Come ogni linguaggio di programmazione, T-SQL ha la sua quota di bug e insidie comuni, alcuni dei quali causano risultati errati e altri causano problemi di prestazioni. In molti di questi casi, ci sono best practice che possono aiutarti a evitare di finire nei guai. Ho intervistato altri MVP di Microsoft Data Platform chiedendo informazioni sui bug e le insidie che vedono spesso o che semplicemente trovano particolarmente interessanti e le best practice che utilizzano per evitarli. Ho molti casi interessanti.
Mille grazie a Erland Sommarskog, Aaron Bertrand, Alejandro Mesa, Umachandar Jayachandran (UC), Fabiano Neves Amorim, Milos Radivojevic, Simon Sabin, Adam Machanic, Thomas Grohser e Chan Ming Man per aver condiviso le tue conoscenze ed esperienze!
Questo articolo è il primo di una serie sull'argomento. Ogni articolo si concentra su un determinato tema. Questo mese mi concentro su bug, insidie e best practices legate al determinismo. Un calcolo deterministico è quello che garantisce la produzione di risultati ripetibili dati gli stessi input. Ci sono molti bug e insidie che derivano dall'uso di calcoli non deterministici. In questo articolo tratterò le implicazioni dell'uso dell'ordine non deterministico, delle funzioni non deterministiche, dei riferimenti multipli alle espressioni di tabella con calcoli non deterministici e dell'uso delle espressioni CASE e della funzione NULLIF con calcoli non deterministici.
Uso il database di esempio TSQLV5 in molti degli esempi di questa serie.
Ordine non deterministico
Una fonte comune di bug in T-SQL è l'uso dell'ordine non deterministico. Cioè, quando il tuo ordine per elenco non identifica in modo univoco una riga. Potrebbe essere l'ordine della presentazione, l'ordine TOP/OFFSET-FETCH o l'ordine della finestra.
Prendi ad esempio uno scenario di paging classico utilizzando il filtro OFFSET-FETCH. È necessario eseguire una query sulla tabella Sales.Orders restituendo una pagina di 10 righe alla volta, ordinate per data dell'ordine, decrescente (prima la più recente). Userò le costanti per gli elementi offset e fetch per semplicità, ma in genere sono espressioni basate su parametri di input.
La seguente query (chiamala Query 1) restituisce la prima pagina dei 10 ordini più recenti:
UTILIZZA TSQLV5; SELECT orderid, orderdate, custid FROM Sales.Orders ORDER BY orderdate DESC OFFSET 0 RIGHE FETCH SUCCESSIVO SOLO 10 RIGHE;
Il piano per la query 1 è mostrato nella figura 1.
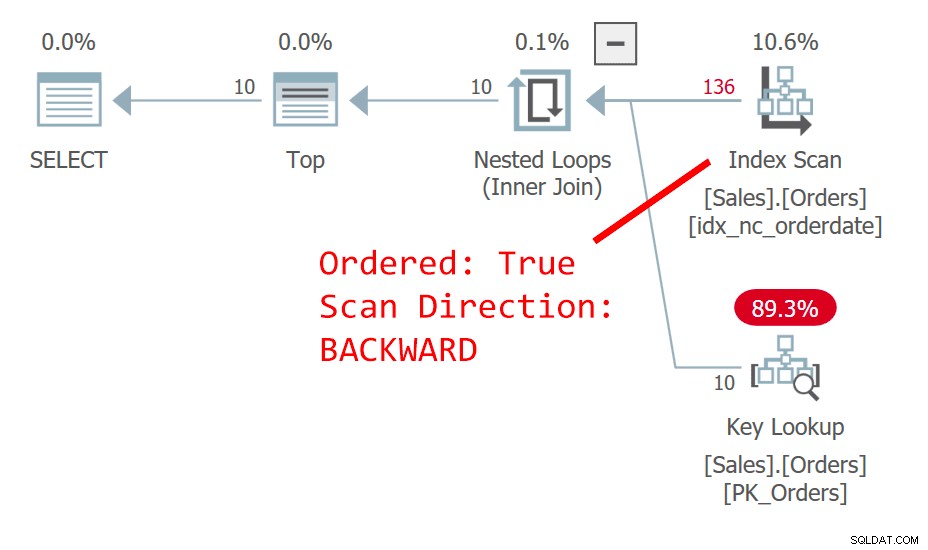 Figura 1:piano per la query 1
Figura 1:piano per la query 1
La query ordina le righe in base alla data dell'ordine, decrescente. La colonna orderdate non identifica in modo univoco una riga. Questo ordine non deterministico significa che concettualmente non c'è preferenza tra le righe con la stessa data. In caso di pareggi, ciò che determina quale riga preferirà SQL Server sono cose come le scelte del piano e il layout dei dati fisici, non qualcosa su cui puoi fare affidamento come ripetibile. Il piano in Figura 1 esegue la scansione dell'indice su orderdate ordinato all'indietro. Succede che questa tabella abbia un indice cluster su orderid e in una tabella cluster