In un blog precedente, abbiamo annunciato una nuova funzionalità ClusterControl 1.7.4 chiamata Replica da cluster a cluster. Automatizza l'intero processo di configurazione di un cluster di ripristino di emergenza dal cluster principale, con la replica nel mezzo. Per informazioni più dettagliate si prega di fare riferimento al post di blog sopra menzionato.
Ora, in questo blog, daremo un'occhiata a come configurare questa nuova funzionalità per un cluster esistente. Per questa attività, assumeremo che ClusterControl sia installato e che il cluster master sia stato distribuito utilizzandolo.
Requisiti per il Master Cluster
Ci sono alcuni requisiti per il Master Cluster per farlo funzionare:
- Percona XtraDB Cluster versione 5.6.xe successive, o MariaDB Galera Cluster versione 10.xe successive.
- GTID abilitato.
- Registrazione binaria abilitata su almeno un nodo del database.
- Le credenziali di backup devono essere le stesse nel cluster master e nel cluster slave.
Preparazione del cluster principale
Il Master Cluster deve essere preparato per utilizzare questa nuova funzionalità. Richiede la configurazione sia dal lato ClusterControl che dal lato Database.
Configurazione ClusterControl
Nel nodo del database, controlla le credenziali dell'utente di backup memorizzate in /etc/my.cnf.d/secrets-backup.cnf (per OS basato su RedHat) o in /etc/mysql/secrets-backup .cnf (per sistemi operativi basati su Debian).
$ cat /etc/my.cnf.d/secrets-backup.cnf
# Security credentials for backup.
[mysqldump]
user=backupuser
password=cYj0GFBEdqdreZEl
[xtrabackup]
user=backupuser
password=cYj0GFBEdqdreZEl
[mysqld]
wsrep_sst_auth=backupuser:cYj0GFBEdqdreZElNel nodo ClusterControl, modifica il file di configurazione /etc/cmon.d/cmon_ID.cnf (dove ID è il numero ID del cluster) e assicurati che contenga le stesse credenziali memorizzate in secrets-backup. cfr.
$ cat /etc/cmon.d/cmon_8.cnf
backup_user=backupuser
backup_user_password=cYj0GFBEdqdreZEl
basedir=/usr
cdt_path=/
cluster_id=8
...Qualsiasi modifica su questo file richiede un riavvio del servizio cmon:
$ service cmon restartControlla i parametri di replica del database per assicurarti di avere GTID e registrazione binaria abilitati.
Configurazione database
Nel nodo database, controllare il file /etc/my.cnf (per OS basato su RedHat) o /etc/mysql/my.cnf (per OS basato su Debian) per vedere la configurazione relativa al processo di replica.
Percona XtraDB:
$ cat /etc/my.cnf
# REPLICATION SPECIFIC
server_id=4002
binlog_format=ROW
log_bin = /var/lib/mysql-binlog/binlog
log_slave_updates = ON
gtid_mode = ON
enforce_gtid_consistency = true
relay_log = relay-log
expire_logs_days = 7Gruppo MariaDB Galera:
$ cat /etc/my.cnf
# REPLICATION SPECIFIC
server_id=9000
binlog_format=ROW
log_bin = /var/lib/mysql-binlog/binlog
log_slave_updates = ON
relay_log = relay-log
wsrep_gtid_domain_id=9000
wsrep_gtid_mode=ON
gtid_domain_id=9000
gtid_strict_mode=ON
gtid_ignore_duplicates=ON
expire_logs_days = 7Invece controllando i file di configurazione, puoi verificare se è abilitato nell'interfaccia utente di ClusterControl. Vai a ClusterControl -> Seleziona Cluster -> Nodi. Lì dovresti avere qualcosa del genere:

Il ruolo "Master" aggiunto nel primo nodo significa che il Binary Logging è abilitato.
Abilitazione registrazione binaria
Se non hai abilitato la registrazione binaria, vai su ClusterControl -> Seleziona Cluster -> Nodi -> Azioni nodo -> Abilita registrazione binaria.
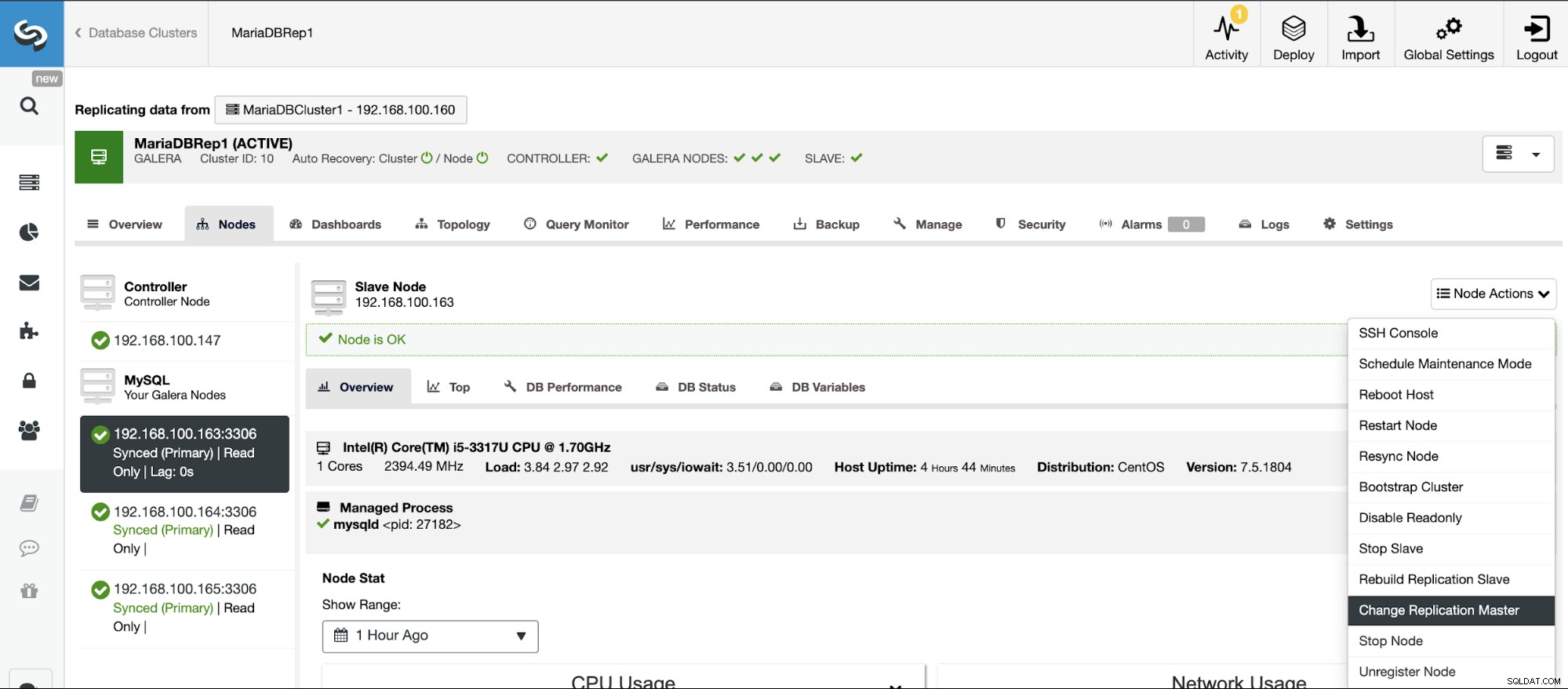
Quindi, devi specificare la conservazione del log binario e il percorso da archiviare esso. Dovresti anche specificare se desideri che ClusterControl riavvii il nodo del database dopo averlo configurato o se preferisci riavviarlo da solo.
