Tutti commettiamo errori e tutti possiamo imparare dagli errori degli altri. In questo post, daremo un'occhiata a numerose risorse online per evitare una cattiva progettazione del database che può portare a molti problemi e costare tempo e denaro. E in un prossimo articolo, ti spiegheremo dove trovare suggerimenti e best practice.
Errori ed errori di progettazione del database da evitare
Esistono numerose risorse online per aiutare i progettisti di database a evitare errori ed errori comuni. Ovviamente, questo articolo non è un elenco esaustivo di tutti gli articoli là fuori. Invece, abbiamo esaminato e commentato una varietà di fonti diverse in modo che tu possa trovare quella più adatta a te.
Il nostro consiglio
Se c'è solo un articolo tra queste risorse che stai per leggere, dovrebbe essere "Come ottenere un design del database terribilmente sbagliato" di Robert Sheldon
Cominciamo con il blog DATAVERSITY che fornisce un'ampia serie di risorse abbastanza buone:
Errori di chiave primaria e chiave esterna da evitare
di Michael Blaha | blog DATAVERSITY | 2 settembre 2015
Più errori di progettazione del database:confusione con relazioni molti-a-molti
di Michael Blaha | blog DATAVERSITY | 30 settembre 2015
Errori vari di progettazione del database
di Michael Blaha | blog DATAVERSITY | 26 ottobre 2015
Michael Blaha ha contribuito con una bella serie di tre articoli. Ogni articolo affronta diverse insidie della modellazione del database e della progettazione fisica; gli argomenti includono chiavi, relazioni ed errori generali. Inoltre, ci sono discussioni con Michael su alcuni punti. Se stai cercando insidie in merito a chiavi e relazioni, questo sarebbe un buon punto di partenza.
Mr. Blaha afferma che "circa il 20% dei database viola le regole della chiave primaria". Oh! Ciò significa che circa il 20% degli sviluppatori di database non ha creato correttamente le chiavi primarie. Se questa statistica è vera, mostra davvero l'importanza degli strumenti di modellazione dei dati che "incoraggiano" fortemente o addirittura richiedono ai modellatori di definire le chiavi primarie.
Mr. Blaha condivide anche l'euristica secondo cui "circa il 50% dei database" ha problemi di chiave esterna (secondo la sua esperienza con i database legacy che ha studiato). Ci ricorda di evitare collegamenti informali tra tabelle incorporando il valore da una tabella all'altra anziché utilizzare una chiave esterna.
Ho visto questo problema molte volte. Ammetto che il collegamento informale può essere richiesto dalla funzionalità da implementare, ma più spesso si verifica per semplice pigrizia. Ad esempio, potremmo voler mostrare l'id utente di qualcuno che ha modificato qualcosa, quindi memorizziamo l'id utente direttamente nella tabella. Ma cosa succede se quell'utente cambia il suo ID utente? Quindi questo collegamento informale viene interrotto. Ciò è spesso dovuto a design e modellazione scadenti.
Progettare il tuo database:i 5 errori principali da evitare
di Henrique Netzka | blog DATAVERSITY | 2 novembre 2015
Sono rimasto un po' deluso da questo articolo, poiché conteneva un paio di elementi abbastanza specifici (memorizzazione del protocollo in un CLOB) e alcuni molto generali (pensa alla localizzazione). Nel complesso l'articolo va bene, ma sono davvero questi i primi 5 errori da evitare? Secondo me, ci sono molti altri errori comuni che dovrebbero fare la lista.
Tuttavia, su una nota positiva, questo è uno dei pochi articoli che menziona la globalizzazione e la localizzazione in modo significativo. Lavoro in un ambiente molto multilingue e ho visto diverse orribili implementazioni della localizzazione, quindi sono stato felice di trovare menzionato questo problema. Le colonne della lingua e del fuso orario possono sembrare ovvie, ma appaiono molto raramente nei modelli di database.