la chiave dell'indice cluster viene utilizzata come localizzatore di riga negli indici non cluster. In realtà viene posizionato in modo implicito come l'ultimo elemento chiave in tutti gli indici non cluster anche se in teoria SQL Server potrebbe averlo inserito nell'indice come colonna inclusa. Quindi, implicitamente, l'indice non cluster su orderdate è effettivamente definito su (orderdate, orderid). Di conseguenza, nella nostra scansione all'indietro ordinata dell'indice, tra righe legate in base a orderdate, si accede a una riga con un valore orderid più alto prima di una riga con un valore orderid più basso. Questa query genera il seguente output:
orderid data ordine custid ----------- ---------- ----------- 11077 2019-05-06 65 11076 2019-05- 06 9 11075 2019-05-06 68 11074 2019-05-06 73 11073 2019-05-05 58 11072 2019-05-05 20 11071 2019-05-05 46 11070 2019-05-05-694 2019-05-05 694 2 19-05-05 694 2 80 *** 11068 2019-05-04 62
Quindi, usa la seguente query (chiamala Query 2) per ottenere la seconda pagina di 10 righe:
SELECT orderid, orderdate, custid FROM Sales.Orders ORDER BY orderdate DESC OFFSET 10 RIGHE FETCH SUCCESSIVO SOLO 10 RIGHE;
Il piano per Query è mostrato nella Figura 2.
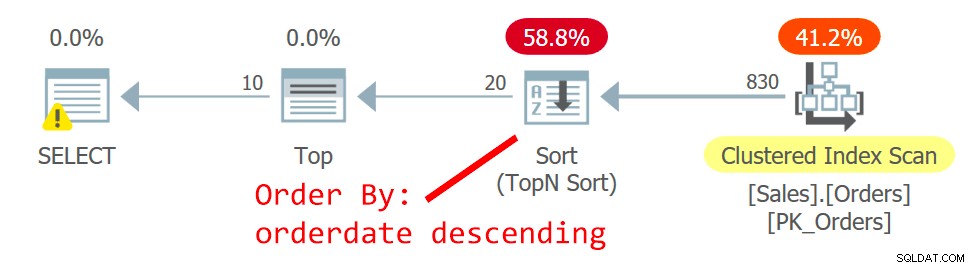
Figura 2:piano per la query 2
L'ottimizzatore sceglie un piano diverso, uno che esegue la scansione dell'indice cluster in modo non ordinato e utilizza un ordinamento TopN per supportare la richiesta dell'operatore Top di gestire il filtro di recupero dell'offset. Il motivo della modifica è che il piano nella figura 1 utilizza un indice non di copertura non cluster e più la pagina che stai cercando è lontana, più ricerche sono necessarie. Con la richiesta della seconda pagina, hai superato il punto critico che giustifica l'utilizzo dell'indice non coprente.
Anche se la scansione dell'indice cluster, definito con orderid come chiave, non è ordinata, il motore di archiviazione utilizza internamente una scansione dell'ordine dell'indice. Questo ha a che fare con la dimensione dell'indice. Fino a 64 pagine, il motore di archiviazione preferisce generalmente le scansioni degli ordini di indicizzazione alle scansioni degli ordini di allocazione. Anche se l'indice era più grande, al di sotto del livello di isolamento di lettura commit e dei dati non contrassegnati come di sola lettura, il motore di archiviazione utilizza una scansione dell'ordine dell'indice per evitare la doppia lettura e il salto delle righe a causa delle divisioni di pagina che si verificano durante il scansione. Alle condizioni indicate, in pratica, tra righe con la stessa data, questo piano accede a una riga con orderid inferiore prima di una con orderid superiore.
Questa query genera il seguente output:
orderid data ordine custid ----------- ---------- ----------- 11069 2019-05-04 80 *** 11064 2019 -05-01 71 11065 2019-05-01 46 11066 2019-05-01 89 11060 2019-04-30 27 11061 2019-04-30 32 11062 2019-04-30 66 11063 2019-04-1057 04-29 53 11058 2019-04-29 6
Osserva che anche se i dati sottostanti non sono cambiati, ti sei ritrovato con lo stesso ordine (con ID ordine 11069) restituito sia nella prima che nella seconda pagina!
