Ho iniziato a scrivere dello strumento (pglupgrade) che ho sviluppato per eseguire aggiornamenti automatizzati con tempi di inattività prossimi allo zero dei cluster PostgreSQL. In questo post parlerò dello strumento e ne discuterò i dettagli di progettazione.
Puoi controllare la prima parte della serie qui:Aggiornamenti automatizzati con tempi di inattività quasi pari a zero dei cluster PostgreSQL nel cloud (Parte I).

Lo strumento è scritto in Ansible. Ho precedenti esperienze di lavoro con Ansible e attualmente ci lavoro anche in 2ndQuadrant , motivo per cui è stata un'opzione comoda per me. Detto questo, puoi implementare la logica di aggiornamento dei tempi di inattività minimi, che verrà spiegata più avanti in questo post, con il tuo strumento di automazione preferito.
Ulteriori letture:post del blog Ansible Loves PostgreSQL , PostgreSQL Planet in Ansible Galaxy e presentazione Gestione di PostgreSQL con Ansible.
Pglupgrade Playbook
In Ansible, playbook sono gli script principali sviluppati per automatizzare processi come il provisioning di istanze cloud e l'aggiornamento dei cluster di database. I playbook possono contenere una o più riproduzione . I playbook possono contenere anche variabili , ruoli e gestori se definito.
Lo strumento è costituito da due playbook principali. Il primo playbook è provision.yml che automatizza il processo di creazione di macchine Linux in cloud, secondo le specifiche (Questo è un playbook opzionale scritto solo per effettuare il provisioning di istanze cloud e non direttamente correlato all'aggiornamento ). Il secondo (e principale) playbook è pglupgrade.yml che automatizza il processo di aggiornamento dei cluster di database.
Il playbook di Pglupgrade ha otto riproduzioni per orchestrare l'aggiornamento. Ciascuna delle riproduzioni, utilizza un file di configurazione (config.yml ), eseguire alcune attività sugli host o sui gruppi host definiti nel file di inventario dell'host (host.ini ).
File di inventario
Un file di inventario consente ad Ansible di sapere quali server deve connettersi tramite SSH, quali informazioni di connessione richiede e, facoltativamente, quali variabili sono associate a tali server. Di seguito puoi vedere un file di inventario di esempio, che è stato utilizzato per eseguire aggiornamenti automatici del cluster per uno dei casi di studio progettati per lo strumento. Discuteremo questi casi di studio nei prossimi post di questa serie.
[old-primary] 54.171.211.188 [new-primary] 54.246.183.100 [old-standbys] 54.77.249.81 54.154.49.180 [new-standbys:children] old-standbys [pgbouncer] 54.154.49.180
File di inventario (host.ini )
Il file di inventario di esempio contiene cinque host meno di cinque gruppi ospitanti che includono old-primary , new-primary , old-standbys , new-standbys e pgbouncer . Un server può appartenere a più di un gruppo. Ad esempio, il old-standbys è un gruppo contenente i new-standbys gruppo, che indica gli host definiti in old-standbys gruppo (54.77.249.81 e 54.154.49.180) appartiene anche al new-standbys gruppo. In altre parole, il new-standbys il gruppo viene ereditato da (figli di) old-standbys gruppo. Ciò si ottiene utilizzando lo speciale :children suffisso.
Una volta che il file di inventario è pronto, il playbook di Ansible può essere eseguito tramite ansible-playbook comando puntando al file di inventario (se il file di inventario non si trova nella posizione predefinita, altrimenti utilizzerà il file di inventario predefinito) come mostrato di seguito:
$ ansible-playbook -i hosts.ini pglupgrade.yml
Esecuzione di un playbook Ansible
File di configurazione
Il playbook di Pglupgrade utilizza un file di configurazione (config.yml ) che consente agli utenti di specificare i valori per le variabili di aggiornamento logico.
