Di recente ho avuto molte conversazioni sui tipi di carichi di lavoro, in particolare per capire se un carico di lavoro è parametrizzato, ad hoc o misto. È una delle cose che esaminiamo durante un audit sanitario e Kimberly ha un'ottima query dalla sua cache del piano e l'ottimizzazione per i carichi di lavoro ad hoc post che fa parte del nostro kit di strumenti. Ho copiato la query di seguito e, se non l'hai mai eseguita in nessuno dei tuoi ambienti di produzione, trova sicuramente un po' di tempo per farlo.
SELECT objtype AS [CacheType],
COUNT_BIG(*) AS [Total Plans],
SUM(CAST(size_in_bytes AS DECIMAL(18, 2))) / 1024 / 1024 AS [Total MBs],
AVG(usecounts) AS [Avg Use Count],
SUM(CAST((CASE WHEN usecounts = 1 THEN size_in_bytes
ELSE 0
END) AS DECIMAL(18, 2))) / 1024 / 1024 AS [Total MBs – USE Count 1],
SUM(CASE WHEN usecounts = 1 THEN 1
ELSE 0
END) AS [Total Plans – USE Count 1]
FROM sys.dm_exec_cached_plans
GROUP BY objtype
ORDER BY [Total MBs – USE Count 1] DESC; Se eseguo questa query su un ambiente di produzione, potremmo ottenere un output simile al seguente:
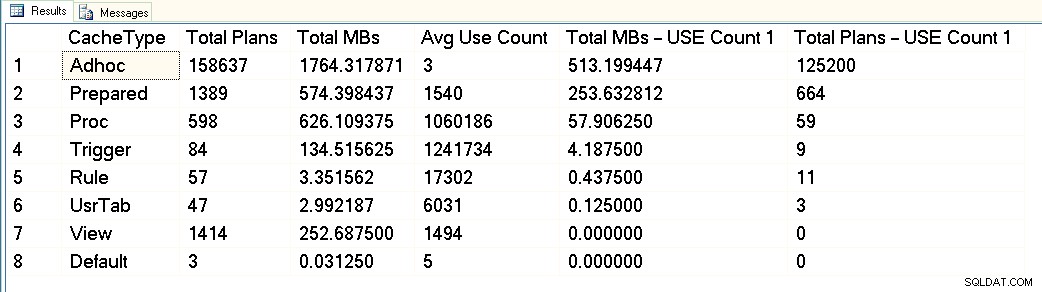
Da questo screenshot puoi vedere che abbiamo circa 3 GB in totale dedicati alla cache del piano e di questi 1,7 GB sono per i piani di oltre 158.000 query ad hoc. Di questi 1,7 GB, circa 500 MB vengono utilizzati per 125.000 piani che eseguono UNO solo tempo. Circa 1 GB della cache del piano è per piani preparati e procedurali e occupano solo circa 300 MB di spazio. Ma nota il conteggio medio dell'uso:ben oltre 1 milione per le procedure. Osservando questo output, classificherei questo carico di lavoro come misto:alcune query parametrizzate, altre ad hoc.
Il post sul blog di Kimberly discute le opzioni per la gestione di una cache dei piani piena di molte query ad hoc. Pianificare il rigonfiamento della cache è solo un problema con cui devi fare i conti quando hai un carico di lavoro ad hoc e in questo post voglio esplorare l'effetto che può avere sulla CPU come risultato di tutte le compilazioni che devono verificarsi. Quando una query viene eseguita in SQL Server, viene eseguita la compilazione e l'ottimizzazione e si verifica un sovraccarico associato a questo processo, che spesso si manifesta come costo della CPU. Una volta che un piano di query è nella cache, può essere riutilizzato. Le query parametrizzate possono finire per riutilizzare un piano che è già nella cache, perché il testo della query è esattamente lo stesso. Quando viene eseguita una query ad hoc, riutilizzerà il piano nella cache solo se ha l'esatto stesso testo e valore/i di input .
