Questo articolo è il secondo di una serie su bug, insidie e best practice di T-SQL. Questa volta mi concentro sui classici bug che coinvolgono le sottoquery. In particolare, mi occupo di errori di sostituzione e problemi logici a tre valori. Molti degli argomenti che tratterò nella serie sono stati suggeriti da altri MVP in una discussione che abbiamo avuto sull'argomento. Grazie a Erland Sommarskog, Aaron Bertrand, Alejandro Mesa, Umachandar Jayachandran (UC), Fabiano Neves Amorim, Milos Radivojevic, Simon Sabin, Adam Machanic, Thomas Grohser, Chan Ming Man e Paul White per i vostri suggerimenti!
Errore di sostituzione
Per dimostrare il classico errore di sostituzione, utilizzerò un semplice scenario ordini clienti. Esegui il codice seguente per creare una funzione di supporto denominata GetNums e per creare e popolare le tabelle Clienti e Ordini:
SET NOCOUNT ON;
USE tempdb;
GO
DROP TABLE IF EXISTS dbo.Orders;
DROP TABLE IF EXISTS dbo.Customers;
DROP FUNCTION IF EXISTS dbo.GetNums;
GO
CREATE FUNCTION dbo.GetNums(@low AS BIGINT, @high AS BIGINT) RETURNS TABLE
AS
RETURN
WITH
L0 AS (SELECT c FROM (SELECT 1 UNION ALL SELECT 1) AS D(c)),
L1 AS (SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B),
L2 AS (SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B),
L3 AS (SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B),
L4 AS (SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B),
L5 AS (SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B),
Nums AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L5)
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum;
GO
CREATE TABLE dbo.Customers
(
custid INT NOT NULL
CONSTRAINT PK_Customers PRIMARY KEY,
companyname VARCHAR(50) NOT NULL
);
INSERT INTO dbo.Customers WITH (TABLOCK) (custid, companyname)
SELECT n AS custid, CONCAT('Cust ', CAST(n AS VARCHAR(10))) AS companyname
FROM dbo.GetNums(1, 100);
CREATE TABLE dbo.Orders
(
orderid INT NOT NULL IDENTITY
CONSTRAINT PK_Orders PRIMARY KEY,
customerid INT NOT NULL,
filler BINARY(100) NOT NULL -- representing other columns
CONSTRAINT DFT_Orders_filler DEFAULT(0x)
);
INSERT INTO dbo.Orders WITH (TABLOCK) (customerid)
SELECT
C.n AS customerid
FROM dbo.GetNums(1, 10000) AS O
CROSS JOIN dbo.GetNums(1, 100) AS C
WHERE C.n NOT IN(17, 59);
CREATE INDEX idx_customerid ON dbo.Orders(customerid); Attualmente, la tabella Clienti ha 100 clienti con ID cliente consecutivi nell'intervallo da 1 a 100. 98 di questi clienti hanno ordini corrispondenti nella tabella Ordini. I clienti con ID 17 e 59 non hanno ancora effettuato ordini e quindi non sono presenti nella tabella Ordini.
Cerchi solo i clienti che hanno effettuato ordini e provi a raggiungere questo obiettivo utilizzando la seguente query (chiamala Query 1):
SET NOCOUNT OFF; SELECT custid, companyname FROM dbo.Customers WHERE custid IN (SELECT custid FROM dbo.Orders);
Dovresti recuperare 98 clienti, ma invece ottieni tutti i 100 clienti, inclusi quelli con ID 17 e 59:
custid companyname ------- ------------ 1 Cust 1 2 Cust 2 3 Cust 3 ... 16 Cust 16 17 Cust 17 18 Cust 18 ... 58 Cust 58 59 Cust 59 60 Cust 60 ... 98 Cust 98 99 Cust 99 100 Cust 100 (100 rows affected)
Riesci a capire cosa c'è che non va?
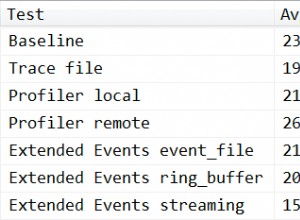
Per aumentare la confusione, esamina il piano per la query 1 come mostrato nella figura 1.
