Ogni versione di PostgreSQL include alcuni importanti miglioramenti delle funzionalità, ma ciò che è ugualmente interessante è che ogni versione migliora anche le funzionalità precedenti.
Poiché PostgreSQL 13 dovrebbe essere rilasciato a breve, è tempo di verificare quali funzionalità e miglioramenti ci stanno apportando la community. Uno di questi miglioramenti senza disturbi è il "Miglioramento della replica logica per il partizionamento".
Comprendiamo questo miglioramento della funzionalità con un esempio in esecuzione.
Terminologia
Due termini importanti per comprendere questa funzione sono:
- Tabelle delle partizioni
- Replica logica
Tabelle delle partizioni
Un modo per dividere un grande tavolo in più parti fisiche per ottenere vantaggi come:
- Prestazioni delle query migliorate
- Aggiornamenti più rapidi
- Caricamenti ed eliminazioni di massa più veloci
- Organizzazione dei dati usati raramente su unità disco lente
Alcuni di questi vantaggi si ottengono tramite lo sfoltimento della partizione (ovvero il pianificatore di query che utilizza la definizione della partizione per decidere se scansionare una partizione o meno) e il fatto che una partizione è piuttosto più facile da inserire nella memoria finita rispetto a un tavolo enorme.
Una tabella è partizionata in base a:
- Elenco
- Hash
- Gamma

Replica logica
Come suggerisce il nome, questo è un metodo di replica in cui i dati vengono replicati in modo incrementale in base alla loro identità (es. chiave). Non è simile a WAL o ai metodi di replica fisica in cui i dati vengono inviati byte per byte.
In base a un modello Publisher-Subscriber, l'origine dei dati deve definire un publisher mentre la destinazione deve essere registrata come abbonato. I casi d'uso interessanti per questo sono:
- Replica selettiva (solo una parte del database)
- Scrittura simultanea su due istanze del database in cui i dati vengono replicati
- Replica tra diversi sistemi operativi (es. Linux e Windows)
- Sicurezza granulare sulla replica dei dati
- Attiva l'esecuzione quando i dati arrivano sul lato ricevente
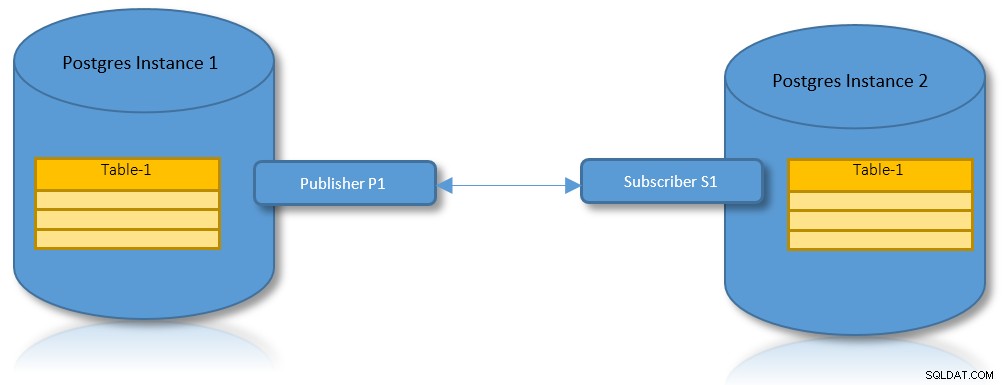
Replica logica per partizioni
Con i vantaggi sia della replica logica che del partizionamento, è un caso d'uso pratico avere uno scenario in cui una tabella partizionata deve essere replicata su due istanze PostgreSQL.
Di seguito sono riportati i passaggi per stabilire ed evidenziare il miglioramento in corso in PostgreSQL 13 in questo contesto.
