Usi le sottoquery SQL o eviti di usarle?
Supponiamo che il responsabile del credito e delle riscossioni ti chieda di elencare i nomi delle persone, i loro saldi non pagati al mese e il saldo corrente e desideri che tu importi questo array di dati in Excel. Lo scopo è analizzare i dati e presentare un'offerta per rendere i pagamenti più leggeri per mitigare gli effetti della pandemia di COVID19.
Si sceglie di utilizzare una query e una sottoquery nidificata o un join? Quale decisione prenderai?
Subquery SQL:cosa sono?
Prima di approfondire la sintassi, l'impatto sulle prestazioni e le avvertenze, perché non definire prima una sottoquery?
In parole povere, una sottoquery è una query all'interno di una query. Mentre una query che incorpora una sottoquery è la query esterna, ci riferiamo a una sottoquery come query interna o selezione interna. E le parentesi racchiudono una sottoquery simile alla struttura seguente:
SELECT
col1
,col2
,(subquery) as col3
FROM table1
[JOIN table2 ON table1.col1 = table2.col2]
WHERE col1 <operator> (subquery)In questo post esamineremo i seguenti punti:
- Sintassi delle sottoquery SQL a seconda dei diversi tipi di sottoquery e operatori.
- Quando e in che tipo di istruzioni si può usare una sottoquery.
- Implicazioni sul rendimento rispetto a JOIN .
- Avvertenze comuni quando si utilizzano sottoquery SQL.
Come di consueto, forniamo esempi e illustrazioni per migliorare la comprensione. Ma tieni presente che l'obiettivo principale di questo post è sulle sottoquery in SQL Server.
Ora iniziamo.
Crea sottoquery SQL autonome o correlate
Per prima cosa, le sottoquery vengono classificate in base alla loro dipendenza dalla query esterna.
Lascia che ti descriva cos'è una sottoquery autonoma.
Le subquery autonome (o talvolta denominate subquery non correlate o semplici) sono indipendenti dalle tabelle nella query esterna. Permettetemi di illustrare questo:
-- Get sales orders of customers from Southwest United States
-- (TerritoryID = 4)
USE [AdventureWorks]
GO
SELECT CustomerID, SalesOrderID
FROM Sales.SalesOrderHeader
WHERE CustomerID IN (SELECT [CustomerID]
FROM [AdventureWorks].[Sales].[Customer]
WHERE TerritoryID = 4)Come illustrato nel codice precedente, la sottoquery (racchiusa tra parentesi di seguito) non ha riferimenti ad alcuna colonna nella query esterna. Inoltre, puoi evidenziare la sottoquery in SQL Server Management Studio ed eseguirla senza ricevere errori di runtime.
Il che, a sua volta, porta a un debug più semplice delle sottoquery autonome.
La prossima cosa da considerare sono le sottoquery correlate. Rispetto alla sua controparte autonoma, questa ha almeno una colonna a cui si fa riferimento dalla query esterna. Per chiarire, fornirò un esempio:
USE [AdventureWorks]
GO
SELECT DISTINCT a.LastName, a.FirstName, b.BusinessEntityID
FROM Person.Person AS p
JOIN HumanResources.Employee AS e ON p.BusinessEntityID = e.BusinessEntityID
WHERE 1262000.00 IN
(SELECT [SalesQuota]
FROM Sales.SalesPersonQuotaHistory spq
WHERE p.BusinessEntityID = spq.BusinessEntityID)Sei stato abbastanza attento da notare il riferimento a BusinessEntityID dalla Persona tavolo? Ben fatto!
Una volta che nella sottoquery viene fatto riferimento a una colonna della query esterna, diventa una sottoquery correlata. Un altro punto da considerare:se evidenzi una sottoquery e la esegui, si verificherà un errore.
E sì, hai assolutamente ragione:questo rende molto più difficile eseguire il debug delle sottoquery correlate.
Per rendere possibile il debug, segui questi passaggi:
- isola la sottoquery.
- sostituisci il riferimento alla query esterna con un valore costante.
Isolando la sottoquery per il debug apparirà così:
SELECT [SalesQuota]
FROM Sales.SalesPersonQuotaHistory spq
WHERE spq.BusinessEntityID = <constant value>Ora, scaviamo un po' più a fondo nell'output delle sottoquery.
Crea sottoquery SQL con 3 possibili valori restituiti
Bene, per prima cosa, pensiamo a quali valori restituiti possiamo aspettarci dalle sottoquery SQL.
In effetti, ci sono 3 possibili esiti:
- Un unico valore
- Valori multipli
- Interi tavoli
Valore singolo
Iniziamo con l'output a valore singolo. Questo tipo di sottoquery può apparire ovunque nella query esterna in cui è prevista un'espressione, ad esempio WHERE clausola.
-- Output a single value which is the maximum or last TransactionID
USE [AdventureWorks]
GO
SELECT TransactionID, ProductID, TransactionDate, Quantity
FROM Production.TransactionHistory
WHERE TransactionID = (SELECT MAX(t.TransactionID)
FROM Production.TransactionHistory t)Quando utilizzi un MAX (), si recupera un singolo valore. Questo è esattamente quello che è successo alla nostra sottoquery sopra. Usando l'uguale (= ) l'operatore indica a SQL Server che si prevede un singolo valore. Un'altra cosa:se la sottoquery restituisce più valori utilizzando uguale (= ) viene visualizzato un errore simile a quello qui sotto:
Msg 512, Level 16, State 1, Line 20
Subquery returned more than 1 value. This is not permitted when the subquery follows =, !=, <, <= , >, >= or when the subquery is used as an expression.Valori multipli
Successivamente, esaminiamo l'output multivalore. Questo tipo di sottoquery restituisce un elenco di valori con una singola colonna. Inoltre, agli operatori piace IN e NON IN aspetterà uno o più valori.
