La maggior parte dei carichi di lavoro OLTP implica l'utilizzo casuale dell'I/O del disco. Sapendo che i dischi (incluso l'SSD) hanno prestazioni più lente rispetto all'utilizzo della RAM, i sistemi di database utilizzano la memorizzazione nella cache per aumentare le prestazioni. La memorizzazione nella cache consiste nell'archiviazione dei dati in memoria (RAM) per un accesso più rapido in un secondo momento.
PostgreSQL utilizza anche la memorizzazione nella cache dei suoi dati in uno spazio chiamato shared_buffers. In questo blog esploreremo questa funzionalità per aiutarti ad aumentare le prestazioni.
Nozioni di base sulla memorizzazione nella cache di PostgreSQL
Prima di approfondire il concetto di memorizzazione nella cache, diamo un'occhiata alle nozioni di base.
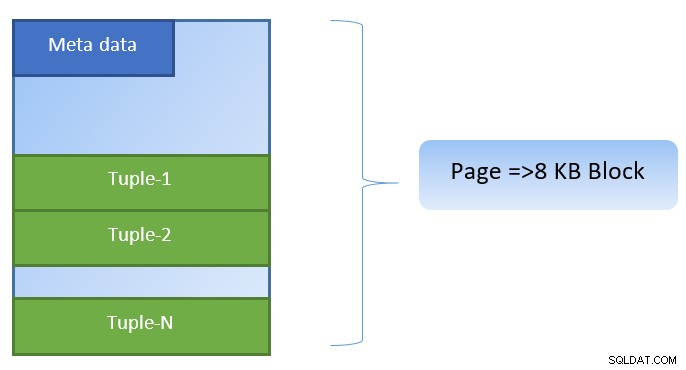
In PostgreSQL, i dati sono organizzati sotto forma di pagine di dimensione 8KB e ciascuna di queste pagine può contenere più tuple (a seconda della dimensione della tupla). Una rappresentazione semplicistica potrebbe essere la seguente:
PostgreSQL memorizza nella cache quanto segue per accelerare l'accesso ai dati:
- Dati nelle tabelle
- Indici
- Piani di esecuzione delle query
Mentre la memorizzazione nella cache del piano di esecuzione della query si concentra sul salvataggio dei cicli della CPU; la memorizzazione nella cache dei dati della tabella e dei dati dell'indice è mirata a risparmiare costose operazioni di I/O del disco.
PostgreSQL consente agli utenti di definire quanta memoria vorrebbe riservare per mantenere tale cache per i dati. L'impostazione pertinente è shared_buffers nel file di configurazione postgresql.conf. Il valore finito di shared_buffers definisce quante pagine possono essere memorizzate nella cache in qualsiasi momento.
Quando viene eseguita una query, PostgreSQL cerca la pagina sul disco che contiene la tupla pertinente e la inserisce nella cache shared_buffers per l'accesso laterale. La prossima volta che sarà necessario accedere alla stessa tupla (oa qualsiasi tupla nella stessa pagina), PostgreSQL può salvare l'IO del disco leggendolo in memoria.
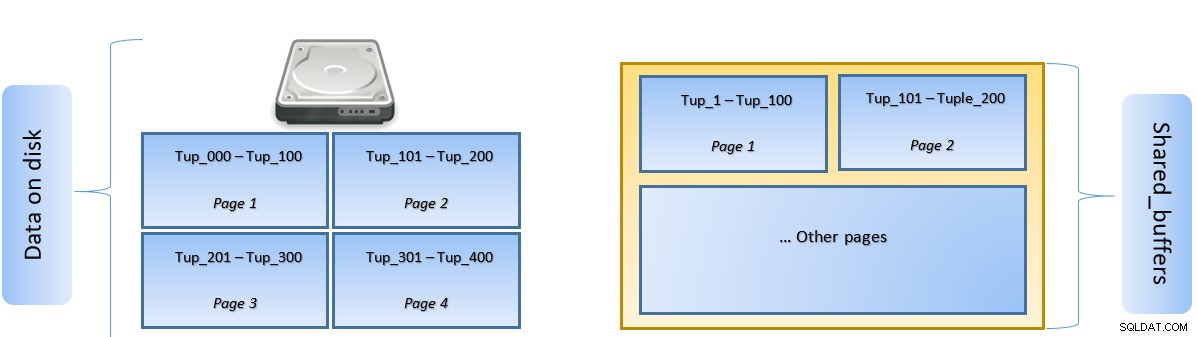
Nella figura sopra, Pagina-1 e Pagina-2 di un determinato la tabella è stata memorizzata nella cache. Nel caso in cui una query utente debba accedere a tuple tra Tuple-1 e Tuple-200, PostgreSQL può recuperarlo dalla RAM stessa.
