Avere tabelle di riferimento nel tuo database non è un grosso problema, giusto? Devi solo legare un codice o un ID con una descrizione per ogni tipo di riferimento. Ma cosa succede se hai letteralmente dozzine e dozzine di tabelle di riferimento? Esiste un'alternativa all'approccio di una tabella per tipo? Continua a leggere per scoprire un generico ed estensibile progettazione di database per la gestione di tutti i tuoi dati di riferimento.
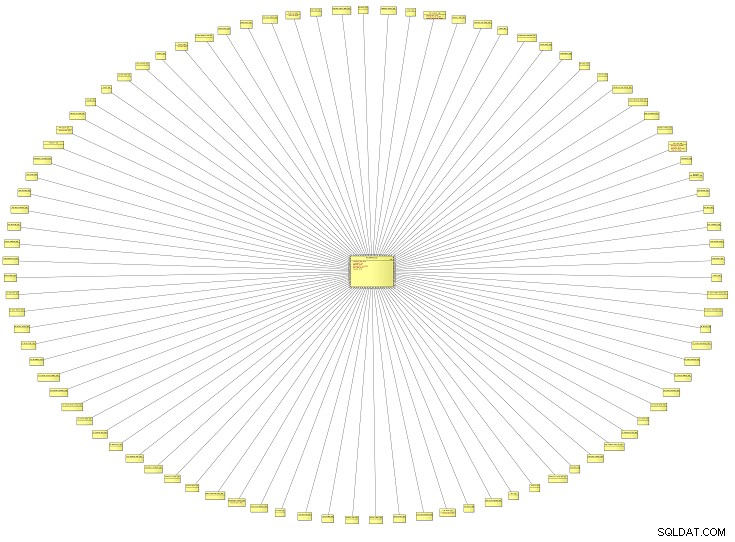
Questo diagramma dall'aspetto insolito è una vista a volo d'uccello di un modello di dati logici (LDM) contenente tutti i tipi di riferimento per un sistema aziendale. Proviene da un istituto di istruzione, ma potrebbe applicarsi al modello di dati di qualsiasi tipo di organizzazione. Più grande è il modello, più tipi di riferimento scoprirai.
Per tipi di riferimento intendo dati di riferimento, valori di ricerca o, se vuoi essere flash, tassonomie . In genere, i valori qui definiti vengono utilizzati negli elenchi a discesa nell'interfaccia utente dell'applicazione. Possono anche apparire come intestazioni in un rapporto.
Questo particolare modello di dati aveva circa 100 tipi di riferimento. Ingrandiamo e guardiamo solo due di loro.
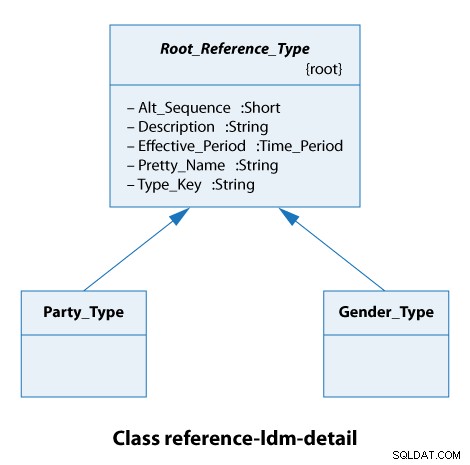
Da questo diagramma di classe, vediamo che tutti i tipi di riferimento estendono il Root_Reference_Type . In pratica, questo significa solo che tutti i nostri tipi di riferimento hanno gli stessi attributi di Alt_Sequence fino a Type_Key compreso, come mostrato di seguito.
| Attributo | Descrizione |
|---|---|
Alt_Sequence | Utilizzato per definire una sequenza alternativa quando è richiesto un ordine non alfabetico. |
Description | La descrizione del tipo. |
Effective_Period | Definisce efficacemente se la voce di riferimento è abilitata o meno. Una volta che un riferimento è stato utilizzato, non può essere cancellato a causa di vincoli referenziali; può essere solo disabilitato. |
| Il nome carino per il tipo. Questo è ciò che l'utente vede sullo schermo. |
Type_Key | La chiave interna univoca per il tipo. Questo è nascosto all'utente, ma gli sviluppatori di applicazioni possono farne un ampio uso nel loro SQL. |
Il tipo di festa qui è un'organizzazione o una persona. I tipi di genere sono maschili e femminili. Quindi questi sono casi davvero semplici.