Detto questo, ho pensato che sarebbe stato interessante creare un modello che includa traduzioni che possono essere modificate dagli utenti finali (anziché utilizzare i bundle di risorse). Qualche tempo fa ho scritto di un modello per un database di sondaggi online. Qui ho modellato una traduzione semplificata di domande e scelte di risposta:
Partendo dal presupposto che dobbiamo consentire agli utenti finali di mantenere le traduzioni, il metodo preferito sarebbe aggiungere tabelle di traduzione per domande e risposte:
Ho anche aggiunto un fuso orario a user_account tabella in modo da poter memorizzare date/ora nell'ora locale degli utenti:
7 errori comuni di progettazione del database
di Grzegorz Kaczor | Blog verticale | 17 luglio 2015
Farò una piccola autopromozione qui. Ci sforziamo di pubblicare regolarmente articoli interessanti e coinvolgenti qui.
Questo articolo particolare sottolinea diverse importanti aree di interesse, come la denominazione, l'indicizzazione, le considerazioni sul volume e le tracce di controllo. L'articolo affronta anche problemi relativi a sistemi DBM specifici, come le limitazioni Oracle sui nomi delle tabelle. Mi piacciono molto i bei esempi chiari, anche se illustrano come i designer commettono errori ed errori.
Ovviamente non è possibile elencare tutti gli errori di progettazione e quelli elencati potrebbero non essere tuo errori più comuni. Quando scriviamo di errori comuni, sono quelli che abbiamo commesso o che abbiamo trovato nel lavoro di altri che stiamo attingendo. Un elenco completo degli errori, classificati in base alla frequenza, sarebbe impossibile da compilare per una singola persona. Tuttavia, penso che questo articolo fornisca diversi spunti utili su potenziali insidie. È una bella risorsa solida nel complesso.
Mentre il signor Kaczor fa diversi punti interessanti nel suo articolo, ho trovato i suoi commenti sul "non considerare il volume o il traffico possibili" piuttosto interessanti. In particolare, è particolarmente pertinente la raccomandazione di separare i dati di uso frequente dai dati storici. Questa è una soluzione che utilizziamo frequentemente nelle nostre applicazioni di messaggistica; dobbiamo avere una cronologia ricercabile di tutti i messaggi, ma i messaggi con maggiori probabilità di accesso sono quelli che sono stati pubblicati negli ultimi giorni. Quindi dividere i dati "attivi" o recenti a cui si accede frequentemente (un volume di dati molto più piccolo) dai dati storici a lungo termine (la grande massa di dati) è generalmente un'ottima tecnica.
Errori comuni di progettazione del database
di Troy Blake | Blog DBA senior | 11 luglio 2015
L'articolo di Troy Blake è un'altra buona risorsa, anche se potrei aver rinominato questo articolo "Errori comuni di progettazione di SQL Server".
Ad esempio, abbiamo il commento:"le stored procedure sono il tuo migliore amico quando si tratta di utilizzare SQL Server in modo efficace". Va bene, ma si tratta di un errore generale comune o è più specifico di SQL Server? Dovrei optare per questo essendo un po 'specifico di SQL Server, poiché ci sono degli svantaggi nell'utilizzo delle procedure memorizzate, come finire con procedure memorizzate specifiche del fornitore e quindi il blocco del fornitore. Quindi non sono un fan dell'inclusione di "Procedure archiviate non in uso" in questo elenco.
Tuttavia, sul lato positivo, penso che l'autore abbia identificato alcuni errori molto comuni, come pianificazione scadente, progettazione del sistema scadente, documentazione limitata, standard di denominazione deboli e mancanza di test.
Quindi lo classificherei come un riferimento molto utile per i professionisti di SQL Server e un riferimento utile per gli altri.
Sette errori nella modellazione dei dati
di Kurt Cagle | LinkedIn | 12 giugno 2015
Mi è davvero piaciuto leggere l'elenco di errori di modellazione del database del signor Cagle. Questi provengono dal punto di vista di un architetto di database; identifica chiaramente gli errori di modellazione di livello superiore che dovrebbero essere evitati. Con questa visualizzazione dell'immagine più grande, puoi interrompere un potenziale pasticcio di modellazione.
