In questo articolo, discuteremo di diversi problemi che potresti incontrare durante la creazione, la configurazione o la manutenzione di un sito del gruppo di disponibilità Always on.
Prima di esaminare questo articolo, si consiglia di leggere l'articolo precedente, Configurazione e configurazione di un gruppo di disponibilità sempre attivo in SQL Server, per acquisire familiarità con il concetto di gruppo di disponibilità sempre attivo e le procedure guidate del nuovo gruppo di disponibilità illustrate in questo articolo.
Funzione del gruppo di disponibilità Always on non abilitata
Si supponga che, durante il tentativo di creare un nuovo gruppo di disponibilità Always On, dal nodo Always On High Availability, in Esplora oggetti di SQL Server Management Studio, si è verificato il seguente messaggio di errore:
La funzionalità Gruppi di disponibilità Always On deve essere abilitata per l'istanza del server "SQL1" prima di poter creare un gruppo di disponibilità su questa istanza. Per abilitare questa funzionalità, aprire Gestione configurazione SQL Server, selezionare Servizi SQL Server, fare clic con il pulsante destro del mouse sul nome del servizio SQL Server, selezionare Proprietà e utilizzare la scheda Gruppi di disponibilità Always On della finestra di dialogo Proprietà server. L'abilitazione dei gruppi di disponibilità Always On potrebbe richiedere che l'istanza del server sia ospitata da un nodo WSFC (Windows Server Failover Cluster). (Microsoft.SqlServer.Management.HadrTasks)

Dal messaggio di errore è chiaro che la funzionalità Gruppi di disponibilità AlwaysOn deve essere abilitata su ogni istanza di SQL Server che partecipa al sito del gruppo di disponibilità AlwaysOn, prima di creare quel sito.
Puoi abilitare facilmente la funzionalità Always on Availability Group, aprendo la console di Gestione configurazione SQL Server, sfoglia la scheda Servizi di SQL Server, quindi fai clic con il pulsante destro del mouse sul servizio Motore di database di SQL Server e scegli l'opzione Proprietà.
Dalla finestra delle proprietà di SQL Server aperta, passare alla scheda Disponibilità sempre attiva e selezionare la casella di controllo accanto a Abilita gruppo di disponibilità sempre attivo , tenendo in considerazione che questa modifica richiede il riavvio del servizio SQL Server per avere effetto, come illustrato di seguito:

Problema di convalida dei prerequisiti del database
Nei passaggi precedenti della procedura guidata Nuovo gruppo di disponibilità, ti verrà chiesto di specificare i database che parteciperanno al gruppo di disponibilità Always on. Prima di aggiungere il database, il database deve superare il controllo di convalida dei prerequisiti. In caso contrario, il database non può essere selezionato dagli elenchi di database, come mostrato nel messaggio di errore seguente:
Per essere aggiunto a un gruppo di disponibilità, questo database deve essere impostato sul modello di ripristino completo. Impostare la proprietà del database del modello di ripristino su Completo ed eseguire un backup completo o differenziale del database sul database. Sarà quindi necessario pianificare i backup dei log sul database.

Il messaggio è chiaro. Dove il database deve essere configurato con un modello di ripristino completo e un backup completo o differenziale deve essere eseguito su quel database.
Inoltre, la procedura guidata avverte di pianificare un backup del registro delle transazioni per quel database dopo aver modificato il modello di ripristino su Completo, per troncare automaticamente il file di registro delle transazioni e impedire che il file di registro delle transazioni esaurisca lo spazio libero.
Per risolvere il problema, cambia il modello di ripristino del database da Semplice a Completo, dalla scheda Opzioni della finestra delle proprietà del database, quindi esegui un backup completo da quel database, come mostrato di seguito:

Aggiornando la finestra Seleziona database, lo stato del database verrà modificato in Soddisfa i prerequisiti, come mostrato di seguito:

Problema di autorizzazione alla posizione di rete condivisa
Durante il tentativo di configurare un sito del gruppo di disponibilità Always on, il passaggio di convalida della procedura guidata Nuovo gruppo di disponibilità non è riuscito con il seguente messaggio di errore:
Il server primario 'SQL1' non può scrivere in '\\SQL1\AlwaysON\BackupLocDb_dbb55cb4-af89-4ed3-b189-1fcaad42358c.bak'. (Microsoft.SqlServer.Management.HadrModel)
Backup non riuscito per il server 'SQL1'. (Microsoft.SqlServer.SmoExtended)
Impossibile aprire il dispositivo di backup '\\SQL1\AlwaysON\BackupLocDb_dbb55cb4-af89-4ed3-b189-1fcaad42358c.bak'. Errore del sistema operativo 5 (Accesso negato.).
BACKUP DATABASE sta terminando in modo anomalo. (.Net SqlClient Data Provider)
Nel metodo di sincronizzazione iniziale del backup completo del database e del registro, è necessaria una cartella condivisa per conservare temporaneamente i file del backup completo e del registro delle transazioni per ripristinarli in tutte le repliche secondarie. Se la replica primaria non è in grado di scrivervi i file di backup, o le repliche secondarie non sono in grado di leggere i file di backup da essa, il processo di convalida del nuovo gruppo di disponibilità avrà esito negativo come indicato di seguito:

Per risolvere il problema, è necessario concedere all'account del servizio SQL Server delle repliche primarie e secondarie l'autorizzazione di lettura e scrittura sulla cartella condivisa mostrata nel messaggio di errore, quindi eseguire nuovamente il processo di convalida per assicurarsi che tutti i controlli siano riusciti , come mostrato di seguito:

Problema del cluster di failover di Windows
Si supponga di controllare lo stato di un sito del gruppo di disponibilità Always on esistente e si veda che:
- Il ruolo primario è stato spostato dall'istanza SQL1 a SQL2.
- In SQL2, i database sono nello stato sincronizzato.
- In SQL1, i database non sono sincronizzati.
- SQL1 è in stato di risoluzione.
Come puoi vedere chiaramente da SSMS Object Explorer di seguito:

Controllando i registri degli errori di SQL Server nel nodo problematico, possiamo vedere che la replica del gruppo di disponibilità diventa offline e il gruppo di disponibilità ha smesso di funzionare a causa di un problema nel cluster di failover di Windows Server, come mostrato negli errori seguenti:
- Gruppi di disponibilità Always On:il nodo locale del clustering di failover di Windows Server non è più online . Questo è solo un messaggio informativo. Non è richiesta alcuna azione da parte dell'utente.
- Sempre attivo:il gestore delle repliche di disponibilità è offline perché il nodo locale di Windows Server Failover Clustering (WSFC) ha perso il quorum. Questo è solo un messaggio informativo. Non è richiesta alcuna azione da parte dell'utente.
- Sempre attivo:la replica locale del gruppo di disponibilità "DemoGroup" si sta arrestando. Questo è solo un messaggio informativo. Non è richiesta alcuna azione da parte dell'utente.

La stessa cosa può essere rilevata dal Visualizzatore eventi di Windows Server, che mostra gradualmente come la replica cambia il suo stato in stato di risoluzione, come di seguito:
- Sempre attivo:la replica locale del gruppo di disponibilità 'DemoGroup' si prepara a passare al ruolo risolutivo . Questo è solo un messaggio informativo. Non è richiesta alcuna azione da parte dell'utente.
- Al gruppo di disponibilità "DemoGroup" è stato chiesto di interrompere il rinnovo del contratto di locazione perché il gruppo di disponibilità è offline . Questo è solo un messaggio informativo. Non è richiesta alcuna azione da parte dell'utente.
- Lo stato della replica di disponibilità locale nel gruppo di disponibilità 'DemoGroup' è cambiato da 'PRIMARY_NORMAL' a 'RESOLVING_NORMAL'. Lo stato è cambiato perché il gruppo di disponibilità è offline. La replica è offline perché il gruppo di disponibilità associato è stato eliminato oppure l'utente ha portato offline il gruppo di disponibilità associato nella console di gestione di Windows Server Failover Clustering (WSFC) oppure il gruppo di disponibilità sta eseguendo il failover su un'altra istanza di SQL Server. Per ulteriori informazioni, vedere il registro degli errori di SQL Server o il registro del cluster. Se si tratta di un gruppo di disponibilità di Windows Server Failover Clustering (WSFC), puoi anche vedere la console di gestione WSFC.