-- Output multiple values which is a list of customers with lastnames that --- start with 'I'
USE [AdventureWorks]
GO
SELECT [SalesOrderID], [OrderDate], [ShipDate], [CustomerID]
FROM Sales.SalesOrderHeader
WHERE [CustomerID] IN (SELECT c.[CustomerID] FROM Sales.Customer c
INNER JOIN Person.Person p ON c.PersonID = p.BusinessEntityID
WHERE p.lastname LIKE N'I%' AND p.PersonType='SC')Valori dell'intera tabella
E, ultimo ma non meno importante, perché non approfondire gli output di intere tabelle.
-- Output a table of values based on sales orders
USE [AdventureWorks]
GO
SELECT [ShipYear],
COUNT(DISTINCT [CustomerID]) AS CustomerCount
FROM (SELECT YEAR([ShipDate]) AS [ShipYear], [CustomerID]
FROM Sales.SalesOrderHeader) AS Shipments
GROUP BY [ShipYear]
ORDER BY [ShipYear]Hai notato il DA clausola?
Invece di usare una tabella, usava una sottoquery. Questa è chiamata tabella derivata o sottoquery di tabella.
E ora, lascia che ti presenti alcune regole di base quando usi questo tipo di query:
- Tutte le colonne nella sottoquery devono avere nomi univoci. Proprio come una tabella fisica, una tabella derivata dovrebbe avere nomi di colonna univoci.
- ORDINA PER non è consentito a meno che TOP è anche specificato. Questo perché la tabella derivata rappresenta una tabella relazionale in cui le righe non hanno un ordine definito.
In questo caso, una tabella derivata ha i vantaggi di una tabella fisica. Ecco perché nel nostro esempio possiamo utilizzare COUNT () in una delle colonne della tabella derivata.
Questo è tutto per quanto riguarda gli output delle sottoquery. Ma prima di andare oltre, potresti aver notato che la logica dietro l'esempio per più valori e anche per altri può essere eseguita anche usando un JOIN .
-- Output multiple values which is a list of customers with lastnames that start with 'I'
USE [AdventureWorks]
GO
SELECT o.[SalesOrderID], o.[OrderDate], o.[ShipDate], o.[CustomerID]
FROM Sales.SalesOrderHeader o
INNER JOIN Sales.Customer c on o.CustomerID = c.CustomerID
INNER JOIN Person.Person p ON c.PersonID = p.BusinessEntityID
WHERE p.LastName LIKE N'I%' AND p.PersonType = 'SC'In effetti, l'output sarà lo stesso. Ma quale si comporta meglio?
Prima di entrare in questo, lascia che ti dica che ho dedicato una sezione a questo argomento caldo. Lo esamineremo con piani di esecuzione completi e daremo un'occhiata alle illustrazioni.
Quindi, abbi pazienza per un momento. Discutiamo di un altro modo per inserire le tue sottoquery.
Altre istruzioni in cui è possibile utilizzare le sottoquery SQL
Finora abbiamo utilizzato le sottoquery SQL su SELECT dichiarazioni. E il fatto è che puoi goderti i vantaggi delle sottoquery su INSERT , AGGIORNAMENTO e ELIMINA o in qualsiasi istruzione T-SQL che formi un'espressione.
Quindi, diamo un'occhiata a una serie di altri esempi.
Utilizzo di sottoquery SQL nelle istruzioni UPDATE
È abbastanza semplice includere sottoquery in UPDATE dichiarazioni. Perché non dai un'occhiata a questo esempio?
-- In the products inventory, transfer all products of Vendor 1602 to ----
-- location 6
USE [AdventureWorks]
GO
UPDATE [Production].[ProductInventory]
SET LocationID = 6
WHERE ProductID IN
(SELECT ProductID
FROM Purchasing.ProductVendor
WHERE BusinessEntityID = 1602)
GOHai visto cosa abbiamo fatto lì?
Il fatto è che puoi inserire sottoquery in WHERE clausola di un UPDATE dichiarazione.
Dal momento che non lo abbiamo nell'esempio, puoi anche utilizzare una sottoquery per il SET clausola come SET colonna =(sottoquery) . Ma attenzione:dovrebbe restituire un singolo valore perché altrimenti si verifica un errore.
Cosa faremo dopo?
Utilizzo di sottoquery SQL nelle istruzioni INSERT
Come già sai, puoi inserire record in una tabella utilizzando un SELECT dichiarazione. Sono sicuro che hai un'idea di quale sarà la struttura della sottoquery, ma dimostriamolo con un esempio:
-- Impose a salary increase for all employees in DepartmentID 6
-- (Research and Development) by 10 (dollars, I think)
-- effective June 1, 2020
USE [AdventureWorks]
GO
INSERT INTO [HumanResources].[EmployeePayHistory]
([BusinessEntityID]
,[RateChangeDate]
,[Rate]
,[PayFrequency]
,[ModifiedDate])
SELECT
a.BusinessEntityID
,'06/01/2020' as RateChangeDate
,(SELECT MAX(b.Rate) FROM [HumanResources].[EmployeePayHistory] b
WHERE a.BusinessEntityID = b.BusinessEntityID) + 10 as NewRate
,2 as PayFrequency
,getdate() as ModifiedDate
FROM [HumanResources].[EmployeeDepartmentHistory] a
WHERE a.DepartmentID = 6
and StartDate = (SELECT MAX(c.StartDate)
FROM HumanResources.EmployeeDepartmentHistory c
WHERE c.BusinessEntityID = a.BusinessEntityID)Allora, cosa stiamo guardando qui?
- La prima sottoquery recupera l'ultima retribuzione di un dipendente prima di aggiungere gli ulteriori 10.
- La seconda sottoquery ottiene l'ultimo record di stipendio del dipendente.
- Infine, il risultato di SELECT è inserito nella EmployeePayHistory tabella.
