Le attività Gaps and Islands sono classiche sfide di query in cui è necessario identificare intervalli di valori mancanti e intervalli di valori esistenti in una sequenza. La sequenza è spesso basata su alcuni valori di data, o data e ora, che normalmente dovrebbero apparire a intervalli regolari, ma mancano alcune voci. L'attività lacune cerca i periodi mancanti e l'attività isole cerca i periodi esistenti. In passato ho trattato molte soluzioni alle lacune e alle attività delle isole nei miei libri e articoli. Di recente mi è stata presentata una nuova sfida per isole speciali dal mio amico Adam Machanic e risolverla ha richiesto un po' di creatività. In questo articolo presento la sfida e la soluzione che ho trovato.
La sfida
Nel tuo database tieni traccia dei servizi supportati dalla tua azienda in una tabella chiamata CompanyServices e ogni servizio normalmente segnala circa una volta al minuto che è online in una tabella chiamata EventLog. Il codice seguente crea queste tabelle e le popola con piccoli set di dati di esempio:
SET NOCOUNT ON; USE tempdb; IF OBJECT_ID(N'dbo.EventLog') IS NOT NULL DROP TABLE dbo.EventLog; IF OBJECT_ID(N'dbo.CompanyServices') IS NOT NULL DROP TABLE dbo.CompanyServices; CREATE TABLE dbo.CompanyServices ( serviceid INT NOT NULL, CONSTRAINT PK_CompanyServices PRIMARY KEY(serviceid) ); GO INSERT INTO dbo.CompanyServices(serviceid) VALUES(1), (2), (3); CREATE TABLE dbo.EventLog ( logid INT NOT NULL IDENTITY, serviceid INT NOT NULL, logtime DATETIME2(0) NOT NULL, CONSTRAINT PK_EventLog PRIMARY KEY(logid) ); GO INSERT INTO dbo.EventLog(serviceid, logtime) VALUES (1, '20180912 08:00:00'), (1, '20180912 08:01:01'), (1, '20180912 08:01:59'), (1, '20180912 08:03:00'), (1, '20180912 08:05:00'), (1, '20180912 08:06:02'), (2, '20180912 08:00:02'), (2, '20180912 08:01:03'), (2, '20180912 08:02:01'), (2, '20180912 08:03:00'), (2, '20180912 08:03:59'), (2, '20180912 08:05:01'), (2, '20180912 08:06:01'), (3, '20180912 08:00:01'), (3, '20180912 08:03:01'), (3, '20180912 08:04:02'), (3, '20180912 08:06:00'); SELECT * FROM dbo.EventLog;
La tabella EventLog è attualmente popolata con i seguenti dati:
logid serviceid logtime ----------- ----------- --------------------------- 1 1 2018-09-12 08:00:00 2 1 2018-09-12 08:01:01 3 1 2018-09-12 08:01:59 4 1 2018-09-12 08:03:00 5 1 2018-09-12 08:05:00 6 1 2018-09-12 08:06:02 7 2 2018-09-12 08:00:02 8 2 2018-09-12 08:01:03 9 2 2018-09-12 08:02:01 10 2 2018-09-12 08:03:00 11 2 2018-09-12 08:03:59 12 2 2018-09-12 08:05:01 13 2 2018-09-12 08:06:01 14 3 2018-09-12 08:00:01 15 3 2018-09-12 08:03:01 16 3 2018-09-12 08:04:02 17 3 2018-09-12 08:06:00
L'attività delle isole speciali consiste nell'identificare i periodi di disponibilità (servizio, ora di inizio, ora di fine). Un problema è che non vi è alcuna garanzia che un servizio riporti che è online esattamente ogni minuto; dovresti tollerare un intervallo fino a, diciamo, 66 secondi dalla voce di registro precedente e considerarlo comunque parte dello stesso periodo di disponibilità (isola). Oltre i 66 secondi, la nuova voce di registro avvia un nuovo periodo di disponibilità. Quindi, per i dati di esempio di input sopra, la tua soluzione dovrebbe restituire il seguente set di risultati (non necessariamente in questo ordine):