La soluzione tradizionale della tabella di riferimento
Quindi, come implementeremo il modello logico nel mondo fisico di un database reale?
Potremmo ritenere che ogni tipo di riferimento verrà mappato alla propria tabella. Potresti riferirti a questo come al più tradizionale un tavolo per classe soluzione. È abbastanza semplice e assomiglierebbe a questo:
Il rovescio della medaglia è che potrebbero esserci dozzine e dozzine di queste tabelle, tutte con le stesse colonne, che fanno tutte praticamente la stessa cosa.
Inoltre, potremmo creare molto più lavoro di sviluppo . Se è necessaria un'interfaccia utente per ogni tipo affinché gli amministratori mantengano i valori, la quantità di lavoro si moltiplica rapidamente. Non ci sono regole rigide per questo, dipende davvero dal tuo ambiente di sviluppo, quindi dovrai parlare con i tuoi sviluppatori per capire quale impatto ha.
Ma dato che tutti i nostri tipi di riferimento hanno gli stessi attributi o colonne, esiste un modo più generico per implementare il nostro modello di dati logici? Si C'è! E richiede solo due tabelle .
La soluzione a due tavoli
La prima discussione che ho avuto su questo argomento risale alla metà degli anni '90, quando lavoravo per una compagnia di assicurazioni del London Market. Allora, siamo passati direttamente alla progettazione fisica e abbiamo utilizzato principalmente chiavi naturali/commerciali, non ID. Laddove esistevano i dati di riferimento, abbiamo deciso di mantenere una tabella per tipo composta da un codice univoco (il VARCHAR PK) e una descrizione. In effetti, allora c'erano molte meno tabelle di riferimento. Il più delle volte, in una colonna verrebbe utilizzato un insieme limitato di codici aziendali, possibilmente con un vincolo di controllo del database definito; non ci sarebbe alcuna tabella di riferimento.
Ma da allora il gioco è andato avanti. Questa è una soluzione a due tabelle potrebbe assomigliare a:
Come puoi vedere, questo modello di dati fisici è molto semplice. Ma è abbastanza diverso dal modello logico, e non perché qualcosa sia andato tutto a forma di pera. È perché molte cose sono state fatte nell'ambito del design fisico .
Il reference_type la tabella rappresenta ogni singola classe di riferimento dell'LDM. Quindi, se hai 20 tipi di riferimento nel tuo LDM, avrai 20 righe di metadati nella tabella. Il reference_value la tabella contiene i valori consentiti per tutti i tipi di riferimento.
Al momento di questo progetto, c'erano alcune discussioni piuttosto animate tra gli sviluppatori. Alcuni preferivano la soluzione a due tavoli e altri preferivano un tavolo per tipo metodo.
Ci sono pro e contro per ogni soluzione. Come puoi immaginare, gli sviluppatori erano principalmente preoccupati per la quantità di lavoro che l'interfaccia utente avrebbe richiesto. Alcuni pensavano che mettere insieme un'interfaccia utente di amministrazione per ogni tabella sarebbe stato piuttosto veloce. Altri pensavano che la creazione di un'unica interfaccia utente di amministrazione sarebbe stata più complessa, ma alla fine avrebbe pagato.
Su questo particolare progetto è stata preferita la soluzione a due tavoli. Diamo un'occhiata più in dettaglio.