Configurazione
Per i nostri test genereremo una stringa casuale in TSQL e la concateneremo a una query in modo che ogni esecuzione abbia un valore letterale diverso. L'ho inserito in una stored procedure che chiama la query utilizzando Dynamic String Execution (EXEC @QueryString), quindi si comporta come un'istruzione ad hoc. Chiamarlo dall'interno di una stored procedure significa che possiamo eseguirlo un numero noto di volte.
USE [WideWorldImporters];
GO
DROP PROCEDURE IF EXISTS dbo.[RandomSelects];
GO
CREATE PROCEDURE dbo.[RandomSelects]
@NumRows INT
AS
DECLARE @ConcatString NVARCHAR(200);
DECLARE @QueryString NVARCHAR(1000);
DECLARE @RowLoop INT = 0;
WHILE (@RowLoop < @NumRows)
BEGIN
SET @ConcatString = CAST((CONVERT (INT, RAND () * 2500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1000) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1500) + 1) AS NVARCHAR(50));
SELECT @QueryString = N'SELECT w.ColorID, s.StockItemName
FROM Warehouse.Colors w
JOIN Warehouse.StockItems s
ON w.ColorID = s.ColorID
WHERE w.ColorName = ''' + @ConcatString + ''';';
EXEC (@QueryString);
SELECT @RowLoop = @RowLoop + 1;
END
GO
DBCC FREEPROCCACHE;
GO
EXEC dbo.[RandomSelects] @NumRows = 10;
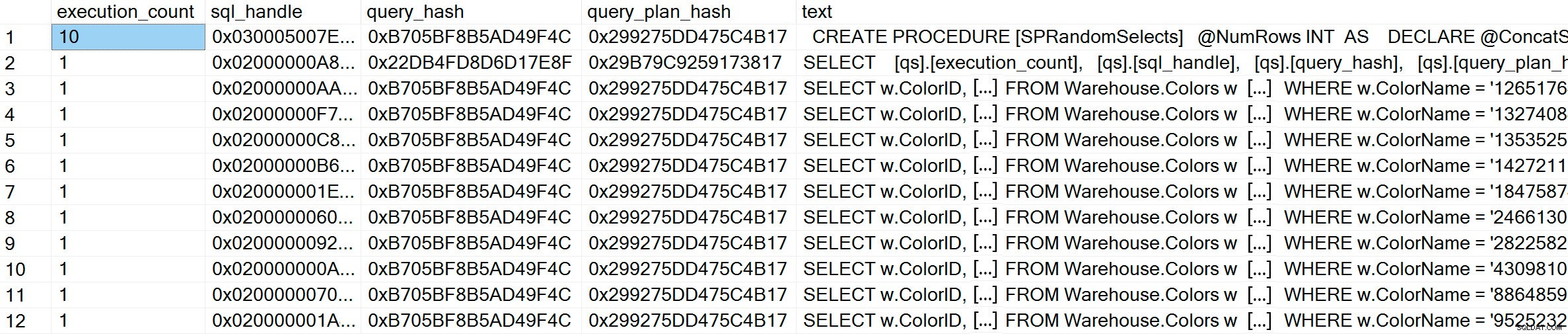
GO Dopo l'esecuzione, se controlliamo la cache del piano, possiamo vedere che abbiamo 10 voci univoche, ciascuna con un conteggio_esecuzione di 1 (ingrandire l'immagine se necessario per vedere i valori univoci per il predicato):
SELECT [qs].[execution_count], [qs].[sql_handle], [qs].[query_hash], [qs].[query_plan_hash], [st].[text] FROM sys.dm_exec_query_stats AS [qs] CROSS APPLY sys.dm_exec_sql_text ([qs].[sql_handle]) AS [st] CROSS APPLY sys.dm_exec_query_plan ([qs].[plan_handle]) AS [qp] WHERE [st].[text] LIKE '%Warehouse%' ORDER BY [st].[text], [qs].[execution_count] DESC; GO

Ora creiamo una stored procedure quasi identica che esegue la stessa query, ma parametrizzata:
USE [WideWorldImporters];
GO
DROP PROCEDURE IF EXISTS dbo.[SPRandomSelects];
GO
CREATE PROCEDURE dbo.[SPRandomSelects]
@NumRows INT
AS
DECLARE @ConcatString NVARCHAR(200);
DECLARE @QueryString NVARCHAR(1000);
