Allontanandomi dalla mia serie sull'ottimizzazione delle prestazioni a scatti, vorrei discutere di come la frammentazione dell'indice può insinuarsi in alcune circostanze.
Cos'è la frammentazione dell'indice?
La maggior parte delle persone pensa che la "frammentazione dell'indice" significhi il problema in cui le pagine foglia dell'indice sono fuori ordine:la pagina foglia dell'indice con il valore chiave successivo non è quella fisicamente contigua nel file di dati alla pagina foglia dell'indice attualmente in esame . Questa si chiama frammentazione logica (e alcune persone la chiamano frammentazione esterna, un termine confuso che non mi piace).
La frammentazione logica si verifica quando una pagina foglia dell'indice è piena ed è necessario spazio su di essa, sia per un inserto che per allungare un record esistente (dall'aggiornamento di una colonna a lunghezza variabile). In tal caso, Storage Engine crea una nuova pagina vuota e sposta il 50% delle righe (di solito, ma non sempre) dalla pagina intera alla nuova pagina. Questa operazione crea spazio in entrambe le pagine, consentendo l'inserimento o l'aggiornamento di procedere, ed è denominata divisione di pagina. Ci sono casi patologici interessanti che coinvolgono ripetute divisioni di pagina da una singola operazione e divisioni di pagina che aumentano i livelli di indice, ma vanno oltre lo scopo di questo post.
Quando si verifica una divisione di pagina, di solito provoca una frammentazione logica perché è altamente improbabile che la nuova pagina allocata sia fisicamente contigua a quella che viene divisa. Quando un indice ha molta frammentazione logica, le scansioni dell'indice vengono rallentate perché le letture fisiche delle pagine necessarie non possono essere eseguite in modo altrettanto efficiente (usando letture "readahead" multipagina) quando le pagine foglia non sono archiviate in ordine nel file di dati .
Questa è la definizione di base di frammentazione dell'indice, ma c'è un secondo tipo di frammentazione dell'indice che la maggior parte delle persone non considera:bassa densità di pagina (a volte chiama frammentazione interna, ancora una volta, un termine confuso che non mi piace).
La densità di pagina è una misura della quantità di dati archiviati in una pagina foglia indice. Quando si verifica una divisione di pagina con il solito caso 50/50, ogni pagina foglia (quella di divisione e quella nuova) viene lasciata con una densità di pagina di solo il 50%. Minore è la densità della pagina, maggiore è lo spazio vuoto presente nell'indice e quindi maggiore è lo spazio su disco e la memoria del pool di buffer che puoi pensare come sprecata. Ho scritto sul blog di questo problema qualche anno fa e puoi leggerlo qui.
Ora che ho fornito una definizione di base dei due tipi di frammentazione dell'indice, li chiamerò collettivamente semplicemente "frammentazione".
Per il resto di questo post vorrei discutere di tre casi in cui gli indici cluster possono essere frammentati anche se si evitano operazioni che ovviamente causerebbero la frammentazione (ad es. inserimenti casuali e aggiornamento dei record per essere più lunghi).
Frammentazione da eliminazioni
"In che modo un'eliminazione da una pagina foglia indice cluster può causare una divisione della pagina?" potresti chiedere. Non succede, in circostanze normali (e sono rimasto seduto a pensarci per alcuni minuti per assicurarmi che non ci fosse qualche strano caso patologico! Ma vedi la sezione seguente...) Tuttavia, le eliminazioni possono far diminuire progressivamente la densità della pagina.
Immagina il caso in cui l'indice cluster ha un valore di chiave di identità bigint, quindi gli inserti andranno sempre sul lato destro dell'indice e non verranno mai, mai inseriti in una parte precedente dell'indice (a meno che qualcuno non esegua il riseding del valore di identità - potenzialmente molto problematico!). Immagina ora che il carico di lavoro elimini dalla tabella i record che non sono più necessari, dopodiché l'attività di pulizia fantasma in background recupererà lo spazio sulla pagina e diventerà spazio libero.
In assenza di inserimenti casuali (impossibile nel nostro scenario a meno che qualcuno non reinsedi l'identità o specifichi un valore chiave da utilizzare dopo aver abilitato SET IDENTITY INSERT per la tabella), nessun nuovo record utilizzerà mai lo spazio liberato dai record eliminati. Ciò significa che la densità di pagina media delle parti precedenti dell'indice cluster diminuirà costantemente, determinando un aumento della quantità di spazio su disco sprecato e di memoria del pool di buffer, come descritto in precedenza.