Si spera che la migliore pratica qui sia chiara. Aggiungi un tiebreaker al tuo ordine per elenco per ottenere un ordine deterministico. Ad esempio, order by orderdate discendente, orderid discendente.
Riprova a chiedere la prima pagina, questa volta con un ordine deterministico:
SELECT orderid, orderdate, custid FROM Sales.Orders ORDER BY orderdate DESC, orderid DESC OFFSET 0 RIGHE FETCH SUCCESSIVA SOLO 10 RIGHE;
Ottieni il seguente output, garantito:
orderid data ordine custid ----------- ---------- ----------- 11077 2019-05-06 65 11076 2019-05- 06 9 11075 2019-05-06 68 11074 2019-05-06 73 11073 2019-05-05 58 11072 2019-05-05 20 11071 2019-05-05 46 11070 2019-05-05-694 2019-05-05 694 2 19-05-05 694 2 80 11068 2019-05-04 62
Richiedi la seconda pagina:
SELECT orderid, orderdate, custid FROM Sales.Orders ORDER BY orderdate DESC, orderid DESC OFFSET 10 RIGHE FETCH SUCCESSIVA SOLO 10 RIGHE;
Ottieni il seguente output, garantito:
orderid data ordine custid ----------- ---------- ------------ 11067 2019-05-04 17 11066 2019-05- 01 89 11065 2019-05-01 46 11064 2019-05-01 71 11063 2019-04-30 37 11062 2019-04-30 66 11061 2019-04-30 32 11060 2019-04-309 2019-04-309 27 67 11058 2019-04-29 6
Finché non sono state apportate modifiche ai dati sottostanti, hai la garanzia di ottenere pagine consecutive senza ripetizioni o saltare righe tra le pagine.
In modo simile, utilizzando funzioni di finestra come ROW_NUMBER con ordine non deterministico, potresti ottenere risultati diversi per la stessa query a seconda della forma del piano e dell'effettivo ordine di accesso tra i legami. Considera la seguente query (chiamala Query 3), implementando la richiesta della prima pagina utilizzando i numeri di riga (forzando l'uso dell'indice su orderdate a scopo illustrativo):
WITH C AS ( SELECT orderid, orderdate, custid, ROW_NUMBER() OVER(ORDER BY orderdate DESC) AS n FROM Sales.Orders WITH (INDEX(idx_nc_orderdate))) SELECT orderid, orderdate, custid FROM C WHERE n TRA 1 E 10;
Il piano per questa query è mostrato nella Figura 3:
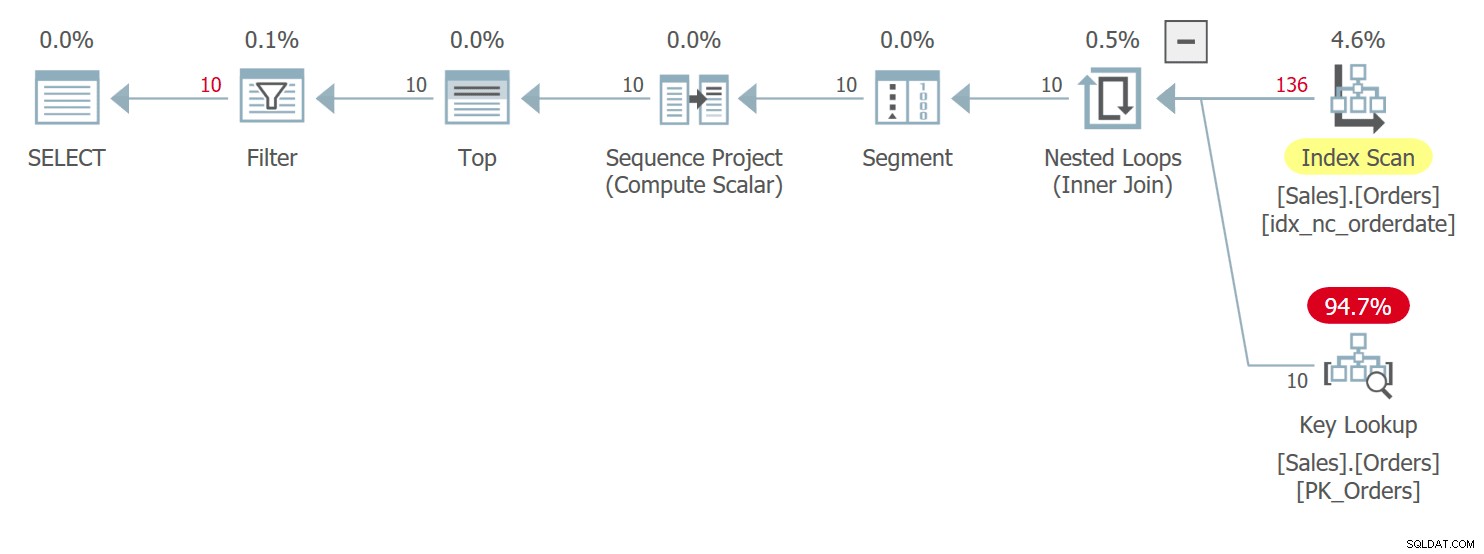
Figura 3:piano per la query 3
Qui hai condizioni molto simili a quelle che ho descritto in precedenza per la query 1 con il suo piano mostrato in precedenza nella figura 1. Tra le righe con legami nei valori orderdate, questo piano accede a una riga con un valore orderid più alto prima di una con un valore più basso valore dell'ordine Questa query genera il seguente output:
orderid data ordine custid ----------- ---------- ----------- 11077 2019-05-06 65 11076 2019-05- 06 9 11075 2019-05-06 68 11074 2019-05-06 73 11073 2019-05-05 58 11072 2019-05-05 20 11071 2019-05-05 46 11070 2019-05-05-694 2019-05-05 694 2 19-05-05 694 2 80 *** 11068 2019-05-04 62