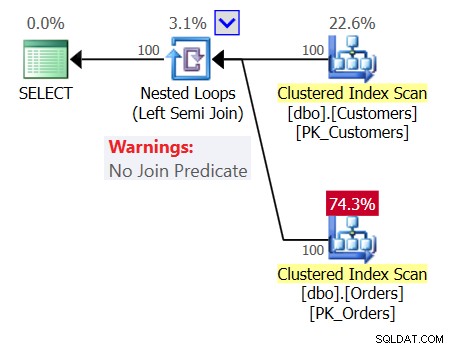 Figura 1:piano per la query 1
Figura 1:piano per la query 1
Il piano mostra un operatore Nested Loops (Left Semi Join) senza predicato di join, il che significa che l'unica condizione per restituire un cliente è avere una tabella Ordini non vuota, come se la query che hai scritto fosse la seguente:
SELECT custid, companyname FROM dbo.Customers WHERE EXISTS (SELECT * FROM dbo.Orders);
Probabilmente ti aspettavi un piano simile a quello mostrato nella Figura 2.
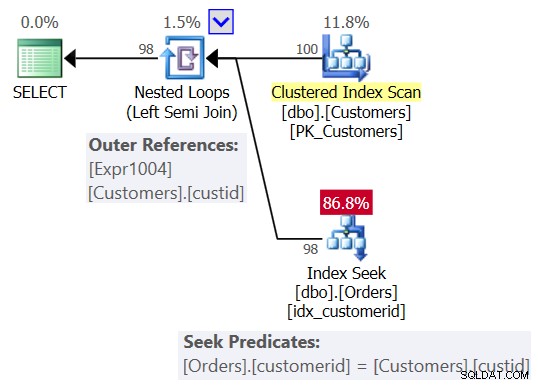 Figura 2:piano previsto per la query 1
Figura 2:piano previsto per la query 1
In questo piano viene visualizzato un operatore Nested Loops (Left Semi Join), con una scansione dell'indice cluster su Customers come input esterno e una ricerca nell'indice sulla colonna customerid in Orders come input interno. Viene inoltre visualizzato un riferimento esterno (parametro correlato) basato sulla colonna custid in Clienti e il predicato di ricerca Orders.customerid =Customers.custid.
Allora perché stai ricevendo il piano nella Figura 1 e non quello nella Figura 2? Se non l'hai ancora capito, osserva attentamente le definizioni di entrambe le tabelle, in particolare i nomi delle colonne, e i nomi delle colonne utilizzati nella query. Noterai che la tabella Clienti contiene gli ID cliente in una colonna chiamata custid e che la tabella Ordini contiene gli ID cliente in una colonna chiamata customerid. Tuttavia, il codice usa custid sia nelle query esterne che in quelle interne. Poiché il riferimento a custid nella query interna non è qualificato, SQL ServerSQL Server deve risolvere la tabella da cui proviene la colonna. Secondo lo standard SQL, SQL Server dovrebbe cercare prima la colonna nella tabella che viene interrogata nello stesso ambito, ma poiché non c'è una colonna chiamata custid in Orders, dovrebbe quindi cercarla nella tabella nell'esterno portata, e questa volta c'è una corrispondenza. Quindi, involontariamente, il riferimento a custid diventa implicitamente un riferimento correlato, come se avessi scritto la seguente query:
SELECT custid, companyname FROM dbo.Customers WHERE custid IN (SELECT Customers.custid FROM dbo.Orders);
A condizione che Orders non sia vuoto e che il valore custid esterno non sia NULL (non può essere nel nostro caso poiché la colonna è definita come NOT NULL), otterrai sempre una corrispondenza perché confronti il valore con se stesso . Quindi la query 1 diventa l'equivalente di:
SELECT custid, companyname FROM dbo.Customers WHERE EXISTS (SELECT * FROM dbo.Orders);
Se la tabella esterna supportava NULL nella colonna custid, la query 1 sarebbe stata equivalente a:
SELECT custid, companyname FROM dbo.Customers WHERE EXISTS (SELECT * FROM dbo.Orders) AND custid IS NOT NULL;
Ora capisci perché la query 1 è stata ottimizzata con il piano nella figura 1 e perché hai riavuto tutti i 100 clienti.
Qualche tempo fa ho visitato un cliente che aveva un bug simile, ma sfortunatamente con una dichiarazione DELETE. Pensa per un momento cosa significa. Tutte le righe della tabella sono state cancellate e non solo quelle che originariamente intendevano eliminare!