Come mostrato di seguito, il config.yml memorizza principalmente le variabili specifiche di PostgreSQL necessarie per configurare un cluster PostgreSQL come postgres_old_datadir e postgres_new_datadir per memorizzare il percorso della directory dei dati di PostgreSQL per la vecchia e la nuova versione di PostgreSQL; postgres_new_confdir memorizzare il percorso della directory di configurazione di PostgreSQL per la nuova versione di PostgreSQL; postgres_old_dsn e postgres_new_dsn per memorizzare la stringa di connessione per pglupgrade_user per poterti connettere al pglupgrade_database dei nuovi e dei vecchi server primari. La stringa di connessione stessa è composta dalle variabili configurabili in modo che l'utente (pglupgrade_user ) e il database (pglupgrade_database ) le informazioni possono essere modificate per i diversi casi d'uso.
ansible_user: admin
pglupgrade_user: pglupgrade
pglupgrade_pass: pglupgrade123
pglupgrade_database: postgres
replica_user: postgres
replica_pass: ""
pgbouncer_user: pgbouncer
postgres_old_version: 9.5
postgres_new_version: 9.6
subscription_name: upgrade
replication_set: upgrade
initial_standbys: 1
postgres_old_dsn: "dbname={{pglupgrade_database}} host={{groups['old-primary'][0]}} user {{pglupgrade_user}}"
postgres_new_dsn: "dbname={{pglupgrade_database}} host={{groups['new-primary'][0]}} user={{pglupgrade_user}}"
postgres_old_datadir: "/var/lib/postgresql/{{postgres_old_version}}/main"
postgres_new_datadir: "/var/lib/postgresql/{{postgres_new_version}}/main"
postgres_new_confdir: "/etc/postgresql/{{postgres_new_version}}/main" File di configurazione (config.yml )
Come passaggio chiave per qualsiasi aggiornamento, le informazioni sulla versione di PostgreSQL possono essere specificate per la versione corrente (postgres_old_version ) e la versione che verrà aggiornata a (postgres_new_version ). A differenza della replica fisica in cui la replica è una copia del sistema a livello di byte/blocco, la replica logica consente la replica selettiva dove la replica può copiare i dati logici includono i database specificati e le tabelle in quei database. Per questo motivo, config.yml permette di configurare quale database replicare tramite pglupgrade_database variabile. Inoltre, l'utente della replica logica deve disporre dei privilegi di replica, motivo per cui pglupgrade_user la variabile deve essere specificata nel file di configurazione. Ci sono altre variabili relative al funzionamento interno di pglogical come subscription_name e replication_set che vengono utilizzati nel ruolo pglogico.
Progettazione ad alta disponibilità dello strumento Pglupgrade
Lo strumento Pglupgrade è progettato per offrire all'utente la flessibilità in termini di proprietà ad alta disponibilità (HA) per i diversi requisiti di sistema. Il initial_standbys variabile (vedi config.yml ) è la chiave per designare le proprietà HA del cluster durante l'operazione di aggiornamento.
Ad esempio, se initial_standbys è impostato su 1 (può essere impostato su qualsiasi numero consentito dalla capacità del cluster), ciò significa che ci sarà 1 standby creato nel cluster aggiornato insieme al master prima dell'avvio della replica. In altre parole, se hai 4 server e imposti initial_standbys su 1, avrai 1 server primario e 1 server di standby nella nuova versione aggiornata, oltre a 1 server primario e 1 server di standby nella vecchia versione.
Questa opzione consente di riutilizzare i server esistenti mentre l'aggiornamento è ancora in corso. Nell'esempio di 4 server, i vecchi server primario e di standby possono essere ricostruiti come 2 nuovi server di standby al termine della replica.
Quando initial_standbys è impostata su 0, non ci saranno server di standby iniziali creati nel nuovo cluster prima dell'inizio della replica.
Se il initial_standbys la configurazione sembra confusa, non ti preoccupare. Questo verrà spiegato meglio nel prossimo post del blog quando discuteremo di due diversi casi di studio.
Infine, il file di configurazione consente di specificare i gruppi di server vecchi e nuovi. Questo potrebbe essere fornito in due modi. Innanzitutto, se esiste un cluster esistente, gli indirizzi IP dei server (possono essere sia bare metal che server virtuali ) deve essere inserito in hosts.ini file considerando le proprietà HA desiderate durante l'operazione di aggiornamento.
