Uno degli aspetti chiave dell'alta disponibilità è la capacità di reagire rapidamente ai guasti. Non è raro gestire manualmente i database e fare in modo che il software di monitoraggio tenga d'occhio lo stato del database. In caso di guasto, il software di monitoraggio invia un avviso al personale di guardia. Ciò significa che qualcuno potrebbe potenzialmente dover svegliarsi, accedere a un computer e accedere ai sistemi e guardare i registri, ovvero c'è un bel po' di tempo prima che possa iniziare la riparazione. Idealmente, l'intero processo dovrebbe essere automatizzato.
In questo blog, esamineremo come distribuire un sistema completamente automatizzato che rileva quando il database primario si guasta e avvia procedure di failover promuovendo un database secondario. Useremo ClusterControl per eseguire il failover automatico del database Moodle PostgreSQL.
Vantaggio del failover automatico
- Meno tempo per ripristinare il servizio database
- Tempi di attività del sistema più elevati
- Minore dipendenza dall'amministratore di database o dall'amministratore che ha impostato la disponibilità elevata per il database
Architettura
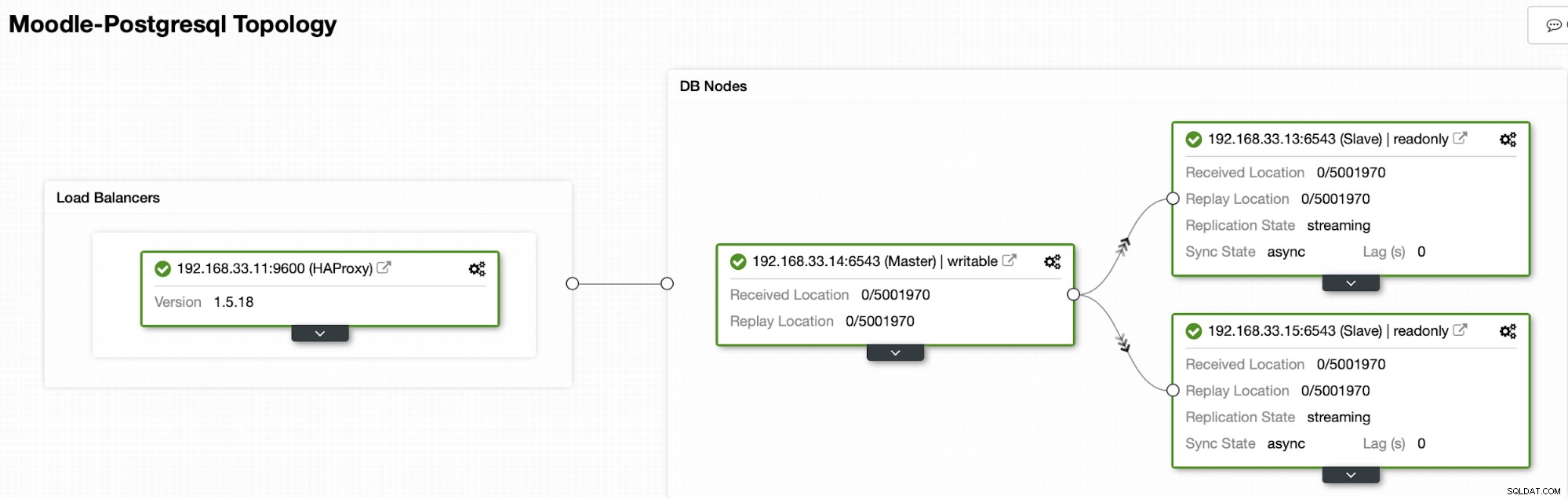
Attualmente abbiamo un server primario Postgres e due server secondari sotto il sistema di bilanciamento del carico HAProxy che invia il traffico Moodle al nodo PostgreSQL primario. Il ripristino del cluster e il ripristino automatico del nodo in ClusterControl sono le impostazioni importanti per eseguire il processo di failover automatico.

Controllare su quale server eseguire il failover
ClusterControl offre l'inserimento nella whitelist e la blacklist di un insieme di server che si desidera partecipare al failover o escludere come candidato.
Ci sono due variabili che puoi impostare nella configurazione di cmon,
- replication_failover_whitelist :contiene un elenco di IP o nomi host di server secondari che dovrebbero essere utilizzati come potenziali candidati primari. Se questa variabile è impostata, verranno presi in considerazione solo quegli host.