Per quanto riguarda le migliori pratiche che possono aiutarti a evitare tali bug, ce ne sono due principali. Innanzitutto, per quanto puoi controllarlo, assicurati di utilizzare nomi di colonna coerenti tra le tabelle per gli attributi che rappresentano la stessa cosa. In secondo luogo, assicurati di classificare i riferimenti di colonna qualificati nelle sottoquery, anche in quelle autonome in cui questa non è una pratica comune. Naturalmente, puoi utilizzare l'alias di tabella se preferisci non utilizzare nomi di tabelle completi. Applicando questa pratica alla nostra query, supponiamo che il tuo tentativo iniziale abbia utilizzato il codice seguente:
SELECT custid, companyname FROM dbo.Customers WHERE custid IN (SELECT O.custid FROM dbo.Orders AS O);
Qui non si consente la risoluzione implicita dei nomi delle colonne e pertanto SQL Server genera il seguente errore:
Msg 207, Level 16, State 1, Line 108 Invalid column name 'custid'.
Vai a controllare i metadati per la tabella Ordini, ti rendi conto che hai usato il nome di colonna sbagliato e risolvi la query (chiama questa Query 2), in questo modo:
SELECT custid, companyname FROM dbo.Customers WHERE custid IN (SELECT O.customerid FROM dbo.Orders AS O);
Questa volta ottieni il risultato giusto con 98 clienti, esclusi i clienti con ID 17 e 59:
custid companyname ------- ------------ 1 Cust 1 2 Cust 2 3 Cust 3 ... 16 Cust 16 18 Cust 18 .. 58 Cust 58 60 Cust 60 ... 98 Cust 98 99 Cust 99 100 Cust 100 (98 rows affected)
Ottieni anche il piano previsto mostrato in precedenza nella Figura 2.
Per inciso, è chiaro il motivo per cui Customers.custid è un riferimento esterno (parametro correlato) nell'operatore Nested Loops (Left Semi Join) nella Figura 2. Ciò che è meno ovvio è il motivo per cui Espr1004 appare nel piano anche come riferimento esterno. Il collega MVP di SQL Server Paul White teorizza che potrebbe essere correlato all'utilizzo di informazioni dalla foglia dell'input esterno per suggerire al motore di archiviazione di evitare sforzi duplicati da parte dei meccanismi di read-ahead. Puoi trovare i dettagli qui.
Problemi logici a tre valori
Un bug comune che coinvolge le sottoquery ha a che fare con i casi in cui la query esterna utilizza il predicato NOT IN e la sottoquery può potenzialmente restituire NULL tra i suoi valori. Ad esempio, supponiamo di dover essere in grado di memorizzare gli ordini nella nostra tabella Ordini con un NULL come ID cliente. Un caso del genere rappresenterebbe un ordine che non è associato ad alcun cliente; ad esempio, un ordine che compensa le incongruenze tra i conteggi dei prodotti effettivi e quelli registrati nel database.
Utilizzare il codice seguente per ricreare la tabella Ordini con la colonna custid che consente NULL e per ora popolarla con gli stessi dati di esempio di prima (con ordini per ID cliente da 1 a 100, esclusi 17 e 59):
DROP TABLE IF EXISTS dbo.Orders;
GO
CREATE TABLE dbo.Orders
(
orderid INT NOT NULL IDENTITY
CONSTRAINT PK_Orders PRIMARY KEY,
custid INT NULL,
filler BINARY(100) NOT NULL -- representing other columns
CONSTRAINT DFT_Orders_filler DEFAULT(0x)
);
INSERT INTO dbo.Orders WITH (TABLOCK) (custid)
SELECT
C.n AS customerid
FROM dbo.GetNums(1, 10000) AS O
CROSS JOIN dbo.GetNums(1, 100) AS C
WHERE C.n NOT IN(17, 59);
CREATE INDEX idx_custid ON dbo.Orders(custid); Si noti che già che ci siamo, ho seguito la procedura consigliata discussa nella sezione precedente per utilizzare nomi di colonna coerenti tra le tabelle per gli stessi attributi e ho chiamato la colonna nella tabella Ordini custid proprio come nella tabella Clienti.