Alcuni dei tipi menzionati nell'articolo possono essere trovati altrove, ma alcuni di questi sono unici:astrarre troppo presto o mescolare modelli concettuali, logici e fisici. Questi non sono spesso menzionati da altri autori, probabilmente perché si stanno concentrando sul processo di modellazione dei dati piuttosto che su una visione del sistema più ampia.
In particolare, l'esempio di "Getting Too Abstract Too Early" descrive un interessante processo di pensiero per creare alcune "storie" di esempio e testare quali relazioni sono importanti in questo dominio. Questo focalizza il pensiero sulle relazioni tra gli oggetti modellati. Risulta in domande come quali sono le relazioni importanti in questo dominio ?
Sulla base di questa comprensione, creiamo il modello attorno alle relazioni anziché iniziare da singoli elementi del dominio e costruire le relazioni su di essi. Mentre molti di noi potrebbero utilizzare questo approccio, tra queste risorse nessun altro autore ha commentato. Ho trovato questa descrizione e gli esempi piuttosto interessanti.
Come ottenere un design del database terribilmente sbagliato
di Robert Sheldon | Parlare semplice | 6 marzo 2015
Se c'è solo un articolo tra queste risorse che stai per leggere, dovrebbe essere questo di Robert Sheldon
Quello che mi piace davvero di questo articolo è che per ciascuno degli errori menzionati ci sono suggerimenti su come farlo nel modo giusto. La maggior parte di questi si concentra sull'evitare l'errore piuttosto che sulla correzione, ma penso comunque che siano molto utili. C'è pochissima teoria qui; risposte per lo più dirette su come evitare errori durante la modellazione dei dati. Esistono alcuni punti specifici di SQL Server, ma principalmente SQL Server viene utilizzato per fornire esempi di prevenzione degli errori o soluzioni per l'errore.
Anche lo scopo dell'articolo è piuttosto ampio:copre la mancata pianificazione, il non preoccuparsi della documentazione, l'uso di convenzioni di denominazione scadenti, i problemi di normalizzazione (troppo o troppo poco), il fallimento di chiavi e vincoli, l'indicizzazione non corretta e l'esecuzione test inadeguati.
In particolare, mi sono piaciuti i consigli pratici sull'integrità dei dati:quando utilizzare i vincoli di controllo e quando definire chiavi esterne. Inoltre, il signor Sheldon descrive anche la situazione in cui i team rinviano all'applicazione per rafforzare l'integrità. È chiaro quando afferma che è possibile accedere a un database in più modi e con numerose applicazioni. La sua conclusione che "i dati dovrebbero essere protetti dove risiedono:all'interno del database". Questo è così vero che può essere ripetuto ai team di sviluppo e ai manager per spiegare l'importanza di implementare i controlli di integrità nel modello di dati.
Questo è il mio tipo di articolo e puoi dire che altri sono d'accordo sulla base dei numerosi commenti che lo approvano. Quindi, il massimo dei voti qui; è una risorsa molto preziosa.
Dieci errori comuni nella progettazione di database
di Louis Davidson | Parlare semplice | 26 febbraio 2007
Ho trovato questo articolo abbastanza buono, poiché copriva molti errori di progettazione comuni. C'erano analogie significative, esempi, modelli e persino alcune citazioni classiche di William Shakespeare e J.R.R. Tolkien.
Un paio di errori sono stati spiegati in modo più dettagliato rispetto ad altri, con lunghi esempi ed estratti SQL che ho trovato un po' ingombranti. Ma è una questione di gusti.
Anche in questo caso, abbiamo alcuni argomenti specifici di SQL Server. Ad esempio, il punto di non utilizzare le stored procedure per accedere ai dati è positivo per SQL, ma gli SP non sono sempre una buona idea quando l'obiettivo è il supporto su più DBMS. Inoltre, siamo avvertiti di non provare a codificare oggetti T-SQL generici. Poiché lavoro raramente con SQL Server o Sybase, non ho trovato questo suggerimento pertinente.
L'elenco è abbastanza simile a quello di Robert Sheldon, ma se lavori principalmente su SQL Server, troverai alcune informazioni aggiuntive.
