Di recente abbiamo lanciato un nuovo sito di supporto, dove puoi porre domande, inviare feedback sui prodotti o richieste di funzionalità o aprire ticket di supporto. Parte dell'obiettivo era centralizzare tutti i luoghi in cui stavamo offrendo assistenza alla comunità. Ciò includeva il sito di domande e risposte SQLPerformance.com, in cui Paul White, Hugo Kornelis e molti altri hanno contribuito a risolvere le vostre domande più complicate sull'ottimizzazione delle query e sul piano di esecuzione, risalendo fino a febbraio 2013. Vi dico con sentimenti contrastanti che il Il sito di domande e risposte è stato chiuso.
C'è un vantaggio, però. Ora puoi porre queste domande difficili nel nuovo forum di supporto. Se stai cercando il vecchio contenuto, beh, è ancora lì, ma sembra un po' diverso. Per una serie di motivi di cui non parlerò oggi, una volta deciso di disattivare il sito di domande e risposte originale, alla fine abbiamo deciso di ospitare semplicemente tutto il contenuto esistente su un sito WordPress di sola lettura, piuttosto che migrarlo nel back-end del nuovo sito.
Questo post non riguarda i motivi alla base di tale decisione.
Mi sono sentito davvero male per la rapidità con cui il sito delle risposte doveva essere offline, il DNS cambiato e il contenuto migrato. Poiché sul sito è stato implementato un banner di avviso ma AnswerHub non lo ha effettivamente reso visibile, questo è stato uno shock per molti utenti. Quindi volevo assicurarmi di mantenere adeguatamente il maggior numero possibile di contenuti e volevo che fosse giusto. Questo post è qui perché ho pensato che sarebbe stato interessante parlare del processo reale, di quanti diversi pezzi di tecnologia sono stati coinvolti per portarlo a termine e mostrare il risultato. Non mi aspetto che nessuno di voi tragga vantaggio da questo end-to-end, poiché si tratta di un percorso di migrazione relativamente oscuro, ma più come esempio di collegamento di un gruppo di tecnologie per svolgere un'attività. Serve anche come un buon promemoria per me stesso che molte cose non finiscono per essere così facili come sembrano prima di iniziare.
La TL;DR è questo:ho speso un sacco di tempo e sforzi per rendere bello il contenuto archiviato, anche se sto ancora cercando di recuperare gli ultimi post che sono arrivati verso la fine. Ho usato queste tecnologie:
- Perl
- SQL Server
- PowerShell
- Trasmissione (FTP)
- HTML
- CSS
- C#
- MarkdownSharp
- phpMyAdmin
- MySQL
Da qui il titolo. Se vuoi una grossa fetta dei dettagli cruenti, eccoli qui. In caso di domande o feedback, contattaci o commenta di seguito.
AnswerHub ha fornito un file di dump da 665 MB dal database MySQL che ospitava il contenuto di domande e risposte. Ogni editor che ho provato si è soffocato su di esso, quindi ho dovuto prima suddividerlo in un file per tabella usando questo pratico script Perl di Jared Cheney. Le tabelle di cui avevo bisogno erano chiamate network11_nodes (domande, risposte e commenti), network11_authoritables (utenti) e network11_managed_files (tutti gli allegati, inclusi i caricamenti del piano):perl extract_sql.pl -t network11_nodes -r dump.sql>> nodes.sql
perl extract_sql.pl -t network11_authoritables -r dump.sql>> users.sql
perl extract_sql.pl -t network11_file_gestiti -r dump.sql>> files.sql
Ora quelli non erano estremamente veloci da caricare in SSMS, ma almeno lì potevo usare Ctrl +H per cambiare (ad esempio) questo:
CREATE TABLE `network11_managed_files` ( `c_id` bigint(20) NOT NULL, ... ); INSERT INTO `network11_managed_files` (`c_id`, ...) VALUES (1, ...);
A questo:
CREATE TABLE dbo.files ( c_id bigint NOT NULL, ... ); INSERT dbo.files (c_id, ...) VALUES (1, ...);
Quindi potrei caricare i dati in SQL Server in modo da poterli manipolare. E credetemi, l'ho manipolato.
Successivamente, ho dovuto recuperare tutti gli allegati. Vedi, il file di dump MySQL che ho ricevuto dal venditore conteneva un gazillion INSERT dichiarazioni, ma nessuno dei file del piano effettivi che gli utenti avevano caricato:il database aveva solo i percorsi relativi ai file. Ho usato T-SQL per creare una serie di comandi di PowerShell che avrebbero chiamato Invoke-WebRequest per recuperare tutti i file e archiviarli localmente (molti modi per scuoiare questo gatto, ma questo è stato facilissimo). Da questo:
SELECT 'Invoke-WebRequest -Uri ' + '"$($url)' + RTRIM(c_id) + '-' + c_name + '"' + ' -OutFile "E:\s\temp\' + RTRIM(c_id) + '-' + c_name + '";' FROM dbo.files WHERE LOWER(c_mime_type) LIKE 'application/%';
Ciò ha prodotto questo set di comandi (insieme a un pre-comando per risolvere questo problema TLS); il tutto è andato abbastanza rapidamente, ma non consiglio questo approccio per nessuna combinazione di {massiccio set di file} e/o {bassa larghezza di banda}:
$AllProtocols = [System.Net.SecurityProtocolType]'Ssl3,Tls,Tls11,Tls12'; [System.Net.ServicePointManager]::SecurityProtocol = $AllProtocols; $u = "https://answers.sqlperformance.com/s/temp/"; Invoke-WebRequest -Uri "$($u)/1-proc.pesession" -OutFile "E:\s\temp\1-proc.pesession"; Invoke-WebRequest -Uri "$($u)/14-test.pesession" -OutFile "E:\s\temp\14-test.pesession"; Invoke-WebRequest -Uri "$($u)/15-a.QueryAnalysis" -OutFile "E:\s\temp\15-a.QueryAnalysis"; ...
Questo ha scaricato quasi tutti gli allegati ma, è vero, alcuni sono stati persi a causa di errori sul vecchio sito quando sono stati inizialmente caricati. Quindi, nel nuovo sito, potresti occasionalmente vedere un riferimento a un allegato che non esiste.
Poi ho usato Panic Transmit 5 per caricare il temp cartella al nuovo sito e ora, quando il contenuto viene caricato, si collega a /s/temp/1-proc.pesession continuerà a funzionare.
Successivamente, sono passato a SSL. Per richiedere un certificato sul nuovo sito WordPress, abbiamo dovuto aggiornare il DNS per answer.sqlperformance.com per puntare al CNAME sul nostro host WordPress, WPEngine. Era una specie di gallina e uova qui:abbiamo dovuto subire dei tempi di inattività per gli URL https, che non avrebbero funzionato senza alcun certificato sul nuovo sito. Questo andava bene perché il certificato sul vecchio sito era scaduto, quindi davvero, non stavamo peggio. Ho anche dovuto aspettare per farlo fino a quando non avessi scaricato tutti i file dal vecchio sito, perché una volta che il DNS si è capovolto, non ci sarebbe stato modo di accedervi se non attraverso una porta sul retro.
Mentre aspettavo la propagazione del DNS, ho iniziato a lavorare sulla logica per inserire tutte le domande, le risposte e i commenti in qualcosa di consumabile in WordPress. Non solo gli schemi delle tabelle erano diversi da WordPress, ma anche i tipi di entità sono abbastanza diversi. La mia visione era quella di combinare ogni domanda - e qualsiasi risposta e/o commento - in un unico post.
La parte difficile è che la tabella nodes contiene solo tutti e tre i tipi di contenuto nella stessa tabella, con riferimenti padre e padre originale ("master"). Il loro codice front-end probabilmente utilizza una sorta di cursore per scorrere e visualizzare il contenuto in un ordine gerarchico e cronologico. Non avrei quel lusso in WordPress, quindi ho dovuto mettere insieme l'HTML in un colpo solo. A titolo di esempio, ecco come apparivano i dati:
SELECT c_type, c_id, c_parent, oParent = c_originalParent, c_creation_date, c_title FROM dbo.nodes WHERE c_originalParent = 285; /* c_type c_id c_parent oParent c_creation_date accepted c_title ---------- ------ -------- ------- ---------------- -------- ------------------------- question 285 NULL 285 2013-02-13 16:30 why is the MERGE JOIN ... answer 287 285 285 2013-02-14 01:15 1 NULL comment 289 285 285 2013-02-14 13:35 NULL answer 293 285 285 2013-02-14 18:22 NULL comment 294 287 285 2013-02-14 18:29 NULL comment 298 285 285 2013-02-14 20:40 NULL comment 299 298 285 2013-02-14 18:29 NULL */
Non potevo ordinare per ID, tipo o genitore, poiché a volte un commento arrivava in seguito a una risposta precedente, la prima risposta non sarebbe sempre la risposta accettata e così via. Volevo questo output (dove ++ rappresenta un livello di rientro):
/* c_type c_id c_parent oParent c_creation_date reason ---------- ------ -------- ------- ---------------- ------------------------- question 285 NULL 285 2013-02-13 16:30 question is ALWAYS first ++comment 289 285 285 2013-02-14 13:35 comments on the question before answers answer 287 285 285 2013-02-14 01:15 first answer (accepted = 1) ++comment 294 287 285 2013-02-14 18:29 first comment on first answer ++comment 298 287 285 2013-02-14 20:40 second comment on first answer ++++comment 299 298 285 2013-02-14 18:29 reply to second comment on first answer answer 293 285 285 2013-02-14 18:22 second answer */
Ho iniziato a scrivere un CTE ricorsivo e,
DECLARE @foo TABLE
(
c_type varchar(255),
c_id int,
c_parent int,
oParent int,
accepted bit
);
INSERT @foo(c_type, c_id, c_parent, oParent, accepted) VALUES
('question', 285, NULL, 285, 0),
('answer', 287, 285 , 285, 1),
('comment', 289, 285 , 285, 0),
('comment', 294, 287 , 285, 0),
('comment', 298, 287 , 285, 0),
('comment', 299, 298 , 285, 0),
('answer', 293, 285 , 285, 0);
;WITH cte AS
(
SELECT
lvl = 0,
f.c_type,
f.c_id, f.c_parent, f.oParent,
Sort = CONVERT(varchar(255),RIGHT('00000' + CONVERT(varchar(5),f.c_id),5))
FROM @foo AS f WHERE f.c_parent IS NULL
UNION ALL
SELECT
lvl = c.lvl + 1,
c_type = CONVERT(varchar(255), CASE
WHEN f.accepted = 1 THEN 'accepted answer'
WHEN f.c_type = 'comment' THEN c.c_type + ' ' + f.c_type
ELSE f.c_type
END),
f.c_id, f.c_parent, f.oParent,
Sort = CONVERT(varchar(255),c.Sort + RIGHT('00000' + CONVERT(varchar(5),f.c_id),5))
FROM @foo AS f INNER JOIN cte AS c ON c.c_id = f.c_parent
)
SELECT lvl = CASE lvl WHEN 0 THEN 1 ELSE lvl END, c_type, c_id, c_parent, oParent, Sort
FROM cte
ORDER BY
oParent,
CASE
WHEN c_type LIKE 'question%' THEN 1 -- it's a question *or* a comment on the question
WHEN c_type LIKE 'accepted answer%' THEN 2 -- accepted answer *or* comment on accepted answer
ELSE 3 END,
Sort; Risultati:
/* lvl c_type c_id c_parent oParent Sort ---- --------------------------------- ----------- ----------- ----------- -------------------- 1 question 285 NULL 285 00285 1 question comment 289 285 285 0028500289 1 accepted answer 287 285 285 0028500287 2 accepted answer comment 294 287 285 002850028700294 2 accepted answer comment 298 287 285 002850028700298 3 accepted answer comment comment 299 298 285 00285002870029800299 1 answer 293 285 285 0028500293 */
Genio. Ne ho controllati una dozzina o giù di lì ed ero felice di passare al passaggio successivo. Ho ringraziato abbondantemente Andy, diverse volte, ma lascia che lo ripeta:Grazie Andy!
Ora che potevo restituire l'intero set nell'ordine che mi piaceva, dovevo eseguire alcune manipolazioni dell'output per applicare elementi HTML e nomi di classi che mi consentissero di contrassegnare domande, risposte, commenti e rientri in modo significativo. L'obiettivo finale era un output simile a questo (e tieni presente che questo è uno dei casi più semplici):
<div class="question">
<span class="authorq" title=" Author : author name ">
<i class="fas fa-user"></i>Author name</span>
<span class="createdq" title=" February 13th, 2013 ">
<i class="fas fa-calendar-alt"></i>2013-02-13 16:30:36</span>
<div class=mainbodyq>I don't understand why the merge operator is passing over 4million
rows to the hash match operator when there is only 41K and 19K from other operators.
<div class=attach><i class="fas fa-file"></i>
<a target="_blank" href="/s/temp/254-tmp4DA0.queryanalysis" rel="noopener noreferrer">
/s/temp/254-tmp4DA0.queryanalysis</a>
</div>
</div>
<div class="comment indent1 ">
<div class=linecomment>
<span class="authorc" title=" Author : author name ">
<i class="fas fa-user"></i>author name</span>
<span class="createdc" title=" February 14th, 2013 ">
<i class="fas fa-calendar-alt"></i>2013-02-14 13:35:39</span>
</div>
<div class=mainbodyc>
I am still trying to understand the significant amount of rows from the MERGE operator.
Unless it's a result of a Cartesian product from the two inputs then finally the WHERE
predicate is applied to filter out the unmatched rows leaving the 4 million row count.
</div>
</div>
<div class="answer indent1 [accepted]">
<div class=lineanswer>
<span class="authora" title=" Author : author name ">
<i class="fas fa-user"></i>author name</span>
<span class="createda" title=" February 14th, 2013 ">
<i class="fas fa-calendar-alt"></i>2013-02-14 01:15:42</span>
</div>
<div class=mainbodya>
The reason for the large number of rows can be seen in the Plan Explorer tool tip for
the Merge Join operator:
<img src="/s/temp/259-sp.png" alt="Merge Join tool tip" />
...
</div>
</div>
</div>
Non passerò attraverso il numero ridicolo di iterazioni che ho dovuto affrontare per atterrare su una forma affidabile di quell'output per tutti gli oltre 5.000 elementi (che si sono tradotti in quasi 1.000 post una volta che tutto è stato incollato insieme). Inoltre, dovevo generarli sotto forma di INSERT affermazioni che potevo quindi incollare in phpMyAdmin sul sito WordPress, il che significava aderire al loro bizzarro diagramma di sintassi. Tali dichiarazioni dovevano includere altre informazioni aggiuntive richieste da WordPress, ma non presenti o accurate nei dati di origine (come post_type ). E quella console di amministrazione sarebbe scaduta a causa di troppi dati, quindi ho dovuto suddividerli in ~ 750 inserti alla volta. Ecco la procedura con cui sono finito (questo non è proprio per imparare nulla di specifico, solo una dimostrazione di quanta manipolazione dei dati importati fosse necessaria):
CREATE /* OR ALTER */ PROCEDURE dbo.BuildMySQLInserts
@LowerBound int = 1,
@UpperBound int = 750
AS
BEGIN
SET NOCOUNT ON;
;WITH CTE AS
(
SELECT lvl = 0,
[type] = CONVERT(varchar(100),f.[type]),
f.id,
f.parent,
f.master_parent,
created = CONVERT(char(10), f.created, 120) + ' '
+ CONVERT(char(8), f.created, 108),
f.state,
Sort = CONVERT(varchar(100),RIGHT('0000000000'
+ CONVERT(varchar(10),f.id),10))
FROM dbo.foo AS f
WHERE f.type = 'question'
AND master_parent BETWEEN @LowerBound AND @UpperBound
UNION ALL
SELECT lvl = c.lvl + 1,
CONVERT(varchar(100),CASE
WHEN f.[state] = '[accepted]' THEN 'accepted answer'
WHEN f.type = 'comment' THEN c.type + ' ' + f.type
ELSE f.type
END),
f.id,
f.parent,
f.master_parent,
created = CONVERT(char(10), f.created, 120) + ' '
+ CONVERT(char(8), f.created, 108),
f.state,
Sort = CONVERT(varchar(100),c.sort + RIGHT('0000000000'
+ CONVERT(varchar(10),f.id),10))
FROM dbo.foo AS f
JOIN CTE AS c ON c.id = f.parent
)
SELECT
master_parent,
prefix = CASE WHEN lvl = 0 THEN
CONVERT(varchar(11), master_parent) + ', 3, ''' + created + ''', '''
+ created + ''',''' END,
bodypre = '<div class="' + COALESCE(c_type, RTRIM(LEFT([type],8)))
+ CASE WHEN c_type <> 'question' THEN ' indent' + RTRIM(lvl)
+ COALESCE(' ' + [state], '') ELSE '' END + '">'
+ CASE WHEN c_type <> 'question' THEN
'<div class=line' + c_type + '>' ELSE '' END
+ '<span class="author' + LEFT(c_type, 1) + '" title=" Author : '
+ REPLACE(REPLACE(Fullname,'''','\'''),'"','')
+ ' "><i class="fas fa-user"></i>' + REPLACE(Fullname,'''','\''') --"
+ '</span> <span class="created' + LEFT(c_type,1) + '" title=" '
+ DATENAME(MONTH, c_creation_date) + ' ' + RTRIM(DAY(c_creation_date))
+ CASE
WHEN DAY(c_creation_date) IN (1,21,31) THEN 'st'
WHEN DAY(c_creation_date) IN (2,22) THEN 'nd'
WHEN DAY(c_creation_date) IN (3,23) THEN 'rd' ELSE 'th' END
+ ', ' + RTRIM(YEAR(c_creation_date))
+ ' "><i class="fas fa-calendar-alt"></i>' + created + '</span>'
+ CASE WHEN c_type <> 'question' THEN '</div>' ELSE '' END,
body = '<div class=mainbody' + left(c_type,1) + '>'
+ REPLACE(REPLACE(c_body, char(39), '\' + char(39)), '’', '\' + char(39)),
bodypost = COALESCE(urls, '') + '</div></div>',--'
+ CASE WHEN c_type = 'question' THEN '</div>' ELSE '' END,
suffix = ''',''' + REPLACE(n.c_title, '''', '\''') + ''','''',''publish'',
''closed'',''closed'','''',''' + REPLACE(n.c_plug, '''', '\''')
+ ''','''','''',''' + created + ''',''' + created + ''','''',0,
''https://answers.sqlperformance.com/?p=' + CONVERT(varchar(11), master_parent)
+ ''', 0, ''post'','''',0);',
rn = RTRIM(ROW_NUMBER() OVER (PARTITION BY master_parent
ORDER BY master_parent,
CASE
WHEN [type] LIKE 'question%' THEN 1
WHEN [type] LIKE 'accepted answer%' THEN 2
ELSE 3
END,
Sort)),
c = RTRIM(COUNT(*) OVER (PARTITION BY master_parent))
FROM CTE
LEFT OUTER JOIN dbo.network11_nodes AS n
ON cte.id = n.c_id
LEFT OUTER JOIN dbo.Users AS u
ON n.c_author = u.UserID
LEFT OUTER JOIN
(
SELECT NodeID, urls = STRING_AGG('<div class=attach>
<i class="fas fa-file'
+ CASE WHEN c_mime_type IN ('image/jpeg','image/png')
THEN '-image' ELSE '' END
+ '"></i><a target="_blank" href=' + url + ' rel="noopener noreferrer">' + url + '</a></div>', '\n')
FROM dbo.Attachments
GROUP BY NodeID
) AS a
ON n.c_id = a.NodeID
ORDER BY master_parent,
CASE
WHEN [type] LIKE 'question%' THEN 1
WHEN [type] LIKE 'accepted answer%' THEN 2
ELSE 3
END,
Sort;
END
GO L'output non è completo e non è ancora pronto per essere inserito in WordPress:
 Output di esempio (fai clic per ingrandire)
Output di esempio (fai clic per ingrandire)
Avrei bisogno di ulteriore aiuto da C# per trasformare il contenuto effettivo (incluso il markdown) in HTML e CSS che potrei controllare meglio e scrivere l'output (un mucchio di INSERT istruzioni che includevano un mucchio di codice HTML) ai file sul disco che potevo aprire e incollare in phpMyAdmin. Per l'HTML, testo normale + markdown iniziato in questo modo:
SELEZIONA qualcosa da dbo.sometable;
[1]:https://altrove
Dovrebbe diventare questo:
C'è un post del blog qui che ne parla, e anche questo post .
SELEZIONARE qualcosa da dbo.sometable; Per ottenere questo risultato, ho chiesto l'aiuto di MarkdownSharp, una libreria open source originata da Stack Overflow che gestisce gran parte della conversione da markdown a HTML. Era adatto alle mie esigenze, ma non perfetto; Dovrei comunque eseguire ulteriori manipolazioni:
- MarkdownSharp non consente cose come
target=_blank, quindi dovrei iniettarli io stesso dopo l'elaborazione; - il codice (qualsiasi cosa preceduta da quattro spazi) eredita i wrapper
using System.Text; using System.Data; using System.Data.SqlClient; using MarkdownSharp; using System.IO; namespace AnswerHubMigrator { class Program { static void Main(string[] args) { StringBuilder output; string suffix = ""; string thisfile = ""; // pass two arguments on the command line, e.g. 1, 750 int LowerBound = int.Parse(args[0]); int UpperBound = int.Parse(args[1]); // auto-expand URLs, and only accept bold/italic markdown // when it completely surrounds an entire word var options = new MarkdownOptions { AutoHyperlink = true, StrictBoldItalic = true }; MarkdownSharp.Markdown mark = new MarkdownSharp.Markdown(options); using (var conn = new SqlConnection("Server=.\\SQL2017;Integrated Security=true")) using (var cmd = new SqlCommand("MigrateDB.dbo.BuildMySQLInserts", conn)) { cmd.CommandType = CommandType.StoredProcedure; cmd.Parameters.Add("@LowerBound", SqlDbType.Int).Value = LowerBound; cmd.Parameters.Add("@UpperBound", SqlDbType.Int).Value = UpperBound; conn.Open(); using (var reader = cmd.ExecuteReader()) { // use a StringBuilder to dump output to a file output = new StringBuilder(); while (reader.Read()) { // on first pass, make a new delete/insert // delete is to make the commands idempotent if (reader["rn"].Equals("1")) { // for each master parent, I would create a // new WordPress post, inheriting the parent ID output.Append("DELETE FROM `wp_posts` WHERE ID = "); output.Append(reader["master_parent"].ToString()); output.Append("; INSERT INTO `wp_posts` (`ID`, `post_author`, "); output.Append("`post_date`, `post_date_gmt`, `post_content`, "); output.Append("`post_title`, `post_excerpt`, `post_status`, "); output.Append("`comment_status`, `ping_status`, `post_password`,"); output.Append(" `post_name`, `to_ping`, `pinged`, `post_modified`,"); output.Append(" `post_modified_gmt`, `post_content_filtered`, "); output.Append("`post_parent`, `guid`, `menu_order`, `post_type`, "); output.Append("`post_mime_type`, `comment_count`) VALUES ("); // I'm sure some of the above columns are optional, but identifying // those would not be a valuable use of time IMHO output.Append(reader["prefix"]); // hold on to the additional values until last row suffix = reader["suffix"].ToString(); } // manipulate the body content to be WordPress and INSERT statement-friendly string body = reader["body"].ToString().Replace(@"\n", "\n"); body = mark.Transform(body).Replace("href=", "target=_blank href="); body = body.Replace("<p>", "").Replace("</p>", ""); body = body.Replace("<pre><code>", "<pre lang=\"tsql\">"); body = body.Replace("</code></"+"pre>", "</"+"pre>"); body = body.Replace(@"'", "\'").Replace(@"’", "\'"); body = reader["bodypre"].ToString() + body.Replace("\n", @"\n"); body += reader["bodypost"].ToString(); body = body.Replace("<", "<").Replace(">", ">"); output.Append(body); // if we are on the last row, add additional values from the first row if (reader["c"].Equals(reader["rn"])) { output.Append(suffix); } } thisfile = UpperBound.ToString(); using (StreamWriter w = new StreamWriter(@"C:\wp\" + thisfile + ".sql")) { w.WriteLine(output); w.Flush(); } } } } } }Sì, è un brutto mucchio di codice, ma alla fine mi ha portato al set di output che non farebbe vomitare phpMyAdmin e che WordPress si presenterebbe bene (abbastanza). Ho semplicemente chiamato il programma C# più volte con i diversi intervalli di parametri:
AnswerHubMigrator 1 750 AnswerHubMigrator 751 1500 AnswerHubMigrator 1501 2250 ...
Quindi ho aperto ciascuno dei file, li ho incollati in phpMyAdmin e ho premuto VAI:
 phpMyAdmin (clicca per ingrandire)
phpMyAdmin (clicca per ingrandire) Ovviamente ho dovuto aggiungere alcuni CSS all'interno di WordPress per aiutare a distinguere tra domande, commenti e risposte, e anche indentare i commenti per mostrare le risposte sia alle domande che alle risposte, annidare i commenti che rispondono ai commenti e così via. Ecco come appare un estratto quando approfondisci le domande di un mese:
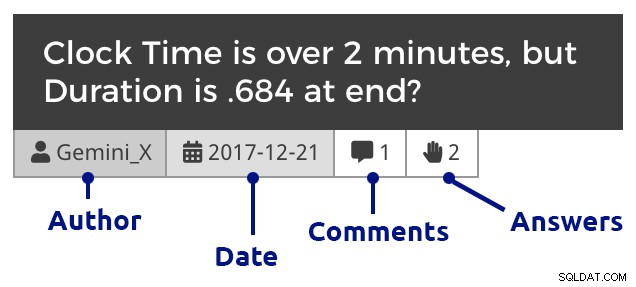 Riquadro domanda (fai clic per ingrandire)
Riquadro domanda (fai clic per ingrandire) E poi un post di esempio, che mostra immagini incorporate, allegati multipli, commenti nidificati e una risposta:
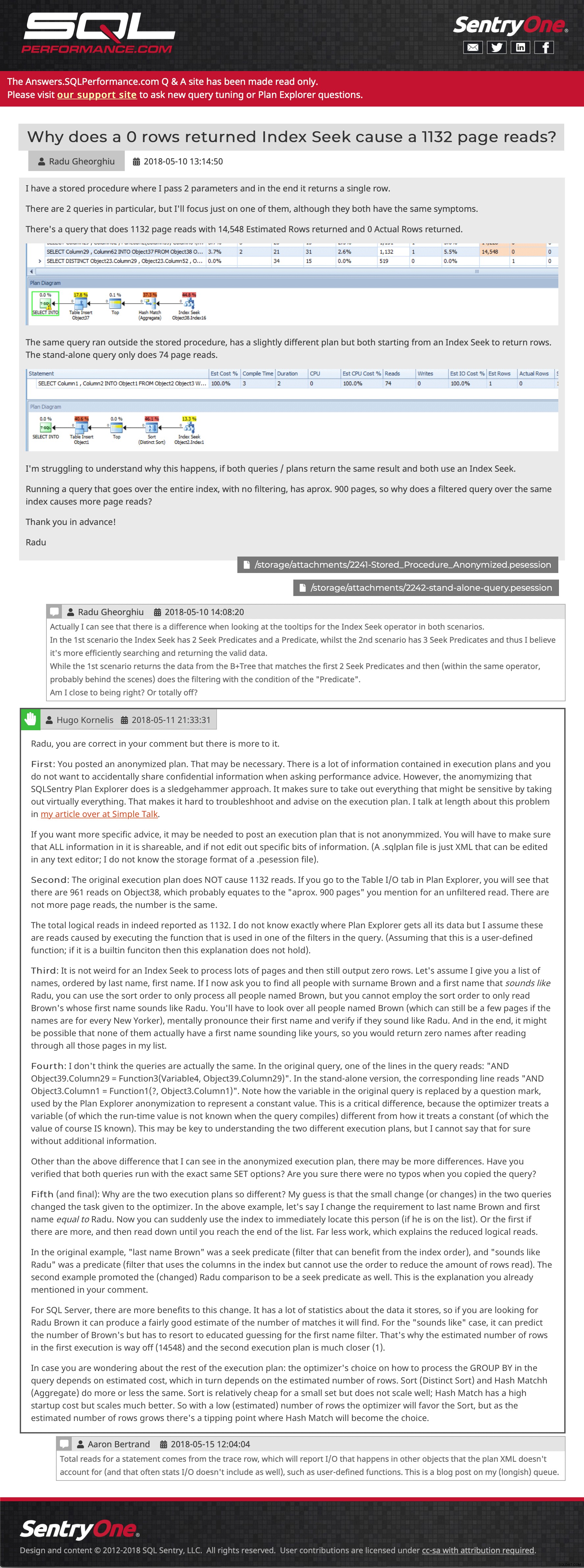 Domanda e risposta di esempio (fai clic per andare lì)
Domanda e risposta di esempio (fai clic per andare lì) Sto ancora cercando di recuperare alcuni post che sono stati inviati al sito dopo che è stato eseguito l'ultimo backup, ma ti invito a navigare. Facci sapere se trovi qualcosa mancante o fuori posto, o anche solo per dirci che il contenuto è ancora utile per te. Ci auguriamo di reintrodurre la funzionalità di caricamento del piano da Plan Explorer, ma richiederà un po' di lavoro API sul nuovo sito di supporto, quindi oggi non ho un ETA per te.
- Answers.SQLPerformance.com