DECLARE @RowLoop INT = 0;
WHILE (@RowLoop < @NumRows)
BEGIN
SET @ConcatString = CAST((CONVERT (INT, RAND () * 2500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1000) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1500) + 1) AS NVARCHAR(50))
SELECT w.ColorID, s.StockItemName
FROM Warehouse.Colors w
JOIN Warehouse.StockItems s
ON w.ColorID = s.ColorID
WHERE w.ColorName = @ConcatString;
SELECT @RowLoop = @RowLoop + 1;
END
GO
EXEC dbo.[SPRandomSelects] @NumRows = 10;
GO All'interno della cache dei piani, oltre alle 10 query ad hoc, vediamo una voce per la query parametrizzata che è stata eseguita 10 volte. Poiché l'input è parametrizzato, anche se nel parametro vengono passate stringhe molto diverse, il testo della query è esattamente lo stesso:
Test
Ora che abbiamo capito cosa succede nella cache del piano, creiamo più carico. Useremo un file della riga di comando che chiama lo stesso file .sql su 10 thread diversi, con ogni file che chiama la stored procedure 10.000 volte. Cancelleremo la cache del piano prima di iniziare e cattureremo la CPU totale e le compilazioni SQL al secondo con PerfMon durante l'esecuzione degli script.
Contenuto del file Adhoc.sql:
EXEC [WideWorldImporters].dbo.[RandomSelects] @NumRows = 10000;
Contenuto del file Parameterized.sql:
EXEC [WideWorldImporters].dbo.[SPRandomSelects] @NumRows = 10000;
Esempio di file di comando (visualizzato in Blocco note) che chiama il file .sql:
Esempio di file di comando (visualizzato in Blocco note) che crea 10 thread, ciascuno dei quali chiama il file Run_Adhoc.cmd:
Dopo aver eseguito ciascuna serie di query 100.000 volte in totale, se osserviamo la cache dei piani vediamo quanto segue:

Ci sono più di 10.000 piani ad hoc nella cache dei piani. Potresti chiederti perché non esiste un piano per tutte le 100.000 query ad hoc eseguite e ha a che fare con il funzionamento della cache del piano (la dimensione è basata sulla memoria disponibile, quando i piani inutilizzati sono scaduti, ecc.). L'importante è che così esistono molti piani ad hoc, rispetto a quello che vediamo per il resto dei tipi di cache.
