Ho avuto il piacere di partecipare al PGDay UK la scorsa settimana:un evento molto bello, spero di avere la possibilità di tornare l'anno prossimo. Ci sono stati molti discorsi interessanti, ma quello che ha attirato la mia attenzione in particolare è stato Performace for query con raggruppamento di Alexey Bashtanov.
Ho tenuto un discreto numero di discorsi simili orientati alle prestazioni in passato, quindi so quanto sia difficile presentare i risultati del benchmark in un modo comprensibile e interessante, e penso che Alexey abbia fatto un ottimo lavoro. Quindi, se ti occupi di aggregazione di dati (ad esempio BI, analisi o carichi di lavoro simili), ti consiglio di sfogliare le diapositive e se hai la possibilità di partecipare al discorso di un'altra conferenza, ti consiglio vivamente di farlo.
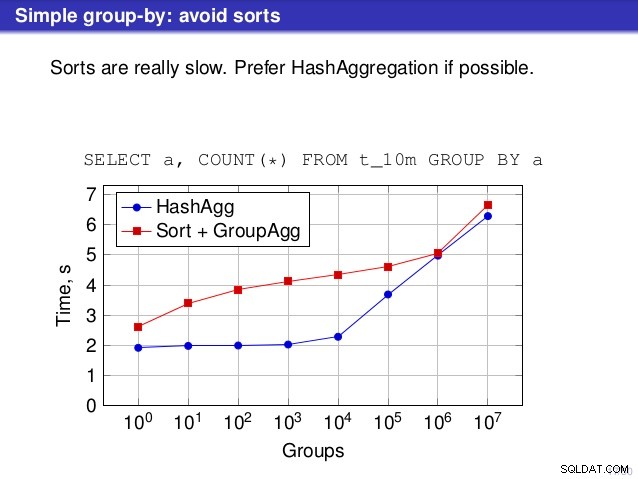
Ma c'è un punto in cui non sono d'accordo con il discorso, però. In diversi punti il discorso ha suggerito che in genere dovresti preferire HashAggregate, perché gli ordinamenti sono lenti.
Lo considero un po 'fuorviante, perché un'alternativa a HashAggregate è GroupAggregate, non Sort. Quindi la raccomandazione presuppone che ogni GroupAggregate abbia un ordinamento nidificato, ma non è del tutto vero. GroupAggregate richiede un input ordinato e un ordinamento esplicito non è l'unico modo per farlo:abbiamo anche i nodi IndexScan e IndexOnlyScan, che eliminano i costi di ordinamento e mantengono gli altri vantaggi associati ai percorsi ordinati (in particolare IndexOnlyScan).
Lascia che ti mostri come si comporta (IndexOnlyScan+GroupAggregate) rispetto a HashAggregate e (Sort+GroupAggregate):lo script che ho usato per le misurazioni è qui. Crea quattro semplici tabelle, ciascuna con 100 milioni di righe e un numero diverso di gruppi nella colonna "branch_id" (che determina la dimensione della tabella hash). Il più piccolo ha 10.000 gruppi
-- table with 10k groups create table t_10000 (branch_id bigint, amount numeric); insert into t_10000 select mod(i, 10000), random() from generate_series(1,100000000) s(i);
e tre tavoli aggiuntivi hanno gruppi da 100k, 1M e 5M. Eseguiamo questa semplice query aggregando i dati:
SELECT branch_id, SUM(amount) FROM t_10000 GROUP BY 1
e quindi convincere il database a utilizzare tre diversi piani:
1) Aggregato hash
SET enable_sort = off;
SET enable_hashagg = on;
EXPLAIN SELECT branch_id, SUM(amount) FROM t_10000 GROUP BY 1;
QUERY PLAN
----------------------------------------------------------------------------
HashAggregate (cost=2136943.00..2137067.99 rows=9999 width=40)
Group Key: branch_id
-> Seq Scan on t_10000 (cost=0.00..1636943.00 rows=100000000 width=19)
(3 rows) 2) GroupAggregate (con un ordinamento)
SET enable_sort = on;
SET enable_hashagg = off;
EXPLAIN SELECT branch_id, SUM(amount) FROM t_10000 GROUP BY 1;
QUERY PLAN
-------------------------------------------------------------------------------
GroupAggregate (cost=16975438.38..17725563.37 rows=9999 width=40)
Group Key: branch_id
-> Sort (cost=16975438.38..17225438.38 rows=100000000 width=19)
Sort Key: branch_id
-> Seq Scan on t_10000 (cost=0.00..1636943.00 rows=100000000 ...)
