L'esecuzione di database sull'infrastruttura cloud sta diventando sempre più popolare in questi giorni. Sebbene una VM cloud possa non essere affidabile come un server di livello aziendale, i principali provider di servizi cloud offrono una varietà di strumenti per aumentare la disponibilità del servizio. In questo post del blog, ti mostreremo come architettare il tuo database MySQL o MariaDB per un'elevata disponibilità, nel cloud. Esamineremo in particolare Amazon Web Services e Google Cloud Platform, ma la maggior parte dei suggerimenti può essere utilizzata anche con altri fornitori di servizi cloud.
Sia AWS che Google offrono servizi di database sui loro cloud e questi servizi possono essere configurati per l'alta disponibilità. È possibile avere copie in diverse zone di disponibilità (o zone in GCP), per aumentare le tue possibilità di sopravvivere a un guasto parziale dei servizi all'interno di una regione. Sebbene un servizio ospitato sia un modo molto conveniente per eseguire un database, tieni presente che il servizio è progettato per comportarsi in un modo specifico e che potrebbe o meno soddisfare le tue esigenze. Quindi, ad esempio, AWS RDS per MySQL ha un elenco piuttosto limitato di opzioni quando si tratta di gestione del failover. Le distribuzioni Multi-AZ hanno un tempo di failover di 60-120 secondi come da documentazione. In effetti, dato che l'istanza MySQL "ombra" deve partire da un set di dati "corrotto", ciò potrebbe richiedere ancora più tempo poiché potrebbe essere necessario più lavoro sull'applicazione o il rollback delle transazioni dai registri di ripristino di InnoDB. Esiste un'opzione per promuovere uno schiavo a diventare un padrone, ma non è fattibile in quanto non è possibile riattivare gli schiavi esistenti dal nuovo padrone. Nel caso di un servizio gestito, è anche intrinsecamente più complesso e più difficile rintracciare i problemi di prestazioni. Ulteriori approfondimenti su RDS per MySQL e le sue limitazioni in questo post del blog.
Se invece decidi di gestire i database, ti trovi in un mondo di possibilità diverso. Un certo numero di cose che puoi fare su bare metal sono possibili anche su istanze EC2 o Compute Engine. Non hai il sovraccarico della gestione dell'hardware sottostante e mantieni il controllo su come progettare il sistema. Esistono due opzioni principali durante la progettazione per la disponibilità di MySQL:la replica di MySQL e il cluster Galera. Discutiamoli.
Replica MySQL
La replica di MySQL è un modo comune per ridimensionare MySQL con più copie dei dati. Asincrono o semi-sincrono, consente di propagare le modifiche eseguite su un singolo writer, il master, a repliche/slave, ognuna delle quali conterrebbe l'intero set di dati e può essere promossa a nuovo master. La replica può essere utilizzata anche per ridimensionare le letture, indirizzando il traffico di lettura alle repliche e scaricando il master in questo modo. Il principale vantaggio della replica è la facilità d'uso:è così ampiamente conosciuto e popolare (è anche facile da configurare) che ci sono numerose risorse e strumenti per aiutarti a gestirlo e configurarlo. Il nostro ClusterControl è uno di questi:puoi usarlo per distribuire facilmente una configurazione di replica MySQL con bilanciatori di carico integrati, gestire le modifiche alla topologia, il failover/ripristino e così via.
Uno dei problemi principali con la replica di MySQL è che non è progettata per gestire le divisioni di rete o gli errori del master. Se un master va giù, devi promuovere una delle repliche. Si tratta di un processo manuale, sebbene possa essere automatizzato con strumenti esterni (es. ClusterControl). Inoltre, non esiste un meccanismo di quorum e non esiste supporto per il fencing delle istanze master non riuscite nella replica di MySQL. Sfortunatamente, questo può portare a seri problemi negli ambienti distribuiti:se hai promosso un nuovo master mentre quello vecchio torna online, potresti finire per scrivere su due nodi, creando deriva dei dati e causando seri problemi di coerenza dei dati.