Tieni presente che l'abilitazione della registrazione binaria richiede sempre il riavvio del servizio database .
Creazione del cluster slave dalla GUI ClusterControl
Per creare un nuovo cluster slave, vai su ClusterControl -> Seleziona cluster -> Azioni cluster -> Crea cluster slave.
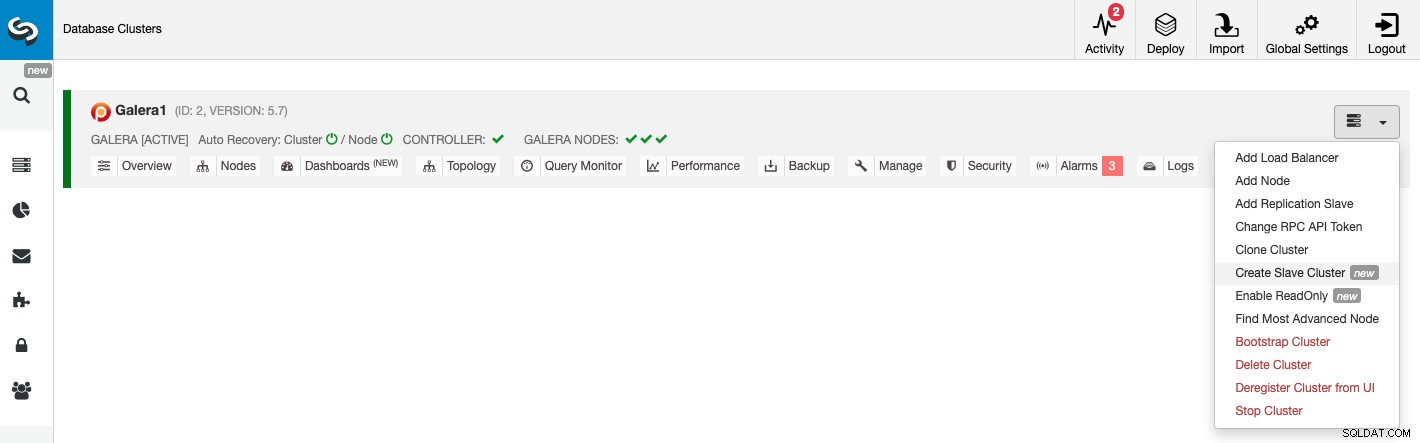
Il Cluster Slave può essere creato eseguendo lo streaming dei dati dal Master Cluster corrente o utilizzando un backup esistente.
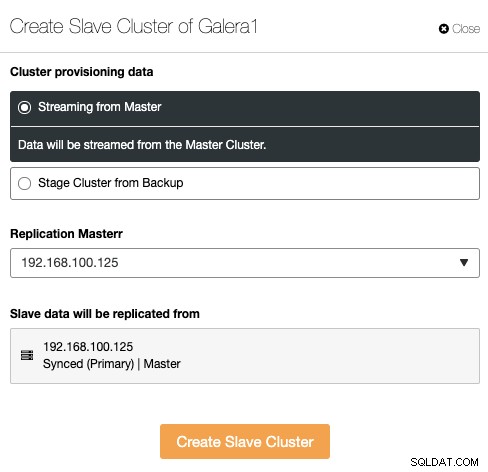
In questa sezione, devi anche scegliere il nodo master del cluster corrente da cui verranno replicati i dati.
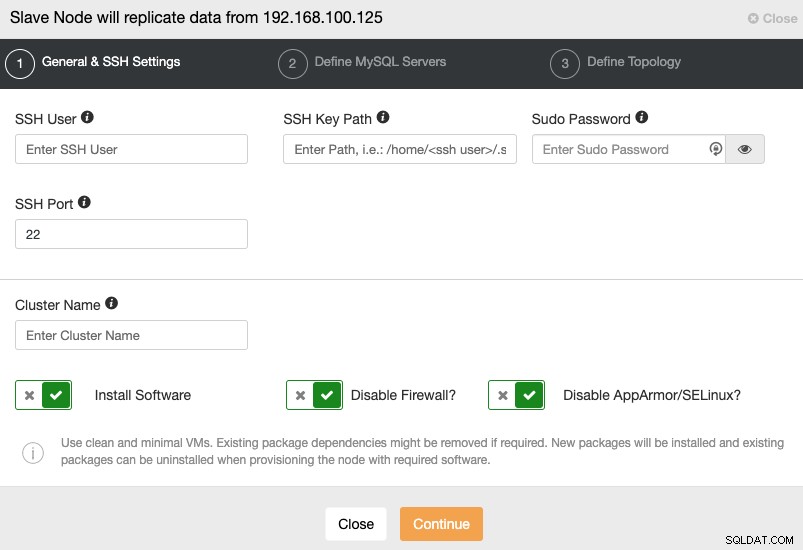
Quando vai al passaggio successivo, devi specificare Utente, Chiave o Password e porta per connetterti tramite SSH ai tuoi server. Hai anche bisogno di un nome per il tuo Cluster Slave e se vuoi che ClusterControl installi per te il software e le configurazioni corrispondenti.