Il secondo modo è eseguire provision.yml playbook (questo è il modo in cui ho eseguito il provisioning delle istanze cloud, ma puoi utilizzare i tuoi script di provisioning o eseguire il provisioning manuale delle istanze ) per eseguire il provisioning di server Linux vuoti nel cloud (istanze AWS EC2) e ottenere gli indirizzi IP dei server in hosts.ini file. Ad ogni modo, config.yml otterrà informazioni sull'host tramite hosts.ini file.
Flusso di lavoro del processo di aggiornamento
Dopo aver spiegato il file di configurazione (config.yml ) utilizzato da pglupgrade playbook, possiamo spiegare il flusso di lavoro del processo di aggiornamento.
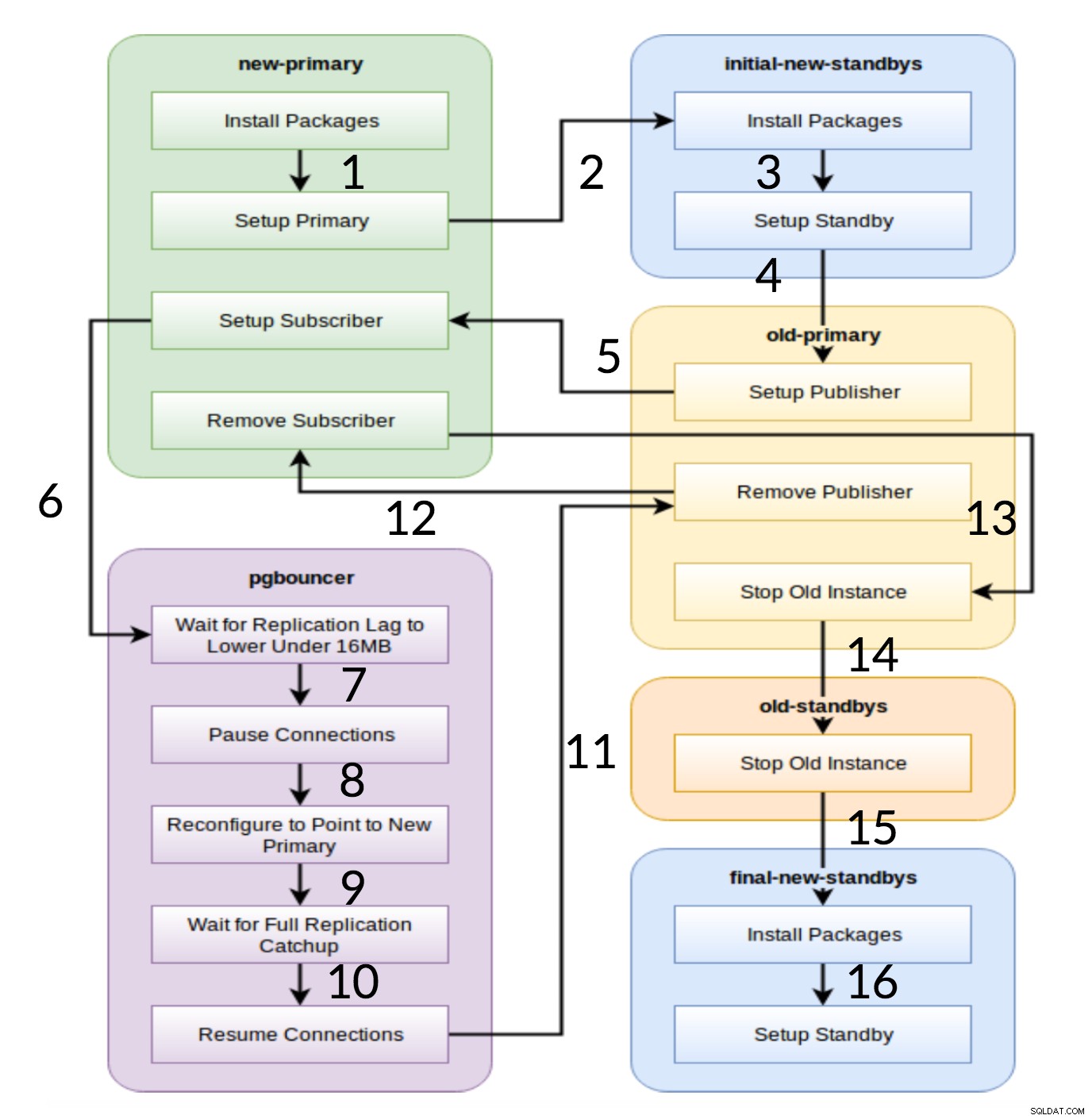
Flusso di lavoro Pglupgrade
Come si vede dal diagramma sopra, ci sono sei gruppi di server che vengono generati all'inizio in base alla configurazione (entrambi hosts.ini e il config.yml ). Il new-primary e old-primary i gruppi avranno sempre un server, pgbouncer il gruppo può avere uno o più server e tutti i gruppi di standby possono avere zero o più server al loro interno. Per quanto riguarda l'attuazione, l'intero processo è suddiviso in otto fasi. Ogni passaggio corrisponde a una riproduzione nel playbook di pgupgrade, che esegue le attività richieste sui gruppi host assegnati. Il processo di aggiornamento viene spiegato attraverso le seguenti riproduzioni:
- Crea host in base alla configurazione: Gioco di preparazione che crea gruppi interni di server in base alla configurazione. Il risultato di questo gioco (in combinazione con
hosts.inicontent) sono i sei gruppi di server (illustrati con colori diversi nel diagramma del flusso di lavoro) che verranno utilizzati dalle seguenti sette riproduzioni. - Imposta un nuovo cluster con standby/i iniziali: Imposta un cluster PostgreSQL vuoto con i nuovi standby/i primari e iniziali (se presenti). Garantisce che non rimangano residui dalle installazioni di PostgreSQL dall'utilizzo precedente.
- Modifica il vecchio primario per supportare la replica logica: Installa l'estensione pglogic. Quindi imposta l'editore aggiungendo tutte le tabelle e le sequenze alla replica.
- Replica alla nuova primaria: Imposta l'abbonato sul nuovo master che funge da trigger per avviare la replica logica. Questa riproduzione termina la replica dei dati esistenti e inizia a recuperare ciò che è cambiato da quando è iniziata la replica.