Il modello di dati di riferimento estensibile e flessibile
Poiché il tuo modello di dati si evolve nel tempo e sono necessari nuovi tipi di riferimento, non è necessario continuare ad apportare modifiche al database per ogni nuovo tipo di riferimento. Hai solo bisogno di definire nuovi dati di configurazione. Per fare ciò, aggiungi una nuova riga al reference_type tabella e aggiungi il relativo elenco controllato di valori consentiti al reference_value tabella.
Un concetto importante contenuto in questa soluzione è quello di definire periodi di tempo effettivi per determinati valori. Ad esempio, la tua organizzazione potrebbe dover acquisire un nuovo reference_value di "Prova di identità" che sarà accettabile in una data futura. Si tratta semplicemente di aggiungere quel nuovo reference_value con il effective_period_from data impostata correttamente. Questo può essere fatto in anticipo. Fino all'arrivo di tale data, la nuova voce non verrà visualizzata nell'elenco a discesa dei valori visualizzati dagli utenti dell'applicazione. Ciò è dovuto al fatto che l'applicazione visualizza solo i valori correnti o abilitati.
D'altra parte, potresti dover impedire agli utenti di utilizzare un particolare reference_value . In tal caso, aggiornalo semplicemente con il effective_period_to data impostata correttamente. Trascorso quel giorno, il valore non apparirà più nell'elenco a discesa. Diventa disabilitato da quel momento in poi. Ma poiché esiste ancora fisicamente come riga nella tabella, viene mantenuta l'integrità referenziale per quelle tabelle dove è già stato referenziato.
Ora che stavamo lavorando alla soluzione a due tabelle, è apparso evidente che alcune colonne aggiuntive sarebbero state utili su reference_type tavolo. Si trattava principalmente di problemi relativi all'interfaccia utente.
Ad esempio, pretty_name nel reference_type è stata aggiunta la tabella per l'utilizzo nell'interfaccia utente. È utile per le tassonomie di grandi dimensioni utilizzare una finestra con una funzione di ricerca. Quindi pretty_name potrebbe essere utilizzato per il titolo della finestra.
D'altra parte, se è sufficiente un elenco a discesa di valori, pretty_name potrebbe essere utilizzato per il prompt LOV. In modo simile, la descrizione può essere utilizzata nell'interfaccia utente per popolare la guida di rollover.
Dare un'occhiata al tipo di configurazione o ai metadati che entrano in queste tabelle aiuterà a chiarire un po' le cose.
Come gestire tutto ciò
Sebbene l'esempio qui utilizzato sia molto semplice, i valori di riferimento per un progetto di grandi dimensioni possono diventare rapidamente piuttosto complessi. Quindi potrebbe essere consigliabile mantenere tutto questo in un foglio di calcolo. In tal caso, puoi utilizzare il foglio di calcolo stesso per generare l'SQL utilizzando la concatenazione di stringhe. Questo viene incollato in script, che vengono eseguiti sui database di destinazione che supportano il ciclo di vita dello sviluppo e il database di produzione (attivo). Questo semina il database con tutti i dati di riferimento necessari.
Ecco i dati di configurazione per i due tipi di LDM, Gender_Type e Party_Type :
PROMPT Gender_Type INSERT INTO reference_type (id, pretty_name, ref_type_key, description, id_range_from, id_range_to) VALUES (rety_seq.nextval, 'Gender Type', 'GENDER_TYPE', ' Identifies the gender of a person.', 13000000, 13999999); INSERT INTO reference_value (id, pretty_name, description, effective_period_from, alt_sequence, reference_type_id) VALUES (13000010,'Female', 'Female', TRUNC(SYSDATE), 10, rety_seq.currval); INSERT INTO reference_value (id, pretty_name, description, effective_period_from, alt_sequence, reference_type_id) VALUES (13000020,'Male', 'Male', TRUNC(SYSDATE), 20, rety_seq.currval); PROMPT Party_Type INSERT INTO reference_type (id, pretty_name, ref_type_key, description, id_range_from, id_range_to) VALUES (rety_seq.nextval, 'Party Type', 'PARTY_TYPE', A controlled list of reference values that identifies the type of party.', 23000000, 23999999); INSERT INTO reference_value (id, pretty_name, description, effective_period_from, alt_sequence, reference_type_id) VALUES (23000010,'Organisation', 'Organisation', TRUNC(SYSDATE), 10, rety_seq.currval); INSERT INTO reference_value (id, pretty_name, description, effective_period_from, alt_sequence, reference_type_id) VALUES (23000020,'Person', 'Person', TRUNC(SYSDATE), 20, rety_seq.currval);
C'è una riga in reference_type per ogni sottotipo LDM di Root_Reference_Type . La descrizione in reference_type è preso dalla descrizione della classe LDM. Per Gender_Type , si leggerebbe "Identifica il sesso di una persona". Gli snippet DML mostrano le differenze nelle descrizioni tra tipo e valore, che possono essere utilizzate nell'interfaccia utente o nei rapporti.
