Di recente, sono stato coinvolto nello sviluppo della funzionalità che richiedeva un trasferimento veloce e frequente di grandi volumi di dati su disco. Inoltre, questi dati dovevano essere letti di tanto in tanto dal disco. Pertanto, ero destinato a scoprire il luogo, il modo e i mezzi per archiviare questi dati. In questo articolo, esaminerò brevemente l'attività, esaminerò e confronterò le soluzioni per il completamento di questa attività.
Contesto dell'attività :Lavoro in un team che sviluppa strumenti per lo sviluppo di database relativi (SQL Server, MySQL, Oracle). La gamma di strumenti include sia strumenti standalone che componenti aggiuntivi per MS SSMS.
Compito :Ripristino di documenti aperti al momento della chiusura dell'IDE al successivo avvio dell'IDE.
Caso d'uso :Chiudere rapidamente l'IDE prima di lasciare l'ufficio senza pensare a quali documenti sono stati salvati e quali no. Al prossimo avvio di IDE, dobbiamo ottenere lo stesso ambiente che era al momento della chiusura e continuare il lavoro. Tutti i risultati del lavoro devono essere salvati al momento della chiusura disordinata, ad es. durante l'arresto anomalo di un programma o di un sistema operativo o durante lo spegnimento.
Analisi delle attività :la funzione simile è presente nei browser web. Tuttavia, i browser memorizzano solo URL costituiti da circa 100 simboli. Nel nostro caso, dobbiamo memorizzare l'intero contenuto del documento. Pertanto, abbiamo bisogno di un posto dove salvare e archiviare i documenti degli utenti. Inoltre, a volte gli utenti lavorano con SQL in modo diverso rispetto ad altri linguaggi. Ad esempio, se scrivo una classe C# lunga più di 1000 righe, difficilmente sarà accettabile. Mentre, nell'universo SQL, insieme alle query di 10-20 righe, esistono i mostruosi dump del database. Tali dump sono difficilmente modificabili, il che significa che gli utenti preferirebbero mantenere le proprie modifiche al sicuro.
Requisiti per uno spazio di archiviazione:
- Dovrebbe essere una soluzione incorporata leggera.
- Dovrebbe avere un'elevata velocità di scrittura.
- Dovrebbe avere un'opzione per l'accesso multiprocessing. Questo requisito non è critico, poiché possiamo garantire l'accesso con l'aiuto degli oggetti di sincronizzazione, ma sarebbe comunque bello avere questa opzione.
Candidati
Il primo candidato è piuttosto goffo, ovvero archiviare tutto in una cartella, da qualche parte in AppData.
Il secondo candidato è ovvio:SQLite, uno standard di database incorporati. Candidato molto solido e popolare.
Il terzo candidato è il database LiteDB. È il primo risultato per la query "database incorporato per .net" in Google.
Prima vista
File system. I file sono file, richiedono manutenzione e denominazione corretta. Oltre al contenuto del file, avremo bisogno di memorizzare un piccolo insieme di proprietà (percorso originale su disco, stringa di connessione, versione dell'IDE, in cui è stato aperto). Significa che dovremo creare due file per un documento o inventare un formato che separi le proprietà dal contenuto.
SQLite è un classico database relazionale. Il database è rappresentato da un file su disco. Questo file viene associato allo schema del database, dopodiché dobbiamo interagire con esso con l'aiuto dei mezzi SQL. Saremo in grado di creare 2 tabelle, una per le proprietà e l'altra per il contenuto, nel caso dovremo utilizzare proprietà o contenuto separatamente.
LiteDB è un database non relazionale. Simile a SQLite, il database è rappresentato da un unico file. È scritto interamente in С#. Ha un'accattivante semplicità d'uso:dobbiamo solo dare un oggetto alla libreria, mentre la serializzazione verrà eseguita con mezzi propri.
Test delle prestazioni
Prima di fornire il codice, vorrei spiegare la concezione generale e fornire i risultati del confronto.
L'idea generale è confrontare la velocità di scrittura di grandi quantità di file piccoli nel database, la quantità media di file medi e una piccola quantità di file di grandi dimensioni. Il caso con file medi è per lo più vicino al caso reale, mentre i casi con file piccoli e grandi sono casi limite, che devono essere presi in considerazione.