In altre istruzioni T-SQL
A parte SELECT , INSERIRE , AGGIORNAMENTO e ELIMINA , puoi anche utilizzare le sottoquery SQL in:
Dichiarazioni di variabili o istruzioni SET in stored procedure e funzioni
Consentitemi di chiarire utilizzando questo esempio:
DECLARE @maxTransId int = (SELECT MAX(TransactionID)
FROM Production.TransactionHistory)In alternativa, puoi farlo nel modo seguente:
DECLARE @maxTransId int
SET @maxTransId = (SELECT MAX(TransactionID)
FROM Production.TransactionHistory)Nelle espressioni condizionali
Perché non dai un'occhiata a questo esempio:
IF EXISTS(SELECT [Name] FROM sys.tables where [Name] = 'MyVendors')
BEGIN
DROP TABLE MyVendors
ENDA parte questo, possiamo farlo in questo modo:
IF (SELECT count(*) FROM MyVendors) > 0
BEGIN
-- insert code here
ENDCrea sottoquery SQL con confronto o operatori logici
Finora abbiamo visto l'uguale (= ) e l'operatore IN. Ma c'è molto altro da esplorare.
Utilizzo degli operatori di confronto
Quando un operatore di confronto come =, <,>, <>,>=o <=viene utilizzato con una sottoquery, la sottoquery deve restituire un singolo valore. Inoltre, si verifica un errore se la sottoquery restituisce più valori.
L'esempio seguente genererà un errore di runtime.
USE [AdventureWorks]
GO
SELECT b.LastName, b.FirstName, b.MiddleName, a.JobTitle, a.BusinessEntityID
FROM HumanResources.Employee a
INNER JOIN Person.Person b on a.BusinessEntityID = b.BusinessEntityID
INNER JOIN HumanResources.EmployeeDepartmentHistory c on a.BusinessEntityID
= c.BusinessEntityID
WHERE c.DepartmentID = 6
and StartDate = (SELECT d.StartDate
FROM HumanResources.EmployeeDepartmentHistory d
WHERE d.BusinessEntityID = a.BusinessEntityID)Sai cosa c'è che non va nel codice sopra?
Innanzitutto, il codice utilizza l'operatore uguale (=) con la sottoquery. Inoltre, la sottoquery restituisce un elenco di date di inizio.
Per risolvere il problema, fai in modo che la sottoquery utilizzi una funzione come MAX () nella colonna della data di inizio per restituire un singolo valore.
Utilizzo di operatori logici
Utilizzare EXISTS o NOT EXISTS
ESISTE restituisce VERO se la sottoquery restituisce qualsiasi riga. In caso contrario, restituisce FALSE . Nel frattempo, utilizzando NON ESISTE restituirà TRUE se non ci sono righe e FALSE , altrimenti.
Considera l'esempio seguente:
IF EXISTS(SELECT name FROM sys.tables where name = 'Token')
BEGIN
DROP TABLE Token
ENDPer prima cosa, permettetemi di spiegare. Il codice sopra rilascerà il token della tabella se si trova in sys.tables , ovvero se esiste nel database. Un altro punto:il riferimento al nome della colonna è irrilevante.
Perché?
Si scopre che il motore di database ha solo bisogno di ottenere almeno 1 riga utilizzando EXISTS . Nel nostro esempio, se la sottoquery restituisce una riga, la tabella verrà eliminata. Se invece la sottoquery non ha restituito una sola riga, le istruzioni successive non verranno eseguite.
Pertanto, la preoccupazione di ESISTE è solo righe e nessuna colonna.
Inoltre, ESISTE utilizza una logica a due valori:TRUE o FALSO . Non ci sono casi in cui restituirà NULL . La stessa cosa accade quando annulli ESISTE utilizzando NON .
Utilizzare IN o NOT IN
Una sottoquery introdotta con IN o NON IN restituirà un elenco di zero o più valori. E a differenza di ESISTE , è richiesta una colonna valida con il tipo di dati appropriato.
Permettetemi di chiarirlo con un altro esempio:
-- From the product inventory, extract the products that are available
-- (Quantity >0)
-- except for products from Vendor 1676, and introduce a price cut for the --- whole month of June 2020.
-- Insert the results in product price history.
USE [AdventureWorks]
GO
INSERT INTO [Production].[ProductListPriceHistory]
([ProductID]
,[StartDate]
,[EndDate]
,[ListPrice]
,[ModifiedDate])
SELECT
a.ProductID
,'06/01/2020' as StartDate
,'06/30/2020' as EndDate
,a.ListPrice - 2 as ReducedListPrice
,getdate() as ModifiedDate
FROM [Production].[ProductListPriceHistory] a
WHERE a.StartDate = (SELECT MAX(StartDate)
FROM Production.ProductListPriceHistory
WHERE ProductID = a.ProductID)
AND a.ProductID IN (SELECT ProductID
FROM Production.ProductInventory
WHERE Quantity > 0)
AND a.ProductID NOT IN (SELECT ProductID
FROM [Purchasing].[ProductVendor]
WHERE BusinessEntityID = 1676Come puoi vedere dal codice sopra, entrambi IN e NON IN vengono introdotti gli operatori. E in entrambi i casi, le righe verranno restituite. Ogni riga nella query esterna verrà confrontata con il risultato di ogni sottoquery per ottenere un prodotto disponibile e un prodotto che non è del fornitore 1676.
Nidificazione di sottoquery SQL
Puoi annidare sottoquery anche fino a 32 livelli. Tuttavia, questa capacità dipende dalla memoria disponibile del server e dalla complessità di altre espressioni nella query.
Qual è la tua opinione su questo?
Nella mia esperienza, non ricordo di aver nidificato fino a 4. Uso raramente 2 o 3 livelli. Ma sono solo io e le mie esigenze.
Che ne dici di un buon esempio per capirlo:
-- List down the names of employees who are also customers.
USE [AdventureWorks]
GO
SELECT
LastName
,FirstName
,MiddleName
FROM Person.Person
WHERE BusinessEntityID IN (SELECT BusinessEntityID
FROM Sales.Customer
WHERE BusinessEntityID IN
(SELECT BusinessEntityID
FROM HumanResources.Employee))Come possiamo vedere in questo esempio, la nidificazione ha raggiunto 2 livelli.