(5 rows) 3) GroupAggregate (con un IndexOnlyScan)
SET enable_sort = on;
SET enable_hashagg = off;
CREATE INDEX ON t_10000 (branch_id, amount);
EXPLAIN SELECT branch_id, SUM(amount) FROM t_10000 GROUP BY 1;
QUERY PLAN
--------------------------------------------------------------------------
GroupAggregate (cost=0.57..3983129.56 rows=9999 width=40)
Group Key: branch_id
-> Index Only Scan using t_10000_branch_id_amount_idx on t_10000
(cost=0.57..3483004.57 rows=100000000 width=19)
(3 rows) Risultati
Dopo aver misurato i tempi per ogni piano su tutti i tavoli, i risultati si presentano così:
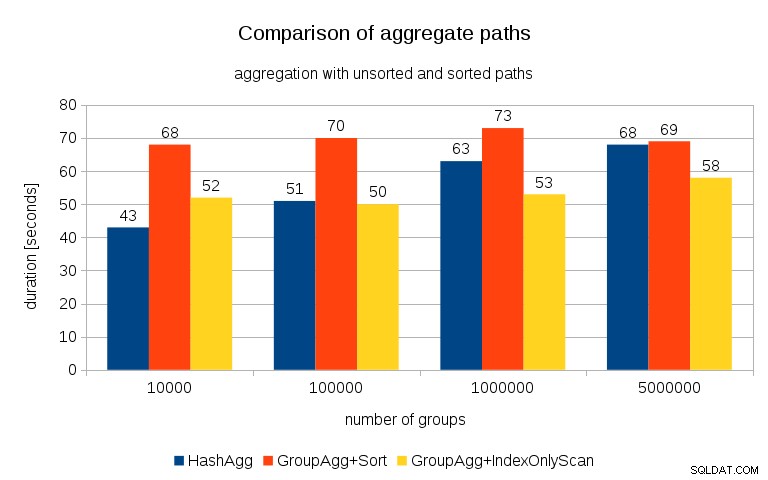
Per le tabelle hash di piccole dimensioni (che si adattano alla cache L3, che in questo caso è 16 MB), il percorso HashAggregate è chiaramente più veloce di entrambi i percorsi ordinati. Ma ben presto GroupAgg+IndexOnlyScan diventa altrettanto veloce o addirittura più veloce:ciò è dovuto all'efficienza della cache, il principale vantaggio di GroupAggregate. Mentre HashAggregate deve mantenere l'intera tabella hash in memoria in una volta, GroupAggregate deve mantenere solo l'ultimo gruppo. E meno memoria usi, più è probabile che la inserisca nella cache L3, che è all'incirca un ordine di grandezza più veloce rispetto alla RAM normale (per le cache L1/L2 la differenza è ancora maggiore).
Quindi, sebbene ci sia un notevole sovraccarico associato a IndexOnlyScan (per il caso di 10k è circa il 20% più lento del percorso HashAggregate), man mano che la tabella hash cresce, il rapporto di hit della cache L3 diminuisce rapidamente e la differenza alla fine rende GroupAggregate più veloce. E alla fine anche GroupAggregate+Sort diventa alla pari con il percorso HashAggregate.