- replication_failover_blacklist :contiene un elenco di host che non saranno mai considerati candidati primari. È possibile utilizzarlo per elencare i server secondari utilizzati per i backup o le query analitiche. Se l'hardware varia tra i server secondari, potresti voler inserire qui i server che utilizzano hardware più lento.
Processo di failover automatico
Fase 1
Abbiamo avviato il caricamento dei dati sul server primario (192.168.33.14) utilizzando lo strumento sysbench.
[example@sqldat.com sysbench]# /bin/sysbench --db-driver=pgsql --oltp-table-size=100000 --oltp-tables-count=24 --threads=2 --pgsql-host=****** --pgsql-port=6543 --pgsql-user=sbtest --pgsql-password=***** --pgsql-db=sbtest /usr/share/sysbench/tests/include/oltp_legacy/parallel_prepare.lua run
sysbench 1.0.20 (using bundled LuaJIT 2.1.0-beta2)
Running the test with following options:
Number of threads: 2
Initializing random number generator from current time
Initializing worker threads...
Threads started!
thread prepare0
Creating table 'sbtest1'...
Inserting 100000 records into 'sbtest1'
Creating secondary indexes on 'sbtest1'...
Creating table 'sbtest2'...
Fase 2
Interromperemo il server primario di Postgres (192.168.33.14). In ClusterControl, il parametro (enable_cluster_autorecovery) è abilitato in modo da promuovere il prossimo primario adatto.
# service postgresql-12 stopPassaggio 3
ClusterControl rileva gli errori nel primario e promuove un secondario con i dati più aggiornati come nuovo primario. Funziona anche sul resto dei server secondari per farli replicare dal nuovo primario.

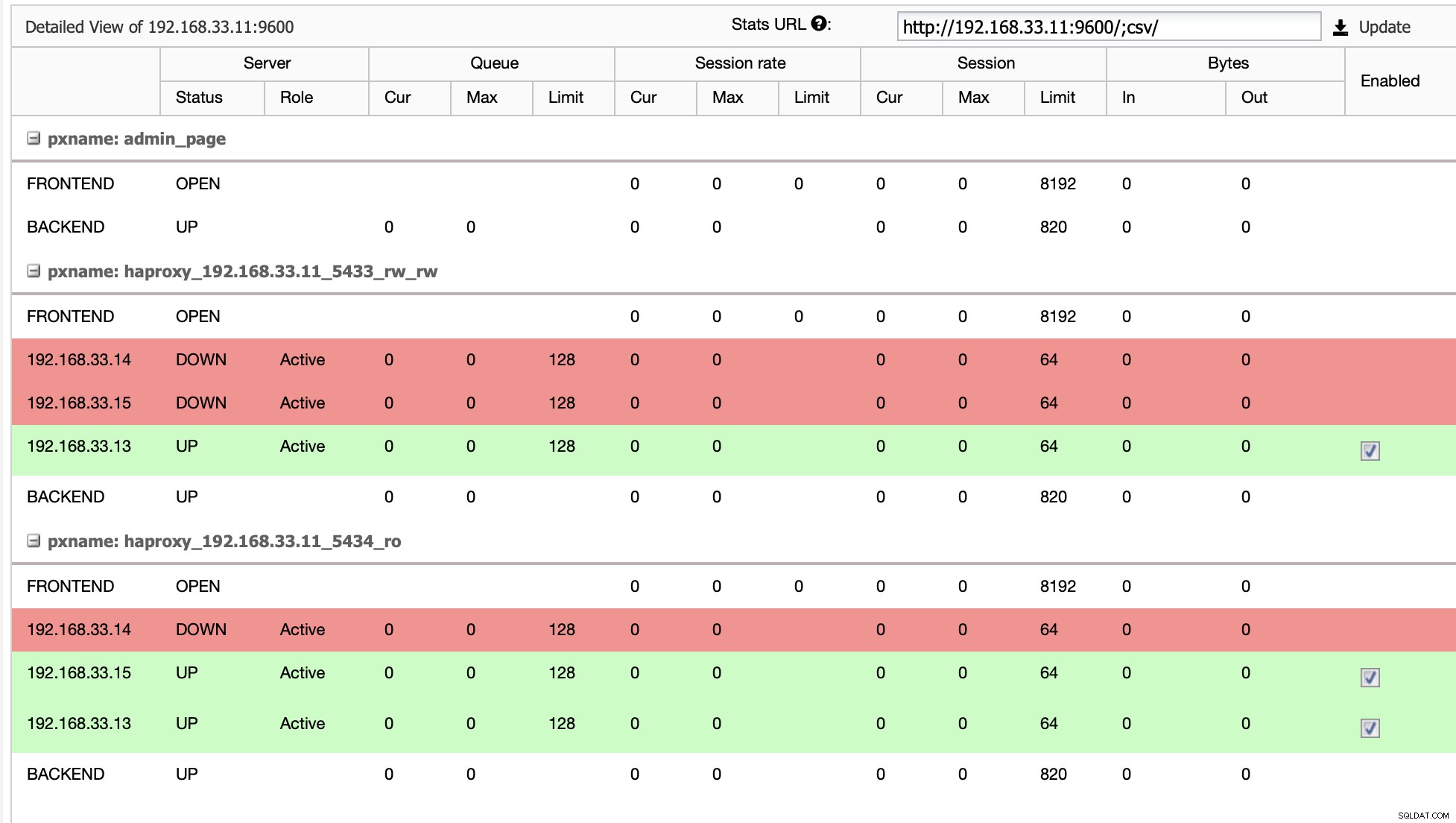
Nel nostro caso il (192.168.33.13) è un nuovo server primario e i server secondari ora vengono replicati da questo nuovo server primario. Ora HAProxy instrada il traffico del database dai server Moodle all'ultimo server primario.
