettivo per il piano:
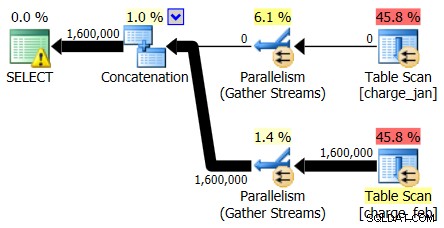
Osservando prima solo gli operatori del piano, puoi vedere alcuni dettagli degni di nota:
- C'è un avviso nell'operatore root
- C'è una scansione della tabella per entrambe le tabelle referenziate a livello foglia (charge_jan e charge_feb) e ti chiedi perché entrambi sono ancora heap e non hanno indici raggruppati
- Vedi che ci sono solo righe che scorrono attraverso la tabella charge_feb e non la tabella charge_jan
- Vedi zone parallele nel piano
Per quanto riguarda l'avviso nell'iteratore radice, passaci sopra con il mouse e vedi che mancano avvisi di indice con una raccomandazione per i seguenti indici:
CREATE NONCLUSTERED INDEX [<Name of Missing Index, sysname,>] ON [dbo].[charge_feb] ([charge_dt]) INCLUDE ([charge_no]) GO CREATE NONCLUSTERED INDEX [<Name of Missing Index, sysname,>] ON [dbo].[charge_jan] ([charge_dt]) INCLUDE ([charge_no]) GO
Chiedi allo sviluppatore del database originale perché non esiste un indice cluster e la risposta è "Non lo so".
Continuando l'indagine prima di apportare modifiche, guardi la scheda Plan Tree in SQL Sentry Plan Explorer e vedi effettivamente che ci sono differenze significative tra le righe stimate rispetto a quelle effettive per una delle tabelle:

Sembra che ci siano due problemi:
- Una sottostima per le righe nella scansione della tabella charge_jan
- Una sovrastima per le righe nella scansione della tabella charge_feb
Quindi le stime di cardinalità sono distorto e ti chiedi se questo è correlato allo sniffing dei parametri. Decidi di controllare il valore compilato del parametro e confrontarlo con il valore di runtime del parametro, che puoi vedere nella scheda Parametri:

In effetti ci sono differenze tra il valore di runtime e il valore compilato. Copiare il database in un ambiente di test simile a un prodotto e quindi testare l'esecuzione della stored procedure con il valore di runtime di 28/02/2013 prima e poi 31/01/2013.
I piani del 28/02/2013 e del 31/01/2013 hanno forme identiche ma flussi di dati effettivi diversi. Il piano del 28/02/2013 e le stime di cardinalità erano le seguenti:
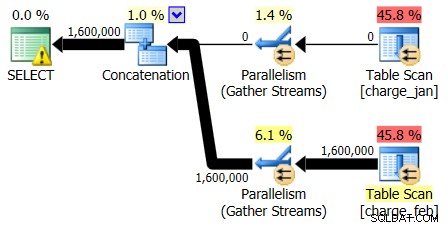

E mentre il piano del 28/02/2013 non mostra problemi di stima della cardinalità, il piano del 31/01/2013:
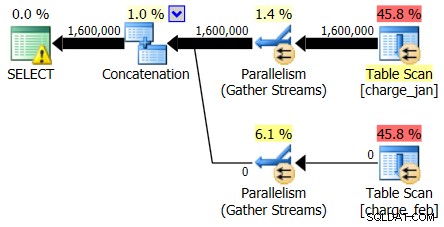

Quindi il secondo piano mostra le stesse sopra e sottostima, solo invertite rispetto al piano originale che hai visto.
Decidi di aggiungere gli indici suggeriti all'ambiente di test simile a prod per entrambe le tabelle charge_jan e charge_feb e vedi se questo aiuta. Eseguendo le stored procedure nell'ordine di gennaio/febbraio, vengono visualizzate le seguenti nuove forme di piano e le stime di cardinalità associate:
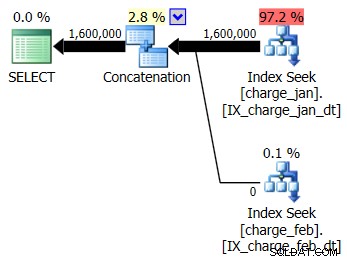