- Passa pgbouncer (e applicazioni) alla nuova primaria: Quando il ritardo di replica converge a zero, sospende pgbouncer per cambiare l'applicazione gradualmente. Quindi punta pgbouncer config al nuovo primario e attende che la differenza di replica arrivi a zero. Infine, pgbouncer viene ripreso e tutte le transazioni in attesa vengono propagate al nuovo primario e lì iniziano l'elaborazione. Gli standby iniziali sono già in uso e rispondono alle richieste di lettura.
- Ripulisci la configurazione della replica tra il vecchio primario e il nuovo primario: Termina la connessione tra il vecchio e il nuovo server primari. Poiché tutte le applicazioni vengono spostate sul nuovo server primario e l'aggiornamento viene eseguito, la replica logica non è più necessaria. La replica tra i server primari e di standby continua con la replica fisica.
- Interrompi il vecchio cluster: Il servizio Postgres viene interrotto nei vecchi host per garantire che nessuna applicazione possa più connettersi ad esso.
- Riconfigura il resto degli standby per il nuovo primario: Ricostruisce altri standby se sono presenti host rimanenti diversi dagli standby iniziali. Nel secondo caso di studio, non ci sono server in standby rimanenti da ricostruire. Questo passaggio offre la possibilità di ricostruire il vecchio server primario come nuovo standby se indicato nel gruppo new-standbys su hosts.ini. La riutilizzabilità dei server esistenti (anche il vecchio primario) si ottiene utilizzando il progetto di configurazione in standby in due fasi dello strumento pglupgrade. L'utente può specificare quali server devono diventare standby del nuovo cluster prima dell'aggiornamento e quali dovrebbero diventare standby dopo l'aggiornamento.
Conclusione
In questo post, abbiamo discusso i dettagli di implementazione e la progettazione ad alta disponibilità dello strumento pglupgrade. In tal modo, abbiamo anche menzionato alcuni concetti chiave dello sviluppo di Ansible (ad esempio playbook, inventario e file di configurazione) utilizzando lo strumento come esempio. Abbiamo illustrato il flusso di lavoro del processo di aggiornamento e riassunto come funziona ogni passaggio con una riproduzione corrispondente. Continueremo a spiegare pglupgrade mostrando casi di studio nei post prossimi di questa serie.
Grazie per aver letto!