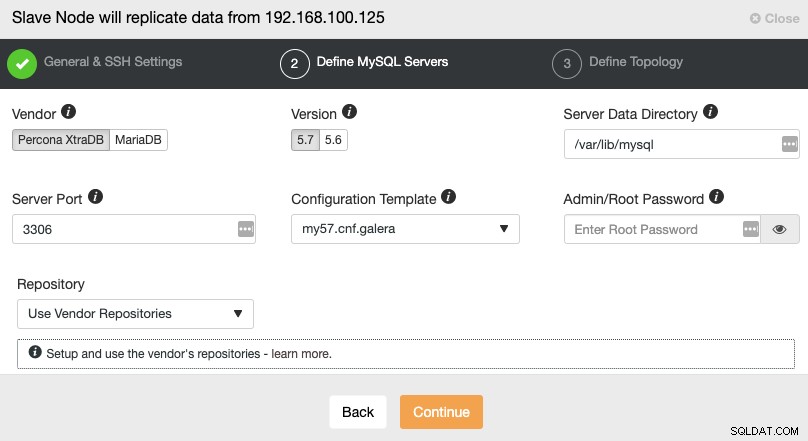
Dopo aver impostato le informazioni di accesso SSH, è necessario definire il fornitore del database e versione, datadir, porta del database e la password dell'amministratore. Assicurati di utilizzare lo stesso fornitore/versione e le stesse credenziali utilizzate dal cluster master. Puoi anche specificare quale repository utilizzare.
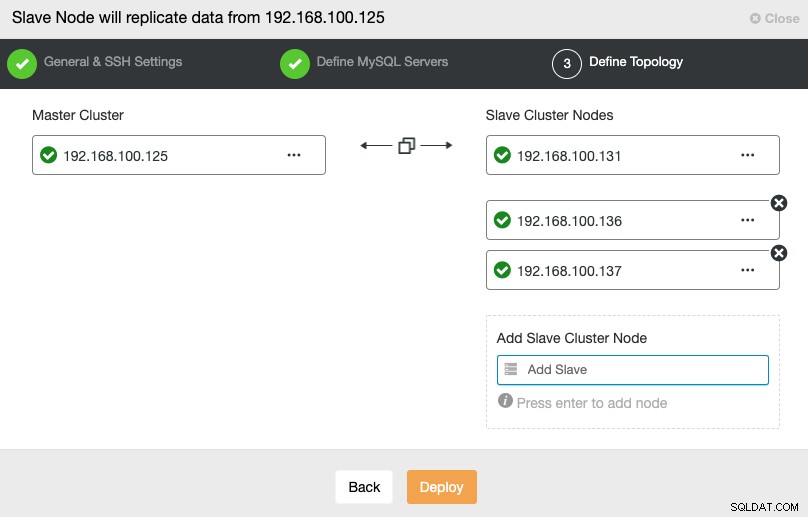
In questo passaggio, è necessario aggiungere server al nuovo cluster slave. Per questa attività, puoi inserire sia l'indirizzo IP che il nome host di ciascun nodo del database.
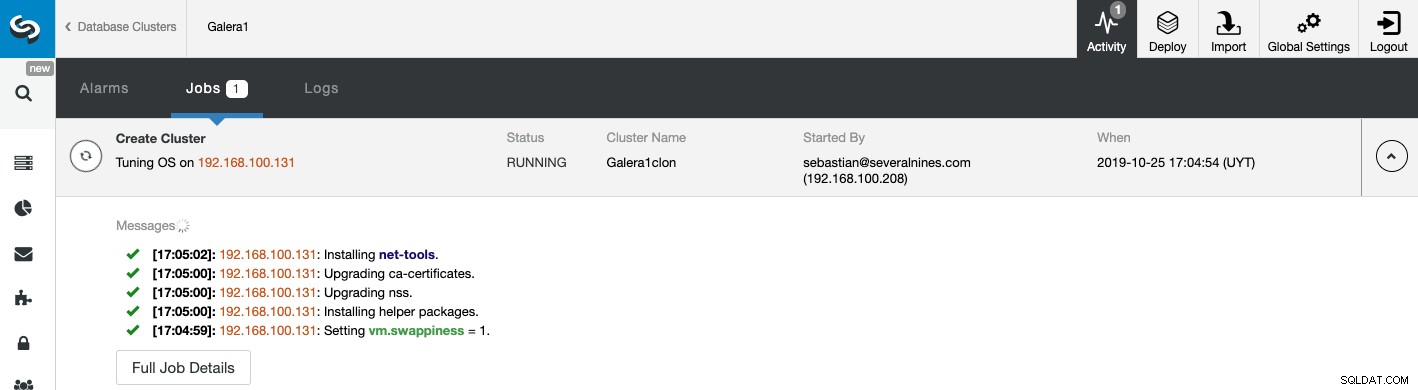
Puoi monitorare lo stato della creazione del tuo nuovo Slave Cluster dal Monitoraggio attività ClusterControl. Al termine dell'attività, puoi vedere il cluster nella schermata principale di ClusterControl.