Potresti obiettare che i tuoi dati generalmente hanno un numero piuttosto basso di gruppi e quindi la tabella hash si adatterà sempre alla cache L3. Ma considera che la cache L3 è condivisa da tutti i processi in esecuzione sulla CPU e anche da tutte le parti del piano di query. Quindi, sebbene al momento disponiamo di circa 20 MB di cache L3 per socket, la tua query ne riceverà solo una parte e quel bit sarà condiviso da tutti i nodi nella tua query (forse piuttosto complessa).
Aggiornamento 26/07/2016 :Come sottolineato nei commenti di Peter Geoghegan, il modo in cui i dati sono stati generati risulta probabilmente in correlazione – non i valori (o meglio gli hash dei valori), ma le allocazioni di memoria. Ho ripetuto le query con dati correttamente randomizzati, ovvero facendo
insert into t_10000 select (10000*random())::bigint, random() from generate_series(1,100000000) s(i);
invece di
insert into t_10000 select mod(i, 10000), random() from generate_series(1,100000000) s(i);
e i risultati si presentano così:
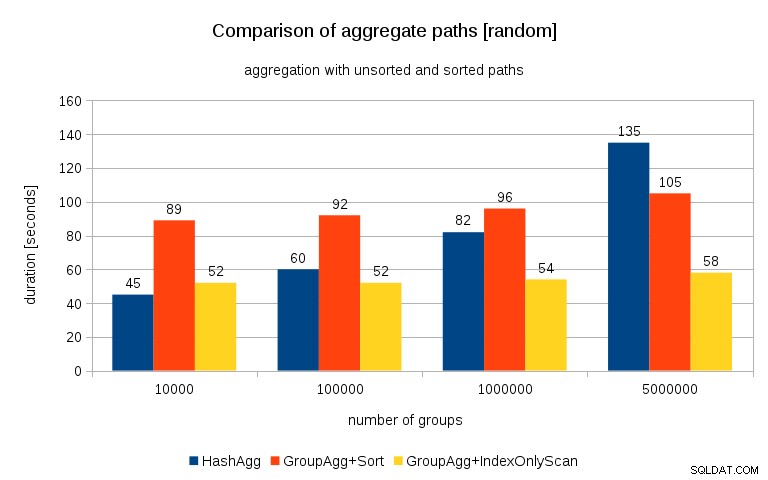
Confrontandolo con il grafico precedente, penso che sia abbastanza chiaro che i risultati sono ancora più a favore di percorsi ordinati, in particolare per il set di dati con gruppi da 5 milioni. Il set di dati 5M mostra anche che GroupAgg con un ordinamento esplicito potrebbe essere più veloce di HashAgg.
Riepilogo
Sebbene HashAggregate sia probabilmente più veloce di GroupAggregate con un ordinamento esplicito (sono riluttante a dire che è sempre così), l'utilizzo più rapido di GroupAggregate con IndexOnlyScan può renderlo molto più veloce di HashAggregate.
Naturalmente, non puoi scegliere direttamente il piano esatto:il pianificatore dovrebbe farlo per te. Ma influisci sul processo di selezione (a) creando indici e (b) impostando work_mem . Ecco perché a volte abbassa work_mem (e maintenance_work_mem ) i valori si traducono in prestazioni migliori.
Tuttavia, gli indici aggiuntivi non sono gratuiti:costano sia il tempo della CPU (quando si inseriscono nuovi dati) sia lo spazio su disco. Per IndexOnlyScans i requisiti di spazio su disco possono essere piuttosto significativi perché l'indice deve includere tutte le colonne a cui fa riferimento la query e IndexScan normale non ti darebbe le stesse prestazioni in quanto genera molti I/O casuali sulla tabella (eliminando tutti i potenziali guadagni).
Un'altra caratteristica interessante è la stabilità delle prestazioni:nota come i tempi di HashAggregate cambiano a seconda del numero di gruppi, mentre i percorsi GroupAggregate funzionano per lo più allo stesso modo.