Introduzione
Raggiungere una registrazione minima utilizzando INSERT...SELECT in un vuoto la destinazione dell'indice cluster non è così semplice come descritto nella Guida al caricamento delle prestazioni dei dati .
Questo post fornisce nuovi dettagli sui requisiti per la registrazione minima quando la destinazione di inserimento è un indice cluster tradizionale vuoto. (La parola "tradizionale" lì esclude columnstore e ottimizzato per la memoria ("Hekaton") tabelle raggruppate). Per le condizioni che si applicano quando la tabella di destinazione è un heap, vedere l'articolo precedente di questa serie.
Riepilogo per le tabelle raggruppate
La Guida alle prestazioni del caricamento dei dati contiene un riepilogo di alto livello delle condizioni richieste per la registrazione minima in tabelle raggruppate:
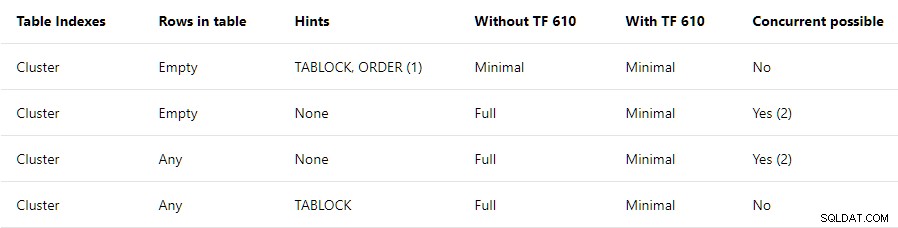
Questo post riguarda solo la riga superiore . Afferma che TABLOCK e ORDER sono richiesti suggerimenti, con una nota che dice:
Se si utilizza BULK INSERT è necessario utilizzare il suggerimento per l'ordine.
Bersaglio vuoto con blocco tavolo
La riga di riepilogo in alto suggerisce che tutti gli inserimenti in un indice cluster vuoto verranno registrati minimamente purché TABLOCK e ORDER i suggerimenti sono specificati. Il TABLOCK è richiesto un suggerimento per abilitare il RowSetBulk struttura utilizzata per i carichi sfusi della tabella dell'heap. Un ORDER è necessario un suggerimento per garantire che le righe arrivino all'Inserimento indice cluster operatore del piano nell'indice di destinazione ordine chiave . Senza questa garanzia, SQL Server potrebbe aggiungere righe di indice non ordinate correttamente, il che non sarebbe corretto.
A differenza di altri metodi di caricamento collettivo, non è possibile per specificare il ORDER richiesto suggerimento su un INSERT...SELECT dichiarazione. Questo suggerimento non è lo stesso come usando un ORDER BY clausola sul INSERT...SELECT dichiarazione. Un ORDER BY clausola su un INSERT garantisce solo il modo in cui qualsiasi identità vengono assegnati i valori, non l'ordine di inserimento delle righe.
Per INSERT...SELECT , SQL Server effettua la propria determinazione se assicurarsi che le righe vengano presentate all'Inserimento indice cluster operatore in ordine chiave o meno. L'esito di questa valutazione è visibile nei piani di esecuzione tramite il DMLRequestSort proprietà dell'Inserisci operatore. Il DMLRequestSort proprietà deve essere impostato su vero per INSERT...SELECT in un indice da registrare minimamente . Quando è impostato su falso , registrazione minima non può verificarsi.
Avere DMLRequestSort impostato su vero è l'unica garanzia accettabile dell'ordinamento dell'input di inserimento per SQL Server. Si potrebbe esaminare il piano di esecuzione e prevedere che le righe dovrebbero/dovranno/devono arrivare in ordine di indice cluster, ma senza le specifiche garanzie interne fornito da DMLRequestSort , quella valutazione non conta nulla.
Quando DMLRequestSort è vero , SQL Server può introdurre un ordinamento esplicito operatore nel piano di esecuzione. Se può garantire internamente l'ordine in altri modi, Ordina può essere omesso. Se sono disponibili sia le alternative di ordinamento che quelle di non ordinamento, l'ottimizzatore creerà un basato sui costi scelta. L'analisi dei costi non tiene conto della registrazione minima direttamente; è guidato dai vantaggi attesi dell'I/O sequenziale e dall'evitare la divisione delle pagine.