Impostazione
Considera una configurazione a due nodi per eseguire due diverse istanze contenenti una tabella partizionata:
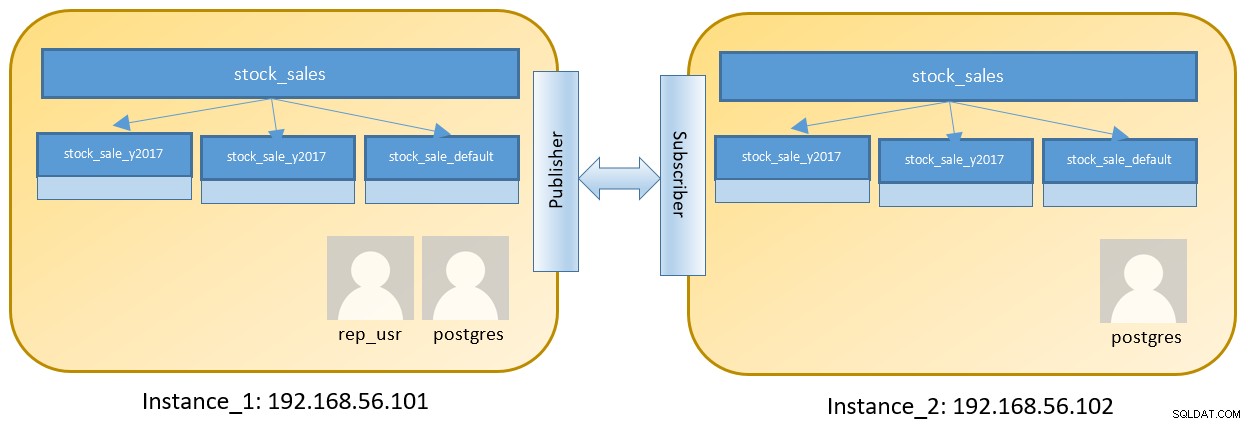
I passaggi su Instance_1 sono i seguenti dopo l'accesso su 192.168.56.101 come utente postgres :
$ initdb -D ${HOME}/pgdata-1
$ echo "listen_addresses = '192.168.56.101'" >> ${HOME}/pgdata-1/postgresql.conf
$ echo "wal_level = logical" >> ${HOME}/pgdata-1/postgresql.conf
$ echo "host postgres all 192.168.56.102/32 md5" >> ${HOME}/pgdata-1/pg_hba.conf
$ pg_ctl -D ${HOME}/pgdata-1 -l logfile startL'impostazione 'wal_level' è specificatamente impostata su 'logical' per indicare che la replica logica verrà utilizzata per replicare i dati da questa istanza. Anche il file di configurazione "pg_hba.conf" è stato modificato per consentire le connessioni da 192.168.56.102.
# CREATE TABLE stock_sales
( sale_date date not null, unit_sold int, unit_price int )
PARTITION BY RANGE ( sale_date );
# CREATE TABLE stock_sales_y2017 PARTITION OF stock_sales
FOR VALUES FROM ('2017-01-01') TO ('2018-01-01');
# CREATE TABLE stock_sales_y2018 PARTITION OF stock_sales
FOR VALUES FROM ('2018-01-01') TO ('2019-01-01');
# CREATE TABLE stock_sales_default
PARTITION OF stock_sales DEFAULT;Sebbene il ruolo postgres sia creato per impostazione predefinita nel database di Instance_1, è necessario creare anche un utente separato con accesso limitato, il che limita l'ambito solo per una determinata tabella.
# CREATE ROLE rep_usr WITH REPLICATION LOGIN PASSWORD 'rep_pwd';
# GRANT CONNECT ON DATABASE postgres TO rep_usr;
# GRANT USAGE ON SCHEMA public TO rep_usr;
# GRANT SELECT ON ALL TABLES IN SCHEMA public to rep_usr;È richiesta una configurazione quasi simile su Instance_2
$ initdb -D ${HOME}/pgdata-2
$ echo "listen_addresses = '192.168.56.102'" >> ${HOME}/pgdata-2/postgresql.conf
$ pg_ctl -D ${HOME}/pgdata-2 -l logfile startVa notato che poiché Instance_2 non sarà una fonte di dati per nessun altro nodo, le impostazioni wal_level così come il file pg_hba.conf non necessitano di impostazioni aggiuntive. Inutile dire che pg_hba.conf potrebbe necessitare di un aggiornamento in base alle esigenze di produzione.
La replica logica non supporta DDL, dobbiamo anche creare una struttura di tabella su Instance_2. Crea una tabella partizionata utilizzando la creazione della partizione sopra per creare la stessa struttura della tabella anche su Instance_2.