Le sottoquery SQL sono dannose per le prestazioni?
In poche parole:si e no. In altre parole, dipende.
E non dimenticare, questo è nel contesto di SQL Server.
Per cominciare, molte istruzioni T-SQL che utilizzano sottoquery possono in alternativa essere riscritte usando JOIN S. E le prestazioni per entrambi sono generalmente le stesse. Nonostante ciò, ci sono casi particolari in cui un join è più veloce. E ci sono casi in cui la sottoquery funziona più rapidamente.
Esempio 1
Esaminiamo un esempio di sottoquery. Prima di eseguirli, premi Control-M oppure abilita Includi piano di esecuzione effettivo dalla barra degli strumenti di SQL Server Management Studio.
USE [AdventureWorks]
GO
SELECT Name
FROM Production.Product
WHERE ListPrice = SELECT ListPrice
FROM Production.Product
WHERE Name = 'Touring End Caps')In alternativa, la query precedente può essere riscritta utilizzando un join che produca lo stesso risultato.
USE [AdventureWorks]
GO
SELECT Prd1.Name
FROM Production.Product AS Prd1
INNER JOIN Production.Product AS Prd2 ON (Prd1.ListPrice = Prd2.ListPrice)
WHERE Prd2.Name = 'Touring End Caps'Alla fine, il risultato per entrambe le query è 200 righe.
Inoltre, puoi controllare il piano di esecuzione per entrambe le istruzioni.
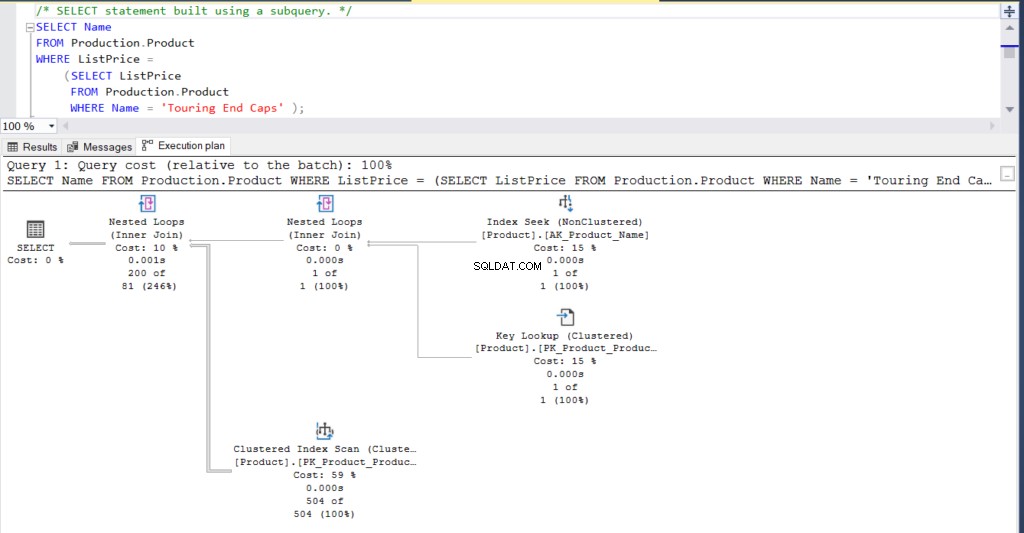
Figura 1:Piano di esecuzione utilizzando una sottoquery
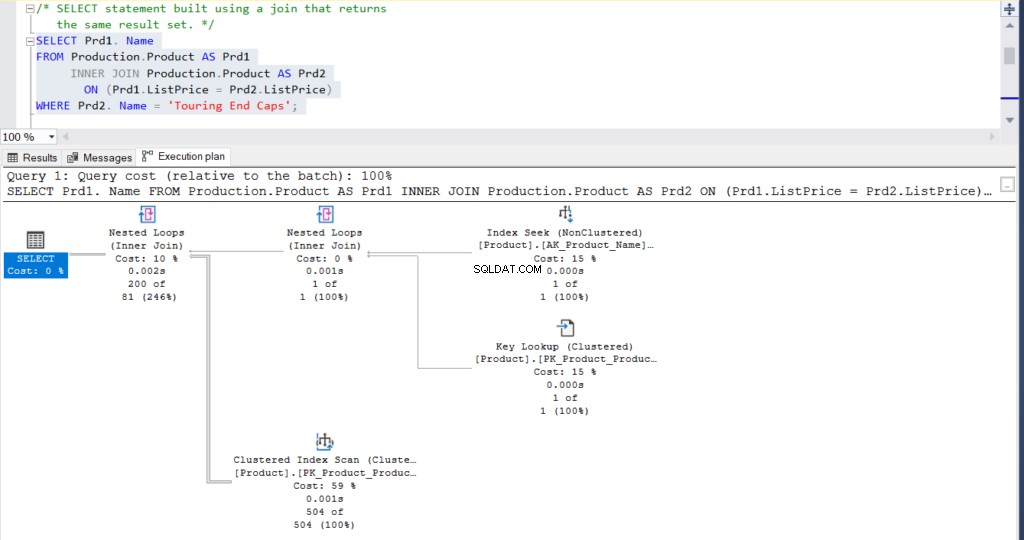
Figura 2:Piano di esecuzione utilizzando un join
Cosa ne pensi? Sono praticamente la stessa cosa? Fatta eccezione per il tempo effettivamente trascorso di ciascun nodo, tutto il resto è sostanzialmente lo stesso.
Ma ecco un altro modo per confrontarlo a parte le differenze visive. Suggerisco di utilizzare il Confronta Showplan .
Per eseguirlo, segui questi passaggi:
- Fai clic con il pulsante destro del mouse sul piano di esecuzione dell'istruzione utilizzando la sottoquery.
- Seleziona Salva piano di esecuzione come .
- Assegna un nome al file subquery-execution-plan.sqlplan .
- Vai al piano di esecuzione dell'istruzione utilizzando un join e fai clic con il pulsante destro del mouse.