Supponiamo di dover scrivere una query che restituisca i clienti che non hanno effettuato ordini. Ti viene in mente la seguente soluzione semplicistica usando il predicato NOT IN (chiamalo Query 3, prima esecuzione):
SELECT custid, companyname FROM dbo.Customers WHERE custid NOT IN (SELECT O.custid FROM dbo.Orders AS O);
Questa query restituisce l'output previsto con i clienti 17 e 59:
custid companyname ------- ------------ 17 Cust 17 59 Cust 59 (2 rows affected)
Viene effettuato un inventario nel magazzino dell'azienda e viene rilevata un'incoerenza tra la quantità effettiva di alcuni prodotti e la quantità registrata nel database. Quindi, aggiungi un ordine di compensazione fittizio per tenere conto dell'incoerenza. Poiché non esiste un cliente effettivo associato all'ordine, utilizzi un NULL come ID cliente. Esegui il codice seguente per aggiungere un'intestazione dell'ordine di questo tipo:
INSERT INTO dbo.Orders(custid) VALUES(NULL);
Esegui la query 3 per la seconda volta:
SELECT custid, companyname FROM dbo.Customers WHERE custid NOT IN (SELECT O.custid FROM dbo.Orders AS O);
Questa volta, ottieni un risultato vuoto:
custid companyname ------- ------------ (0 rows affected)
Chiaramente, qualcosa non va. Sai che i clienti 17 e 59 non hanno effettuato alcun ordine e infatti compaiono nella tabella Clienti ma non nella tabella Ordini. Tuttavia, il risultato della query afferma che non esiste un cliente che non abbia effettuato ordini. Riesci a capire dov'è il bug e come risolverlo?
Il bug ha a che fare con il NULL nella tabella Orders, ovviamente. Per SQL un NULL è un indicatore di un valore mancante che potrebbe rappresentare un cliente applicabile. SQL non sa che per noi il NULL rappresenta un cliente mancante e inapplicabile (irrilevante). Per tutti i clienti nella tabella Clienti presenti nella tabella Ordini, il predicato IN trova una corrispondenza che restituisce TRUE e la parte NOT IN lo rende FALSO, quindi la riga del cliente viene scartata. Fin qui tutto bene. Ma per i clienti 17 e 59, il predicato IN restituisce SCONOSCIUTO poiché tutti i confronti con valori non NULL producono FALSO e il confronto con NULL restituisce SCONOSCIUTO. Ricorda, SQL presuppone che NULL possa rappresentare qualsiasi cliente applicabile, quindi il valore logico UNKNOWN indica che non è noto se l'ID cliente esterno è uguale all'ID cliente NULL interno. FALSO O FALSO … O SCONOSCIUTO è SCONOSCIUTO. Quindi la parte NOT IN applicata a UNKNOWN restituisce ancora UNKNOWN.
In termini inglesi più semplici, hai chiesto di restituire i clienti che non hanno effettuato ordini. Quindi, naturalmente, la query scarta tutti i clienti dalla tabella Clienti che sono presenti nella tabella Ordini perché è noto con certezza che hanno effettuato ordini. Per quanto riguarda il resto (17 e 59 nel nostro caso) la query li scarta poiché in SQL, proprio come non è noto se hanno effettuato ordini, è altrettanto sconosciuto se non hanno effettuato ordini e il filtro ha bisogno di certezza (TRUE) in per restituire una riga. Che sottaceto!
Quindi, non appena il primo NULL entra nella tabella Orders, da quel momento ottieni sempre un risultato vuoto dalla query NOT IN. Che dire dei casi in cui non hai effettivamente NULL nei dati, ma la colonna consente NULL? Come hai visto nella prima esecuzione della Query 3, in tal caso ottieni il risultato corretto. Forse stai pensando che l'applicazione non introdurrà mai NULL nei dati, quindi non c'è nulla di cui preoccuparsi. Questa è una cattiva pratica per un paio di motivi. Per uno, se una colonna è definita come consentire NULL, è praticamente una certezza che i NULL alla fine arriveranno anche se non dovrebbero; è solo una questione di tempo. Potrebbe essere il risultato dell'importazione di dati errati, un bug nell'applicazione e altri motivi. Inoltre, anche se i dati non contengono NULL, se la colonna lo consente, l'ottimizzatore deve tenere conto della possibilità che i NULL siano presenti quando crea il piano di query e nella nostra query NOT IN ciò comporta una penalizzazione delle prestazioni . Per dimostrarlo, considera il piano per la prima esecuzione della query 3 prima di aggiungere la riga con NULL, come mostrato nella Figura 3.