Impostazione replica logica
L'impostazione della replica logica diventa molto più semplice con PostgreSQL 13. Fino a PostgreSQL 12 la struttura era la seguente:
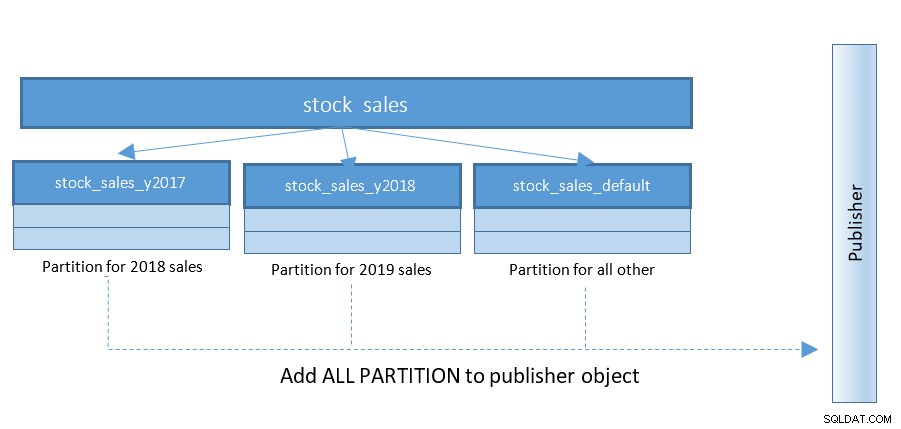
Con PostgreSQL 13, la pubblicazione delle partizioni diventa molto più semplice. Fare riferimento al diagramma seguente e confrontare con il diagramma precedente:
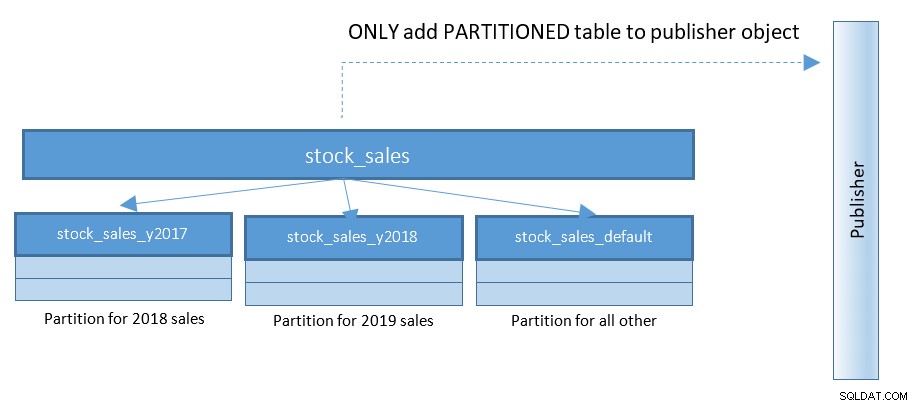
Con le configurazioni che imperversano con 100 e 1000 di tabelle partizionate, questa piccola modifica semplifica cose in larga misura.
In PostgreSQL 13, le istruzioni per creare tale pubblicazione saranno:
CREATE PUBLICATION rep_part_pub FOR TABLE stock_sales
WITH (publish_via_partition_root);Il parametro di configurazione publish_via_partition_root è nuovo in PostgreSQL 13, che consente al nodo destinatario di avere una gerarchia foglia leggermente diversa. La semplice creazione di pubblicazioni su tabelle partizionate in PostgreSQL 12, restituirà istruzioni di errore come di seguito:
ERROR: "stock_sales" is a partitioned table
DETAIL: Adding partitioned tables to publications is not supported.
HINT: You can add the table partitions individually.Ignorando le limitazioni di PostgreSQL 12 e procedendo con questa funzionalità su PostgreSQL 13, dobbiamo stabilire l'abbonato su Instance_2 con le seguenti istruzioni:
CREATE SUBSCRIPTION rep_part_sub CONNECTION 'host=192.168.56.101 port=5432 user=rep_usr password=rep_pwd dbname=postgres' PUBLICATION rep_part_pub;Verifica se funziona davvero
Abbiamo praticamente finito con l'intera configurazione, ma eseguiamo un paio di test per vedere se le cose funzionano.
Sull'istanza_1, inserisci più righe assicurandoti che si generino in più partizioni:
# INSERT INTO stock_sales (sale_date, unit_sold, unit_price) VALUES ('2017-09-20', 12, 151);# INSERT INTO stock_sales (sale_date, unit_sold, unit_price) VALUES ('2018-07-01', 22, 176);
# INSERT INTO stock_sales (sale_date, unit_sold, unit_price) VALUES ('2016-02-02', 10, 1721);Controlla i dati sull'istanza_2:
# SELECT * from stock_sales;
sale_date | unit_sold | unit_price
------------+-----------+------------
2017-09-20 | 12 | 151
2018-07-01 | 22 | 176
2016-02-02 | 10 | 1721Ora controlliamo se la replica logica funziona anche se i nodi foglia non sono gli stessi sul lato destinatario.
Aggiungi un'altra partizione su Instance_1 e inserisci il record:
# CREATE TABLE stock_sales_y2019
PARTITION OF stock_sales
FOR VALUES FROM ('2019-01-01') to ('2020-01-01');
# INSERT INTO stock_sales VALUES(‘2019-06-01’, 73, 174 );Controlla i dati sull'istanza_2:
# SELECT * from stock_sales;
sale_date | unit_sold | unit_price
------------+-----------+------------
2017-09-20 | 12 | 151
2018-07-01 | 22 | 176
2016-02-02 | 10 | 1721
2019-06-01 | 73 | 174Altre funzionalità di partizionamento in PostgreSQL 13
Ci sono anche altri miglioramenti in PostgreSQL 13 relativi al partizionamento, vale a dire:
- Miglioramenti nell'unione tra tabelle partizionate
- Le tabelle partizionate ora supportano i trigger a livello di riga PRIMA
Conclusione
Controllerò sicuramente le due funzionalità imminenti di cui sopra nel mio prossimo set di blog. Fino ad allora spunti di riflessione:con la potenza combinata del partizionamento e della replica logica, PostgreSQL si sta avvicinando a una configurazione master-master?