- Seleziona Confronta Showplan .
- Seleziona il nome del file che hai salvato in #3.
Ora, dai un'occhiata per ulteriori informazioni su Confronta Showplan .
Dovresti essere in grado di vedere qualcosa di simile a questo:
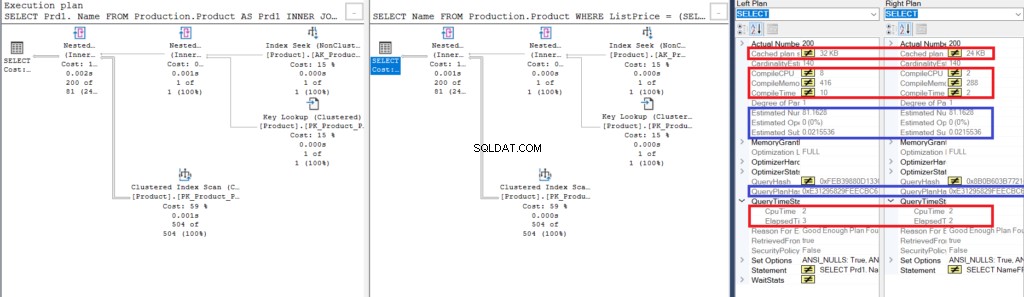
Figura 3:confronto di Showplan per l'utilizzo di un join con l'utilizzo di una sottoquery
Nota le somiglianze:
- Le righe ei costi stimati sono gli stessi.
- QueryPlanHash è anche lo stesso, il che significa che hanno piani di esecuzione simili.
Tuttavia, fai attenzione alle differenze:
- La dimensione del piano della cache è maggiore utilizzando il join rispetto all'utilizzo della sottoquery
- La CPU e il tempo di compilazione (in ms), inclusa la memoria in KB, utilizzati per analizzare, associare e ottimizzare il piano di esecuzione è maggiore utilizzando il join che utilizzando la sottoquery
- Il tempo della CPU e il tempo trascorso (in ms) per eseguire il piano sono leggermente superiori utilizzando il join rispetto alla sottoquery
In questo esempio, la sottoquery è un tic più veloce del join, anche se le righe risultanti sono le stesse.
Esempio 2
Nell'esempio precedente, abbiamo utilizzato solo una tabella. Nell'esempio che segue, utilizzeremo 3 tabelle diverse.
Facciamo in modo che questo accada:
-- Subquery example
USE [AdventureWorks]
GO
SELECT [SalesOrderID], [OrderDate], [ShipDate], [CustomerID]
FROM Sales.SalesOrderHeader
WHERE [CustomerID] IN (SELECT c.[CustomerID] FROM Sales.Customer c
INNER JOIN Person.Person p ON c.PersonID =
p.BusinessEntityID
WHERE p.PersonType='SC')-- Join example
USE [AdventureWorks]
GO
SELECT o.[SalesOrderID], o.[OrderDate], o.[ShipDate], o.[CustomerID]
FROM Sales.SalesOrderHeader o
INNER JOIN Sales.Customer c on o.CustomerID = c.CustomerID
INNER JOIN Person.Person p ON c.PersonID = p.BusinessEntityID
WHERE p.PersonType = 'SC'Entrambe le query restituiscono le stesse 3806 righe.
Quindi, diamo un'occhiata ai loro piani di esecuzione:
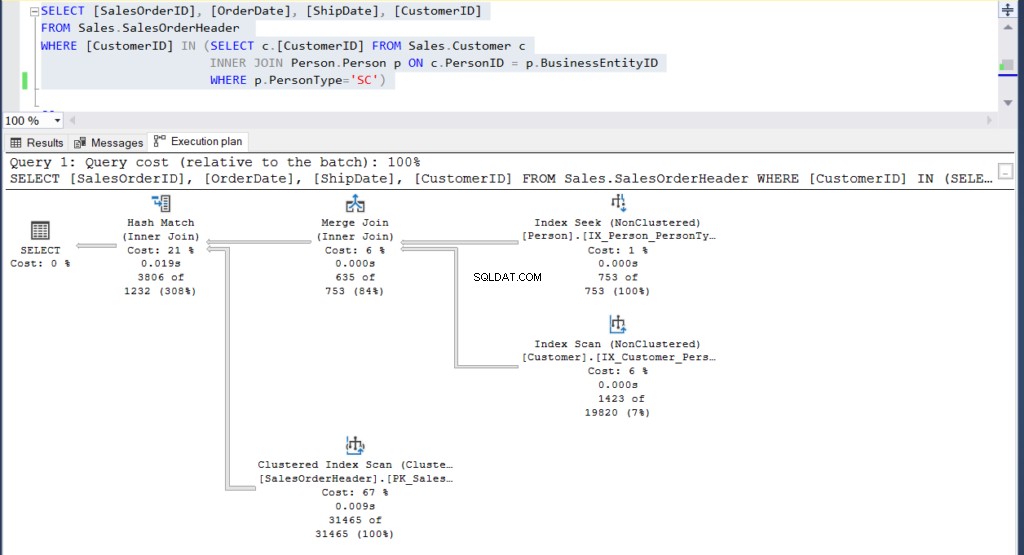
Figura 4:Piano di esecuzione per il nostro secondo esempio utilizzando una sottoquery
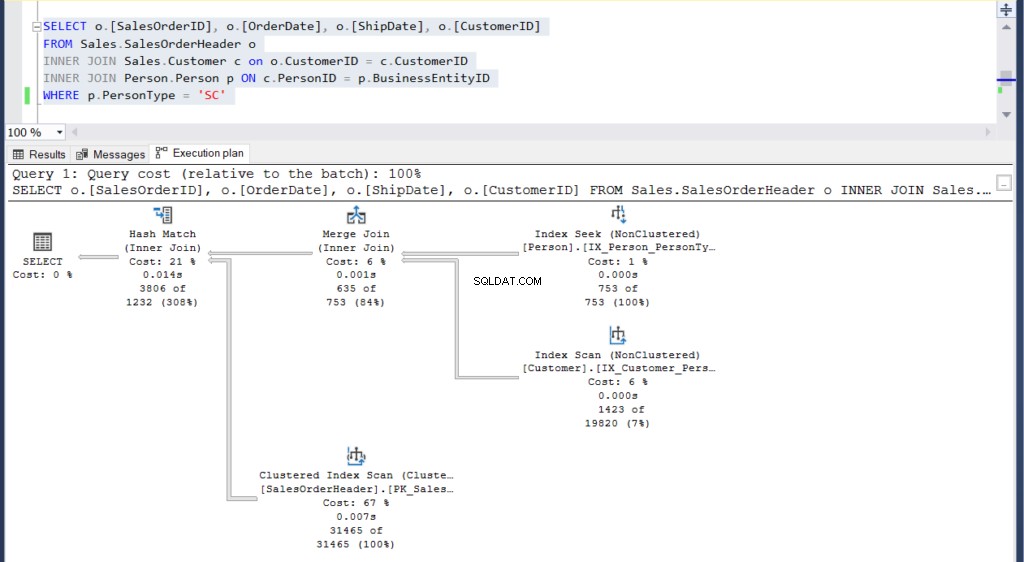
Figura 5:Piano di esecuzione per il nostro secondo esempio utilizzando un join
Riesci a vedere i 2 piani di esecuzione e trovare qualche differenza tra loro? A prima vista sembrano uguali.