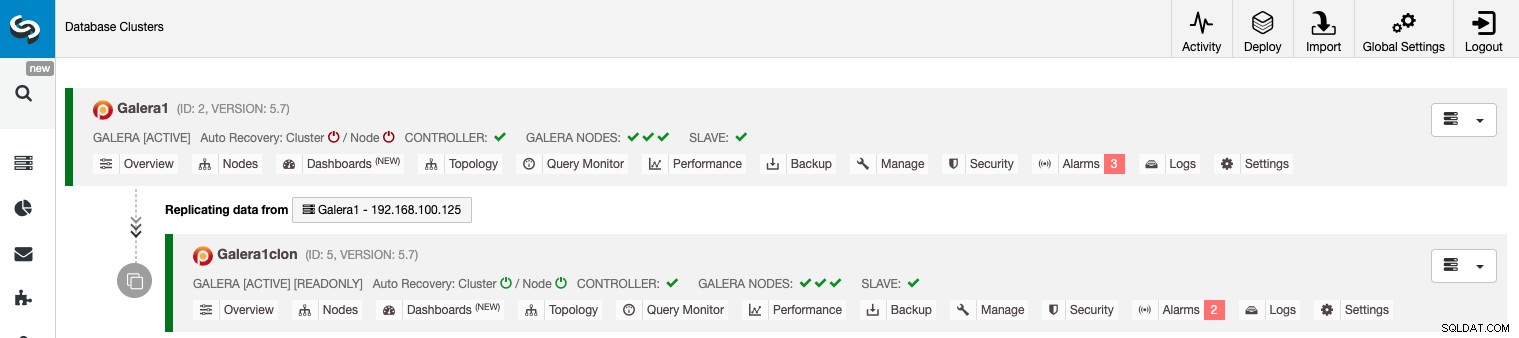
Gestione della replica da cluster a cluster utilizzando la GUI ClusterControl
Ora che la replica da cluster a cluster è attiva e funzionante, ci sono diverse azioni da eseguire su questa topologia utilizzando ClusterControl.
Configura cluster attivo-attivo
Come puoi vedere, per impostazione predefinita lo Slave Cluster è impostato in modalità di sola lettura. È possibile disabilitare il flag di sola lettura sui nodi uno per uno dall'interfaccia utente di ClusterControl, ma tieni presente che il clustering attivo-attivo è consigliato solo se le applicazioni toccano solo set di dati disgiunti su entrambi i cluster poiché MySQL/MariaDB non lo fa offrire qualsiasi rilevamento o risoluzione dei conflitti.
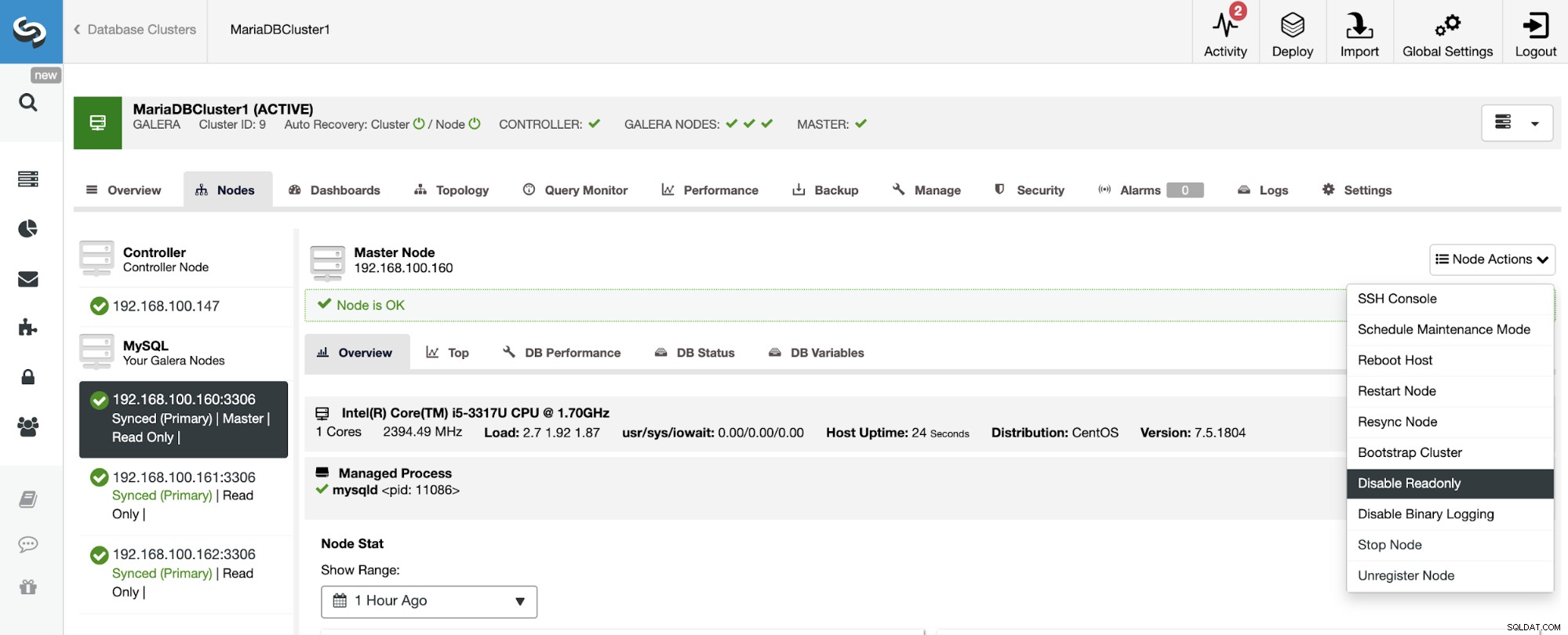
Per disabilitare la modalità di sola lettura, vai su ClusterControl -> Seleziona slave Cluster -> Nodi. In questa sezione, seleziona ciascun nodo e utilizza l'opzione Disattiva sola lettura.
Ricostruire un cluster di schiavi
Per evitare incongruenze, se vuoi ricostruire un cluster slave, questo deve essere un cluster di sola lettura, ciò significa che tutti i nodi devono essere in modalità di sola lettura.