Quindi, esegui nuovamente la query (chiamala Query 4), richiedendo la prima pagina, solo che questa volta forza l'uso dell'indice cluster PK_Orders:
WITH C AS ( SELECT orderid, orderdate, custid, ROW_NUMBER() OVER(ORDER BY orderdate DESC) AS n FROM Sales.Orders WITH (INDEX(PK_Orders))) SELECT orderid, orderdate, custid FROM C WHERE n TRA 1 E 10;
Il piano per questa query è mostrato nella Figura 4.

Figura 4:piano per la query 4
Questa volta hai condizioni molto simili a quelle che ho descritto in precedenza per la query 2 con il suo piano mostrato in precedenza nella figura 2. Tra le righe con legami nei valori orderdate, questo piano accede a una riga con un valore orderid inferiore prima di una con un valore orderid superiore. Questa query genera il seguente output:
orderid data ordine custid ----------- ---------- ----------- 11074 2019-05-06 73 11075 2019-05- 06 68 11076 2019-05-06 9 11077 2019-05-06 65 11070 2019-05-05 44 11071 2019-05-05 46 11072 2019-05-05 20 11073 2019-05-05-69-58 2019-05-05-69-58 2 17 *** 11068 2019-05-04 62
Osserva che le due esecuzioni hanno prodotto risultati diversi anche se nulla è cambiato nei dati sottostanti.
Anche in questo caso, la best practice qui è semplice:usa l'ordine deterministico aggiungendo un tie-break, in questo modo:
WITH C AS ( SELECT orderid, orderdate, custid, ROW_NUMBER() OVER(ORDER BY orderdate DESC, orderid DESC) AS n FROM Sales.Orders ) SELECT orderid, orderdate, custid FROM C WHERE n TRA 1 E 10;
Questa query genera il seguente output:
orderid data ordine custid ----------- ---------- ----------- 11077 2019-05-06 65 11076 2019-05- 06 9 11075 2019-05-06 68 11074 2019-05-06 73 11073 2019-05-05 58 11072 2019-05-05 20 11071 2019-05-05 46 11070 2019-05-05-694 2019-05-05 694 2 19-05-05 694 2 80 11068 2019-05-04 62
Il set restituito è garantito per essere ripetibile indipendentemente dalla forma del piano.
Probabilmente vale la pena ricordare che poiché questa query non ha un ordine di presentazione per clausola nella query esterna, qui non esiste un ordine di presentazione garantito. Se hai bisogno di tale garanzia, devi aggiungere un ordine di presentazione per clausola, in questo modo:
CON C AS ( SELECT orderid, orderdate, custid, ROW_NUMBER() OVER(ORDER BY orderdate DESC, orderid DESC) AS n FROM Sales.Orders ) SELECT orderid, orderdate, custid DA C DOVE n TRA 1 E 10 ORDINE PER n;
Funzioni non deterministiche
Una funzione non deterministica è una funzione che, dati gli stessi input, può restituire risultati diversi in diverse esecuzioni della funzione. Esempi classici sono SYSDATETIME, NEWID e RAND (quando invocato senza un seme di input). Il comportamento delle funzioni non deterministiche in T-SQL può sorprendere alcuni e in alcuni casi potrebbe causare bug e insidie.