Ma un esame più attento con il Confronta Showplan rivela cosa c'è veramente dentro.
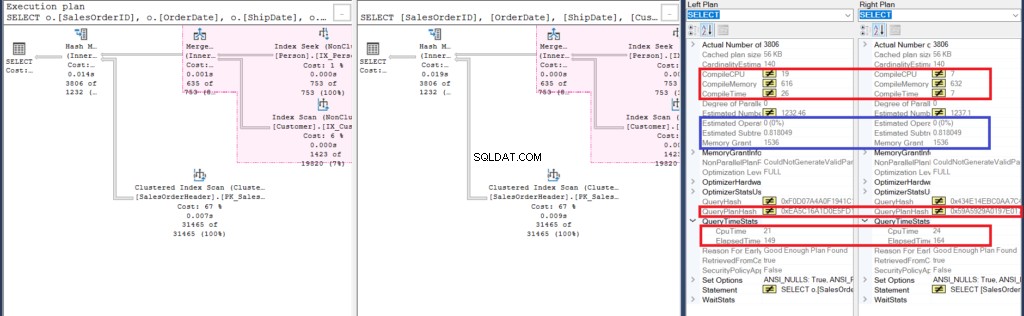
Figura 6:Dettagli di Confronta Showplan per il secondo esempio
Iniziamo analizzando alcune somiglianze:
- L'evidenziazione rosa nel piano di esecuzione rivela operazioni simili per entrambe le query. Poiché la query interna utilizza un join invece di nidificare le sottoquery, questo è abbastanza comprensibile.
- I costi stimati dell'operatore e del sottoalbero sono gli stessi.
Quindi, diamo un'occhiata alle differenze:
- In primo luogo, la compilazione ha richiesto più tempo quando abbiamo utilizzato i join. Puoi verificarlo in Compile CPU e Compile Time. Tuttavia, la query con una sottoquery ha richiesto una memoria di compilazione maggiore in KB.
- Quindi, il QueryPlanHash di entrambe le query è diverso, il che significa che hanno un piano di esecuzione diverso.
- Infine, il tempo trascorso e il tempo della CPU per eseguire il piano sono più veloci utilizzando il join rispetto all'utilizzo di una sottoquery.
Subquery vs. Join Performance Takeaway
È probabile che tu debba affrontare troppi altri problemi relativi alle query che possono essere risolti utilizzando un join o una sottoquery.
Ma la linea di fondo è che una sottoquery non è intrinsecamente negativa rispetto ai join. E non esiste una regola pratica che in una particolare situazione un join sia migliore di una subquery o viceversa.
Quindi, per assicurarti di avere la scelta migliore, controlla i piani di esecuzione. Lo scopo è ottenere informazioni dettagliate su come SQL Server elaborerà una determinata query.
Tuttavia, se scegli di utilizzare una sottoquery, tieni presente che potrebbero sorgere problemi che metteranno alla prova le tue abilità.
Avvertenze comuni nell'uso delle sottoquery SQL
Esistono 2 problemi comuni che possono causare un comportamento sfrenato delle query quando si utilizzano sottoquery SQL.
Il dolore della risoluzione dei nomi delle colonne
Questo problema introduce bug logici nelle tue query e potrebbero essere molto difficili da trovare. Un esempio può chiarire ulteriormente questo problema.
Iniziamo creando una tabella a scopo dimostrativo e popolandola con i dati.
USE [AdventureWorks]
GO
-- Create the table for our demonstration based on Vendors
CREATE TABLE Purchasing.MyVendors
(
BusinessEntity_id int,
AccountNumber nvarchar(15),
Name nvarchar(50)
)
GO
-- Populate some data to our new table
INSERT INTO Purchasing.MyVendors
SELECT BusinessEntityID, AccountNumber, Name
FROM Purchasing.Vendor
WHERE BusinessEntityID IN (SELECT BusinessEntityID
FROM Purchasing.ProductVendor)
AND BusinessEntityID like '14%'
GOOra che la tabella è apparecchiata, attiviamo alcune sottoquery utilizzandola. Ma prima di eseguire la query seguente, ricorda che gli ID fornitore che abbiamo utilizzato dal codice precedente iniziano con "14".
SELECT b.Name, b.ListPrice, a.BusinessEntityID
FROM Purchasing.ProductVendor a
INNER JOIN Production.Product b on a.ProductID = b.ProductID
WHERE a.BusinessEntityID IN (SELECT BusinessEntityID
FROM Purchasing.MyVendors)Il codice sopra viene eseguito senza errori, come puoi vedere di seguito. Ad ogni modo, presta attenzione all'elenco di BusinessEntityIDs .