Da (192.168.33.13)
postgres=# select pg_is_in_recovery();
pg_is_in_recovery
-------------------
f
(1 row)Da (192.168.33.15)
postgres=# select pg_is_in_recovery();
pg_is_in_recovery
-------------------
t
(1 row)
Topologia attuale
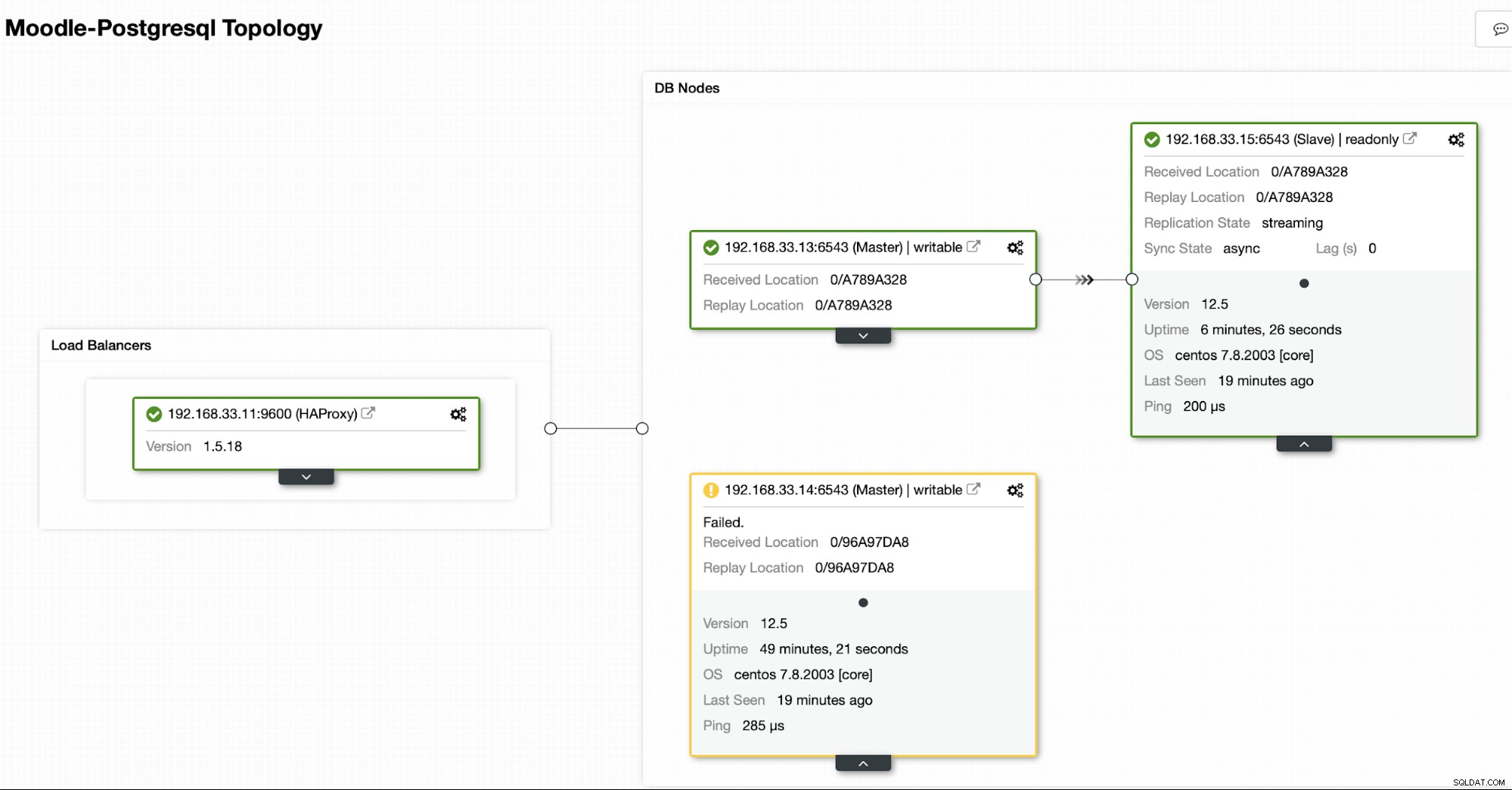
Quando HAProxy rileva che uno dei nostri nodi, primario o replica, è non accessibile, lo contrassegna automaticamente come offline. HAProxy non invierà alcun traffico dall'applicazione Moodle ad essa. Questo controllo viene eseguito dagli script di controllo dello stato configurati da ClusterControl al momento della distribuzione.