Per controllare lo stato del sito del cluster di Windows, utilizzeremo Gestione cluster di failover per vedere quale parte del cluster di Windows non funziona.
Ma il Failover Cluster Manager mostra che l'intero cluster è inattivo, come mostrato di seguito:

La prima cosa da convalidare qui dal lato del cluster di failover di Windows è il servizio cluster, che può essere verificato dalla console dei servizi di Windows, come di seguito:

È chiaro dalla console Servizi che il Servizio cluster non è in esecuzione. Per risolvere il problema, avvia il servizio da tale console, quindi aggiorna la console di Gestione cluster di failover per assicurarti che il sito del cluster di Windows sia attivo e funzionante, come mostrato di seguito:

Selezionando nuovamente il gruppo di disponibilità Always on, vedrai che i database sono nuovamente sincronizzati e il sito del gruppo di disponibilità Always on è di nuovo in stato di integrità, come mostrato di seguito:

Il file di registro delle transazioni è pieno sul lato primario
Si supponga di ricevere il seguente messaggio di errore quando si tenta di eseguire una nuova query su uno dei database del gruppo di disponibilità Always on:

Controllando cosa sta bloccando il file di registro delle transazioni e ne impedisce il troncamento, vedrai che il file di registro delle transazioni di questo database è in attesa che l'operazione di backup del registro venga troncata, come mostrato di seguito:

Eseguire un backup del registro delle transazioni per quel database, nel caso in cui dimentichi di pianificare un processo di backup del registro delle transazioni, come segue:

E controlla di nuovo cosa sta bloccando il registro delle transazioni di quel database, sta mostrando nel mio scenario che è in attesa di Availability_Replica. Ciò significa che i registri sono in attesa di essere scritti nella replica secondaria, ma non sono in grado di inviare questi registri delle transazioni alle repliche secondarie a causa di un problema nel sito del gruppo di disponibilità Always on, come di seguito:

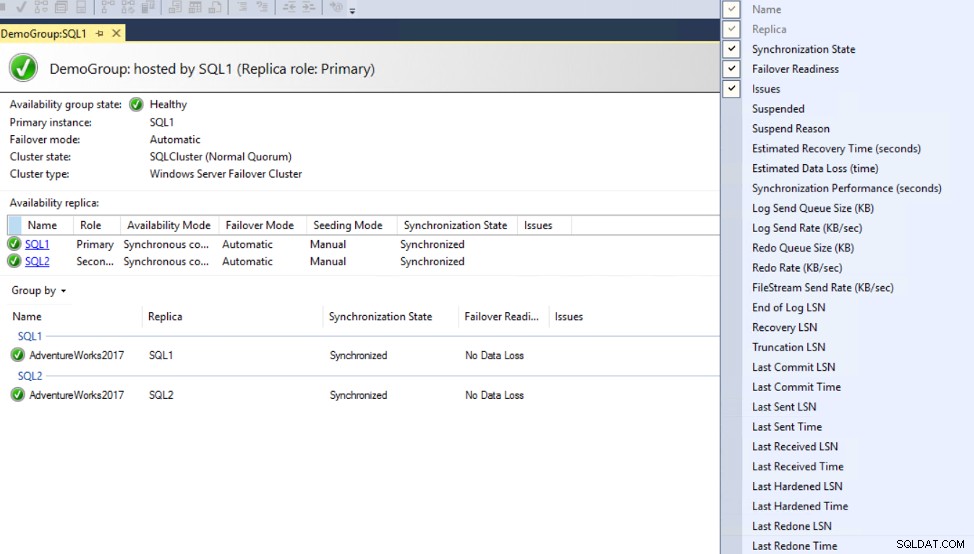
La posizione migliore per controllare e risolvere i problemi del sito del gruppo di disponibilità Always on è il dashboard Always on, che può essere aperto facendo clic con il pulsante destro del mouse sul nome del gruppo di disponibilità e scegliendo l'opzione Mostra dashboard.
Dal dashboard, puoi vedere che la replica secondaria SQL2 non è sincronizzata con la replica primaria, a causa di un problema di connettività, come mostrato di seguito:

Verifica della replica secondaria e verifica che il servizio SQL Server sia attivo e in esecuzione sul lato secondario, come segue:

Quindi, aggiornando nuovamente la dashboard del gruppo di disponibilità, vedrai che il sito del gruppo di disponibilità Always on è di nuovo integro. Checking if the transaction logs file is blocked by any operation, we will see that it is pending OLDEST_PAGE, indicating that the oldest page of the database is older than the checkpoint LSN. This issue can be fixed easily by taking another transaction log backup and the transaction log file will be blocked by nothing, as shown clearly below:

Always on Availability Group Failover Misconfiguration
Assume that the Primary replica becomes offline due to an unplanned issue. As expected, the system will not be affected as an automatic failover operation will be performed and the secondary replica will act as the new Primary replica.
But in our case, this happy scenario is not valid, where the secondary replica changed to Resolving state and the system is down!