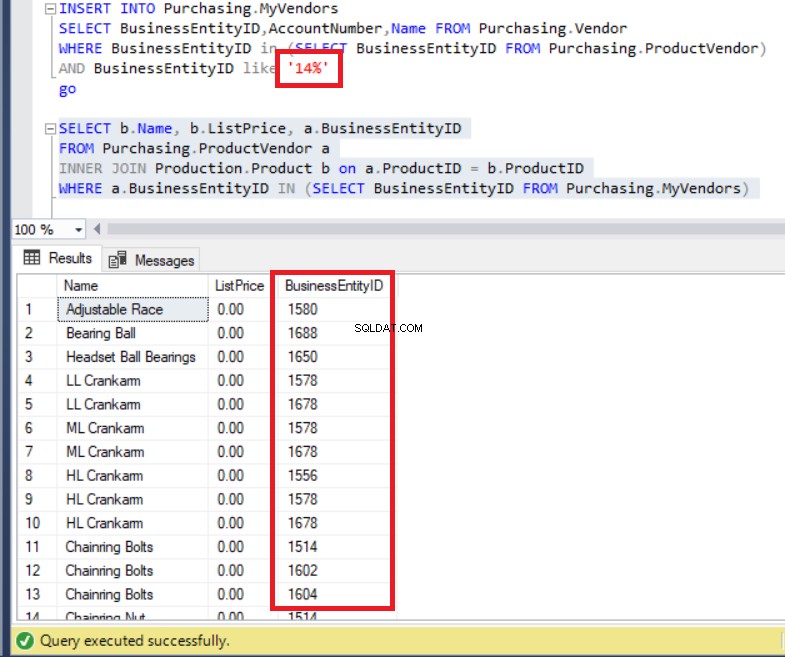
Figura 7:BusinessEntityIDs del set di risultati non sono coerenti con i record della tabella MyVendors
Non abbiamo inserito i dati con BusinessEntityID a partire da '14'? Allora qual è il problema? In effetti, possiamo vedere BusinessEntityIDs che iniziano con '15' e '16'. Da dove vengono?
In realtà, la query elencava tutti i dati da ProductVendor tabella.
In tal caso, potresti pensare che un alias risolverà questo problema in modo che faccia riferimento a MyVendors tabella proprio come quella qui sotto:
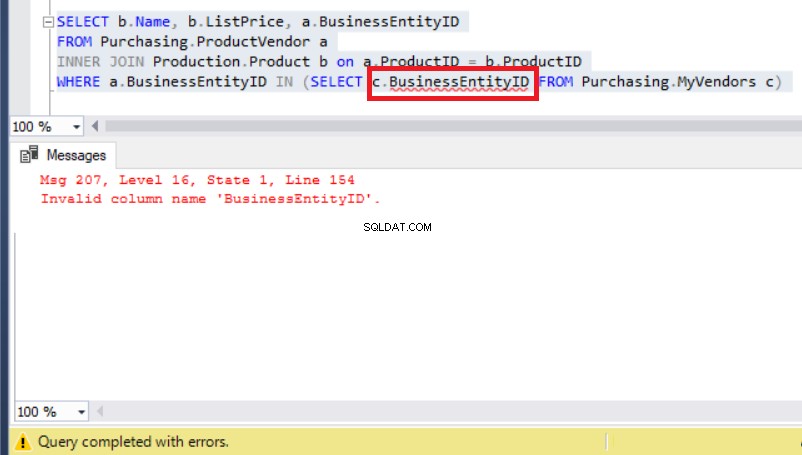
Figura 8:l'aggiunta di un alias a BusinessEntityID genera un errore
Solo che ora il vero problema si è presentato a causa di un errore di runtime.
Controlla MyVendors table di nuovo e lo vedrai invece di BusinessEntityID , il nome della colonna deve essere BusinessEntity_id (con un trattino basso).
Pertanto, l'utilizzo del nome della colonna corretto risolverà finalmente questo problema, come puoi vedere di seguito:
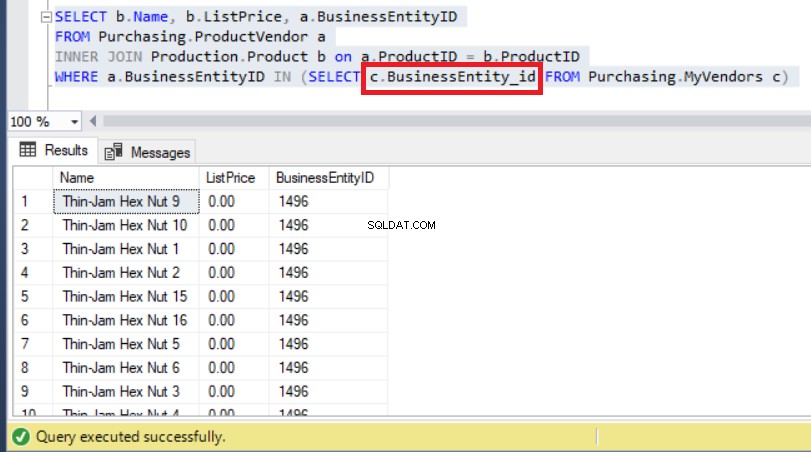
Figura 9:la modifica della sottoquery con il nome di colonna corretto ha risolto il problema
Come puoi vedere sopra, ora possiamo osservare BusinessEntityIDs a partire da '14' proprio come ci aspettavamo in precedenza.
Ma potresti chiederti: perché mai SQL Server ha consentito di eseguire correttamente la query in primo luogo?
Ecco il kicker:la risoluzione dei nomi delle colonne senza alias funziona nel contesto della sottoquery da se stessa andando alla query esterna. Ecco perché il riferimento a BusinessEntityID all'interno della sottoquery non ha generato un errore perché si trova all'esterno della sottoquery, in ProductVendor tabella.