Vedrai quel reference_type chiamato Gender_Type è stato assegnato un intervallo da 13000000 a 13999999 per il relativo reference_value.ids associato . In questo modello, ogni reference_type viene assegnato un intervallo di ID univoco e non sovrapposto. Questo non è strettamente necessario, ma ci consente di raggruppare insieme gli ID valore correlati. In un certo senso imita quello che otterresti se avessi tavoli separati. È bello averlo, ma se pensi che non ci sia alcun vantaggio in questo, puoi farne a meno.
Un'altra colonna aggiunta al PDM è admin_role . Ecco perché.
Chi sono gli amministratori
Alcune tassonomie possono avere valori aggiunti o rimossi con un impatto minimo o nullo. Ciò si verificherà quando nessun programma utilizza i valori nella propria logica o quando il tipo non è interfacciato ad altri sistemi. In questi casi, è sicuro per gli amministratori degli utenti tenerli aggiornati.
Ma in altri casi, è necessario prestare molta più attenzione. Un nuovo valore di riferimento può causare conseguenze indesiderate alla logica di programmazione o ai sistemi a valle.
Ad esempio, supponiamo di aggiungere quanto segue alla tassonomia del tipo di genere:
INSERT INTO reference_value (id, pretty_name, description, effective_period_from, alt_sequence, reference_type_id) VALUES (13000040,'Not Known', 'Gender has not been recorded. Covers gender of unborn child, when someone has refused to answer the question or when the question has not been asked.', TRUNC(SYSDATE), 30, (SELECT id FROM reference_type WHERE ref_type_key = 'GENDER_TYPE'));
Questo diventa rapidamente un problema se abbiamo la seguente logica integrata da qualche parte:
IF ref_key = 'MALE' THEN RETURN 'M'; ELSE RETURN 'F'; END IF;
Chiaramente, la logica "se non sei maschio devi essere femmina" non si applica più nella tassonomia estesa.
Qui è dove si trova il admin_role entra in gioco la colonna. È nato dalle discussioni con gli sviluppatori sulla progettazione fisica e ha funzionato insieme alla loro soluzione dell'interfaccia utente. Ma se è stata scelta la soluzione di una tabella per classe, allora reference_type non sarebbe esistito. I metadati in esso contenuti sarebbero stati codificati nell'applicazione Gender_Type tabella – , che non è né flessibile né estensibile.
Solo gli utenti con il privilegio corretto possono amministrare la tassonomia. È probabile che ciò si basi sull'esperienza in materia (PMI ). D'altra parte, alcune tassonomie potrebbero dover essere amministrate dall'IT per consentire l'analisi dell'impatto, test approfonditi e il rilascio armonioso di eventuali modifiche al codice in tempo per la nuova configurazione. (Se ciò avvenga tramite richieste di modifica o in altro modo, dipende dalla tua organizzazione.)
Potresti aver notato che le colonne di controllo created_by , created_date , updated_by e updated_date non sono affatto referenziati nello script precedente. Ancora una volta, se non sei interessato a questi non devi usarli. Questa particolare organizzazione aveva uno standard che imponeva di avere colonne di controllo su ogni tabella.