Cinque semplici errori di progettazione del database da evitare
di Anith Sen Larson | Parlare semplice | 16 ottobre 2009
Questo articolo fornisce alcuni esempi significativi per ciascuno dei semplici errori di progettazione che copre. D'altra parte, si concentra piuttosto su tipi simili di errori:tabelle di ricerca comuni, tabelle entità-attributo-valore e suddivisione degli attributi.
Le osservazioni vanno bene e l'articolo ha persino riferimenti, che tendono ad essere rari. Tuttavia, vorrei vedere errori di progettazione del database più generali. Questi errori sembravano piuttosto specifici, ma, come ho già scritto, gli errori di cui scriviamo sono generalmente quelli di cui abbiamo esperienza personale.
Un elemento che mi è piaciuto è stata una regola pratica specifica per decidere quando utilizzare un vincolo di controllo rispetto a una tabella separata con un vincolo di chiave esterna. Diversi autori forniscono raccomandazioni simili, ma il signor Larson le suddivide in "deve", "considerare" e "caso forte" - con l'ammissione che "il design è un mix di arte e scienza e quindi implica compromessi". Lo trovo molto vero.
I dieci errori più comuni nella progettazione di database fisici
di Craig Mullins | Dati e tecnologia oggi | 5 agosto 2013
Come suggerisce il nome, "I dieci errori più comuni nella progettazione di database fisici" è leggermente più orientato alla progettazione fisica piuttosto che alla progettazione logica e concettuale. Nessuno degli errori menzionati dall'autore Craig Mullins si distingue davvero o è unico, quindi consiglierei queste informazioni alle persone che lavorano sul lato DBA fisico.
Inoltre, le descrizioni sono un po' brevi, quindi a volte è difficile capire perché un particolare errore possa causare problemi. Non c'è nulla di intrinsecamente sbagliato nelle descrizioni brevi, ma non ti danno molto a cui pensare. E non vengono presentati esempi.
Viene sollevato un punto interessante relativo alla mancata condivisione dei dati. Questo punto è occasionalmente menzionato in altri articoli, ma non come un errore di progettazione. Tuttavia, vedo questo problema abbastanza frequentemente con i database "ricreati" in base a requisiti molto simili, ma da un nuovo team o per un nuovo prodotto
.Capita spesso che il team di prodotto si renda conto in seguito che avrebbe voluto utilizzare dati che erano già presenti nel "padre" del loro database attuale. In realtà, però, avrebbero dovuto potenziare il genitore piuttosto che creare una nuova prole. Le applicazioni hanno lo scopo di condividere dati; un buon design può consentire di riutilizzare più spesso un database.
Fai questi 5 errori di progettazione del database?
di Thomas Larock | Il blog di Thomas Larock | 2 gennaio 2012
Potresti trovare alcuni punti interessanti mentre rispondi alla domanda di Thomas Larock:commetti questi 5 errori di progettazione del database?
Questo articolo è in qualche modo pesantemente ponderato per le chiavi (chiavi straniere, chiavi surrogate e chiavi generate). Tuttavia, ha un punto importante:non si dovrebbe presumere che le funzionalità DBMS siano le stesse su tutti i sistemi. Penso che questo sia un ottimo punto. È anche uno che non si trova nella maggior parte degli altri articoli, forse perché molti autori si concentrano e lavorano principalmente con un singolo DBMS.
Progettare un database:7 cose che non vuoi fare
di Thomas Larock | Il blog di Thomas Larock | 16 gennaio 2013
Il signor Larock ha riciclato un paio dei suoi "5 errori di progettazione del database" quando ha scritto "7 cose che non vuoi fare", ma qui ci sono altri aspetti positivi.
È interessante notare che alcuni dei punti che il signor Larock fa non si trovano in molte altre fonti. Ottieni un paio di osservazioni piuttosto uniche, come "non avere aspettative sulle prestazioni". Questo è un errore grave e che, in base alla mia esperienza, accade abbastanza spesso. Anche durante lo sviluppo del codice dell'applicazione, è spesso dopo la creazione del modello dati, del database e dell'applicazione stessa che le persone iniziano a pensare ai requisiti non funzionali (quando devono essere creati test non funzionali) e iniziano a definire le aspettative di prestazione .