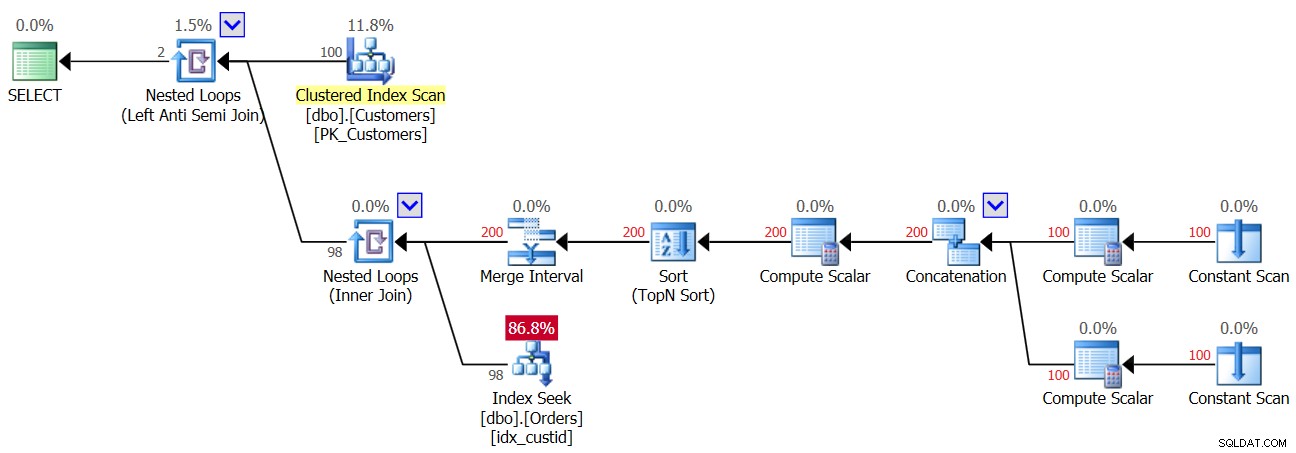 Figura 3:piano per la prima esecuzione della query 3
Figura 3:piano per la prima esecuzione della query 3
L'operatore Nested Loops in alto gestisce la logica Left Anti Semi Join. Si tratta essenzialmente di identificare le non corrispondenze e di cortocircuitare l'attività interiore non appena viene trovata una corrispondenza. La parte esterna del ciclo estrae tutti i 100 clienti dalla tabella Clienti, quindi la parte interna del ciclo viene eseguita 100 volte.
La parte interna del ciclo superiore esegue un operatore Nested Loops (Inner Join). La parte esterna del ciclo inferiore crea due righe per cliente, una per un caso NULL e un'altra per l'ID cliente corrente, in questo ordine. Non lasciare che l'operatore Merge Interval ti confonda. Viene normalmente utilizzato per unire intervalli sovrapposti, ad esempio un predicato come col1 BETWEEN 20 AND 30 OR col1 BETWEEN 25 AND 35 viene convertito in col1 BETWEEN 20 AND 35. Questa idea può essere generalizzata per rimuovere i duplicati in un predicato IN. Nel nostro caso, non possono esserci davvero duplicati. In termini semplificati, come accennato, pensa alla parte esterna del ciclo come alla creazione di due righe per cliente, la prima per un caso NULL e la seconda per l'ID cliente corrente. Quindi la parte interna del ciclo esegue prima una ricerca nell'indice idx_custid su Orders per cercare un NULL. Se viene trovato un NULL, non attiva la seconda ricerca per l'ID cliente corrente (ricorda il cortocircuito gestito dal loop Anti Semi Join in alto). In tal caso, il cliente esterno viene scartato. Ma se non viene trovato un NULL, il ciclo inferiore attiva una seconda ricerca per cercare l'ID cliente corrente negli Ordini. Se viene trovato, il cliente esterno viene scartato. Se non viene trovato, il cliente esterno viene restituito. Ciò significa che quando i NULL non sono presenti negli ordini, questo piano esegue due ricerche per cliente! Questo può essere osservato nella pianta come il numero di righe 200 nell'ingresso esterno dell'anello inferiore. Di conseguenza, ecco le statistiche di I/O che vengono riportate per la prima esecuzione:
Table 'Orders'. Scan count 200, logical reads 603
Il piano per la seconda esecuzione della Query 3, dopo l'aggiunta di una riga con NULL alla tabella Ordini, è mostrato nella Figura 4.