Tuttavia, se la query deve accedere alle Tuple da 250 a 350, dovrà eseguire l'I/O del disco per Pagina 3 e Pagina 4. Qualsiasi ulteriore accesso per Tuple da 201 a 400 verrà recuperato dalla cache e l'I/O del disco non sarà necessario, rendendo così la query più veloce.
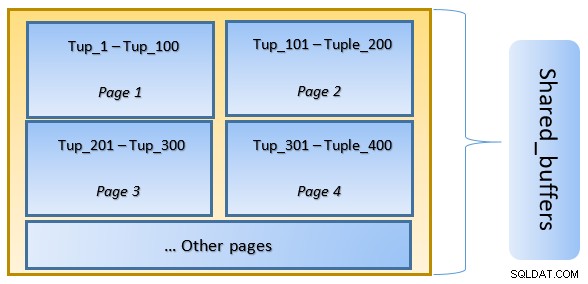
Ad alto livello, PostgreSQL segue l'algoritmo LRU (utilizzato di recente) per identificare le pagine che devono essere eliminate dalla cache. In altre parole, una pagina a cui si accede solo una volta ha maggiori possibilità di sfratto (rispetto a una pagina a cui si accede più volte), nel caso in cui una nuova pagina debba essere recuperata da PostgreSQL nella cache.
Memorizzazione nella cache PostgreSQL in azione
Eseguiamo un esempio e vediamo l'impatto della cache sulle prestazioni.
Avvia PostgreSQL mantenendo shared_buffer impostato su 128 MB predefinito
$ initdb -D ${HOME}/data
$ echo “shared_buffers=128MB” >> ${HOME}/data/postgresql.conf
$ pg_ctl -D ${HOME}/data startConnettiti al server e crea una tabella fittizia tblDummy e un indice su c_id
CREATE Table tblDummy
(
id serial primary key,
p_id int,
c_id int,
entry_time timestamp,
entry_value int,
description varchar(50)
);
CREATE INDEX ON tblDummy(c_id );Popola dati fittizi con 200000 tuple, in modo tale che ci siano 10000 p_id univoci e per ogni p_id ci siano 200 c_id
DO $$
DECLARE
random_value integer:= 1;
BEGIN
FOR p_id_ctr IN 1..10000 BY 1 LOOP
FOR c_id_ctr IN 1..200 BY 1 LOOP
random_value = (( random() * 75 ) + 25);
INSERT INTO tblDummy (p_id,c_id,entry_time, entry_value, description )
VALUES (p_id_ctr,c_id_ctr,'now', random_value, CONCAT('Description for :',p_id_ctr, c_id_ctr));
END LOOP ;
END LOOP ;
END $$;Riavvia il server per svuotare la cache. Ora esegui una query e controlla il tempo impiegato per eseguirla
SELECT pg_stat_reset();
EXPLAIN ANAYZE SELECT count(*) from tbldummy where c_id=1;
QUERY PLAN
--------------------------------------------------------------
Aggregate (cost=17407.33..17407.34 rows=1 width=8) (actual time=160.269..160.269 rows=1 loops=1)
-> Bitmap Heap Scan on tbldummy (cost=189.52..17382.46 rows=9948 width=0) (actual time=10.627..156.275 rows=10000 loops=1)
Recheck Cond: (c_id = 1)
Heap Blocks: exact=10000
-> Bitmap Index Scan on tbldummy_c_id_idx (cost=0.00..187.04 rows=9948 width=0) (actual time=5.091..5.091 rows=10000 loops=1)
Index Cond: (c_id = 1)
Planning Time: 1.325 ms
Execution Time: 160.505 msQuindi controlla i blocchi letti dal disco
SELECT heap_blks_read, heap_blks_hit from pg_statio_user_tables where relname='tbldummy';
heap_blks_read | heap_blks_hit
---------------+---------------
10000 | 0Nell'esempio sopra, c'erano 1000 blocchi letti dal disco per trovare le tuple di conteggio dove c_id =1. Ci sono voluti 160 ms da quando era coinvolto l'I/O del disco per recuperare quei record dal disco.