Al contrario, ci sono alcuni punti che non includerei nella mia lista dei primi dieci, come "andare alla grande, per ogni evenienza". Vedo il punto, ma non è così in cima alla mia lista quando creo un modello di dati. Non c'è alcuna specificità per un particolare sistema DBM, quindi questo è un bonus.
Per concludere, molti di questi punti potrebbero essere racchiusi sotto il punto:"non capire i requisiti", che è davvero nella mia lista dei primi 10 errori.
Come evitare 8 errori comuni nello sviluppo di database
di Base36 | 6 dicembre 2012
Ero abbastanza interessato a leggere questo articolo. Tuttavia, sono rimasto un po' deluso. Non si discute molto sull'evitamento e il punto dell'articolo sembra davvero essere "questi sono errori comuni del database" e "perché sono errori"; le descrizioni su come evitare l'errore sono meno evidenti.
Inoltre, alcuni dei primi 8 errori dell'articolo sono effettivamente contestati. Un esempio è l'uso improprio della chiave primaria. Base36 ci dice che devono essere generati dal sistema e non basati sui dati dell'applicazione nella riga. Anche se sono d'accordo con questo fino a un certo punto, non sono convinto che tutti I PK dovrebbero sempre essere generato; è un po' troppo categorico.
D'altra parte, l'errore di "Hard Deletes" è interessante e non menzionato spesso altrove. Le eliminazioni graduali causano altri problemi, ma è vero che contrassegnare semplicemente una riga come inattiva ha i suoi vantaggi quando si cerca di capire dove sono andati quei dati che erano nel sistema ieri. La ricerca nei registri delle transazioni non è la mia idea di un modo divertente per trascorrere una giornata.
Sette peccati capitali di progettazione di database
di Jason Tiret | Giornale dei sistemi aziendali | 16 febbraio 2010
Ero abbastanza fiducioso quando ho iniziato a leggere l'articolo di Jason Tiret, "Seven Deadly Sins of Database Design". Quindi sono stato felice di scoprire che non si limitava a riciclare gli errori che si trovano in numerosi altri articoli. Al contrario, offriva un "peccato" che non avevo trovato in altri elenchi:provare a eseguire tutta la progettazione del database "in anticipo" e non aggiornare il modello dopo che il database è in produzione, quando vengono apportate modifiche al database. (O, come dice Jason, "Non trattare il modello di dati come un organismo vivente e che respira").
Ho visto questo errore molte volte. La maggior parte delle persone si rende conto del proprio errore solo quando deve aggiornare un modello che non corrisponde più al database effettivo. Naturalmente, il risultato è un modello inutile. Come afferma l'articolo, "le modifiche devono tornare al modello".
D'altra parte, la maggior parte delle voci dell'elenco di Jason sono abbastanza note. Le descrizioni sono buone, ma non ci sono molti esempi. Sarebbero utili ulteriori esempi e dettagli.
Gli errori più comuni nella progettazione di database
di Brian Prince | eWeek.com | 19 marzo 2008

L'articolo "Gli errori più comuni nella progettazione di database" è in realtà una serie di diapositive di una presentazione. Ci sono alcuni pensieri interessanti, ma alcuni degli oggetti unici sono forse un po' esoterici. Ho in mente punti come "Conoscere RAID" e il coinvolgimento degli stakeholder.
In generale, non lo metterei nella tua lista di lettura a meno che tu non ti concentri su questioni generali (pianificazione, denominazione, normalizzazione, indici) e dettagli fisici.
10 errori di progettazione comuni
di davidm | Blog di SQL Server – SQLTeam.com | 12 settembre 2005
Alcuni dei punti in "Dieci errori di progettazione comuni" sono interessanti e relativamente nuovi. Tuttavia, alcuni di questi errori sono piuttosto controversi, come "l'utilizzo di valori NULL" e la denormalizzazione.