Condizioni DMLRequestSort
Entrambi i test seguenti devono essere superati affinché SQL Server possa scegliere di impostare DMLRequestSort a vero durante l'inserimento in un indice cluster vuoto con il blocco della tabella specificato:
- Una stima di più di 250 righe sul lato di input dell'Inserimento indice cluster operatore; e
- Una stima dimensione dei dati di più di 2 pagine . La dimensione stimata dei dati non è un numero intero, quindi un risultato di 2.001 pagine soddisferebbe questa condizione.
(Questo potrebbe ricordarti le condizioni per la registrazione minima dell'heap , ma la stima richiesta la dimensione dei dati qui è di due pagine anziché otto.)
Calcolo della dimensione dei dati
La dimensione stimata dei dati il calcolo qui è soggetto alle stesse stranezze descritte nell'articolo precedente per gli heap, tranne per il RID a 8 byte non è presente.
Per SQL Server 2012 e versioni precedenti, ciò significa 5 byte in più per riga sono inclusi nel calcolo della dimensione dei dati:un byte per un bit interno flag e quattro byte per l'unificatore (usato nel calcolo anche per indici univoci, che non memorizzano un unificatore ).
Per SQL Server 2014 e versioni successive, l'unificatore viene omesso correttamente per unico indici, ma il un byte in più per il bit interno il flag viene mantenuto.
Demo
Lo script seguente deve essere eseguito su un'istanza SQL Server di sviluppo in un nuovo database di test impostare per utilizzare il SIMPLE o BULK_LOGGED modello di recupero.
La demo carica 268 righe in una nuovissima tabella cluster utilizzando INSERT...SELECT con TABLOCK e rapporti sui record del registro delle transazioni generati.
IF OBJECT_ID(N'dbo.Test', N'U') IS NOT NULL
BEGIN
DROP TABLE dbo.Test;
END;
GO
CREATE TABLE dbo.Test
(
id integer NOT NULL IDENTITY
CONSTRAINT [PK dbo.Test (id)]
PRIMARY KEY,
c1 integer NOT NULL,
padding char(45) NOT NULL
DEFAULT ''
);
GO
-- Clear the log
CHECKPOINT;
GO
-- Insert rows
INSERT dbo.Test WITH (TABLOCK)
(c1)
SELECT TOP (268)
CHECKSUM(NEWID())
FROM master.dbo.spt_values AS SV;
GO
-- Show log entries
SELECT
FD.Operation,
FD.Context,
FD.[Log Record Length],
FD.[Log Reserve],
FD.AllocUnitName,
FD.[Transaction Name],
FD.[Lock Information],
FD.[Description]
FROM sys.fn_dblog(NULL, NULL) AS FD;
GO
-- Count the number of fully-logged rows
SELECT
[Fully Logged Rows] = COUNT_BIG(*)
FROM sys.fn_dblog(NULL, NULL) AS FD
WHERE
FD.Operation = N'LOP_INSERT_ROWS'
AND FD.Context = N'LCX_CLUSTERED'
AND FD.AllocUnitName = N'dbo.Test.PK dbo.Test (id)';
(Se esegui lo script su SQL Server 2012 o versioni precedenti, modifica il TOP clausola nel copione da 268 a 252, per ragioni che verranno spiegate tra poco.)
L'output mostra che tutte le righe inserite sono state registrate completamente nonostante il vuoto tabella cluster di destinazione e il TABLOCK suggerimento:
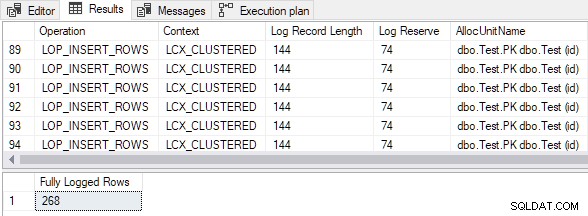
Dimensione dei dati di inserimento calcolata
Le proprietà del piano di esecuzione dell'Inserimento indice cluster l'operatore mostra che DMLRequestSort è impostato su falso . Questo perché sebbene il numero stimato di righe da inserire sia superiore a 250 (rispettando il primo requisito), il calcolato la dimensione dei dati non superare due pagine da 8 KB.