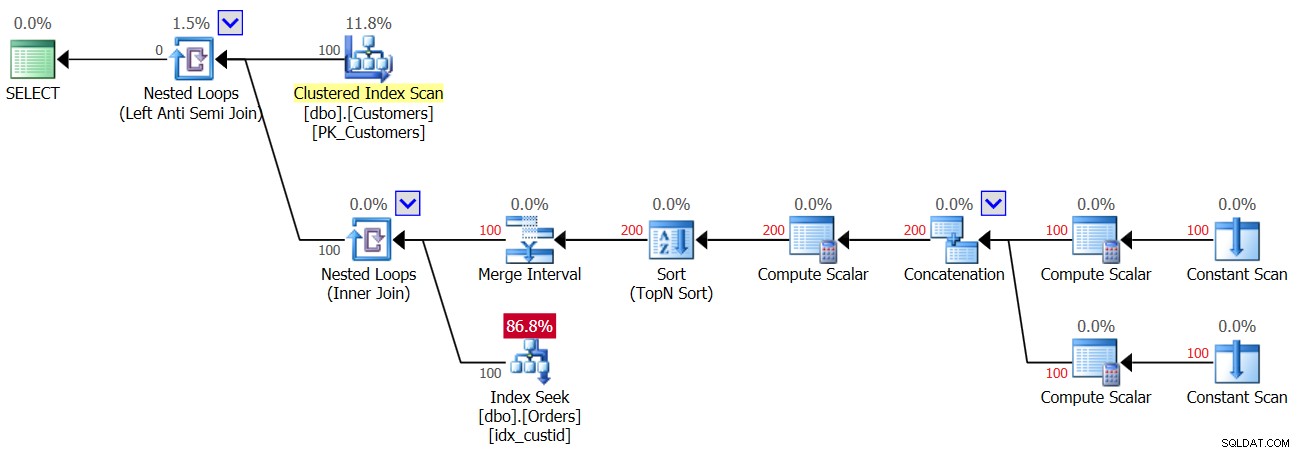 Figura 4:piano per la seconda esecuzione della query 3
Figura 4:piano per la seconda esecuzione della query 3
Poiché nella tabella è presente un NULL, per tutti i clienti, la prima esecuzione dell'operatore Index Seek trova una corrispondenza e quindi tutti i clienti vengono scartati. Quindi sì, facciamo solo una ricerca per cliente e non due, quindi questa volta ottieni 100 ricerche e non 200; tuttavia, allo stesso tempo questo significa che stai ottenendo un risultato vuoto!
Di seguito sono riportate le statistiche di I/O riportate per la seconda esecuzione:
Table 'Orders'. Scan count 100, logical reads 300
Una soluzione a questa attività quando sono possibili NULL tra i valori restituiti nella sottoquery è semplicemente filtrarli, in questo modo (chiamalo Soluzione 1/Query 4):
SELECT custid, companyname FROM dbo.Customers WHERE custid NOT IN (SELECT O.custid FROM dbo.Orders AS O WHERE O.custid IS NOT NULL);
Questo codice genera l'output previsto:
custid companyname ------- ------------ 17 Cust 17 59 Cust 59 (2 rows affected)
Lo svantaggio di questa soluzione è che devi ricordarti di aggiungere il filtro. Preferisco una soluzione che utilizzi il predicato NOT EXISTS, in cui la sottoquery ha una correlazione esplicita confrontando l'ID cliente dell'ordine con l'ID cliente del cliente, in questo modo (chiamalo Soluzione 2/Query 5):
SELECT C.custid, C.companyname FROM dbo.Customers AS C WHERE NOT EXISTS (SELECT * FROM dbo.Orders AS O WHERE O.custid = C.custid);
Ricorda che un confronto basato sull'uguaglianza tra un NULL e qualsiasi cosa produce UNKNOWN e UNKNOWN viene scartato da un filtro WHERE. Quindi, se i NULL esistono negli ordini, vengono eliminati dal filtro della query interna senza che tu debba aggiungere un trattamento NULL esplicito e quindi non devi preoccuparti se i NULL esistono o meno nei dati.