Sono d'accordo sul fatto che la creazione di tutte le colonne come nullable sia un errore, ma la definizione di una colonna come nullable potrebbe essere richiesta per una particolare funzione aziendale. Può quindi essere considerato un errore generico? Penso di no.
Un altro punto su cui discuto è la denormalizzazione. Questo non è sempre un errore di progettazione. Ad esempio, potrebbe essere necessaria la denormalizzazione per motivi di prestazioni.
Anche questo articolo è in gran parte privo di dettagli ed esempi. Le conversazioni tra DBA e programmatore o manager sono divertenti, ma avrei preferito esempi più concreti e giustificazioni dettagliate per questi errori comuni.
OTLT e EAV:i due grandi errori di progettazione che fanno tutti i principianti
di Tony Andrews | Tony Andrews su Oracle e database | 21 ottobre 2004
L'articolo del signor Andrews ci ricorda gli errori "One True Lookup Table" (OTLT) e Entity-Attribute-Value (EAV) menzionati in altri articoli. Un aspetto interessante di questa presentazione è che si concentra su questi due errori, quindi le descrizioni e gli esempi sono precisi. Inoltre, viene fornita una possibile spiegazione del motivo per cui alcuni designer implementano OTLT e EAV.
Per ricordarti, la tabella OTLT in genere è simile a questa, con voci di più domini gettate nella stessa tabella:
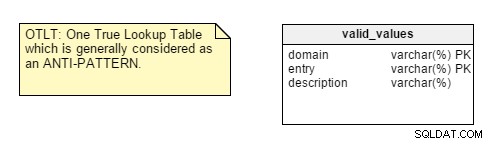
Come al solito, si discute se OTLT sia una soluzione praticabile e un buon modello di progettazione. Devo dire che sono dalla parte del gruppo anti-OTLT; queste tabelle introducono numerosi problemi. Potremmo usare l'analogia dell'uso di un singolo enumeratore per rappresentare tutti i possibili valori di tutte le possibili costanti. Non l'ho mai visto, finora.
Errori comuni nel database
di John Paul Ashenfelter | del dottor Dobb | 01 gennaio 2002
L'articolo del signor Ashenfelter elenca ben 15 errori di database comuni. Ci sono anche alcuni errori che non sono menzionati frequentemente in altri articoli. Sfortunatamente, le descrizioni sono relativamente brevi e non ci sono esempi. Il merito di questo articolo è che l'elenco copre molto terreno e può essere utilizzato come "lista di controllo" di errori da evitare. Anche se potrei non classificarli come gli errori di database più importanti, sono sicuramente tra i più comuni.
Una nota positiva, questo è uno dei pochi articoli che menziona la necessità di gestire l'internazionalizzazione dei formati per dati come data, valuta e indirizzo. Un esempio sarebbe bello qui. Potrebbe essere semplice come “assicurarsi che State sia una colonna nullable; in molti paesi non esiste uno stato associato a un indirizzo”.
In precedenza in questo articolo, ho menzionato altre preoccupazioni e alcuni approcci per prepararsi alla globalizzazione del database, come i fusi orari e le traduzioni (localizzazione). Il fatto che nessun altro articolo menzioni la preoccupazione dei formati di valuta e data è preoccupante. I nostri database sono preparati per l'utilizzo globale delle nostre applicazioni?
Menzioni d'onore
Ovviamente, ci sono altri articoli che descrivono errori ed errori di progettazione di database comuni, ma volevamo darti un'ampia rassegna di diverse risorse. Puoi trovare ulteriori informazioni in articoli come:
10 errori comuni di progettazione del database | Blog di classe MIS | 29 gennaio 2012
10 errori comuni nella progettazione di database | IDG.se | 24 giugno 2010
Risorse online:da dove cominciare? Dove andare?
Come accennato in precedenza, questo elenco non vuole assolutamente essere un esame esauriente di ogni articolo online che descrive errori ed errori di progettazione del database. Piuttosto, abbiamo identificato diverse fonti che sono particolarmente utili o hanno un focus specifico che potresti trovare utile.
Non esitare a consigliare altri articoli.