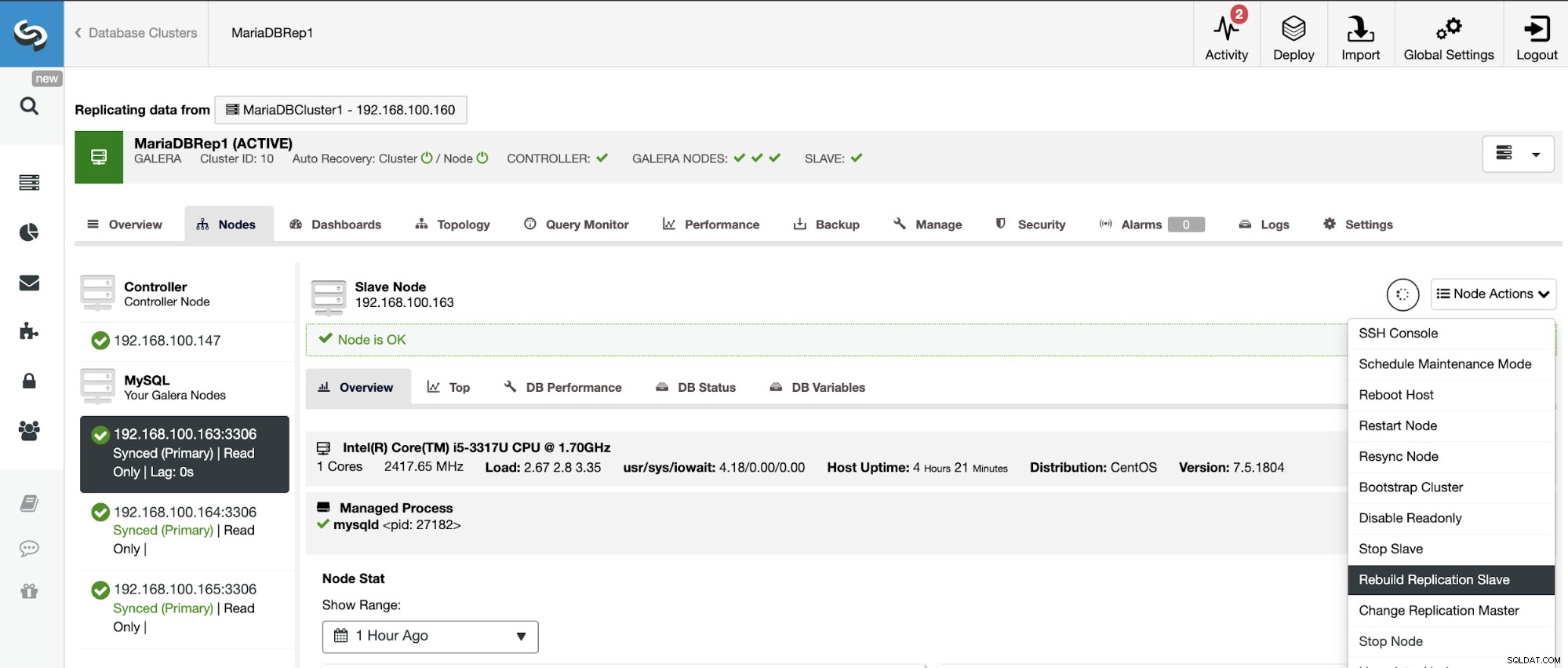
Vai a ClusterControl -> Seleziona cluster slave -> Nodi -> Scegli il Nodo connesso al Master Cluster -> Azioni Nodo -> Ricostruisci Replica Slave.
Modifiche alla topologia
Se hai la seguente topologia:
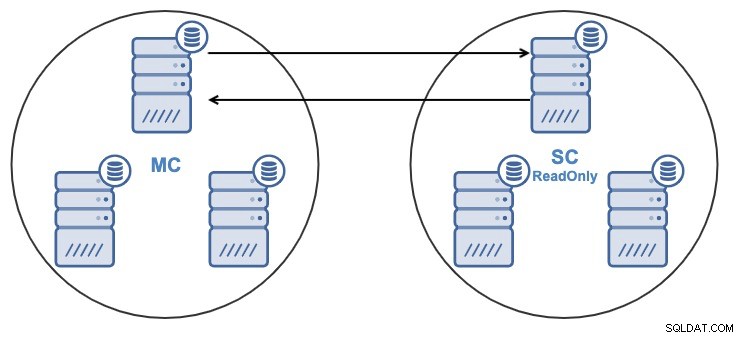
E per qualche motivo, vuoi cambiare il nodo di replica nel Master Grappolo. È possibile cambiare il nodo master utilizzato dal Cluster Slave con un altro nodo master nel Cluster Master.
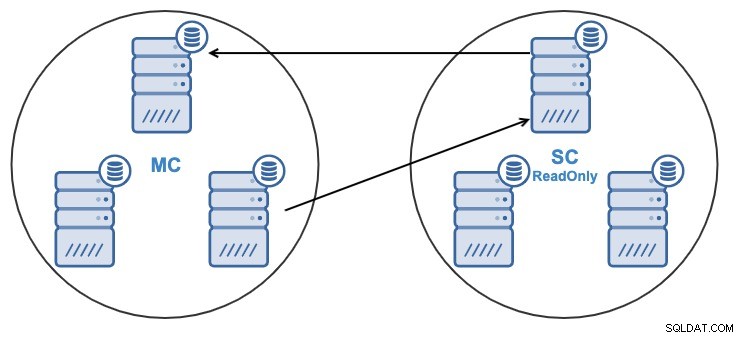
Per essere considerato un nodo master, deve avere la registrazione binaria abilitata .
Vai a ClusterControl -> Seleziona cluster slave -> Nodi -> Scegli il Nodo connesso al Master Cluster -> Node Actions -> Stop Slave/Start Slave.
Arresta/Avvia slave replica
Puoi arrestare e avviare gli slave di replica in modo semplice utilizzando ClusterControl.