Questa query genera l'output previsto:
custid companyname ------- ------------ 17 Cust 17 59 Cust 59 (2 rows affected)
I piani per entrambe le soluzioni sono mostrati nella Figura 5.
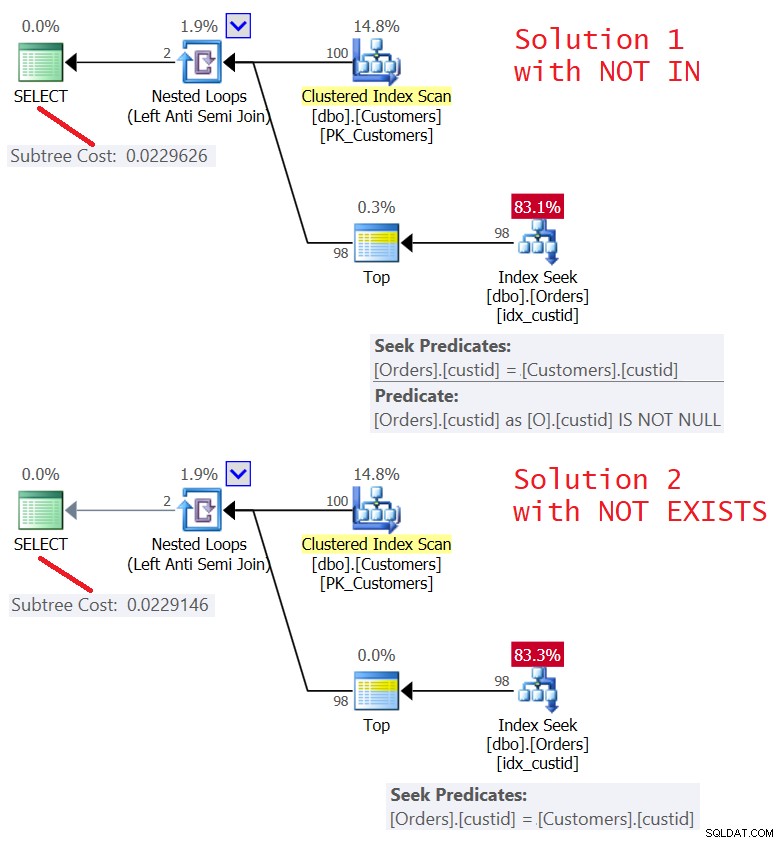 Figura 5:Piani per la query 4 (soluzione 1) e la query 5 (soluzione 2 )
Figura 5:Piani per la query 4 (soluzione 1) e la query 5 (soluzione 2 )
Come puoi vedere i piani sono quasi identici. Sono anche abbastanza efficienti, utilizzando un'ottimizzazione Left Semi Join con un cortocircuito. Entrambi eseguono solo 100 ricerche nell'indice idx_custid su Orders e, con l'operatore Top, applicano un cortocircuito dopo che una riga è stata toccata nella foglia.
Le statistiche di I/O per entrambe le query sono le stesse:
Table 'Orders'. Scan count 100, logical reads 348
Una cosa da considerare è se c'è qualche possibilità che la tabella esterna abbia NULL nella colonna correlata (custid nel nostro caso). È molto improbabile che sia rilevante in uno scenario come gli ordini dei clienti, ma potrebbe essere rilevante in altri scenari. In tal caso, entrambe le soluzioni gestiscono un NULL esterno in modo errato.
Per dimostrarlo, elimina e ricrea la tabella Clienti con un NULL come uno degli ID cliente eseguendo il codice seguente:
DROP TABLE IF EXISTS dbo.Customers;
GO
CREATE TABLE dbo.Customers
(
custid INT NULL
CONSTRAINT UNQ_Customers_custid UNIQUE CLUSTERED,
companyname VARCHAR(50) NOT NULL
);
INSERT INTO dbo.Customers WITH (TABLOCK) (custid, companyname)
SELECT CAST(NULL AS INT) AS custid, 'Cust NULL' AS companyname
UNION ALL
SELECT n AS custid, CONCAT('Cust ', CAST(n AS VARCHAR(10))) AS companyname
FROM dbo.GetNums(1, 100); La soluzione 1 non restituirà un NULL esterno indipendentemente dal fatto che sia presente o meno un NULL interno.