Esamineremo alcuni esempi più avanti in questo post, che ti mostrano come rilevare le divisioni di rete e implementare STONITH o qualche altro meccanismo di scherma per la configurazione della tua replica MySQL.
Ammasso Galleria
Abbiamo visto nella sezione precedente che la replica di MySQL manca di fencing e supporto del quorum:è qui che Galera Cluster brilla. Ha un supporto quorum integrato, ha anche un meccanismo di fencing che impedisce ai nodi partizionati di accettare scritture. Ciò rende Galera Cluster più adatto della replica in configurazioni multi-datacenter. Galera Cluster supporta anche più writer ed è in grado di risolvere i conflitti di scrittura. Non sei quindi limitato a un singolo writer in una configurazione multi-data center, è possibile avere un writer in ogni data center che riduce la latenza tra la tua applicazione e il livello di database. Non accelera le scritture poiché ogni scrittura deve ancora essere inviata a ogni nodo Galera per la certificazione, ma è comunque più semplice che inviare le scritture da tutti i server delle applicazioni attraverso WAN a un singolo master remoto.
Per quanto sia buono Galera, non è sempre la scelta migliore per tutti i carichi di lavoro. Galera non è un sostituto drop-in per MySQL/InnoDB. Condivide caratteristiche comuni con MySQL "normale": usa InnoDB come motore di archiviazione, contiene l'intero set di dati su ogni nodo, il che rende fattibili i JOIN. Tuttavia, alcune delle caratteristiche prestazionali di Galera (come le prestazioni delle scritture influenzate dalla latenza di rete) differiscono da quelle che ti aspetteresti dalle configurazioni di replica. Anche la manutenzione ha un aspetto diverso:la gestione delle modifiche allo schema funziona in modo leggermente diverso. Alcune progettazioni di schemi non sono ottimali:se nelle tabelle sono presenti hotspot, ad esempio contatori aggiornati di frequente, ciò potrebbe causare problemi di prestazioni. C'è anche una differenza nelle migliori pratiche relative all'elaborazione batch:invece di eseguire query in transazioni di grandi dimensioni, desideri che le tue transazioni siano piccole.
Livello proxy
È molto difficile e ingombrante creare una configurazione ad alta disponibilità senza proxy. Certo, puoi scrivere codice nella tua applicazione per tenere traccia delle istanze del database, inserire nella blacklist quelle malsane, tenere traccia dei master scrivibili e così via. Ma questo è molto più complesso del semplice invio di traffico a un singolo endpoint, ed è qui che entra in gioco un proxy. ClusterControl consente di distribuire ProxySQL, HAProxy e MaxScale. Forniremo alcuni esempi utilizzando ProxySQL, poiché ci offre una buona flessibilità nel controllo del traffico del database.
ProxySQL può essere distribuito in un paio di modi. Per cominciare, può essere distribuito su host separati e Keepalived può essere utilizzato per fornire IP virtuale. L'IP virtuale verrà spostato in caso di errore di una delle istanze ProxySQL. Nel cloud, questa configurazione può essere problematica poiché l'aggiunta di un IP all'interfaccia di solito non è sufficiente. Dovresti modificare la configurazione e gli script di Keepalived per funzionare con IP elastico (o statico, tuttavia potrebbe essere chiamato dal tuo provider cloud). Quindi si utilizzerà l'API cloud o la CLI per trasferire questo indirizzo IP su un altro host. Per questo motivo, suggeriamo di collocare ProxySQL con l'applicazione. Ciascun server delle applicazioni verrebbe configurato per connettersi al ProxySQL locale, utilizzando i socket Unix. Poiché ProxySQL utilizza un processo angelo, gli arresti anomali di ProxySQL possono essere rilevati/riavviati entro un secondo. In caso di arresto anomalo dell'hardware, quel particolare server delle applicazioni si interromperà insieme a ProxySQL. I restanti server delle applicazioni possono comunque accedere alle rispettive istanze ProxySQL locali. Questa particolare configurazione ha funzionalità aggiuntive. Sicurezza - ProxySQL, a partire dalla versione 1.4.8, non supporta SSL lato client. Può solo configurare la connessione SSL tra ProxySQL e il back-end. Collocare ProxySQL sull'host dell'applicazione e utilizzare i socket Unix è una buona soluzione. ProxySQL ha anche la capacità di memorizzare nella cache le query e se si intende utilizzare questa funzionalità, è opportuno mantenerla il più vicino possibile all'applicazione per ridurre la latenza. Suggeriamo di utilizzare questo modello per distribuire ProxySQL.
Impostazioni tipiche
Diamo un'occhiata ad esempi di configurazioni ad alta disponibilità.
Centro unico, replica MySQL
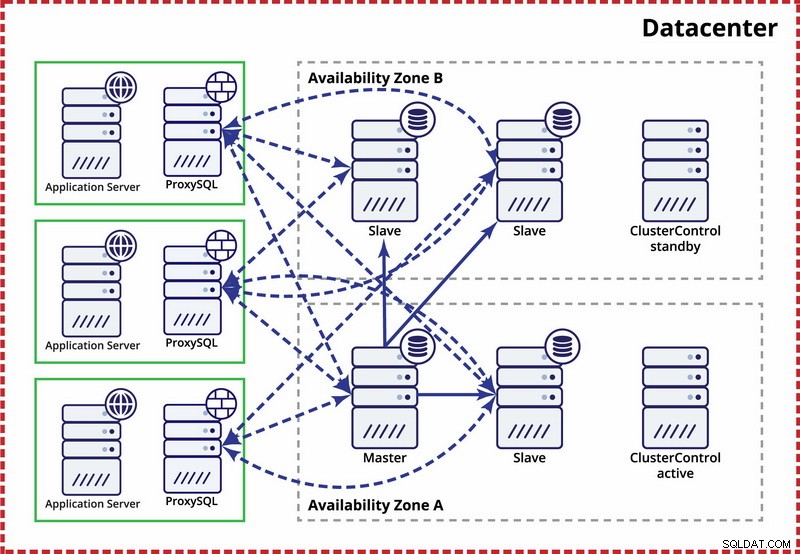
Il presupposto qui è che ci siano due zone separate all'interno del datacenter. Ogni zona dispone di alimentazione, rete e connettività ridondanti e separate per ridurre la probabilità che due zone si guastino contemporaneamente. È possibile impostare una topologia di replica su entrambe le zone.
Qui utilizziamo ClusterControl per gestire il failover. Per risolvere lo scenario split-brain tra zone di disponibilità, collochiamo il ClusterControl attivo con il master. Inoltre, inseriamo nella lista nera gli slave nell'altra zona di disponibilità per assicurarci che il failover automatico non renda disponibili due master.
Più data center, replica MySQL
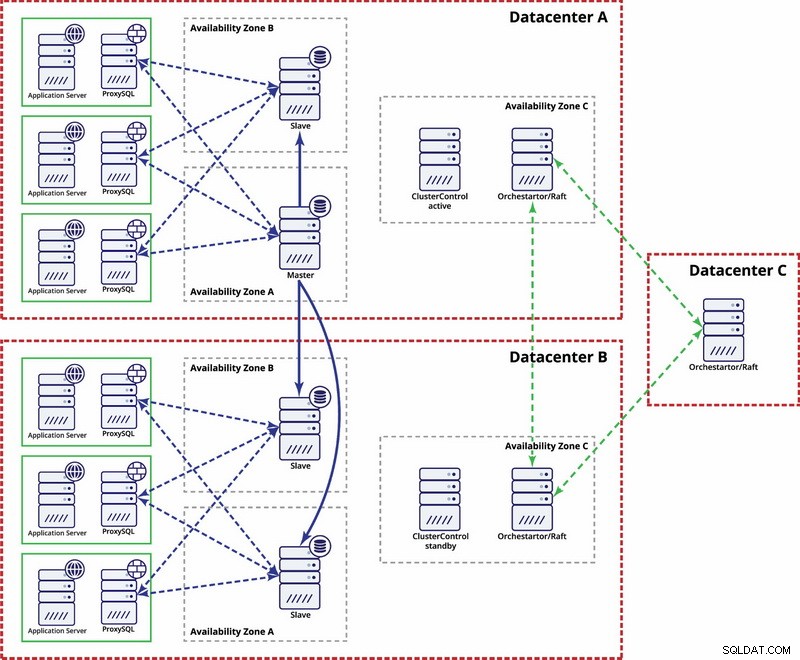
In questo esempio utilizziamo tre datacenter e Orchestrator/Raft per il calcolo del quorum. Potrebbe essere necessario scrivere i propri script per implementare STONITH se il master si trova nel segmento partizionato dell'infrastruttura. ClusterControl viene utilizzato per le funzioni di gestione e ripristino dei nodi.
Più datacenter, Cluster Galera
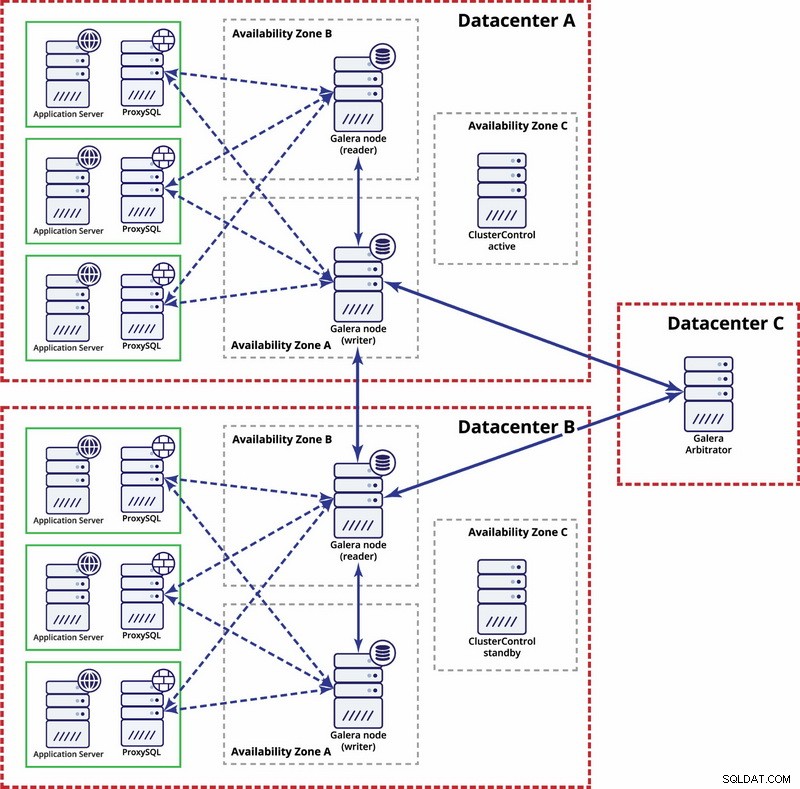
In questo caso utilizziamo tre datacenter con un arbitro Galera nel terzo:ciò rende possibile gestire il guasto dell'intero datacenter e riduce il rischio di partizionamento della rete poiché il terzo datacenter può essere utilizzato come relay.
Per ulteriori letture, dai un'occhiata al whitepaper "Come progettare ambienti di database open source ad alta disponibilità" e guarda la replica del webinar "Progettazione di database open source per un'elevata disponibilità".