Una volta che ClusterControl promuove un server di replica a primario, HAProxy contrassegna il vecchio primario come offline e mette online il nodo promosso.
Una volta che il vecchio server primario è di nuovo online, non si sincronizzerà automaticamente con il nuovo server primario. È necessario reinserirlo nella topologia e può essere eseguito tramite l'interfaccia ClusterControl. Ciò eviterà la possibilità di perdita o incoerenza dei dati, nel caso in cui volessimo indagare sul motivo per cui quel server non è riuscito in primo luogo.
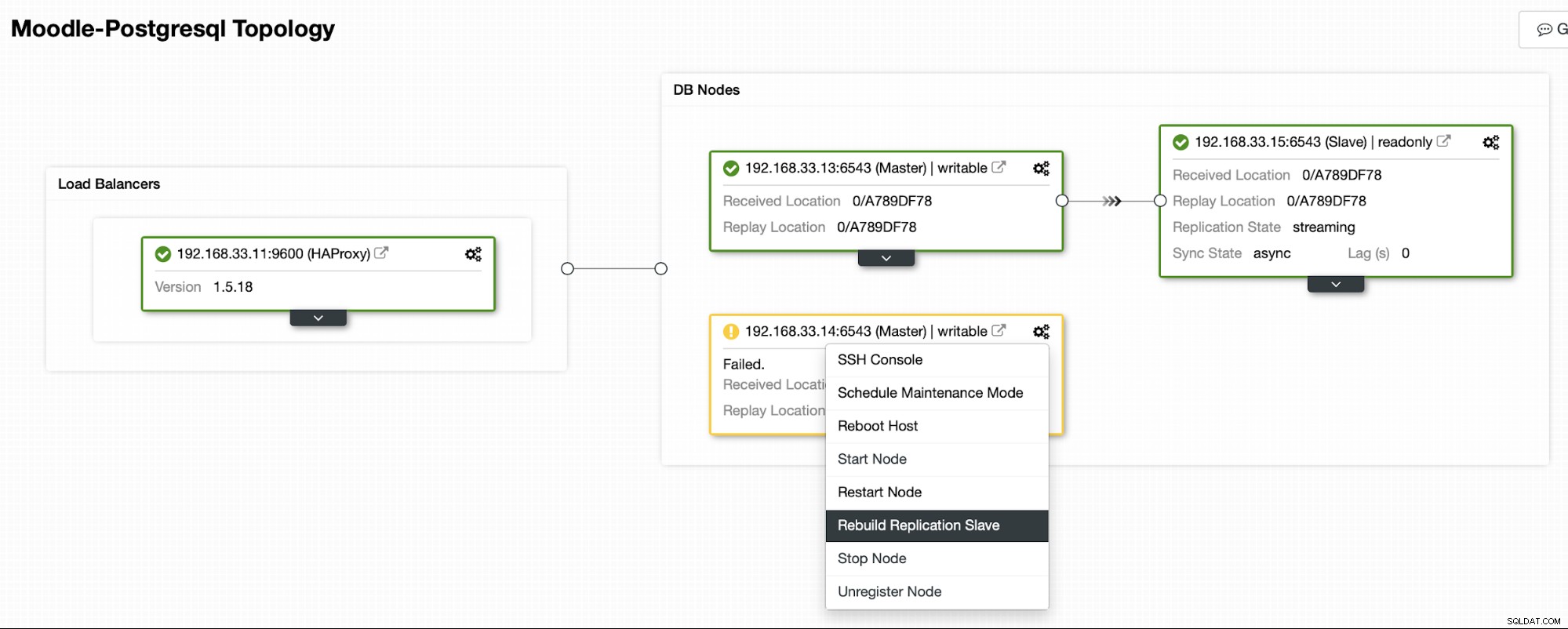
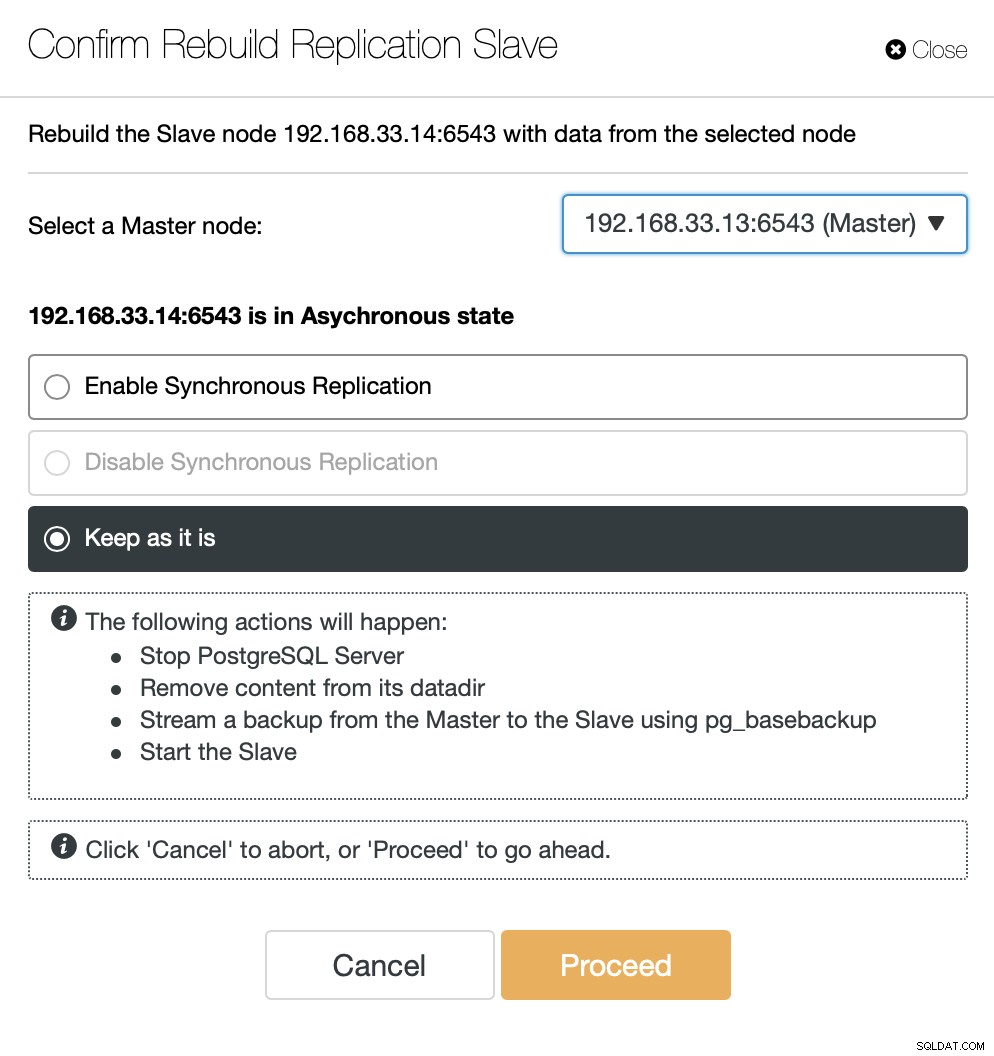
ClusterControl eseguirà lo streaming del backup dal nuovo server primario e configurerà la replica.
Conclusione
Il failover automatico è una parte importante di qualsiasi database di produzione Moodle. Può ridurre i tempi di inattività in caso di inattività di un server, ma anche durante l'esecuzione di attività di manutenzione o migrazioni comuni. È importante farlo bene, poiché è importante che il software di failover prenda le decisioni giuste.