La soluzione 2 restituirà un NULL esterno indipendentemente dal fatto che sia presente o meno un NULL interno.
Se desideri gestire NULL come gestisci valori non NULL, ovvero restituire NULL se presente in Customers ma non in Orders e non restituirlo se presente in entrambi, devi modificare la logica della soluzione per utilizzare una distinzione confronto basato su un confronto basato sull'uguaglianza. Ciò può essere ottenuto combinando il predicato EXISTS e l'operatore dell'insieme EXCEPT, in questo modo (chiamare questa Soluzione 3/Query 6):
SELECT C.custid, C.companyname FROM dbo.Customers AS C WHERE EXISTS (SELECT C.custid EXCEPT SELECT O.custid FROM dbo.Orders AS O);
Poiché attualmente ci sono NULL sia in Clienti che in Ordini, questa query non restituisce correttamente il NULL. Ecco l'output della query:
custid companyname ------- ------------ 17 Cust 17 59 Cust 59 (2 rows affected)
Eseguire il codice seguente per rimuovere la riga con NULL dalla tabella Ordini ed eseguire nuovamente la Soluzione 3:
DELETE FROM dbo.Orders WHERE custid IS NULL; SELECT C.custid, C.companyname FROM dbo.Customers AS C WHERE EXISTS (SELECT C.custid EXCEPT SELECT O.custid FROM dbo.Orders AS O);
Questa volta, poiché un NULL è presente nei Clienti ma non negli Ordini, il risultato include il NULL:
custid companyname ------- ------------ NULL Cust NULL 17 Cust 17 59 Cust 59 (3 rows affected)
Il piano per questa soluzione è mostrato nella Figura 6:
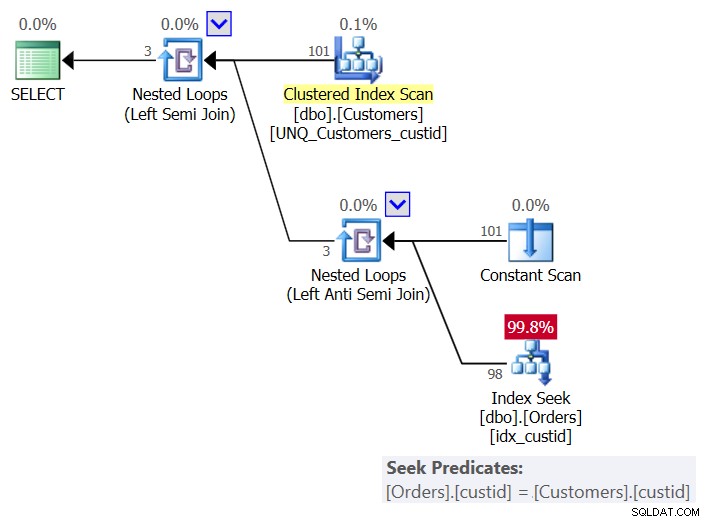 Figura 6:piano per la query 6 (soluzione 3)
Figura 6:piano per la query 6 (soluzione 3)
Per cliente, il piano utilizza un operatore di scansione costante per creare una riga con il cliente corrente e applica una singola ricerca nell'indice idx_custid sugli ordini per verificare se il cliente esiste negli ordini. Si finisce con una ricerca per cliente. Dal momento che attualmente abbiamo 101 clienti nella tabella, otteniamo 101 ricerche.
Ecco le statistiche di I/O per questa query:
Table 'Orders'. Scan count 101, logical reads 415
Conclusione
Questo mese ho trattato bug, insidie e best practice relativi alle sottoquery. Ho trattato errori di sostituzione e problemi logici a tre valori. Ricorda di utilizzare nomi di colonna coerenti tra le tabelle e di qualificare sempre le colonne nelle sottoquery, anche quando sono autonome. Ricorda inoltre di applicare un vincolo NOT NULL quando la colonna non dovrebbe consentire NULL e di prendere sempre in considerazione i NULL quando sono possibili nei tuoi dati. Assicurati di includere NULL nei tuoi dati di esempio quando sono consentiti in modo da poter rilevare più facilmente i bug nel tuo codice durante il test. Fai attenzione con il predicato NOT IN quando combinato con le sottoquery. Se sono possibili NULL nel risultato della query interna, il predicato NOT EXISTS è solitamente l'alternativa preferita.