serviceid starttime endtime ----------- --------------------------- --------------------------- 1 2018-09-12 08:00:00 2018-09-12 08:03:00 1 2018-09-12 08:05:00 2018-09-12 08:06:02 2 2018-09-12 08:00:02 2018-09-12 08:06:01 3 2018-09-12 08:00:01 2018-09-12 08:00:01 3 2018-09-12 08:03:01 2018-09-12 08:04:02 3 2018-09-12 08:06:00 2018-09-12 08:06:00
Si noti, ad esempio, come la voce di registro 5 avvia una nuova isola poiché l'intervallo dalla voce di registro precedente è 120 secondi (> 66), mentre la voce di registro 6 non avvia una nuova isola poiché l'intervallo dalla voce precedente è di 62 secondi ( <=66). Un altro problema è che Adam voleva che la soluzione fosse compatibile con gli ambienti precedenti a SQL Server 2012, il che lo rende una sfida molto più difficile, poiché non è possibile utilizzare le funzioni di aggregazione della finestra con un frame per calcolare i totali parziali e compensare le funzioni della finestra come LAG e LEAD. Come al solito, suggerisco di provare a risolvere la sfida da soli prima di guardare le mie soluzioni. Utilizza i piccoli set di dati campione per verificare la validità delle tue soluzioni. Utilizzare il codice seguente per popolare le tabelle con grandi set di dati di esempio (500 servizi, ~10 milioni di voci di registro per testare le prestazioni delle soluzioni):
-- Helper function dbo.GetNums
IF OBJECT_ID(N'dbo.GetNums') IS NOT NULL DROP FUNCTION dbo.GetNums;
GO
CREATE FUNCTION dbo.GetNums(@low AS BIGINT, @high AS BIGINT) RETURNS TABLE
AS
RETURN
WITH
L0 AS (SELECT c FROM (SELECT 1 UNION ALL SELECT 1) AS D(c)),
L1 AS (SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B),
L2 AS (SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B),
L3 AS (SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B),
L4 AS (SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B),
L5 AS (SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B),
Nums AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L5)
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum;
GO
-- ~10,000,000 intervals
DECLARE
@numservices AS INT = 500,
@logsperservice AS INT = 20000,
@enddate AS DATETIME2(0) = '20180912',
@validinterval AS INT = 60, -- seconds
@normdifferential AS INT = 3, -- seconds
@percentmissing AS FLOAT = 0.01;
TRUNCATE TABLE dbo.EventLog;
TRUNCATE TABLE dbo.CompanyServices;
INSERT INTO dbo.CompanyServices(serviceid)
SELECT A.n AS serviceid
FROM dbo.GetNums(1, @numservices) AS A;
WITH C AS
(
SELECT S.n AS serviceid,
DATEADD(second, -L.n * @validinterval + CHECKSUM(NEWID()) % (@normdifferential + 1), @enddate) AS logtime,
RAND(CHECKSUM(NEWID())) AS rnd
FROM dbo.GetNums(1, @numservices) AS S
CROSS JOIN dbo.GetNums(1, @logsperservice) AS L
)
INSERT INTO dbo.EventLog WITH (TABLOCK) (serviceid, logtime)
SELECT serviceid, logtime
FROM C
WHERE rnd > @percentmissing; Gli output che fornirò per i passaggi delle mie soluzioni presupporranno i piccoli set di dati di esempio e i numeri delle prestazioni che fornirò presupporranno gli insiemi di grandi dimensioni.
Tutte le soluzioni che presenterò beneficiano del seguente indice:
CREATE INDEX idx_sid_ltm_lid ON dbo.EventLog(serviceid, logtime, logid);
Buona fortuna!
Soluzione 1 per SQL Server 2012+
Prima di illustrare una soluzione compatibile con ambienti precedenti a SQL Server 2012, tratterò una soluzione che richiede almeno SQL Server 2012. La chiamerò Soluzione 1.
Il primo passaggio della soluzione è calcolare un flag chiamato isstart che è 0 se l'evento non avvia una nuova isola e 1 altrimenti. Ciò può essere ottenuto utilizzando la funzione LAG per ottenere il tempo di registro dell'evento precedente e verificando se la differenza di tempo in secondi tra l'evento precedente e quello attuale è inferiore o uguale al gap consentito. Ecco il codice che implementa questo passaggio:
DECLARE @allowedgap AS INT = 66; -- in seconds
SELECT *,
CASE
WHEN DATEDIFF(second,
LAG(logtime) OVER(PARTITION BY serviceid ORDER BY logtime, logid),
logtime) <= @allowedgap THEN 0
ELSE 1
END AS isstart
FROM dbo.EventLog; Questo codice genera il seguente output:
logid serviceid logtime isstart ----------- ----------- --------------------------- ----------- 1 1 2018-09-12 08:00:00 1 2 1 2018-09-12 08:01:01 0 3 1 2018-09-12 08:01:59 0 4 1 2018-09-12 08:03:00 0 5 1 2018-09-12 08:05:00 1 6 1 2018-09-12 08:06:02 0 7 2 2018-09-12 08:00:02 1 8 2 2018-09-12 08:01:03 0 9 2 2018-09-12 08:02:01 0 10 2 2018-09-12 08:03:00 0 11 2 2018-09-12 08:03:59 0 12 2 2018-09-12 08:05:01 0 13 2 2018-09-12 08:06:01 0 14 3 2018-09-12 08:00:01 1 15 3 2018-09-12 08:03:01 1 16 3 2018-09-12 08:04:02 0 17 3 2018-09-12 08:06:00 1
Successivamente, un semplice totale parziale del flag isstart produce un identificatore dell'isola (lo chiamerò grp). Ecco il codice che implementa questo passaggio:
DECLARE @allowedgap AS INT = 66;
WITH C1 AS
(
SELECT *,
CASE
WHEN DATEDIFF(second,
LAG(logtime) OVER(PARTITION BY serviceid ORDER BY logtime, logid),
logtime) <= @allowedgap THEN 0
ELSE 1
END AS isstart
FROM dbo.EventLog
)
SELECT *,
SUM(isstart) OVER(PARTITION BY serviceid ORDER BY logtime, logid
ROWS UNBOUNDED PRECEDING) AS grp
FROM C1; Questo codice genera il seguente output:
logid serviceid logtime isstart grp ----------- ----------- --------------------------- ----------- ----------- 1 1 2018-09-12 08:00:00 1 1 2 1 2018-09-12 08:01:01 0 1 3 1 2018-09-12 08:01:59 0 1 4 1 2018-09-12 08:03:00 0 1 5 1 2018-09-12 08:05:00 1 2 6 1 2018-09-12 08:06:02 0 2 7 2 2018-09-12 08:00:02 1 1 8 2 2018-09-12 08:01:03 0 1 9 2 2018-09-12 08:02:01 0 1 10 2 2018-09-12 08:03:00 0 1 11 2 2018-09-12 08:03:59 0 1 12 2 2018-09-12 08:05:01 0 1 13 2 2018-09-12 08:06:01 0 1 14 3 2018-09-12 08:00:01 1 1 15 3 2018-09-12 08:03:01 1 2 16 3 2018-09-12 08:04:02 0 2 17 3 2018-09-12 08:06:00 1 3
Infine, raggruppi le righe in base all'ID servizio e all'identificatore dell'isola e restituisci i tempi di registrazione minimi e massimi come ora di inizio e ora di fine di ciascuna isola. Ecco la soluzione completa:
DECLARE @allowedgap AS INT = 66;
WITH C1 AS
(
SELECT *,
CASE
WHEN DATEDIFF(second,
LAG(logtime) OVER(PARTITION BY serviceid ORDER BY logtime, logid),
logtime) <= @allowedgap THEN 0
ELSE 1
END AS isstart
FROM dbo.EventLog
),
C2 AS
(
SELECT *,
SUM(isstart) OVER(PARTITION BY serviceid ORDER BY logtime, logid
ROWS UNBOUNDED PRECEDING) AS grp
FROM C1
)
SELECT serviceid, MIN(logtime) AS starttime, MAX(logtime) AS endtime
FROM C2
GROUP BY serviceid, grp; Questa soluzione ha richiesto 41 secondi per essere completata sul mio sistema e ha prodotto il piano mostrato nella Figura 1.
 Figura 1:piano per la soluzione 1
Figura 1:piano per la soluzione 1
Come puoi vedere, entrambe le funzioni della finestra sono calcolate in base all'ordine degli indici, senza la necessità di un ordinamento esplicito.
Se stai utilizzando SQL Server 2016 o versioni successive, puoi utilizzare il trucco che tratterò qui per abilitare l'operatore Window Aggregate in modalità batch creando un indice columnstore filtrato vuoto, in questo modo:
CREATE NONCLUSTERED COLUMNSTORE INDEX idx_cs ON dbo.EventLog(logid) WHERE logid = -1 AND logid = -2;
La stessa soluzione ora richiede solo 5 secondi per essere completata sul mio sistema, producendo il piano mostrato nella Figura 2.
 Figura 2:piano per la soluzione 1 utilizzando l'operatore Window Aggregate in modalità batch
Figura 2:piano per la soluzione 1 utilizzando l'operatore Window Aggregate in modalità batch
È tutto fantastico, ma come accennato, Adam stava cercando una soluzione che potesse essere eseguita in ambienti precedenti al 2012.
Prima di continuare, assicurati di eliminare l'indice columnstore per la pulizia:
DROP INDEX idx_cs ON dbo.EventLog;
Soluzione 2 per ambienti precedenti a SQL Server 2012
Sfortunatamente, prima di SQL Server 2012, non avevamo il supporto per le funzioni della finestra di offset come LAG, né il supporto per il calcolo dei totali parziali con le funzioni di aggregazione della finestra con un frame. Ciò significa che dovrai lavorare molto più duramente per trovare una soluzione ragionevole.
Il trucco che ho usato è trasformare ogni voce di registro in un intervallo artificiale la cui ora di inizio è l'ora di registrazione della voce e la cui ora di fine è l'ora di registrazione della voce più il divario consentito. Puoi quindi considerare l'attività come una classica attività di imballaggio a intervalli.
Il primo passaggio della soluzione calcola i delimitatori di intervallo artificiali e i numeri di riga che contrassegnano le posizioni di ciascuno dei tipi di evento (counteach). Ecco il codice che implementa questo passaggio:
DECLARE @allowedgap AS INT = 66; SELECT logid, serviceid, logtime AS s, -- important, 's' > 'e', for later ordering DATEADD(second, @allowedgap, logtime) AS e, ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, logid) AS counteach FROM dbo.EventLog;
Questo codice genera il seguente output:
logid serviceid s e counteach ------ ---------- -------------------- -------------------- ---------- 1 1 2018-09-12 08:00:00 2018-09-12 08:01:06 1 2 1 2018-09-12 08:01:01 2018-09-12 08:02:07 2 3 1 2018-09-12 08:01:59 2018-09-12 08:03:05 3 4 1 2018-09-12 08:03:00 2018-09-12 08:04:06 4 5 1 2018-09-12 08:05:00 2018-09-12 08:06:06 5 6 1 2018-09-12 08:06:02 2018-09-12 08:07:08 6 7 2 2018-09-12 08:00:02 2018-09-12 08:01:08 1 8 2 2018-09-12 08:01:03 2018-09-12 08:02:09 2 9 2 2018-09-12 08:02:01 2018-09-12 08:03:07 3 10 2 2018-09-12 08:03:00 2018-09-12 08:04:06 4 11 2 2018-09-12 08:03:59 2018-09-12 08:05:05 5 12 2 2018-09-12 08:05:01 2018-09-12 08:06:07 6 13 2 2018-09-12 08:06:01 2018-09-12 08:07:07 7 14 3 2018-09-12 08:00:01 2018-09-12 08:01:07 1 15 3 2018-09-12 08:03:01 2018-09-12 08:04:07 2 16 3 2018-09-12 08:04:02 2018-09-12 08:05:08 3 17 3 2018-09-12 08:06:00 2018-09-12 08:07:06 4
Il passaggio successivo consiste nell'annullare gli intervalli in una sequenza cronologica di eventi di inizio e fine, identificati rispettivamente come tipi di evento 's' ed 'e'. Nota che la scelta delle lettere se e e è importante ('s' > 'e' ). Questo passaggio calcola i numeri di riga che contrassegnano l'ordine cronologico corretto di entrambi i tipi di eventi, che ora sono intercalati (countboth). Nel caso in cui un intervallo finisca esattamente dove inizia un altro, posizionando l'evento di inizio prima dell'evento di fine, li impacchetterai insieme. Ecco il codice che implementa questo passaggio:
DECLARE @allowedgap AS INT = 66;
WITH C1 AS
(
SELECT logid, serviceid,
logtime AS s, -- important, 's' > 'e', for later ordering
DATEADD(second, @allowedgap, logtime) AS e,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, logid) AS counteach
FROM dbo.EventLog
)
SELECT logid, serviceid, logtime, eventtype, counteach,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) AS countboth
FROM C1
UNPIVOT(logtime FOR eventtype IN (s, e)) AS U; Questo codice genera il seguente output:
logid serviceid logtime eventtype counteach countboth ------ ---------- -------------------- ---------- ---------- ---------- 1 1 2018-09-12 08:00:00 s 1 1 2 1 2018-09-12 08:01:01 s 2 2 1 1 2018-09-12 08:01:06 e 1 3 3 1 2018-09-12 08:01:59 s 3 4 2 1 2018-09-12 08:02:07 e 2 5 4 1 2018-09-12 08:03:00 s 4 6 3 1 2018-09-12 08:03:05 e 3 7 4 1 2018-09-12 08:04:06 e 4 8 5 1 2018-09-12 08:05:00 s 5 9 6 1 2018-09-12 08:06:02 s 6 10 5 1 2018-09-12 08:06:06 e 5 11 6 1 2018-09-12 08:07:08 e 6 12 7 2 2018-09-12 08:00:02 s 1 1 8 2 2018-09-12 08:01:03 s 2 2 7 2 2018-09-12 08:01:08 e 1 3 9 2 2018-09-12 08:02:01 s 3 4 8 2 2018-09-12 08:02:09 e 2 5 10 2 2018-09-12 08:03:00 s 4 6 9 2 2018-09-12 08:03:07 e 3 7 11 2 2018-09-12 08:03:59 s 5 8 10 2 2018-09-12 08:04:06 e 4 9 12 2 2018-09-12 08:05:01 s 6 10 11 2 2018-09-12 08:05:05 e 5 11 13 2 2018-09-12 08:06:01 s 7 12 12 2 2018-09-12 08:06:07 e 6 13 13 2 2018-09-12 08:07:07 e 7 14 14 3 2018-09-12 08:00:01 s 1 1 14 3 2018-09-12 08:01:07 e 1 2 15 3 2018-09-12 08:03:01 s 2 3 16 3 2018-09-12 08:04:02 s 3 4 15 3 2018-09-12 08:04:07 e 2 5 16 3 2018-09-12 08:05:08 e 3 6 17 3 2018-09-12 08:06:00 s 4 7 17 3 2018-09-12 08:07:06 e 4 8
Come accennato, counteach segna la posizione dell'evento solo tra gli eventi dello stesso tipo e countboth segna la posizione dell'evento tra gli eventi combinati, intercalati, di entrambi i tipi.
La magia viene quindi gestita dal passaggio successivo, il calcolo del conteggio degli intervalli attivi dopo ogni evento basato su counteach e countboth. Il numero di intervalli attivi è il numero di eventi iniziali verificatisi fino a quel momento meno il numero di eventi finali verificatisi fino a quel momento. Per gli eventi iniziali, counteach ti dice quanti eventi iniziali sono accaduti fino a quel momento e puoi capire quanti sono finiti finora sottraendo counteach da countboth. Quindi, l'espressione completa che ti dice quanti intervalli sono attivi è quindi:
counteach - (countboth - counteach)
Per gli eventi finali, counteach ti dice quanti eventi finali sono accaduti finora e puoi capire quanti sono iniziati finora sottraendo counteach da countboth. Quindi, l'espressione completa che ti dice quanti intervalli sono attivi è quindi:
(countboth - counteach) - counteach
Utilizzando la seguente espressione CASE, calcoli la colonna countactive in base al tipo di evento:
CASE
WHEN eventtype = 's' THEN
counteach - (countboth - counteach)
WHEN eventtype = 'e' THEN
(countboth - counteach) - counteach
END Nello stesso passaggio si filtrano solo gli eventi che rappresentano l'inizio e la fine degli intervalli compressi. Gli inizi degli intervalli compressi hanno un tipo 's' e un countactive 1. Le estremità degli intervalli compressi hanno un tipo 'e' e uno countactive 0.
Dopo il filtraggio, ti rimangono coppie di eventi inizio-fine di intervalli compressi, ma ogni coppia è divisa in due righe, una per l'evento di inizio e un'altra per l'evento di fine. Pertanto, lo stesso passaggio calcola l'identificatore di coppia utilizzando i numeri di riga, con la formula (rownum – 1) / 2 + 1.
Ecco il codice che implementa questo passaggio:
DECLARE @allowedgap AS INT = 66;
WITH C1 AS
(
SELECT logid, serviceid,
logtime AS s, -- important, 's' > 'e', for later ordering
DATEADD(second, @allowedgap, logtime) AS e,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, logid) AS counteach
FROM dbo.EventLog
),
C2 AS
(
SELECT logid, serviceid, logtime, eventtype, counteach,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) AS countboth
FROM C1
UNPIVOT(logtime FOR eventtype IN (s, e)) AS U
)
SELECT serviceid, eventtype, logtime,
(ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) - 1) / 2 + 1 AS grp
FROM C2
CROSS APPLY ( VALUES( CASE
WHEN eventtype = 's' THEN
counteach - (countboth - counteach)
WHEN eventtype = 'e' THEN
(countboth - counteach) - counteach
END ) ) AS A(countactive)
WHERE (eventtype = 's' AND countactive = 1)
OR (eventtype = 'e' AND countactive = 0); Questo codice genera il seguente output:
serviceid eventtype logtime grp ----------- ---------- -------------------- ---- 1 s 2018-09-12 08:00:00 1 1 e 2018-09-12 08:04:06 1 1 s 2018-09-12 08:05:00 2 1 e 2018-09-12 08:07:08 2 2 s 2018-09-12 08:00:02 1 2 e 2018-09-12 08:07:07 1 3 s 2018-09-12 08:00:01 1 3 e 2018-09-12 08:01:07 1 3 s 2018-09-12 08:03:01 2 3 e 2018-09-12 08:05:08 2 3 s 2018-09-12 08:06:00 3 3 e 2018-09-12 08:07:06 3
L'ultimo passaggio ruota le coppie di eventi in una riga per intervallo e sottrae l'intervallo consentito dall'ora di fine per rigenerare l'ora dell'evento corretta. Ecco il codice completo della soluzione:
DECLARE @allowedgap AS INT = 66;
WITH C1 AS
(
SELECT logid, serviceid,
logtime AS s, -- important, 's' > 'e', for later ordering
DATEADD(second, @allowedgap, logtime) AS e,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, logid) AS counteach
FROM dbo.EventLog
),
C2 AS
(
SELECT logid, serviceid, logtime, eventtype, counteach,
ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) AS countboth
FROM C1
UNPIVOT(logtime FOR eventtype IN (s, e)) AS U
),
C3 AS
(
SELECT serviceid, eventtype, logtime,
(ROW_NUMBER() OVER(PARTITION BY serviceid ORDER BY logtime, eventtype DESC, logid) - 1) / 2 + 1 AS grp
FROM C2
CROSS APPLY ( VALUES( CASE
WHEN eventtype = 's' THEN
counteach - (countboth - counteach)
WHEN eventtype = 'e' THEN
(countboth - counteach) - counteach
END ) ) AS A(countactive)
WHERE (eventtype = 's' AND countactive = 1)
OR (eventtype = 'e' AND countactive = 0)
)
SELECT serviceid, s AS starttime, DATEADD(second, -@allowedgap, e) AS endtime
FROM C3
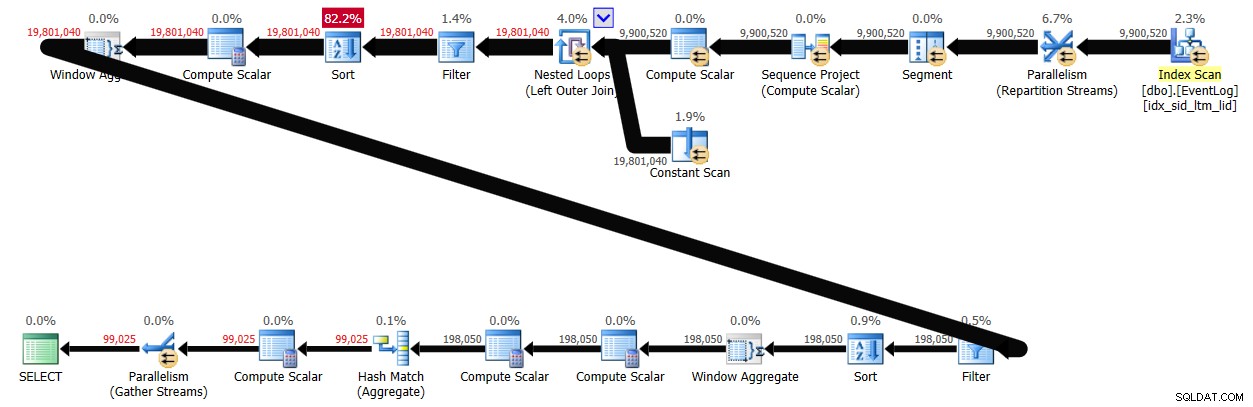
PIVOT( MAX(logtime) FOR eventtype IN (s, e) ) AS P; Questa soluzione ha richiesto 43 secondi per essere completata sul mio sistema e ha generato il piano mostrato nella Figura 3.
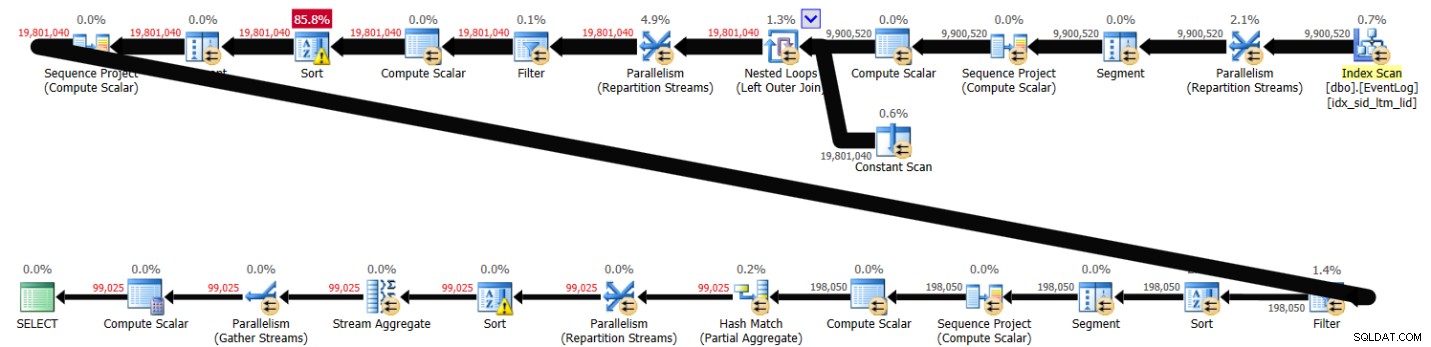 Figura 3:piano per la soluzione 2
Figura 3:piano per la soluzione 2
Come puoi vedere, il calcolo del numero della prima riga viene calcolato in base all'ordine dell'indice, ma i due successivi implicano l'ordinamento esplicito. Tuttavia, le prestazioni non sono così male considerando che sono coinvolte circa 10.000.000 di righe.
Anche se il punto di questa soluzione è usare un ambiente pre-SQL Server 2012, solo per divertimento, ho testato le sue prestazioni dopo aver creato un indice columnstore filtrato per vedere come funziona con l'elaborazione batch abilitata:
CREATE NONCLUSTERED COLUMNSTORE INDEX idx_cs ON dbo.EventLog(logid) WHERE logid = -1 AND logid = -2;
Con l'elaborazione batch abilitata, questa soluzione ha impiegato 29 secondi per terminare sul mio sistema, producendo il piano mostrato nella Figura 4.
Conclusione
È naturale che più limitato è il tuo ambiente, più difficile diventa risolvere le attività di query. La sfida speciale delle isole di Adam è molto più facile da risolvere sulle versioni più recenti di SQL Server rispetto a quelle precedenti. Ma poi ti costringi a usare tecniche più creative. Quindi, come esercizio, per migliorare le tue capacità di interrogazione, potresti affrontare sfide con cui hai già familiarità, ma imporre intenzionalmente determinate restrizioni. Non sai mai in quali tipi di idee interessanti potresti imbatterti!