Le eliminazioni possono causare la frammentazione, purché si consideri la densità della pagina come parte della "frammentazione".
Frammentazione dall'isolamento dell'istantanea
SQL Server 2005 ha introdotto due nuovi livelli di isolamento:isolamento dello snapshot e isolamento dello snapshot con commit di lettura. Questi due hanno una semantica leggermente diversa, ma sostanzialmente consentono alle query di vedere una vista point-in-time di un database e per selezioni prive di collisioni di blocco. Questa è una grande semplificazione, ma è sufficiente per i miei scopi.
Per facilitare questi livelli di isolamento, il team di sviluppo di Microsoft che ho guidato ha implementato un meccanismo chiamato versioning. Il modo in cui funziona il controllo delle versioni è che ogni volta che un record viene modificato, la versione precedente alla modifica del record viene copiata nell'archivio versioni in tempdb e il registrato modificato ottiene un tag di controllo delle versioni a 14 byte aggiunto alla fine di esso. Il tag contiene un puntatore alla versione precedente del record, oltre a un timestamp che può essere utilizzato per determinare qual è la versione corretta di un record da leggere per una determinata query. Ancora una volta, estremamente semplificato, ma è solo l'aggiunta dei 14 byte che ci interessa.
Pertanto, ogni volta che un record cambia quando uno di questi livelli di isolamento è attivo, può espandersi di 14 byte se non è già presente un tag di controllo delle versioni per il record. Cosa succede se non c'è abbastanza spazio per i 14 byte extra nella pagina foglia dell'indice? Esatto, si verificherà una divisione della pagina, causando la frammentazione.
Un grosso problema, potresti pensare, dato che il record sta comunque cambiando, quindi se stesse cambiando comunque le dimensioni, probabilmente si sarebbe verificata una divisione della pagina. No, questa logica è valida solo se la modifica del record è stata per aumentare le dimensioni di una colonna a lunghezza variabile. Verrà aggiunto un tag di controllo delle versioni anche se viene aggiornata una colonna a lunghezza fissa!
Esatto:quando è in corso il controllo delle versioni, gli aggiornamenti alle colonne di lunghezza fissa possono causare l'espansione di un record, causando potenzialmente una divisione e una frammentazione della pagina. La cosa ancora più interessante è che un'eliminazione aggiungerà anche il tag a 14 byte, quindi un'eliminazione in un indice cluster potrebbe causare una divisione della pagina quando è in uso il controllo delle versioni!
La conclusione qui è che l'abilitazione di entrambe le forme di isolamento degli snapshot può portare a una frammentazione che inizia improvvisamente a verificarsi negli indici cluster dove in precedenza non c'era possibilità di frammentazione.
Frammentazione da secondari leggibili
L'ultimo caso di cui voglio parlare è l'utilizzo di secondari leggibili, parte della funzionalità del gruppo di disponibilità aggiunta in SQL Server 2012.
Quando si abilita un secondario leggibile, tutte le query eseguite sulla replica secondaria vengono convertite utilizzando l'isolamento dello snapshot sotto le coperte. Ciò impedisce alle query di bloccare la riproduzione costante dei record di registro dalla replica primaria, poiché il codice di ripristino acquisisce blocchi man mano che procede.
A tale scopo, devono essere presenti tag di controllo delle versioni a 14 byte sui record nella replica secondaria. C'è un problema, perché tutte le repliche devono essere identiche, in modo che la riproduzione del registro funzioni. Beh, non proprio. I contenuti del tag di controllo delle versioni non sono rilevanti in quanto vengono utilizzati solo nell'istanza che li ha creati. Ma la replica secondaria non può aggiungere tag di controllo delle versioni, allungando i record, poiché ciò modificherebbe il layout fisico dei record su una pagina e interromperebbe la riproduzione del registro. Se i tag di controllo delle versioni fossero già presenti, tuttavia, potrebbe utilizzare lo spazio senza interrompere nulla.
Quindi è esattamente quello che succede. Il motore di archiviazione si assicura che tutti i tag di controllo delle versioni necessari per la replica secondaria siano già presenti, aggiungendoli alla replica primaria!
Non appena viene creata una replica secondaria leggibile di un database, qualsiasi aggiornamento a un record nella replica primaria fa sì che al record venga aggiunto un tag vuoto di 14 byte, in modo che i 14 byte siano correttamente contabilizzati in tutti i record di registro . Il tag non viene utilizzato per nulla (a meno che l'isolamento dello snapshot non sia abilitato sulla replica primaria stessa), ma il fatto che sia stato creato provoca l'espansione del record e, se la pagina è già piena, allora...
Sì, l'abilitazione di un secondario leggibile provoca lo stesso effetto sulla replica primaria come se avessi abilitato l'isolamento dello snapshot su di essa:frammentazione.
Riepilogo
Non pensare che poiché stai evitando di utilizzare i GUID come chiavi del cluster ed evitando di aggiornare le colonne a lunghezza variabile nelle tue tabelle, i tuoi indici cluster saranno immuni alla frammentazione. Come ho descritto sopra, ci sono altri carichi di lavoro e fattori ambientali che possono causare problemi di frammentazione negli indici cluster di cui devi essere a conoscenza.
Ora non ti improvvisare e pensa che non dovresti eliminare i record, non dovresti usare l'isolamento degli snapshot e non dovresti usare secondari leggibili. Devi solo essere consapevole che tutti possono causare frammentazione e sapere come rilevarla, rimuoverla e mitigarla.
SQL Sentry ha uno strumento interessante, Fragmentation Manager, che puoi usare come componente aggiuntivo di Performance Advisor per capire dove si trovano i problemi di frammentazione e risolverli. Potresti essere sorpreso dalla frammentazione che trovi quando controlli! Come rapido esempio, qui posso vedere visivamente, fino al livello della singola partizione, quanta frammentazione esiste, quanto velocemente è arrivata in quel modo, eventuali schemi esistenti e l'impatto effettivo che ha sulla memoria sprecata nel sistema:
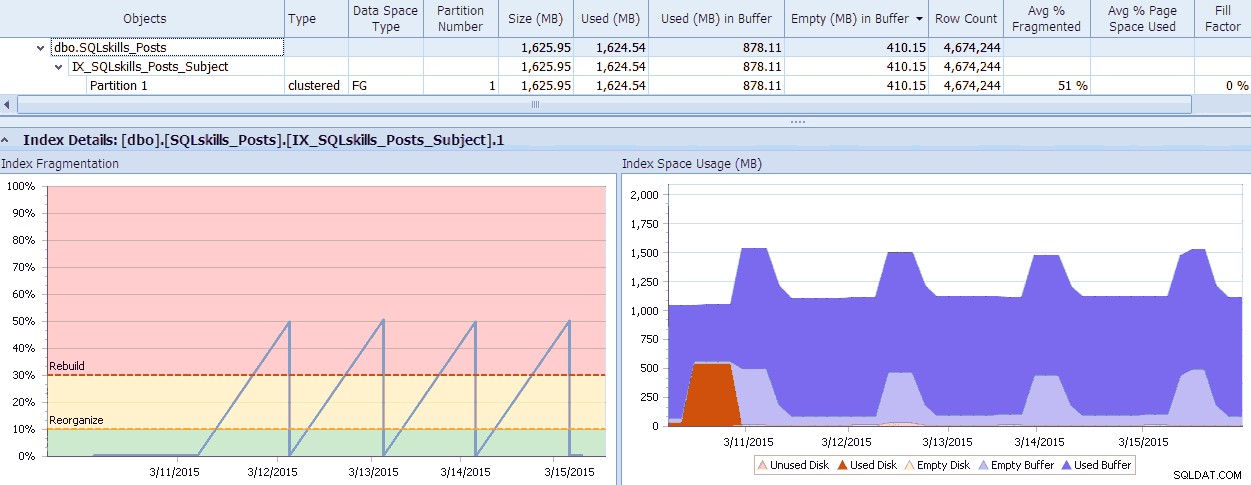 Dati di SQL Sentry Fragmentation Manager (fai clic per ingrandire)
Dati di SQL Sentry Fragmentation Manager (fai clic per ingrandire)
Nel prossimo post parlerò di più sulla frammentazione e su come mitigarla per renderla meno problematica.