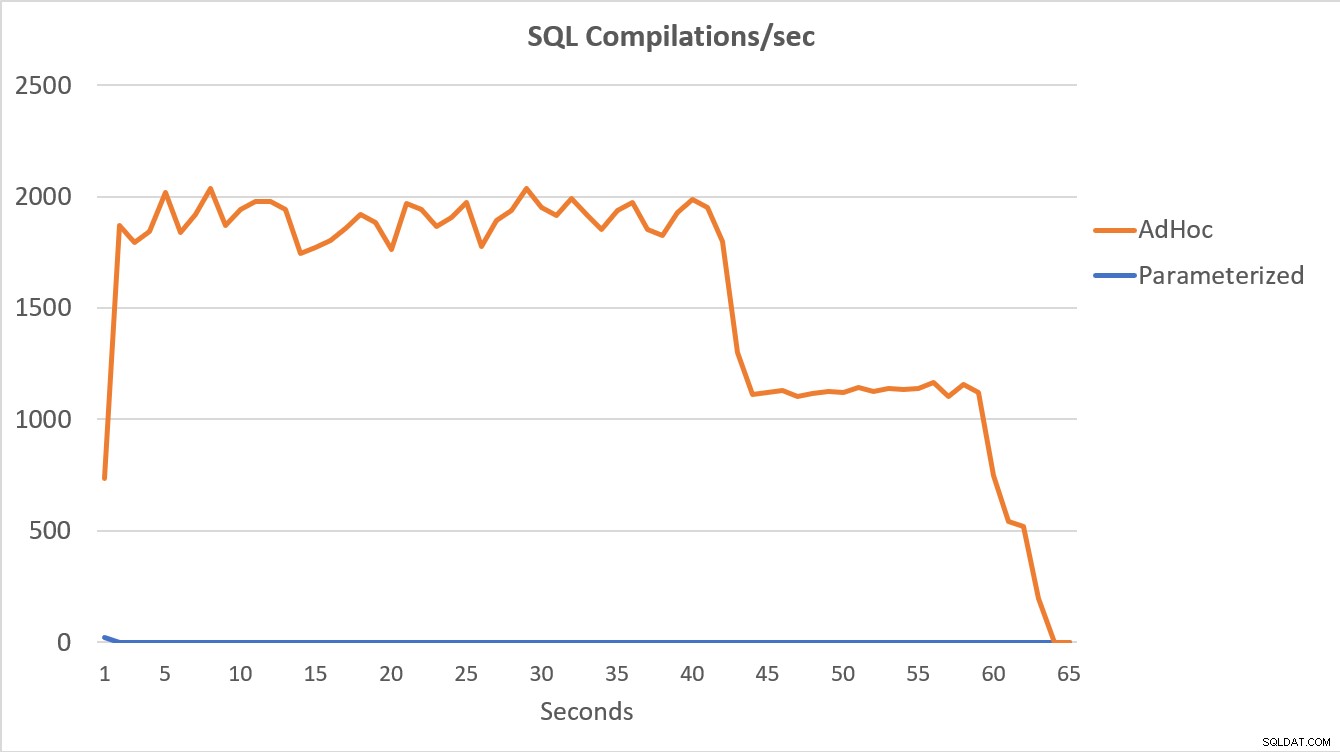
I dati PerfMon, illustrati di seguito, sono i più eloquenti. L'esecuzione delle 100.000 query parametrizzate è stata completata in meno di 15 secondi e all'inizio si è verificato un piccolo picco di Compilazioni/sec, appena percettibile sul grafico. Lo stesso numero di esecuzioni ad hoc ha richiesto poco più di 60 secondi per essere completato, con Compilazioni/sec che sono aumentate vicino a 2000 prima di scendere più vicino a 1000 intorno ai 45 secondi, con CPU vicina o al 100% per la maggior parte del tempo.