Stavo scrivendo il contenuto in un file con l'aiuto di FileStream con la dimensione del buffer standard.
C'era una sfumatura in SQLite che vorrei menzionare. Non siamo stati in grado di inserire tutto il contenuto del documento (come accennato in precedenza, possono essere molto grandi) in una cella del database. Il fatto è che ai fini dell'ottimizzazione, memorizziamo il testo del documento riga per riga. Ciò significa che per inserire il testo in una singola cella, dobbiamo mettere tutto il documento in una singola riga, il che raddoppierebbe la quantità di memoria operativa utilizzata. L'altro lato del problema si rivelerebbe durante la lettura dei dati dal database. Ecco perché c'era una tabella separata in SQLite, in cui i dati venivano archiviati riga per riga e i dati erano collegati con l'aiuto di una chiave esterna con la tabella contenente solo le proprietà del file. Inoltre, sono riuscito a velocizzare il database con l'inserimento di dati batch (diverse migliaia di righe alla volta) in modalità di sincronizzazione OFF senza registrazione e all'interno di una transazione.
LiteDB ha ricevuto un oggetto con List tra le sue proprietà e la libreria lo ha salvato su disco da solo.
Durante lo sviluppo dell'applicazione di test, ho capito che preferisco LiteDB. Il fatto è che il codice di test per SQLite richiede più di 120 righe, mentre il codice, che risolve lo stesso problema in LiteDb, richiede solo 20 righe.
Prova la generazione dei dati
FileStrings.cs
internal class FileStrings {
private static readonly Random random = new Random();
public List Strings {
get;
set;
} = new List();
public int SomeInfo {
get;
set;
}
public FileStrings() {
}
public FileStrings(int id, int minLines, decimal lineIncrement) {
SomeInfo = id;
int lines = minLines + (int)(id * lineIncrement);
for (int i = 0; i < lines; i++) {
Strings.Add(GetString());
}
}
private string GetString() {
int length = 250;
StringBuilder builder = new StringBuilder(length);
for (int i = 0; i < length; i++) { builder.Append(random.Next((int)'a', (int)'z')); } return builder.ToString(); } } Program.cs List files = Enumerable.Range(1, NUM_FILES + 1) .Select(f => new FileStrings(f, MIN_NUM_LINES, (MAX_NUM_LINES - MIN_NUM_LINES) / (decimal)NUM_FILES))
.ToList();
SQLite
private static void SaveToDb(List files) {
using (var connection = new SQLiteConnection()) {
connection.ConnectionString = @"Data Source=data\database.db;FailIfMissing=False;";
connection.Open();
var command = connection.CreateCommand();
command.CommandText = @"CREATE TABLE files
(
id INTEGER PRIMARY KEY,
file_name TEXT
);
CREATE TABLE strings
(
id INTEGER PRIMARY KEY,
string TEXT,
file_id INTEGER,
line_number INTEGER
);
CREATE UNIQUE INDEX strings_file_id_line_number_uindex ON strings(file_id,line_number);
PRAGMA synchronous = OFF;
PRAGMA journal_mode = OFF";
command.ExecuteNonQuery();
var insertFilecommand = connection.CreateCommand();
insertFilecommand.CommandText = "INSERT INTO files(file_name) VALUES(?); SELECT last_insert_rowid();";
insertFilecommand.Parameters.Add(insertFilecommand.CreateParameter());
insertFilecommand.Prepare();
var insertLineCommand = connection.CreateCommand();
insertLineCommand.CommandText = "INSERT INTO strings(string, file_id, line_number) VALUES(?, ?, ?);";
insertLineCommand.Parameters.Add(insertLineCommand.CreateParameter());
insertLineCommand.Parameters.Add(insertLineCommand.CreateParameter());
insertLineCommand.Parameters.Add(insertLineCommand.CreateParameter());
insertLineCommand.Prepare();
foreach (var item in files) {
using (var tr = connection.BeginTransaction()) {
SaveToDb(item, insertFilecommand, insertLineCommand);
tr.Commit();
}
}
}
}
private static void SaveToDb(FileStrings item, SQLiteCommand insertFileCommand, SQLiteCommand insertLinesCommand) {
string fileName = Path.Combine("data", item.SomeInfo + ".sql");
insertFileCommand.Parameters[0].Value = fileName;
var fileId = insertFileCommand.ExecuteScalar();
int lineIndex = 0;
foreach (var line in item.Strings) {
insertLinesCommand.Parameters[0].Value = line;
insertLinesCommand.Parameters[1].Value = fileId;
insertLinesCommand.Parameters[2].Value = lineIndex++;
insertLinesCommand.ExecuteNonQuery();
}
} LiteDB
private static void SaveToNoSql(List item) {
using (var db = new LiteDatabase("data\\litedb.db")) {
var data = db.GetCollection("files");
data.EnsureIndex(f => f.SomeInfo);
data.Insert(item);
}
}
La tabella seguente mostra i risultati medi per diverse esecuzioni del codice di test. Durante le modifiche, la deviazione statistica era abbastanza impercettibile.