Checking the secondary replica’s error log and see why it is not acting as the new Primary as expected, you will see that it is failing due to a role synchronization issue, as shown below:
The availability group database "AdventureWorks2017" is changing roles from "SECONDARY" to "RESOLVING" because the mirroring session or availability group failed over due to role synchronization. This is an informational message only. No user action is required.

This means that there is an issue with the synchronization mode that is used in this Availability Group. The synchronization mode used, can be checked from the Always on Availability Group properties page.
From the properties page below, it is clear that the Failover mode in this Availability Group is configured to be performed Manually only. In this case, you need to manually perform a failover operation before rebooting or shutting down the server:

This can be fixed easily by changing the Failover Mode to Automatic, where an automatic failover operation will be performed in case of any unplanned shutdown or reboot:

The same issue can be faced when the Windows Failover Cluster quorum is configured with Node Majority for an even number of replicas, where any failure for one of the servers will bring the Windows Failover Cluster site offline. For more information, check Windows Failover Cluster Quorum Modes in SQL Server Always On Availability Groups:

Failover with Data Loss
Assume that you are trying to perform a manual failover between the Primary and one of the Secondary replicas, but in the Select New Primary Replica window, you see a warning message that the failover operation may end up with data loss as the Primary and the selected Secondary replica are not synchronized, as shown below:

To identify the cause of that issue, we will browse the Always on Health events using the Always on Availability Group dashboard, which shows that the Primary replica is not able to open a connection to the Secondary replica, ash shown below:

After fixing the connectivity issue between the Primary and the Secondary, refresh the replicas list and you will see that the data loss issue is fixed, as shown below. For more information about troubleshooting the connectivity issues, check Troubleshoot connecting to the SQL Server Database Engine.

Monitoring Always on Availability Group Latency
The Availability Group dashboard can be modified to include additional columns that provide information about the synchronization latency between Primary and Secondary replicas, including the Commit LSN, Sent LSN and harden LSN values, without showing why there is a latency, as shown below:
For more information about measuring the latency, check the Measuring Availability Group synchronization lag.
Starting from SSMS 17.4, the Always on Availability Group dashboard enhanced to include two new options that are used for latency information calculation, analysis and reporting, which helps in identifying the bottlenecks in the transaction logs flow between the Primary and the Secondary replicas and narrow down the cause of that latency.
For more information about the new functionality and reports, check to Use the Always on Availability Group dashboard.
To trigger using this new option, click on Collect Latency Data option from the Always on Availability Group dashboard, that will create a new SQL Agent job on the Primary and Secondary replicas to collect the latency data, As shown below:

When the created job execution has completed on all the Availability Group replicas, you will be able to view the latency statistics from the latency reports by right-clicking on the Availability Group name and choose the Primary Replica Latency or Secondary Replica Latency report, based on the replica role in the Availability Group.
After providing information about the Availability Group replicas, the latency report will show a graphical view of the transaction log commit time on the Primary replica and the remote Hardening time for the secondary replicas, aggregated as average values. Also, the report provides statistical values for the transaction logs send, receive, commit, compress, decompress and other numerical values based on the replica role in the Availability Group.
For more information about the latency report, check New in SSMS - Always On Availability Group Latency Reports.
The below report is an example of the latency reports generated from the Secondary replica, showing normal logs transport operations:

Also, the Log Block Latency report shows the amount of time, in ms, that the transaction log on the Primary replica waits for Secondary replicas to commit that transaction. After enabling it from the Availability Group Dashboard, you can browse it from the SSMS similar to the previous latency reports. Take into consideration that, the large latency time indicates that the Primary replica is waiting a long time for the Secondary replicas to commit the sent transactions, as shown below: