Per il T-SQL Tuesday di questo mese, Steve Jones (@way0utwest) ci ha chiesto di parlare delle nostre esperienze di trigger migliori o peggiori. Sebbene sia vero che i trigger sono spesso disapprovati e persino temuti, hanno diversi casi d'uso validi, tra cui:
- Auditing (prima del 2016 SP1, quando questa funzione è diventata gratuita in tutte le edizioni)
- Applicazione delle regole aziendali e dell'integrità dei dati, quando non possono essere facilmente implementate nei vincoli e non si desidera che dipendano dal codice dell'applicazione o dalle query DML stesse
- Mantenimento delle versioni storiche dei dati (prima di Change Data Capture, Change Tracking e Tabelle temporali)
- Avvisi in coda o elaborazione asincrona in risposta a una modifica specifica
- Consentire modifiche alle visualizzazioni (tramite INSTEAD OF trigger)
Questo non è un elenco esaustivo, solo un breve riepilogo di alcuni scenari che ho sperimentato in cui i trigger erano la risposta giusta in quel momento.
Quando i trigger sono necessari, mi piace sempre esplorare l'uso dei trigger INSTEAD OF piuttosto che i trigger AFTER. Sì, sono un po' più di lavoro in anticipo*, ma hanno alcuni vantaggi piuttosto importanti. In teoria, almeno, la prospettiva di impedire che un'azione (e le sue conseguenze logistiche) avvenga sembra molto più efficiente che lasciare che tutto accada e poi annullarlo.
Lo dico perché devi codificare nuovamente l'istruzione DML all'interno del trigger; questo è il motivo per cui non sono chiamati BEFORE trigger. La distinzione è importante qui, poiché alcuni sistemi implementano veri trigger PRIMA, che semplicemente vengono eseguiti per primi. In SQL Server, un trigger INSTEAD OF annulla in modo efficace l'istruzione che ne ha causato l'attivazione.
Facciamo finta di avere una semplice tabella per memorizzare i nomi degli account. In questo esempio creeremo due tabelle, in modo da poter confrontare due diversi trigger e il loro impatto sulla durata della query e sull'utilizzo del registro. Il concetto è che abbiamo una regola aziendale:il nome dell'account non è presente in un'altra tabella, che rappresenta i nomi "cattivi" e il trigger viene utilizzato per applicare questa regola. Ecco il database:
USE [master];
GO
CREATE DATABASE [tr] ON (name = N'tr_dat', filename = N'C:\temp\tr.mdf', size = 4096MB)
LOG ON (name = N'tr_log', filename = N'C:\temp\tr.ldf', size = 2048MB);
GO
ALTER DATABASE [tr] SET RECOVERY FULL;
GO E i tavoli:
USE [tr]; GO CREATE TABLE dbo.Accounts_After ( AccountID int PRIMARY KEY, name sysname UNIQUE, filler char(255) NOT NULL DEFAULT '' ); CREATE TABLE dbo.Accounts_Instead ( AccountID int PRIMARY KEY, name sysname UNIQUE, filler char(255) NOT NULL DEFAULT '' ); CREATE TABLE dbo.InvalidNames ( name sysname PRIMARY KEY ); INSERT dbo.InvalidNames(name) VALUES (N'poop'),(N'hitler'),(N'boobies'),(N'cocaine');
E, infine, i trigger. Per semplicità, abbiamo a che fare solo con inserti e, sia nel caso successivo che in quello invece di, interromperemo l'intero batch se un singolo nome viola la nostra regola:
CREATE TRIGGER dbo.tr_Accounts_After
ON dbo.Accounts_After
AFTER INSERT
AS
BEGIN
IF EXISTS
(
SELECT 1 FROM inserted AS i
INNER JOIN dbo.InvalidNames AS n
ON i.name = n.name
)
BEGIN
RAISERROR(N'Tsk tsk.', 11, 1);
ROLLBACK TRANSACTION;
RETURN;
END
END
GO
CREATE TRIGGER dbo.tr_Accounts_Instead
ON dbo.Accounts_After
INSTEAD OF INSERT
AS
BEGIN
IF EXISTS
(
SELECT 1 FROM inserted AS i
INNER JOIN dbo.InvalidNames AS n
ON i.name = n.name
)
BEGIN
RAISERROR(N'Tsk tsk.', 11, 1);
RETURN;
END
ELSE
BEGIN
INSERT dbo.Accounts_Instead(AccountID, name, filler)
SELECT AccountID, name, filler FROM inserted;
END
END
GO Ora, per testare le prestazioni, proveremo semplicemente a inserire 100.000 nomi in ciascuna tabella, con un tasso di errore prevedibile del 10%. In altre parole, 90.000 vanno bene nomi, gli altri 10.000 non superano il test e causano il rollback o il mancato inserimento del trigger a seconda del batch.
Innanzitutto, dobbiamo eseguire un po' di pulizia prima di ogni batch:
TRUNCATE TABLE dbo.Accounts_Instead; TRUNCATE TABLE dbo.Accounts_After; GO CHECKPOINT; CHECKPOINT; BACKUP LOG triggers TO DISK = N'C:\temp\tr.trn' WITH INIT, COMPRESSION; GO
Prima di iniziare la lavorazione di ogni batch, conteremo le righe nel registro delle transazioni e misureremo le dimensioni e lo spazio libero. Quindi esamineremo un cursore per elaborare le 100.000 righe in ordine casuale, tentando di inserire ciascun nome nella tabella appropriata. Al termine, misureremo nuovamente il numero di righe e le dimensioni del registro e verificheremo la durata.
SET NOCOUNT ON;
DECLARE @batch varchar(10) = 'After', -- or After
@d datetime2(7) = SYSUTCDATETIME(),
@n nvarchar(129),
@i int,
@err nvarchar(512);
-- measure before and again when we're done:
SELECT COUNT(*) FROM sys.fn_dblog(NULL, NULL);
SELECT CurrentSizeMB = size/128.0,
FreeSpaceMB = (size-CONVERT(int, FILEPROPERTY(name,N'SpaceUsed')))/128.0
FROM sys.database_files
WHERE name = N'tr_log';
DECLARE c CURSOR LOCAL FAST_FORWARD
FOR
SELECT name, i = ROW_NUMBER() OVER (ORDER BY NEWID())
FROM
(
SELECT DISTINCT TOP (90000) LEFT(o.name,64) + '/' + LEFT(c.name,63)
FROM sys.all_objects AS o
CROSS JOIN sys.all_columns AS c
UNION ALL
SELECT TOP (10000) N'boobies' FROM sys.all_columns
) AS x (name)
ORDER BY i;
OPEN c;
FETCH NEXT FROM c INTO @n, @i;
WHILE @@FETCH_STATUS = 0
BEGIN
BEGIN TRY
IF @batch = 'After'
INSERT dbo.Accounts_After(AccountID,name) VALUES(@i,@n);
IF @batch = 'Instead'
INSERT dbo.Accounts_Instead(AccountID,name) VALUES(@i,@n);
END TRY
BEGIN CATCH
SET @err = ERROR_MESSAGE();
END CATCH
FETCH NEXT FROM c INTO @n, @i;
END
-- measure again when we're done:
SELECT COUNT(*) FROM sys.fn_dblog(NULL, NULL);
SELECT duration = DATEDIFF(MILLISECOND, @d, SYSUTCDATETIME()),
CurrentSizeMB = size/128.0,
FreeSpaceMB = (size-CAST(FILEPROPERTY(name,N'SpaceUsed') AS int))/128.0