I dettagli del calcolo (da SQL Server 2014 in poi) sono i seguenti:
- Totale a lunghezza fissa dimensione della colonna =54 byte :
- Digita ID 104
bit=1 byte (interno). - Digita ID 56
integer=4 byte (idcolonna). - Digita ID 56
integer=4 byte (c1colonna). - Digita ID 175
char(45)=45 byte (paddingcolonna).
- Digita ID 104
- Bitmap nulla =3 byte .
- Intestazione riga sovraccarico =4 byte .
- Dimensione riga calcolata =54 + 3 + 4 =61 byte .
- Dimensione dati calcolata =61 byte * 268 righe =16.348 byte .
- Pagine di dati calcolati =16.384 / 8192 =1,99560546875 .
La dimensione della riga calcolata (61 byte) differisce dalla dimensione reale di archiviazione della riga (60 byte) per il byte aggiuntivo di metadati interni presenti nel flusso di inserimento. Il calcolo inoltre non tiene conto dei 96 byte utilizzati in ciascuna pagina dall'intestazione della pagina o di altre cose come l'overhead del controllo delle versioni delle righe. Lo stesso calcolo su SQL Server 2012 aggiunge altri 4 byte per riga per l'unificatore (che non è presente negli indici univoci come accennato in precedenza). I byte extra significano che ci si aspetta che meno righe si adattino a ciascuna pagina:
- Dimensione riga calcolata =61 + 4 =65 byte .
- Dimensione dati calcolata =65 byte * 252 righe =16.380 byte
- Pagine di dati calcolati =16.380 / 8192 =1,99951171875 .
Modifica del TOP la clausola da 268 righe a 269 (o da 252 a 253 per il 2012) rende il calcolo della dimensione dei dati prevista solo supera la soglia minima di 2 pagine:
- SQL Server 2014
- 61 byte * 269 righe =16.409 byte.
- 16.409 / 8192 =2,0030517578125 pagine.
- SQL Server 2012
- 65 byte * 253 righe =16.445 byte.
- 16.445 / 8192 =2,0074462890625 pagine.
Con la seconda condizione ora soddisfatta, DMLRequestSort è impostato su vero e registrazione minima viene raggiunto, come mostrato nell'output di seguito:
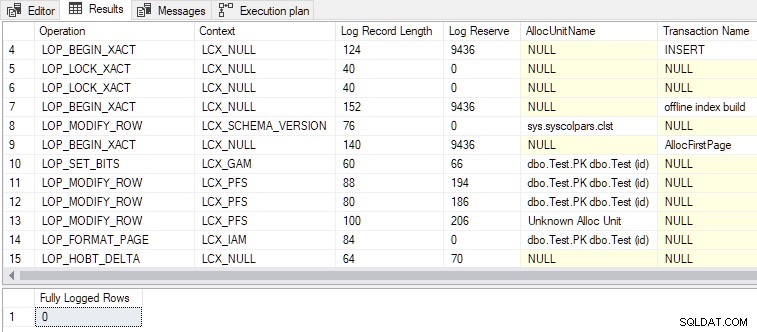
Alcuni altri punti di interesse:
- Viene generato un totale di 79 record di registro, rispetto ai 328 della versione completamente registrata. Un numero inferiore di record di registro è il risultato previsto di una registrazione minima.
- Il
LOP_BEGIN_XACTrecord nella registrazione minima i record riservano una quantità relativamente grande di spazio di registro (9436 byte ciascuno). - Uno dei nomi delle transazioni elencati nei record di log è "offline index build" . Anche se non abbiamo chiesto la creazione di un indice in quanto tale, il caricamento in blocco delle righe in un indice vuoto è essenzialmente la stessa operazione.
- Il registrato completo insert accetta un blocco esclusivo a livello di tabella (
Tab-X), mentre il registrato minimamente insert accetta la modifica dello schema (Sch-M) proprio come fa una build di indici offline "reale". - Caricamento collettivo di una tabella in cluster vuota utilizzando
INSERT...SELECTconTABLOCKeDMRequestSortimpostato su vero utilizza ilRowsetBulkmeccanismo, proprio come il registrato minimo i carichi heap effettuati nell'articolo precedente.