L'esecuzione è più veloce se la stessa query viene rieseguita, poiché tutti i blocchi sono ancora nella cache del server PostgreSQL in questa fase
SELECT pg_stat_reset();
EXPLAIN ANAYZE SELECT count(*) from tbldummy where c_id=1;
QUERY PLAN
-------------------------------------------------------------------------------------
Aggregate (cost=17407.33..17407.34 rows=1 width=8) (actual time=33.760..33.761 rows=1 loops=1)
-> Bitmap Heap Scan on tbldummy (cost=189.52..17382.46 rows=9948 width=0) (actual time=9.584..30.576 rows=10000 loops=1)
Recheck Cond: (c_id = 1)
Heap Blocks: exact=10000
-> Bitmap Index Scan on tbldummy_c_id_idx (cost=0.00..187.04 rows=9948 width=0) (actual time=4.314..4.314 rows=10000 loops=1)
Index Cond: (c_id = 1)
Planning Time: 0.106 ms
Execution Time: 33.990 mse blocchi letti dal disco rispetto alla cache
SELECT heap_blks_read, heap_blks_hit from pg_statio_user_tables where relname='tbldummy';
heap_blks_read | heap_blks_hit
---------------+---------------
0 | 10000È evidente dall'alto che poiché tutti i blocchi sono stati letti dalla cache e non è stato richiesto alcun I/O del disco. Questo quindi ha anche dato i risultati più velocemente.
Impostazione della dimensione della cache PostgreSQL
La dimensione della cache deve essere ottimizzata in un ambiente di produzione in base alla quantità di RAM disponibile e alle query che devono essere eseguite.
Ad esempio, shared_buffer di 128 MB potrebbe non essere sufficiente per memorizzare nella cache tutti i dati, se la query dovesse recuperare più tuple:
SELECT pg_stat_reset();
SELECT count(*) from tbldummy where c_id < 150;
SELECT heap_blks_read, heap_blks_hit from pg_statio_user_tables where relname='tbldummy';
heap_blks_read | heap_blks_hit
----------------+---------------
20331 | 288Cambia shared_buffer a 1024 MB per aumentare heap_blks_hit.
In effetti, considerando le query (basate su c_id), nel caso in cui i dati vengano riorganizzati, è possibile ottenere un migliore rapporto di hit della cache anche con un shared_buffer più piccolo.
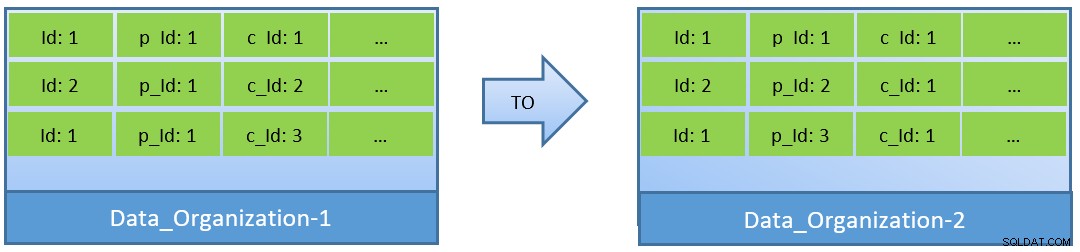
In Data_Organization-1, PostgreSQL avrà bisogno di 1000 letture di blocchi (e consumo di cache ) per trovare c_id=1. D'altra parte, per Data_Organization-2, per la stessa query, PostgreSQL avrà bisogno solo di 104 blocchi.
Meno blocchi richiesti per la stessa query alla fine consumano meno cache e mantengono anche il tempo di esecuzione della query ottimizzato.
Conclusione
Sebbene shared_buffer sia mantenuto a livello di processo PostgreSQL, viene presa in considerazione anche la cache a livello di kernel per identificare piani di esecuzione delle query ottimizzati. Tratterò questo argomento in una serie successiva di blog.