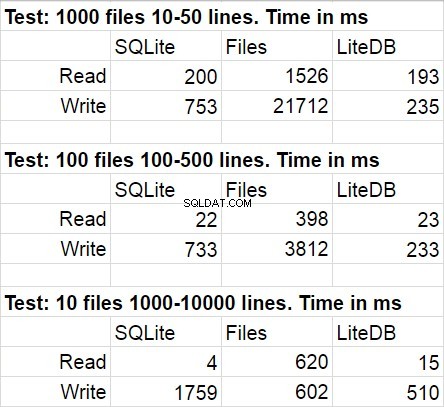
Non sono rimasto sorpreso dal fatto che LiteDB abbia vinto in questo confronto. Tuttavia, sono rimasto scioccato dalla vittoria di LiteDB sui file. Dopo un breve studio del repository della libreria, ho scoperto che la scrittura paginale su disco è stata implementata in modo molto meticoloso, ma sono sicuro che questo è solo uno dei tanti trucchi per le prestazioni utilizzati lì. Un'altra cosa che vorrei sottolineare è un'elevata velocità di accesso al file system diminuisce quando la quantità di file nella cartella diventa davvero grande.
Abbiamo selezionato LiteDB per lo sviluppo della nostra funzionalità e non ci siamo quasi pentiti di questa scelta. Il fatto è che la libreria è scritta in nativo per tutti C#, e se qualcosa non fosse del tutto chiaro, potremmo sempre fare riferimento al codice sorgente.
Contro
Oltre ai vantaggi sopra menzionati di LiteDB rispetto ai suoi concorrenti, abbiamo iniziato a notare dei contro durante lo sviluppo. La maggior parte di questi svantaggi può essere spiegata dalla "giovinezza" della biblioteca. Avendo iniziato a utilizzare la libreria leggermente oltre i confini dello scenario "standard", abbiamo scoperto diversi problemi (#419, #420, #483, #496). L'autore della libreria ha risposto alle domande abbastanza velocemente e la maggior parte dei problemi è stata risolta rapidamente. Ora è rimasta solo un'attività (da non confondere con il suo stato Chiuso). Questo è un problema di accesso competitivo. Sembra che una condizione razziale molto brutta si nasconda da qualche parte nel profondo della biblioteca. Abbiamo ignorato questo bug in modo abbastanza originale (ho intenzione di scrivere un articolo separato su questo argomento).
Vorrei anche menzionare l'assenza di editor e visualizzatore accurati. C'è LiteDBShell, ma è solo per i veri fan della console.
Riepilogo
Abbiamo creato una grande e importante funzionalità su LiteDB e ora stiamo lavorando su un'altra grande funzionalità in cui utilizzeremo anche questa libreria. Per chi cerca un database in-process, suggerisco di prestare attenzione a LiteDB e al modo in cui si dimostrerà nel contesto del tuo compito, poiché, come sai, se qualcosa avesse funzionato per un compito, non sarebbe necessariamente lavorare per un altro compito.