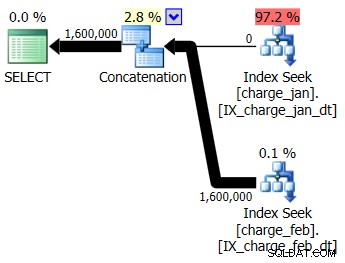

Il nuovo piano utilizza un'operazione di ricerca dell'indice da ciascuna tabella, ma vedi comunque zero righe che scorrono da una tabella e non dall'altra e vedi ancora gli skew della stima della cardinalità in base allo sniffing dei parametri quando il valore di runtime si trova in un mese diverso dalla compilazione valore temporale.
Il tuo team ha una politica di non aggiungere indici senza la prova di un vantaggio sufficiente e dei test di regressione associati. Decidi, per il momento, di rimuovere gli indici non cluster appena creati. Anche se non affronti immediatamente il cluster mancante index, decidi che te ne occuperai in seguito.
A questo punto ti rendi conto che devi approfondire la definizione della procedura memorizzata, che è la seguente:
CREATE PROCEDURE dbo.charge_by_date @charge_dt datetime AS SELECT charge_no FROM dbo.charge_view WHERE charge_dt = @charge_dt GO
Quindi guardi la definizione dell'oggetto charge_view:
CREATE VIEW charge_view AS SELECT * FROM [charge_jan] UNION ALL SELECT * FROM [charge_feb] GO
La vista fa riferimento a dati di addebito separati in tabelle diverse per data. E poi ti chiedi se la seconda distorsione del piano di esecuzione della query può essere evitata modificando la definizione della stored procedure.
Forse se l'ottimizzatore sa in fase di esecuzione qual è il valore, il problema della stima della cardinalità scomparirà e migliorerà le prestazioni complessive?
Vai avanti e ridefinisci la chiamata alla procedura memorizzata come segue, aggiungendo un suggerimento RECOMPILE (sapere che hai anche sentito che questo può aumentare l'utilizzo della CPU, ma poiché questo è un ambiente di test, ti senti sicuro di provarlo):
ALTER PROCEDURE charge_by_date @charge_dt datetime AS SELECT charge_no FROM dbo.charge_view WHERE charge_dt = @charge_dt OPTION (RECOMPILE); GO
Quindi eseguire nuovamente la procedura memorizzata utilizzando il valore 31/01/2013 e quindi il valore 28/2/2013.
La forma del piano rimane la stessa, ma ora il problema della stima della cardinalità è stato rimosso.
I dati della stima della cardinalità del 31/1/2013 mostrano:

E i dati della stima della cardinalità del 28/02/2013 mostrano:

Questo ti rende felice per un momento, ma poi ti rendi conto che la durata dell'esecuzione complessiva della query sembra relativamente la stessa di prima. Inizi a dubitare che lo sviluppatore sarà soddisfatto dei tuoi risultati. Hai risolto lo squilibrio della stima della cardinalità, ma senza l'aumento previsto delle prestazioni non sei sicuro di aver contribuito in modo significativo.
È a questo punto che ti rendi conto che il piano di esecuzione della query è solo un sottoinsieme delle informazioni di cui potresti aver bisogno, quindi espandi ulteriormente la tua esplorazione guardando la scheda I/O tabella. Viene visualizzato il seguente output per l'esecuzione del 31/01/2013:

E per l'esecuzione del 28/02/2013 vedi dati simili:

È a quel punto che ti chiedi se le operazioni di accesso ai dati per entrambi le tabelle sono necessarie in ogni piano. Se l'ottimizzatore sa che hai bisogno solo di righe di gennaio, perché accedere a febbraio e viceversa? Ricordi anche che Query Optimizer non ha garanzie che non ci siano righe effettive degli altri mesi nella tabella "sbagliata" a meno che tali garanzie non siano state fornite esplicitamente tramite vincoli sulla tabella stessa.
Puoi controllare le definizioni delle tabelle tramite sp_help per ciascuna tabella e non vedi alcun vincolo definito per nessuna delle due tabelle.
Quindi, come test, aggiungi i seguenti due vincoli:
ALTER TABLE [dbo].[charge_jan] ADD CONSTRAINT charge_jan_chk CHECK (charge_dt >= '1/1/2013' AND charge_dt < '2/1/2013'); GO ALTER TABLE [dbo].[charge_feb] ADD CONSTRAINT charge_feb_chk CHECK (charge_dt >= '2/1/2013' AND charge_dt < '3/1/2013'); GO
Eseguire nuovamente le stored procedure e visualizzare le seguenti forme di piano e stime di cardinalità.
31/01/2013 esecuzione:
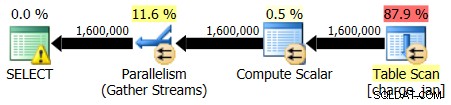

28/02/2013 esecuzione:


Esaminando nuovamente Table I/O, viene visualizzato il seguente output per l'esecuzione del 31/1/2013:

E per l'esecuzione del 28/02/2013 vedi dati simili, ma per la tabella charge_feb:

Ricordando che hai il RECOMPILE ancora nella definizione della procedura memorizzata, provi a rimuoverlo e vedere se vedi lo stesso effetto. Dopo aver eseguito questa operazione, viene visualizzato l'accesso a due tabelle restituito, ma senza letture logiche effettive per la tabella che non contiene righe (rispetto al piano originale senza i vincoli). Ad esempio, l'esecuzione del 31/1/2013 ha mostrato il seguente output di I/O della tabella:

Decidi di procedere con il test di carico dei nuovi vincoli CHECK e della soluzione RECOMPILE, rimuovendo completamente l'accesso alla tabella dal piano (e dagli operatori di piano associati). Ti prepari anche per un dibattito sulla chiave dell'indice cluster e un indice non cluster di supporto adatto che ospiterà un insieme più ampio di carichi di lavoro che attualmente accedono alle tabelle associate.