Molte persone presumono che quando si invoca una funzione non deterministica come parte di una query, la funzione viene valutata separatamente per riga. In pratica, la maggior parte delle funzioni non deterministiche viene valutata una volta per riferimento nella query. Considera la seguente query come esempio:
SELECT orderid, SYSDATETIME() AS dt, RAND() AS rnd FROM Sales.Orders;
Poiché nella query è presente un solo riferimento a ciascuna delle funzioni non deterministiche SYSDATETIME e RAND, ciascuna di queste funzioni viene valutata solo una volta e il risultato viene ripetuto su tutte le righe dei risultati. Ho ottenuto il seguente output durante l'esecuzione di questa query:
orderid dt rnd ----------- ---------------------------- ------ ---------------- 11008 2019-02-04 17:03:07.9229177 0.962042872007464 11019 2019-02-04 17:03:07.9229177 0.962042872007464 11039 2019-02-04:17 07.9229177 0.962042872007464 11040 2019-02-04 17:03:07.9229177 0.962042872007464 11045 2019-02-04 17:03:07.9229177 0.962042872007464 11051 2019-02-04 17:03:07.9229177 0.962042872007464 11054 2019-02-04 17:03:07.9229177 0.962042872007464 11058 2019-02-04 17:03:07.9229177 0.962042872007464 11059 2019-02-04 17:03:07.9229177 0.962042872007464 11061 2019-04 17:03Come esempio in cui la mancata comprensione di questo comportamento può causare un bug, supponiamo di dover scrivere una query che restituisca tre ordini casuali dalla tabella Sales.Orders. Un tentativo iniziale comune consiste nell'utilizzare una query TOP con l'ordinamento basato sulla funzione RAND, pensando che la funzione venga valutata separatamente per riga, in questo modo:
SELECT TOP (3) orderid FROM Sales.Orders ORDER BY RAND();In pratica, la funzione viene valutata una sola volta per l'intera query; pertanto, tutte le righe ottengono lo stesso risultato e l'ordinamento è completamente inalterato. In effetti, se controlli il piano per questa query, non vedrai alcun operatore di ordinamento. Quando ho eseguito questa query più volte, continuavo a ottenere lo stesso risultato:
orderid ----------- 11008 11019 11039La query è in realtà equivalente a una senza una clausola ORDER BY, in cui l'ordinamento della presentazione non è garantito. Quindi tecnicamente l'ordinamento non è deterministico e, in teoria, esecuzioni diverse potrebbero comportare un ordine diverso e quindi una diversa selezione delle prime 3 righe. Tuttavia, la probabilità che ciò accada è bassa e non puoi pensare che questa soluzione produca tre righe casuali in ogni esecuzione.
Un'eccezione alla regola per cui una funzione non deterministica viene richiamata una volta per riferimento nella query è la funzione NEWID, che restituisce un identificatore univoco globale (GUID). Quando viene utilizzata in una query, questa funzione è invocato separatamente per riga. La seguente query lo dimostra:
SELECT orderid, NEWID() AS mynewid FROM Sales.Orders;Questa query ha generato il seguente output:
orderid mynewid ------------------------- ---------------------------------- -- 11008 D6417542-C78A-4A2D-9517-7BB0FCF3B932 11019 E2E46BF1-4FA6-4EF2-8328-18B86259AD5D 11039 2917D923-AC60-44F5-92D7-FF84E52250CC 11040 B6287B49-DAE7-4C6C-98A8-7DB8A879581C 11045 2E14D8F7-21E5-4039-BF7E -0A27D1A0E186 11051 FA0B7B3E-BA41-4D80-8581-782EB88836C0 11054 1E6146BB-FEE7-4FF4-A4A2-3243AA2CBF78 11058 49302EA9-0243-4502-B9D2-46D751E6EFA9 11059 F5BB7CB2-3B17-4D01-ABD2-04F3C5115FCF 11061 09E406CA-0251-423B-8DF5 -564E1257F93E ...Il valore di NEWID stesso è abbastanza casuale. Se applichi la funzione CHECKSUM su di essa, ottieni un risultato intero con una distribuzione casuale ancora migliore. Quindi un modo per ottenere tre ordini casuali è utilizzare una query TOP con l'ordinamento basato su CHECKSUM(NEWID()), in questo modo:
SELECT TOP (3) orderid FROM Sales.Orders ORDER BY CHECKSUM(NEWID());Esegui questa query ripetutamente e nota che ottieni ogni volta un insieme diverso di tre ordini casuali. Ho ottenuto il seguente output in un'unica esecuzione:
orderid ----------- 11031 10330 10962E il seguente output in un'altra esecuzione:
orderid ----------- 10308 10885 10444Oltre a NEWID, cosa succede se è necessario utilizzare una funzione non deterministica come SYSDATETIME in una query e se è necessario valutarla separatamente per riga? Un modo per ottenere ciò è utilizzare una funzione definita dall'utente (UDF) che invoca la funzione non deterministica, in questo modo:
CREA O MODIFICA FUNZIONE dbo.MySysDateTime() RESTITUISCE DATETIME2 COME INIZIO RETURN SYSDATETIME(); FINE; VAIQuindi invochi l'UDF nella query in questo modo (chiamalo Query 5):
SELECT orderid, dbo.MySysDateTime() AS mydt FROM Sales.Orders;L'UDF viene eseguito per riga questa volta. È necessario essere consapevoli, tuttavia, che esiste una forte penalizzazione delle prestazioni associata all'esecuzione per riga dell'UDF. Inoltre, invocare un UDF scalare T-SQL è un inibitore del parallelismo.
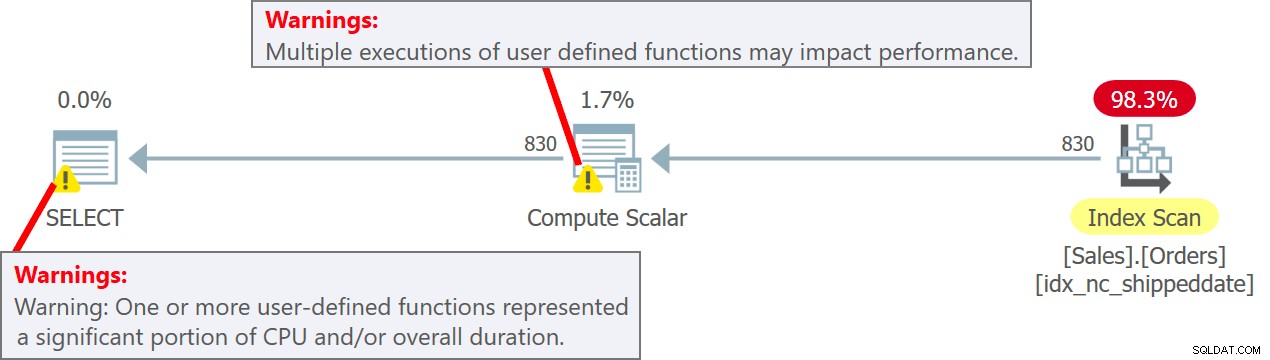
Il piano per questa query è mostrato nella Figura 5.
Figura 5:piano per la query 5Si noti nel piano che effettivamente l'UDF viene invocato per riga di origine nell'operatore Calcola scalare. Nota inoltre che SentryOne Plan Explorer ti avverte della potenziale penalizzazione delle prestazioni associata all'uso dell'UDF sia nell'operatore Compute Scalar che nel nodo radice del piano.
Ho ottenuto il seguente output dall'esecuzione di questa query:
orderid mydt ----------- --------------------------- 11008 2019-02-04 17 :07:03.7221339 11019 2019-02-04 17:07:03.7221339 11039 2019-02-04 17:07:03.7221339 ... 10251 2019-02-04 17:07:03.7231315 1107:07-2 2 03.7231315 10248 2019-02-04 17:07:03.7231315 ... 10416 2019-02-04 17:07:03.7241304 10420 2019-02-04 17:07:03.7241304 10421 2019-02-04 17:07:03.7241304 .. .Osserva che le righe di output hanno più valori di data e ora diversi nella colonna mydt.