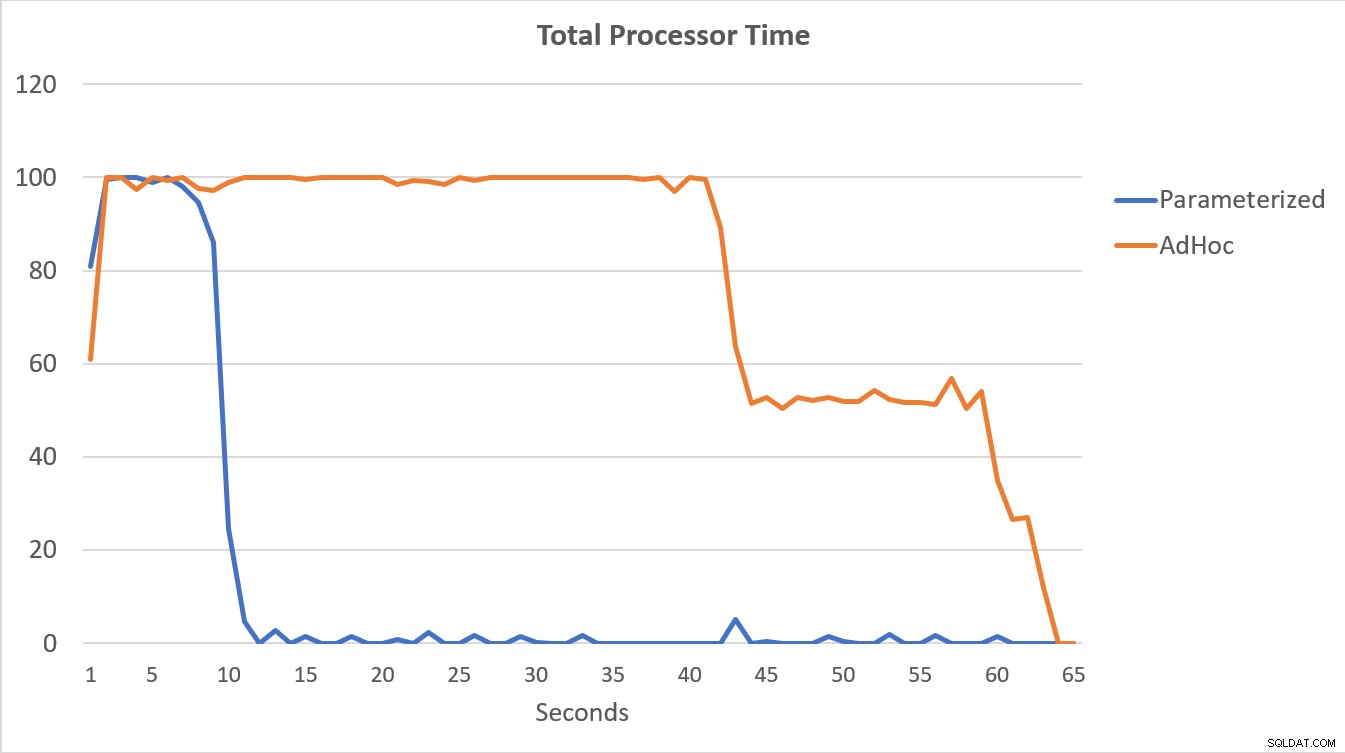
Riepilogo
Il nostro test è stato estremamente semplice in quanto abbiamo inviato variazioni solo per uno query ad hoc, mentre in un ambiente di produzione potremmo avere centinaia o migliaia di varianti diverse per centinaia o migliaia di diverse query ad hoc. L'impatto sulle prestazioni di queste query ad hoc non è solo l'aumento della cache del piano che si verifica, anche se la cache del piano è un ottimo punto di partenza se non si ha familiarità con il tipo di carico di lavoro di cui si dispone. Un volume elevato di query ad hoc può guidare le compilazioni e quindi la CPU, che a volte può essere mascherata aggiungendo più hardware, ma può assolutamente arrivare un punto in cui la CPU diventa un collo di bottiglia. Se ritieni che questo possa essere un problema, o potenziale problema, nel tuo ambiente, cerca di identificare quali query ad hoc vengono eseguite più frequentemente e vedi quali opzioni hai per parametrizzarle. Non fraintendermi:ci sono potenziali problemi con le query parametrizzate (ad es. stabilità del piano a causa dell'inclinazione dei dati) e questo è un altro problema che potresti dover risolvere. Indipendentemente dal carico di lavoro, è importante capire che raramente esiste un metodo "impostalo e dimenticalo" per la codifica, la configurazione, la manutenzione, ecc. Le soluzioni di SQL Server sono entità viventi che respirano in continua evoluzione e si prendono cura e alimentano continuamente di eseguire in modo affidabile. Uno dei compiti di un DBA è rimanere al passo con quel cambiamento e gestire le prestazioni nel miglior modo possibile, indipendentemente dal fatto che si tratti di sfide di prestazioni ad hoc o parametrizzate.