In altre parole, SQL Server cerca la colonna senza alias BusinessEntityID in I miei venditori tavolo. Dato che non c'è, ha guardato fuori e l'ha trovato in ProductVendor tavolo. Pazzesco, vero?
Potresti dire che è un bug in SQL Server, ma, in realtà, è di progettazione nello standard SQL e Microsoft lo ha seguito.
Va bene, è chiaro, non possiamo fare nulla per lo standard, ma come possiamo evitare di incorrere in un errore?
- Per prima cosa, anteponi ai nomi delle colonne il nome della tabella o usa un alias. In altre parole, evita nomi di tabelle senza prefisso o senza alias.
- In secondo luogo, avere una denominazione coerente delle colonne. Evita di avere entrambi BusinessEntityID e BusinessEntity_id , per esempio.
Suona bene? Sì, questo porta un po' di sanità mentale nella situazione.
Ma questa non è la fine.
NULL pazzi
Come ho detto, c'è altro da coprire. T-SQL utilizza la logica a 3 valori a causa del supporto per NULL . E NULL può quasi farci impazzire quando utilizziamo le sottoquery SQL con NON IN .
Vorrei iniziare introducendo questo esempio:
SELECT b.Name, b.ListPrice, a.BusinessEntityID
FROM Purchasing.ProductVendor a
INNER JOIN Production.Product b on a.ProductID = b.ProductID
WHERE a.BusinessEntityID NOT IN (SELECT c.BusinessEntity_id
FROM Purchasing.MyVendors c)L'output della query ci porta a un elenco di prodotti non presenti in MyVendors tabella., come si vede di seguito:
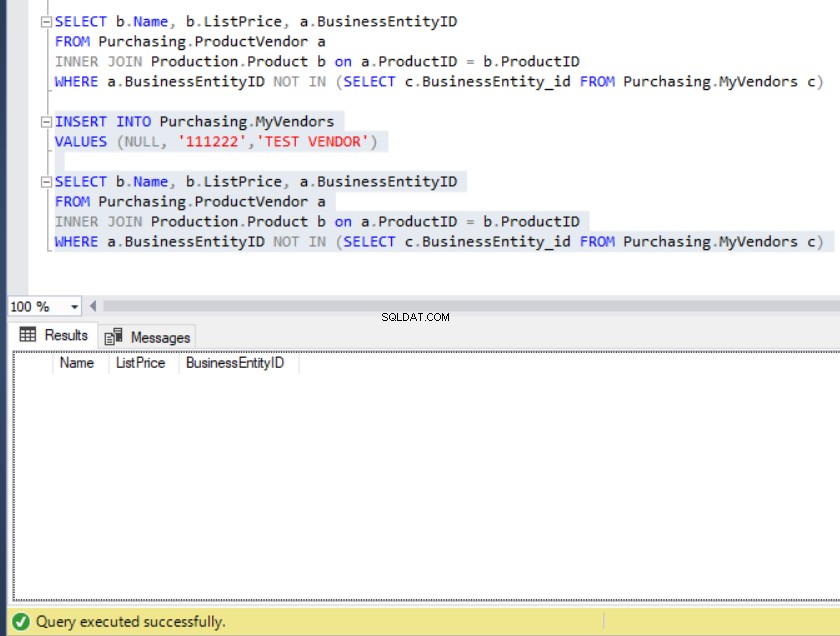
Figura 10:l'output della query di esempio utilizzando NOT IN
Supponiamo ora che qualcuno abbia inserito involontariamente un record in MyVendors tabella con un NULL BusinessEntity_id . Cosa faremo al riguardo?
Figura 11:il set di risultati diventa vuoto quando un NULL BusinessEntity_id viene inserito in MyVendors
Dove sono finiti tutti i dati?
Vedi, il NON l'operatore ha negato IN predicato. Quindi, NON VERO ora diventerà FALSO . Ma NON NULL è sconosciuto. Ciò ha indotto il filtro a scartare le righe SCONOSCIUTE, e questo è il colpevole.
Per assicurarti che questo non accada a te:
- O fai in modo che la colonna della tabella non consenta NULL se i dati non dovrebbero essere così.
- Oppure aggiungi il nome_colonna NON È NULL al tuo DOVE clausola. Nel nostro caso, la sottoquery è la seguente:
SELECT b.Name, b.ListPrice, a.BusinessEntityID
FROM Purchasing.ProductVendor a
INNER JOIN Production.Product b on a.ProductID = b.ProductID
WHERE a.BusinessEntityID NOT IN (SELECT c.BusinessEntity_id
FROM Purchasing.MyVendors c
WHERE c.BusinessEntity_id IS NOT NULL)Da asporto
Abbiamo parlato più o meno di sottoquery ed è giunto il momento di fornire le principali conclusioni di questo post sotto forma di un elenco riepilogativo:
Una sottoquery:
- è una query all'interno di una query.
- è racchiuso tra parentesi.
- può sostituire un'espressione ovunque.
- può essere utilizzato in SELECT , INSERIRE , AGGIORNAMENTO , ELIMINA o altre istruzioni T-SQL.
- può essere autonomo o correlato.
- emette valori singoli, multipli o di tabella.
- funziona su operatori di confronto come =, <>,>, <,>=, <=e operatori logici come IN /NON IN e ESISTE /NON ESISTE .
- non è cattivo o malvagio. Può avere prestazioni migliori o peggiori di JOIN s a seconda di una situazione. Quindi segui il mio consiglio e controlla sempre i piani di esecuzione.
- può avere un comportamento sgradevole su NULL s se utilizzato con NON IN e quando una colonna non è identificata in modo esplicito con una tabella o un alias di tabella.
Acquisisci familiarità con diversi riferimenti aggiuntivi per il tuo piacere di lettura:
- Discussion of Subqueries from Microsoft.
- IN (Transact-SQL)
- EXISTS (Transact-SQL)
- ALL (Transact-SQL)
- SOME | ANY (Transact-SQL)
- Comparison Operators