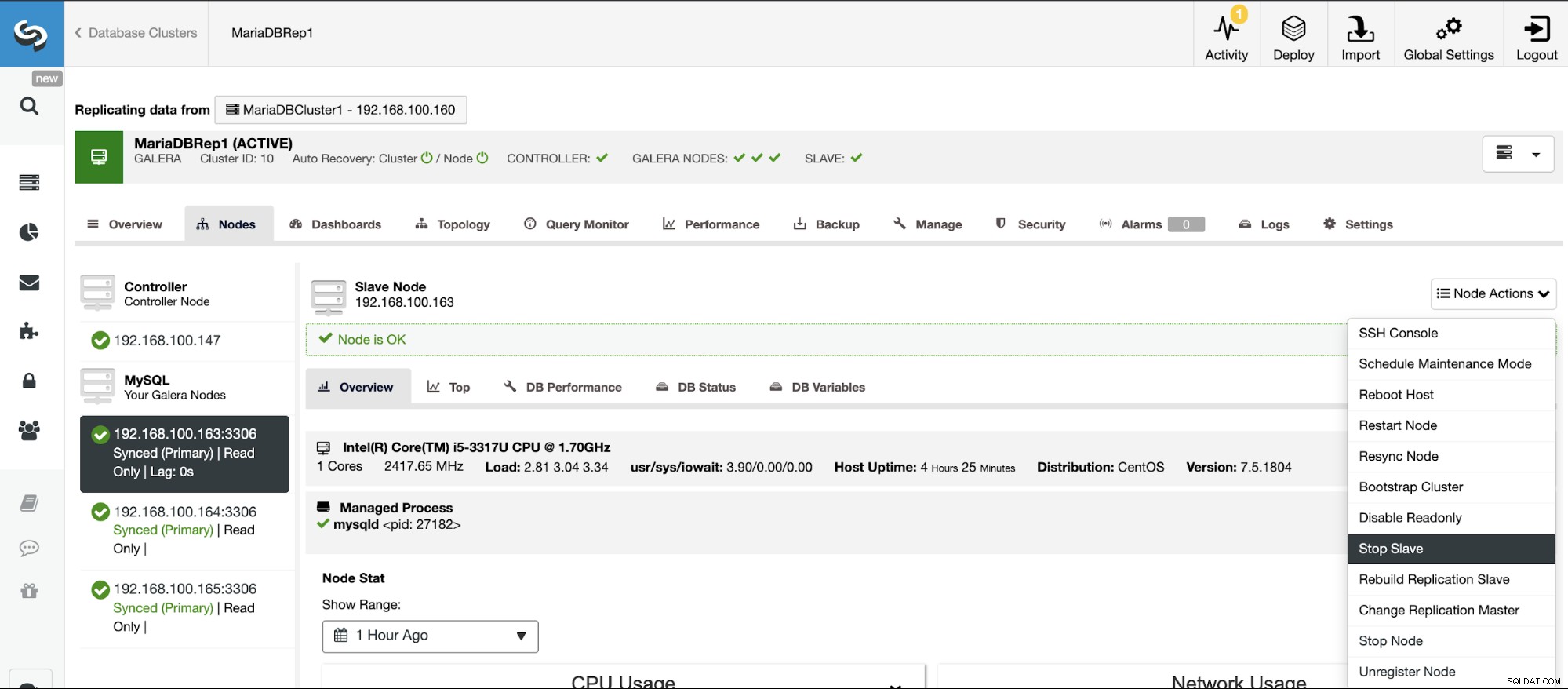
Vai a ClusterControl -> Seleziona cluster slave -> Nodi -> Scegli il Nodo connesso al Master Cluster -> Node Actions -> Stop Slave/Start Slave.
Ripristina slave replica
Utilizzando questa azione, è possibile ripristinare il processo di replica utilizzando RESET SLAVE o RESET SLAVE ALL. La differenza tra loro è che RESET SLAVE non modifica alcun parametro di replica come host master, porta e credenziali. Per eliminare queste informazioni è necessario utilizzare RESET SLAVE ALL che rimuove tutta la configurazione della replica, quindi utilizzando questo comando il collegamento Replica cluster a cluster verrà distrutto.
Prima di utilizzare questa funzione, è necessario interrompere il processo di replica (fare riferimento alla funzione precedente).
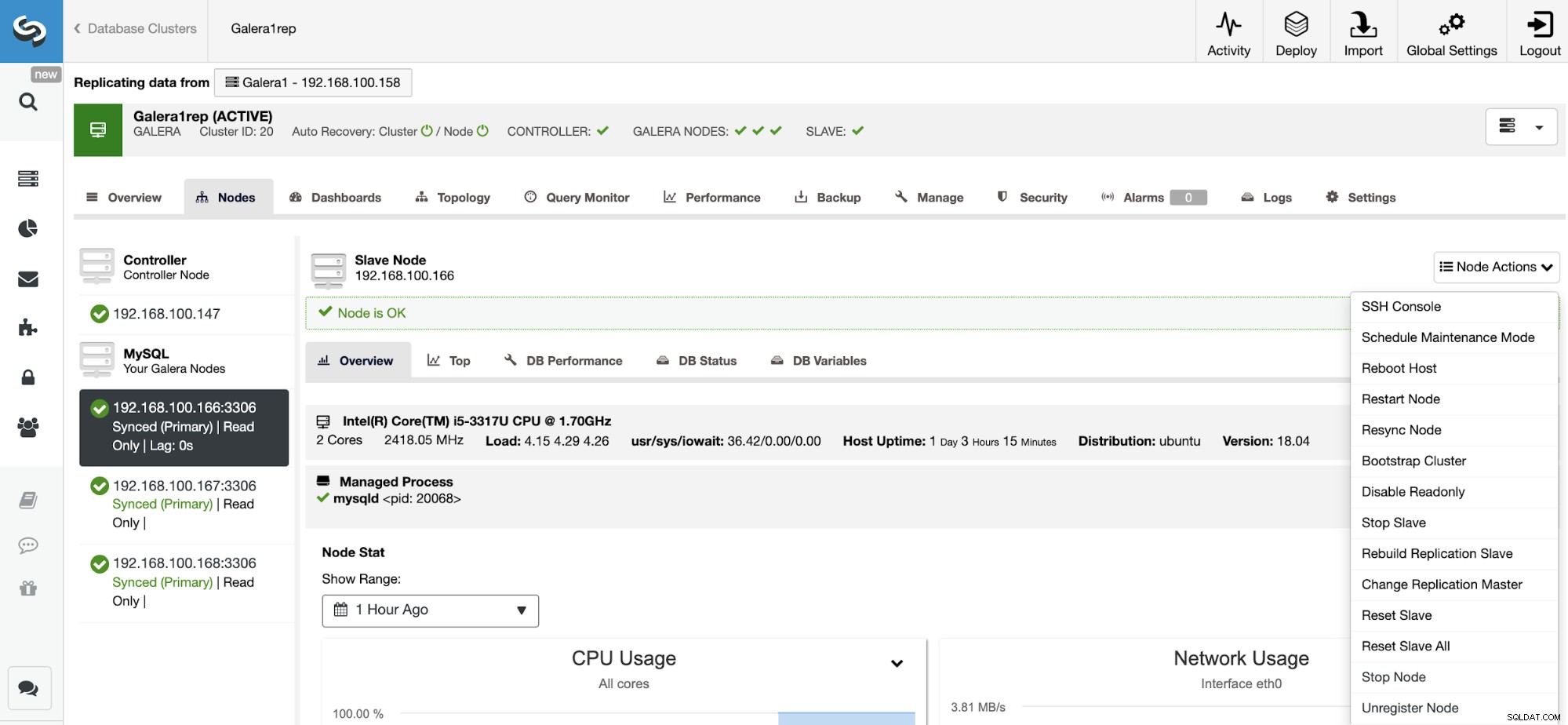
Vai a ClusterControl -> Seleziona Cluster Slave -> Nodi -> Scegli il Nodo connesso al Master Cluster -> Node Actions -> Reset Slave/Reset Slave All.