Potresti aver sentito che SQL Server 2019 risolve il problema di prestazioni comune causato dalle UDF scalari T-SQL integrando tali funzioni. Tuttavia, l'UDF deve soddisfare un elenco di requisiti per essere inlineabile. Uno dei requisiti è che l'UDF non richiami alcuna funzione intrinseca non deterministica come SYSDATETIME. Il motivo di questo requisito è che forse hai creato l'UDF esattamente per ottenere un'esecuzione per riga. Se l'UDF fosse inline, la funzione non deterministica sottostante verrebbe eseguita solo una volta per l'intera query. In effetti, il piano nella figura 5 è stato generato in SQL Server 2019 e puoi vedere chiaramente che l'UDF non è stato integrato. Ciò è dovuto all'uso della funzione non deterministica SYSDATETIME. Puoi verificare se una UDF è inlineabile in SQL Server 2019 interrogando l'attributo is_inlineable nella vista sys.sql_modules, in questo modo:
SELECT is_inlineable FROM sys.sql_modules WHERE object_id =OBJECT_ID(N'dbo.MySysDateTime');Questo codice genera il seguente output che ti dice che UDF MySysDateTime non è inlineabile:
is_inlineable ------------- 0Per dimostrare una UDF che è inlineabile, ecco la definizione di una UDF denominata EndOfyear che accetta una data di input e restituisce la rispettiva data di fine anno:
CREA O MODIFICA FUNZIONE dbo.EndOfYear(@dt AS DATE) RESTITUISCE LA DATA COME INIZIO RESTITUZIONE DATEADD(year, DATEDIFF(year, '18991231', @dt), '18991231'); FINE; VAIQui non vengono utilizzate funzioni non deterministiche e il codice soddisfa anche gli altri requisiti per l'inlining. Puoi verificare che l'UDF sia inlineabile utilizzando il seguente codice:
SELECT is_inlineable FROM sys.sql_modules WHERE object_id =OBJECT_ID(N'dbo.EndOfYear');Questo codice genera il seguente output:
is_inlineable ------------- 1La seguente query (chiamala Query 6) utilizza l'UDF EndOfYear per filtrare gli ordini effettuati in una data di fine anno:
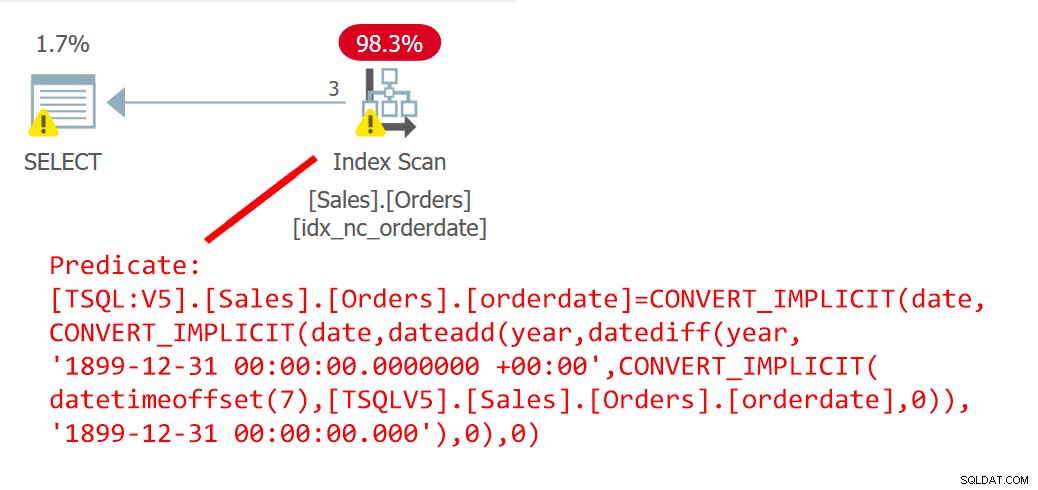
SELECT orderid FROM Sales.Orders WHERE orderdate =dbo.EndOfYear(orderdate);Il piano per questa query è mostrato nella Figura 6.
Figura 6:piano per la query 6Il piano mostra chiaramente che l'UDF è stato inlineato.
Espressioni tabellari, non determinismo e riferimenti multipli
Come accennato, le funzioni non deterministiche come SYSDATETIME vengono invocate una volta per riferimento in una query. Ma cosa succede se si fa riferimento a tale funzione una volta in una query in un'espressione di tabella come un CTE e quindi si dispone di una query esterna con più riferimenti al CTE? Molte persone non si rendono conto che ogni riferimento all'espressione della tabella viene espanso separatamente e il codice inline risulta in più riferimenti alla funzione non deterministica sottostante. Con una funzione come SYSDATETIME, a seconda della tempistica esatta di ciascuna delle esecuzioni, potresti ottenere un risultato diverso per ciascuna. Alcune persone trovano questo comportamento sorprendente.
