È quel martedì del mese, sai, quello in cui si tiene il block party dei blogger noto come T-SQL Tuesday. Questo mese è ospitato da Russ Thomas (@SQLJudo) e l'argomento è "Calling All Tuners and Gear Heads". Tratterò qui un problema relativo alle prestazioni, anche se mi scuso per il fatto che potrebbe non essere completamente in linea con le linee guida che Russ ha stabilito nel suo invito (non userò suggerimenti, tracce di flag o guide di pianificazione) .
A SQLBits la scorsa settimana, ho tenuto una presentazione sui trigger e il mio buon amico e collega MVP Erland Sommarskog ha partecipato. A un certo punto ho suggerito che prima di creare un nuovo trigger su una tabella, dovresti verificare se esistono già trigger e considerare di combinare la logica invece di aggiungere un trigger aggiuntivo. Le mie ragioni erano principalmente per la manutenibilità del codice, ma anche per le prestazioni. Erland ha chiesto se avessi mai testato per vedere se c'era un sovraccarico aggiuntivo nell'avere più trigger sparati per la stessa azione, e ho dovuto ammettere che, no, non avevo fatto nulla di esteso. Quindi lo farò ora.
In AdventureWorks2014, ho creato un semplice insieme di tabelle che sostanzialmente rappresentano sys.all_objects (~2.700 righe) e sys.all_columns (~9.500 righe). Volevo misurare l'effetto sul carico di lavoro di vari approcci all'aggiornamento di entrambe le tabelle:in pratica hai utenti che aggiornano la tabella delle colonne e usi un trigger per aggiornare una colonna diversa nella stessa tabella e alcune colonne nella tabella degli oggetti.
- T1:riferimento :si supponga di poter controllare tutti gli accessi ai dati tramite una procedura memorizzata; in questo caso, gli aggiornamenti su entrambe le tabelle possono essere eseguiti direttamente, senza necessità di trigger. (Questo non è pratico nel mondo reale, perché non puoi vietare in modo affidabile l'accesso diretto ai tavoli.)
- T2:Singolo trigger contro un altro tavolo :si supponga di poter controllare l'istruzione di aggiornamento rispetto alla tabella interessata e aggiungere altre colonne, ma gli aggiornamenti alla tabella secondaria devono essere implementati con un trigger. Aggiorneremo tutte e tre le colonne con un'unica istruzione.
- T3:Singolo trigger contro entrambi i tavoli :in questo caso, abbiamo un trigger con due istruzioni, una che aggiorna l'altra colonna nella tabella interessata e una che aggiorna tutte e tre le colonne nella tabella secondaria.
- T4:Singolo trigger contro entrambi i tavoli :come T3, ma questa volta abbiamo un trigger con quattro istruzioni, una che aggiorna l'altra colonna nella tabella interessata e un'istruzione per ogni colonna aggiornata nella tabella secondaria. Questo potrebbe essere il modo in cui viene gestito se i requisiti vengono aggiunti nel tempo e una dichiarazione separata viene considerata più sicura in termini di test di regressione.
- T5:due trigger :un trigger aggiorna solo la tabella interessata; l'altro usa una singola istruzione per aggiornare le tre colonne nella tabella secondaria. Questo potrebbe essere il modo in cui si fa se gli altri trigger non vengono notati o se è vietato modificarli.
- T6:Quattro trigger :un trigger aggiorna solo la tabella interessata; gli altri tre aggiornano ogni colonna nella tabella secondaria. Anche in questo caso, potrebbe essere così se non sai che esistono altri trigger o se hai paura di toccare gli altri trigger a causa di problemi di regressione.