Gestione della replica da cluster a cluster tramite ClusterControl CLI
Nella sezione precedente, è stato possibile vedere come gestire una replica da cluster a cluster utilizzando l'interfaccia utente di ClusterControl. Ora, vediamo come farlo utilizzando la riga di comando.
Nota:come accennato all'inizio di questo blog, supponiamo che ClusterControl sia installato e che il cluster master sia stato distribuito utilizzandolo.
Crea il cluster slave
Per prima cosa, vediamo un comando di esempio per creare un Cluster Slave utilizzando ClusterControl CLI:
$ s9s cluster --create --cluster-name=Galera1rep --cluster-type=galera --provider-version=10.4 --nodes="192.168.100.166;192.168.100.167;192.168.100.168" --os-user=root --os-key-file=/root/.ssh/id_rsa --db-admin=root --db-admin-passwd=xxxxxxxx --vendor=mariadb --remote-cluster-id=11 --logOra hai il tuo processo di creazione slave in esecuzione, vediamo ogni parametro utilizzato:
- Cluster:per elencare e manipolare i cluster.
- Crea:crea e installa un nuovo cluster.
- Nome-cluster:il nome del nuovo cluster slave.
- Tipo di cluster:il tipo di cluster da installare.
- Versione del provider:la versione del software.
- Nodi:Elenco dei nuovi nodi nel Cluster Slave.
- Os-user:il nome utente per i comandi SSH.
- Os-key-file:il file chiave da utilizzare per la connessione SSH.
- Db-admin:il nome utente dell'amministratore del database.
- Db-admin-passwd:la password per l'amministratore del database.
- Remote-cluster-id:ID cluster principale per la replica da cluster a cluster.
- Registro:Attendi e monitora i messaggi di lavoro.
Utilizzando il flag --log, potrai vedere i log in tempo reale:
Verifying job parameters.
Checking ssh/sudo on 3 hosts.
All 3 hosts are accessible by SSH.
192.168.100.166: Checking if host already exists in another cluster.
192.168.100.167: Checking if host already exists in another cluster.
192.168.100.168: Checking if host already exists in another cluster.
192.168.100.157:3306: Binary logging is enabled.
192.168.100.158:3306: Binary logging is enabled.
Creating the cluster with the following:
wsrep_cluster_address = 'gcomm://192.168.100.166,192.168.100.167,192.168.100.168'
Calling job: setupServer(192.168.100.166).
192.168.100.166: Checking OS information.
…
Caching config files.
Job finished, all the nodes have been added successfully.Configura cluster attivo-attivo
Come hai potuto vedere in precedenza, puoi disabilitare la modalità di sola lettura nel nuovo cluster disabilitandola in ogni nodo, quindi vediamo come farlo dalla riga di comando.
$ s9s node --set-read-write --nodes="192.168.100.166" --cluster-id=16 --logVediamo ogni parametro:
- Nodo:per gestire i nodi.
- Imposta-lettura-scrittura:imposta il nodo in modalità lettura-scrittura.
- Nodi:il nodo in cui cambiarlo.
- Cluster-id:l'ID del cluster in cui si trova il nodo.
Quindi vedrai:
192.168.100.166:3306: Setting read_only=OFF.Ricostruire un cluster di schiavi
Puoi ricostruire un Cluster Slave usando il seguente comando:
$ s9s replication --stage --master="192.168.100.157:3306" --slave="192.168.100.166:3306" --cluster-id=19 --remote-cluster-id=11 --logI parametri sono:
- Replica:per monitorare e controllare la replica dei dati.
- Fase:elabora/ricostruisci uno slave di replica.
- Master:il master di replica nel cluster master.
- Slave:lo slave di replica nel cluster slave.
- Cluster-id:l'ID del cluster slave.
- Remote-cluster-id:l'ID del cluster principale.
- Registro:Attendi e monitora i messaggi di lavoro.
Il registro dei lavori dovrebbe essere simile a questo:
Rebuild replication slave 192.168.100.166:3306 from master 192.168.100.157:3306.
Remote cluster id = 11
Shutting down Galera Cluster.
192.168.100.166:3306: Stopping node.
192.168.100.166:3306: Stopping mysqld (timeout=60, force stop after timeout=true).
192.168.100.166: Stopping MySQL service.
192.168.100.166: All processes stopped.
192.168.100.166:3306: Stopped node.
192.168.100.167:3306: Stopping node.
192.168.100.167:3306: Stopping mysqld (timeout=60, force stop after timeout=true).