Stime di cardinalità
Fai attenzione alle stime di cardinalità bassa nell'Inserimento indice raggruppato operatore. Se una delle soglie richieste per impostare DMLRequestSort a vero non viene raggiunto a causa di una stima imprecisa della cardinalità, l'inserto verrà completamente registrato , indipendentemente dal numero effettivo di righe e dalla dimensione totale dei dati riscontrata al momento dell'esecuzione.
Ad esempio, modificando il TOP clausola nello script demo per utilizzare una variabile risulta in una cardinalità fissa ipotesi di 100 righe, che è inferiore al minimo di 251 righe:
-- Insert rows
DECLARE @NumRows bigint = 269;
INSERT dbo.Test WITH (TABLOCK)
(c1)
SELECT TOP (@NumRows)
CHECKSUM(NEWID())
FROM master.dbo.spt_values AS SV; Pianifica memorizzazione nella cache
Il DMLRequestSort la proprietà viene salvata come parte del piano memorizzato nella cache. Quando un piano memorizzato nella cache viene riutilizzato , il valore di DMLRequestSort è non ricalcolato al momento dell'esecuzione, a meno che non si verifichi una ricompilazione. Nota che le ricompilazioni non si verificano per TRIVIAL piani basati su modifiche nelle statistiche o nella cardinalità delle tabelle.
Un modo per evitare comportamenti imprevisti dovuti alla memorizzazione nella cache è utilizzare un OPTION (RECOMPILE) suggerimento. Ciò garantirà l'impostazione appropriata per DMLRequestSort viene ricalcolato, al costo di una compilazione ad ogni esecuzione.
Traccia bandiera
È possibile forzare DMLRequestSort da impostare su vero impostando non documentato e non supportato flag di traccia 2332, come ho scritto in Ottimizzazione delle query T-SQL che modificano i dati. Sfortunatamente, questo non influiscono su registrazione minima idoneità per le tabelle raggruppate vuote:l'inserto deve ancora essere stimato a più di 250 righe e 2 pagine. Questo flag di traccia ha effetto su altre registrazioni minime scenari, che sono trattati nella parte finale di questa serie.
Riepilogo
Caricamento in blocco di un vuoto indice cluster utilizzando INSERT...SELECT riutilizza il RowsetBulk meccanismo utilizzato per caricare in blocco le tabelle di heap. Ciò richiede il blocco della tabella (normalmente ottenuto con un TABLOCK suggerimento) e un ORDER suggerimento. Non c'è modo di aggiungere un ORDER suggerimento a un INSERT...SELECT dichiarazione. Di conseguenza, ottenendo una registrazione minima in una tabella cluster vuota richiede che DMLRequestSort proprietà dell'Inserimento indice cluster operatore è impostato su true . Questo garantisce a SQL Server che le righe presentate all'Inserisci l'operatore arriverà nell'ordine della chiave dell'indice di destinazione. L'effetto è lo stesso di quando si utilizza il ORDER suggerimento disponibile per altri metodi di inserimento collettivo come BULK INSERT e bcp .
In ordine per DMLRequestSort da impostare su vero , ci deve essere:
- Più di 250 righe stimato da inserire; e
- Una stima inserire una dimensione dei dati superiore a due pagine .
La stima inserire il calcolo della dimensione dei dati non corrisponde al risultato della moltiplicazione del piano di esecuzione numero stimato di righe e dimensione riga stimata proprietà nell'input dell'Inserisci operatore. Il calcolo interno (erroneamente) include una o più colonne interne nel flusso di inserimento, che non vengono mantenute nell'indice finale. Il calcolo interno inoltre non tiene conto delle intestazioni di pagina o di altri costi generali come il controllo delle versioni delle righe.
Durante il test o il debug di registrazione minima problemi, fai attenzione alle stime di cardinalità bassa e ricorda che l'impostazione di DMLRequestSort viene memorizzato nella cache come parte del piano di esecuzione.
La parte finale di questa serie descrive in dettaglio le condizioni richieste per ottenere una registrazione minima senza usare il RowsetBulk meccanismo. Questi corrispondono direttamente alle nuove funzionalità aggiunte con il flag di traccia 610 a SQL Server 2008, quindi modificate per essere attive per impostazione predefinita da SQL Server 2016 in poi.