Ecco i dati di origine con cui abbiamo a che fare:
-- sys.all_objects: SELECT * INTO dbo.src FROM sys.all_objects; CREATE UNIQUE CLUSTERED INDEX x ON dbo.src([object_id]); GO -- sys.all_columns: SELECT * INTO dbo.tr1 FROM sys.all_columns; CREATE UNIQUE CLUSTERED INDEX x ON dbo.tr1([object_id], column_id); -- repeat 5 times: tr2, tr3, tr4, tr5, tr6
Ora, per ciascuno dei 6 test, eseguiremo i nostri aggiornamenti 1000 volte e misureremo la durata
T1:riferimento
Questo è lo scenario in cui siamo abbastanza fortunati da evitare i trigger (di nuovo, non molto realistico). In questo caso, misureremo le letture e la durata di questo batch. Metto /*real*/ nel testo della query in modo che io possa facilmente estrarre le statistiche solo per queste istruzioni e non per qualsiasi istruzione dall'interno dei trigger, poiché alla fine le metriche si accumulano nelle istruzioni che invocano i trigger. Tieni inoltre presente che gli aggiornamenti effettivi che sto apportando non hanno alcun senso, quindi ignora che sto impostando le regole di confronto sul nome del server/istanza e del principal_id dell'oggetto al session_id della sessione corrente .
UPDATE /*real*/ dbo.tr1 SET name += N'', collation_name = @@SERVERNAME WHERE name LIKE '%s%'; UPDATE /*real*/ s SET modify_date = GETDATE(), is_ms_shipped = 0, principal_id = @@SPID FROM dbo.src AS s INNER JOIN dbo.tr1 AS t ON s.[object_id] = t.[object_id] WHERE t.name LIKE '%s%'; GO 1000
T2:trigger singolo
Per questo abbiamo bisogno del seguente semplice trigger, che aggiorna solo dbo.src :
CREATE TRIGGER dbo.tr_tr2
ON dbo.tr2
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE s SET modify_date = GETDATE(), is_ms_shipped = 0, principal_id = SUSER_ID()
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
END
GO Quindi il nostro batch deve solo aggiornare le due colonne nella tabella principale:
UPDATE /*real*/ dbo.tr2 SET name += N'', collation_name = @@SERVERNAME WHERE name LIKE '%s%'; GO 1000
T3:Singolo trigger contro entrambi i tavoli
Per questo test, il nostro trigger si presenta così:
CREATE TRIGGER dbo.tr_tr3
ON dbo.tr3
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE t SET collation_name = @@SERVERNAME
FROM dbo.tr3 AS t
INNER JOIN inserted AS i
ON t.[object_id] = i.[object_id];
UPDATE s SET modify_date = GETDATE(), is_ms_shipped = 0, principal_id = @@SPID
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
END
GO E ora il batch che stiamo testando deve semplicemente aggiornare la colonna originale nella tabella principale; l'altro è gestito dal trigger:
UPDATE /*real*/ dbo.tr3 SET name += N'' WHERE name LIKE '%s%'; GO 1000
T4:Attivazione singola contro entrambi i tavoli
È proprio come T3, ma ora il trigger ha quattro istruzioni:
CREATE TRIGGER dbo.tr_tr4
ON dbo.tr4
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE t SET collation_name = @@SERVERNAME
FROM dbo.tr4 AS t
INNER JOIN inserted AS i
ON t.[object_id] = i.[object_id];
UPDATE s SET modify_date = GETDATE()
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
UPDATE s SET is_ms_shipped = 0
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
UPDATE s SET principal_id = @@SPID
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
END
GO Il lotto di prova è invariato:
UPDATE /*real*/ dbo.tr4 SET name += N'' WHERE name LIKE '%s%'; GO 1000
T5:due trigger
Qui abbiamo un trigger per aggiornare la tabella primaria e un trigger per aggiornare la tabella secondaria:
CREATE TRIGGER dbo.tr_tr5_1
ON dbo.tr5
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE t SET collation_name = @@SERVERNAME
FROM dbo.tr5 AS t
INNER JOIN inserted AS i
ON t.[object_id] = i.[object_id];
END
GO
CREATE TRIGGER dbo.tr_tr5_2
ON dbo.tr5
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE s SET modify_date = GETDATE(), is_ms_shipped = 0, principal_id = @@SPID
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
END
GO Il lotto di prova è ancora una volta molto semplice:
UPDATE /*real*/ dbo.tr5 SET name += N'' WHERE name LIKE '%s%'; GO 1000
T6:Quattro trigger
Questa volta abbiamo un trigger per ogni colonna interessata; uno nella tabella principale e tre nelle tabelle secondarie.