192.168.100.167: Stopping MySQL service.
192.168.100.167: All processes stopped.
…
192.168.100.157:3306: Changing master to 192.168.100.166:3306.
192.168.100.157:3306: Changed master to 192.168.100.166:3306
192.168.100.157:3306: Starting slave.
192.168.100.157:3306: Collecting replication statistics.
192.168.100.157:3306: Started slave successfully.
192.168.100.166:3306: Starting node
Writing file '192.168.100.167:/etc/mysql/my.cnf'.
Writing file '192.168.100.167:/etc/mysql/secrets-backup.cnf'.
Writing file '192.168.100.168:/etc/mysql/my.cnf'.Modifiche alla topologia
Puoi modificare la tua topologia utilizzando un altro nodo nel Master Cluster da cui replicare i dati, quindi ad esempio puoi eseguire:
$ s9s replication --failover --master="192.168.100.161:3306" --slave="192.168.100.163:3306" --cluster-id=10 --remote-cluster-id=9 --logControlliamo i parametri utilizzati.
- Replica:per monitorare e controllare la replica dei dati.
- Failover:prendi il ruolo di master da un vecchio master fallito.
- Master:il nuovo master di replica nel Master Cluster.
- Slave:lo slave di replica nel cluster slave.
- Cluster-id:l'ID del cluster slave.
- Remote-Cluster-id:l'ID del cluster principale.
- Registro:Attendi e monitora i messaggi di lavoro.
Vedrai questo registro:
192.168.100.161:3306 belongs to cluster id 9.
192.168.100.163:3306: Changing master to 192.168.100.161:3306
192.168.100.163:3306: My master is 192.168.100.160:3306.
192.168.100.161:3306: Sanity checking replication master '192.168.100.161:3306[cid:9]' to be used by '192.168.100.163[cid:139814070386698]'.
192.168.100.161:3306: Executing GRANT REPLICATION SLAVE ON *.* TO 'cmon_replication'@'192.168.100.163'.
Setting up link between 192.168.100.161:3306 and 192.168.100.163:3306
192.168.100.163:3306: Stopping slave.
192.168.100.163:3306: Successfully stopped slave.
192.168.100.163:3306: Setting up replication using MariaDB GTID: 192.168.100.161:3306->192.168.100.163:3306.
192.168.100.163:3306: Changing Master using master_use_gtid=slave_pos.
192.168.100.163:3306: Changing master to 192.168.100.161:3306.
192.168.100.163:3306: Changed master to 192.168.100.161:3306
192.168.100.163:3306: Starting slave.
192.168.100.163:3306: Collecting replication statistics.
192.168.100.163:3306: Started slave successfully.
192.168.100.160:3306: Flushing logs to update 'SHOW SLAVE HOSTS'Arresta/Avvia slave replica
Puoi interrompere la replica dei dati dal Master Cluster in questo modo:
$ s9s replication --stop --slave="192.168.100.166:3306" --cluster-id=19 --logVedrai questo:
192.168.100.166:3306: Ensuring the datadir '/var/lib/mysql' exists and is owned by 'mysql'.
192.168.100.166:3306: Stopping slave.
192.168.100.166:3306: Successfully stopped slave.E ora puoi ricominciare:
$ s9s replication --start --slave="192.168.100.166:3306" --cluster-id=19 --logQuindi vedrai:
192.168.100.166:3306: Ensuring the datadir '/var/lib/mysql' exists and is owned by 'mysql'.
192.168.100.166:3306: Starting slave.
192.168.100.166:3306: Collecting replication statistics.
192.168.100.166:3306: Started slave successfully.Adesso controlliamo i parametri utilizzati.
- Replica:per monitorare e controllare la replica dei dati.
- Arresta/Avvia:per fare in modo che lo slave arresti/avvii la replica.
- Slave:il nodo slave di replica.
- Cluster-id:l'ID del cluster in cui si trova il nodo slave.
- Registro:Attendi e monitora i messaggi di lavoro.
Ripristina slave replica
Utilizzando questo comando, è possibile ripristinare il processo di replica utilizzando RESET SLAVE o RESET SLAVE ALL. Per ulteriori informazioni su questo comando, controlla l'utilizzo di questo nella sezione precedente dell'interfaccia utente di ClusterControl.
Prima di utilizzare questa funzione, è necessario interrompere il processo di replica (fare riferimento al comando precedente).
RESET SLAVE:
$ s9s replication --reset --slave="192.168.100.166:3306" --cluster-id=19 --logIl registro dovrebbe essere come:
192.168.100.166:3306: Ensuring the datadir '/var/lib/mysql' exists and is owned by 'mysql'.
192.168.100.166:3306: Executing 'RESET SLAVE'.
192.168.100.166:3306: Command 'RESET SLAVE' succeeded.RESET SLAVE TUTTO:
$ s9s replication --reset --force --slave="192.168.100.166:3306" --cluster-id=19 --logE questo registro dovrebbe essere:
192.168.100.166:3306: Ensuring the datadir '/var/lib/mysql' exists and is owned by 'mysql'.
192.168.100.166:3306: Executing 'RESET SLAVE /*!50500 ALL */'.
192.168.100.166:3306: Command 'RESET SLAVE /*!50500 ALL */' succeeded.Vediamo i parametri utilizzati sia per RESET SLAVE che per RESET SLAVE ALL.
- Replica:per monitorare e controllare la replica dei dati.
- Ripristina:ripristina il nodo slave.
- Forza:usando questo flag utilizzerai il comando RESET SLAVE ALL sul nodo slave.
- Slave:il nodo slave di replica.
- Cluster-id:l'ID del cluster slave.
- Registro:Attendi e monitora i messaggi di lavoro.
Conclusione
Questa nuova funzionalità ClusterControl ti consentirà di creare rapidamente una replica da cluster a cluster e gestirla in modo semplice e intuitivo. Questo ambiente migliorerà la topologia del tuo database/cluster e sarebbe utile per un piano di ripristino di emergenza, un ambiente di test e ancora più opzioni menzionate nel blog di panoramica.