FROM sys.database_files
WHERE name = N'tr_log';
CLOSE c; DEALLOCATE c; Risultati (media su 5 esecuzioni di ciascun batch):
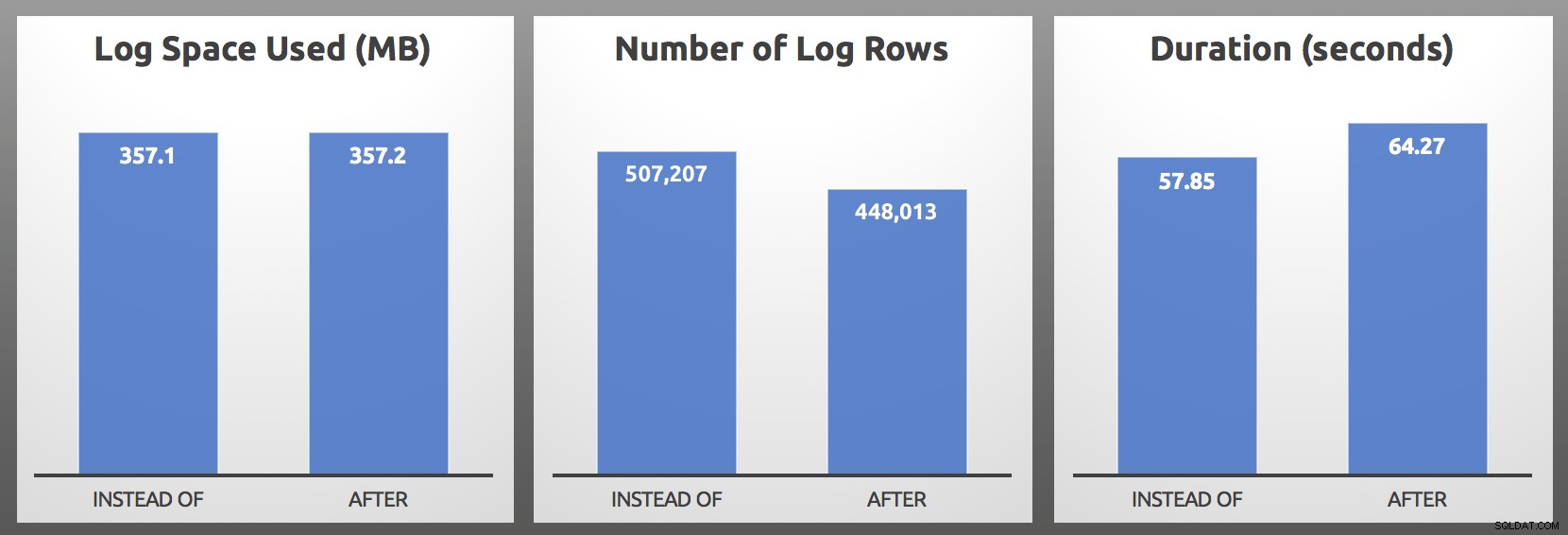 DOPO vs. INVECE DI :Risultati
DOPO vs. INVECE DI :Risultati
Nei miei test, l'utilizzo del registro era di dimensioni quasi identiche, con oltre il 10% in più di righe di registro generate dal trigger INSTEAD OF. Ho scavato un po' alla fine di ogni batch:
SELECT [Operation], COUNT(*) FROM sys.fn_dblog(NULL, NULL) GROUP BY [Operation] ORDER BY [Operation];
Ed ecco un risultato tipico (ho evidenziato i delta maggiori):
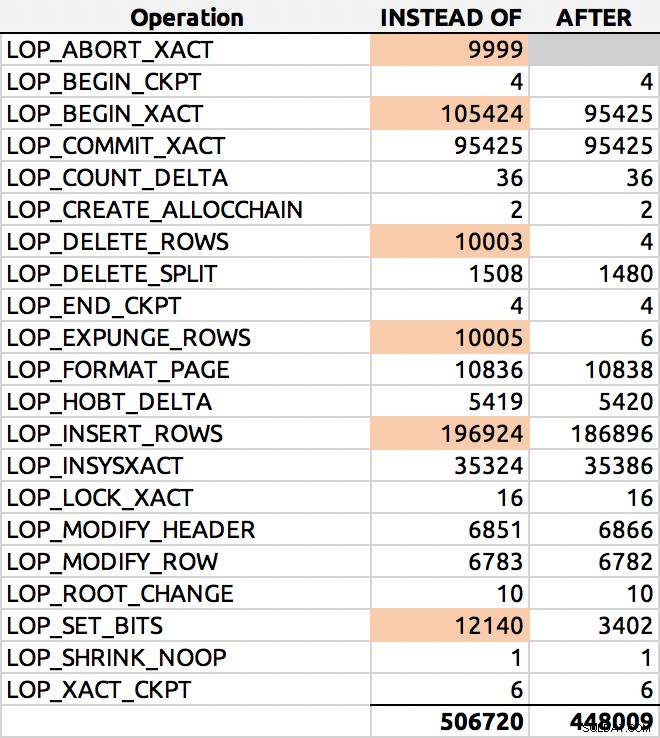 Distribuzione delle righe del registro
Distribuzione delle righe del registro
Lo approfondirò più a fondo un'altra volta.
Ma quando arrivi al punto...
...la metrica più importante sarà quasi sempre la durata e nel mio caso il trigger INSTEAD OF ha eseguito almeno 5 secondi più velocemente in ogni singolo test testa a testa. Nel caso tutto ciò suonasse familiare, sì, ne ho parlato prima, ma allora non osservavo questi stessi sintomi con le righe del registro.
Tieni presente che questo potrebbe non essere il tuo schema o carico di lavoro esatto, potresti avere hardware molto diverso, la tua concorrenza potrebbe essere maggiore e il tuo tasso di errore potrebbe essere molto più alto (o inferiore). I miei test sono stati eseguiti su una macchina isolata con molta memoria e SSD PCIe molto veloci. Se il tuo registro si trova su un'unità più lenta, le differenze nell'utilizzo del registro potrebbero superare le altre metriche e modificare in modo significativo la durata. Tutti questi fattori (e molti altri!) possono influenzare i tuoi risultati, quindi dovresti testare nel tuo ambiente.
Il punto, tuttavia, è che i trigger INSTEAD OF potrebbero essere più adatti. Ora, se solo potessimo ottenere INVECE DEI trigger DDL...