CREATE TRIGGER dbo.tr_tr6_1
ON dbo.tr6
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE t SET collation_name = @@SERVERNAME
FROM dbo.tr6 AS t
INNER JOIN inserted AS i
ON t.[object_id] = i.[object_id];
END
GO
CREATE TRIGGER dbo.tr_tr6_2
ON dbo.tr6
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE s SET modify_date = GETDATE()
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
END
GO
CREATE TRIGGER dbo.tr_tr6_3
ON dbo.tr6
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE s SET is_ms_shipped = 0
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
END
GO
CREATE TRIGGER dbo.tr_tr6_4
ON dbo.tr6
AFTER UPDATE
AS
BEGIN
SET NOCOUNT ON;
UPDATE s SET principal_id = @@SPID
FROM dbo.src AS s
INNER JOIN inserted AS i
ON s.[object_id] = i.[object_id];
END
GO E il lotto di prova:
UPDATE /*real*/ dbo.tr6 SET name += N'' WHERE name LIKE '%s%'; GO 1000
Misurare l'impatto del carico di lavoro
Infine, ho scritto una semplice query su sys.dm_exec_query_stats per misurare le letture e la durata di ogni test:
SELECT [cmd] = SUBSTRING(t.text, CHARINDEX(N'U', t.text), 23), avg_elapsed_time = total_elapsed_time / execution_count * 1.0, total_logical_reads FROM sys.dm_exec_query_stats AS s CROSS APPLY sys.dm_exec_sql_text(s.sql_handle) AS t WHERE t.text LIKE N'%UPDATE /*real*/%' ORDER BY cmd;
Risultati
Ho eseguito i test 10 volte, raccolto i risultati e fatto la media di tutto. Ecco come si è rotto:
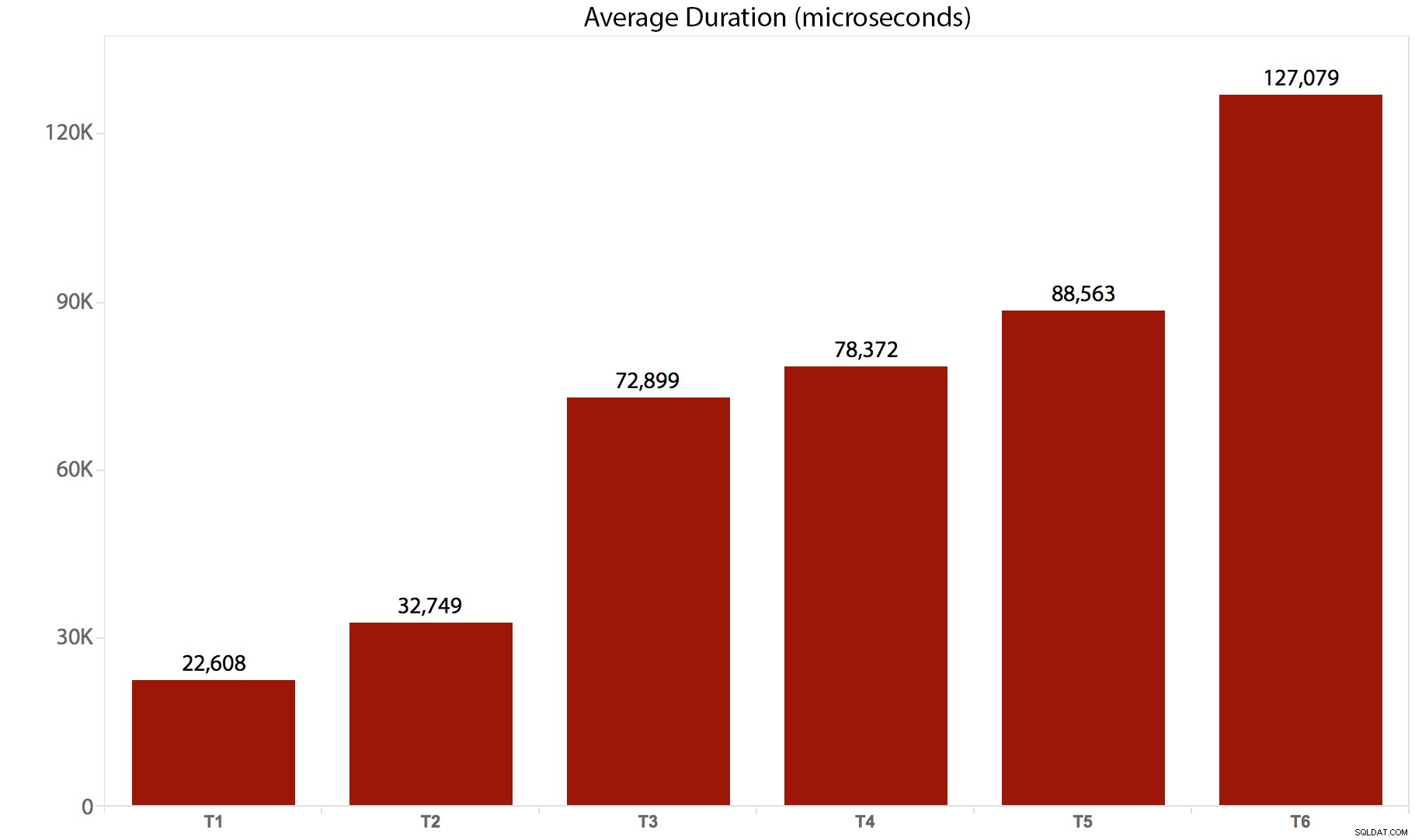
| Test/Lotto | Durata media (microsecondi) | Letture totali (8.000 pagine) |
|---|---|---|
| T1 :AGGIORNAMENTO /*real*/ dbo.tr1 … | 22.608 | 205.134 |
| T2 :AGGIORNAMENTO /*real*/ dbo.tr2 … | 32.749 | 11.331.628 |
| T3 :AGGIORNAMENTO /*real*/ dbo.tr3 … | 72.899 | 22.838.308 |
| T4 :AGGIORNAMENTO /*real*/ dbo.tr4 … | 78.372 | 44.463.275 |
| T5 :AGGIORNAMENTO /*real*/ dbo.tr5 … | 88.563 | 41.514.778 |
| T6 :AGGIORNAMENTO /*real*/ dbo.tr6 … | 127.079 | 100.330.753 |
Ed ecco una rappresentazione grafica della durata:
Conclusione
È chiaro che, in questo caso, c'è un sovraccarico sostanziale per ogni trigger che viene richiamato:tutti questi batch hanno in definitiva influenzato lo stesso numero di righe, ma in alcuni casi le stesse righe sono state toccate più volte. Probabilmente eseguirò ulteriori test successivi per misurare la differenza quando la stessa riga non viene mai toccata più di una volta – uno schema più complicato, forse, in cui 5 o 10 altre tabelle devono essere toccate ogni volta e queste diverse affermazioni potrebbero essere in un solo trigger o in più. La mia ipotesi è che le differenze di overhead saranno guidate più da cose come la concorrenza e il numero di righe interessate che dall'overhead del trigger stesso, ma vedremo.
Vuoi provare tu stesso la demo? Scarica lo script qui.