Trigger:mantenere le cose coerenti
I trigger assicurano che queste colonne di controllo siano costantemente aggiornate, indipendentemente dall'origine dell'SQL (script, applicazione, aggiornamenti batch pianificati, aggiornamenti ad hoc e così via).
-------------------------------------------------------------------------------- PROMPT >>> create REFERENCE_TYPE triggers -------------------------------------------------------------------------------- CREATE OR REPLACE TRIGGER rety_bri BEFORE INSERT ON reference_type FOR EACH ROW DECLARE BEGIN IF (:new.id IS NULL) THEN :new.id := rety_seq.nextval; END IF; :new.created_by := function_to_get_user(); :new.created_date := SYSDATE; :new.updated_by := :new.created_by; :new.updated_date := :new.created_date; END rety_bri; / CREATE OR REPLACE TRIGGER rety_bru BEFORE UPDATE ON reference_type FOR EACH ROW DECLARE BEGIN :new.updated_by := function_to_get_user(); :new.updated_date := SYSDATE; END rety_bru; / -------------------------------------------------------------------------------- PROMPT >>> create REFERENCE_VALUE triggers -------------------------------------------------------------------------------- CREATE OR REPLACE TRIGGER reva_bri BEFORE INSERT ON reference_value FOR EACH ROW DECLARE BEGIN IF (:new.type_key IS NULL) THEN -- create the type_key from pretty_name: :new.type_key := function_to_create_key(new.pretty_name); END IF; :new.created_by := function_to_get_user(); :new.created_date := SYSDATE; :new.updated_by := :new.created_by; :new.updated_date := :new.created_date; END reva_bri; / CREATE OR REPLACE TRIGGER reva_bru BEFORE UPDATE ON reference_value FOR EACH ROW DECLARE BEGIN -- once the type_key is set it cannot be overwritten: :new.type_key := :old.type_key; :new.updated_by := function_to_get_user(); :new.updated_date := SYSDATE; END reva_bru; /
Il mio background è principalmente Oracle e, sfortunatamente, Oracle limita gli identificatori a 30 byte. Per evitare di superarlo, a ciascuna tabella viene assegnato un breve alias da tre a cinque caratteri e altri artefatti relativi alla tabella utilizzano quell'alias nei loro nomi. Quindi, reference_value L'alias di è reva – i primi due caratteri di ogni parola. Prima dell'inserimento riga e prima che l'aggiornamento della riga sia abbreviato in bri e bru rispettivamente. Il nome della sequenza reva_seq , e così via.
I trigger di codifica manuale come questo, tabella dopo tabella, richiedono molto lavoro demoralizzante per gli sviluppatori. Fortunatamente, questi attivatori possono essere creati tramite la generazione di codice , ma questo è l'argomento di un altro articolo!
L'importanza delle chiavi
Il ref_type_key e type_key le colonne sono entrambe limitate a 30 byte. Ciò consente loro di essere utilizzati nelle query SQL di tipo PIVOT (in Oracle. Altri database potrebbero non avere la stessa limitazione della lunghezza dell'identificatore).
Poiché l'univocità della chiave è garantita dal database e il trigger assicura che il suo valore rimanga lo stesso per sempre, queste chiavi possono – e dovrebbero – essere utilizzate nelle query e nel codice per renderle più leggibili . Cosa intendo con questo? Bene, invece di:
SELECT … FROM … INNER JOIN … WHERE reference_value.id = 13000020
Tu scrivi:
SELECT … FROM … INNER JOIN … WHERE reference_value.type_key = 'MALE'
Fondamentalmente, la chiave indica chiaramente cosa sta facendo la query .
Da LDM a PDM, con spazio per crescere
Il viaggio da LDM a PDM non è necessariamente una strada dritta. Né è una trasformazione diretta dall'uno all'altro. È un processo separato che introduce le proprie considerazioni e le proprie preoccupazioni.
Come modelli i dati di riferimento nel tuo database?