Questo può essere illustrato con il seguente codice:
DICHIARA @i AS INT =1, @rc AS INT =NULL; MENTRE 1 =1 INIZIA; CON C1 AS ( SELECT SYSDATETIME() AS dt ), C2 AS ( SELECT dt DA C1 UNION SELECT dt DA C1 ) SELECT @rc =COUNT(*) DA C2; SE @rc> 1 PAUSA; SET @i +=1; FINE; SELECT @rc AS valori distinti, @i AS iterazioni;Se entrambi i riferimenti a C1 nella query in C2 rappresentassero la stessa cosa, questo codice avrebbe prodotto un ciclo infinito. Tuttavia, poiché i due riferimenti vengono espansi separatamente, quando la tempistica è tale che ogni invocazione avvenga in un diverso intervallo di 100 nanosecondi (la precisione del valore del risultato), l'unione risulta in due righe e il codice dovrebbe interrompere il ciclo continuo. Esegui questo codice e verifica tu stesso. Infatti, dopo alcune iterazioni si rompe. Ho ottenuto il seguente risultato in una delle esecuzioni:
iterazioni valori distinti -------------- ----------- 2 448La procedura consigliata consiste nell'evitare di usare espressioni di tabella come CTE e viste, quando la query interna utilizza calcoli non deterministici e la query esterna fa riferimento all'espressione della tabella più volte. Questo ovviamente a meno che tu non comprenda le implicazioni e tu sia d'accordo con loro. Opzioni alternative potrebbero consistere nel persistere il risultato della query interna, ad esempio in una tabella temporanea, e quindi interrogare la tabella temporanea tutte le volte che è necessario.
Per dimostrare esempi in cui non seguire le migliori pratiche può creare problemi, supponiamo di dover scrivere una query che accoppia i dipendenti dalla tabella HR.Employees in modo casuale. Ti viene in mente la seguente query (chiamala query 7) per gestire l'attività:
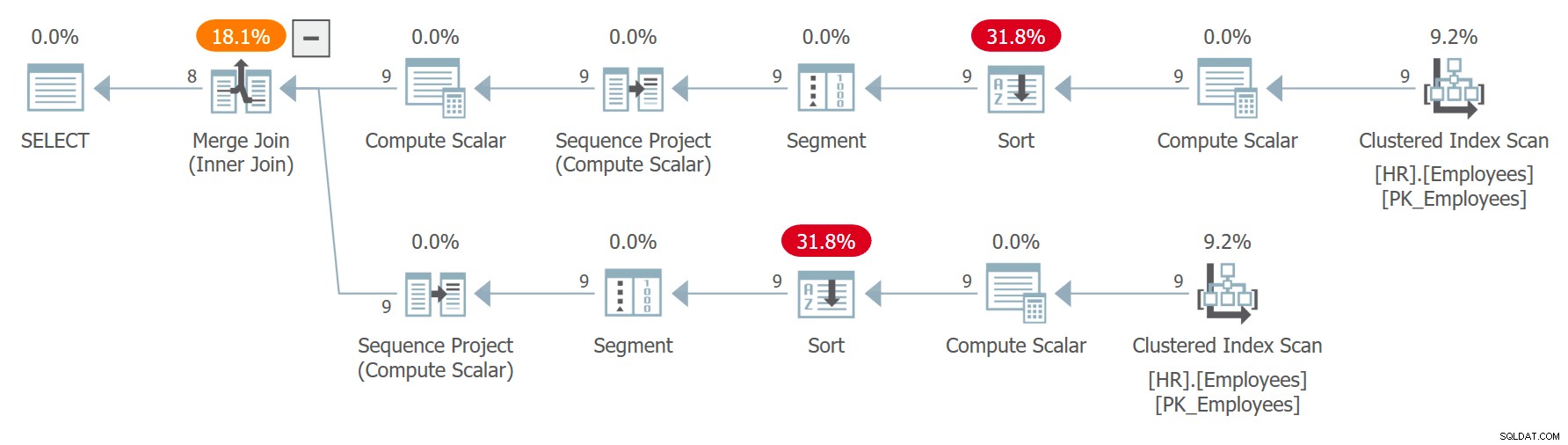
CON C AS ( SELECT empid, firstname, lastname, ROW_NUMBER() OVER(ORDER BY CHECKSUM(NEWID())) AS n FROM HR.Employees ) SELECT C1.empid AS empid1, C1.firstname AS firstname1, C1. cognome AS cognome1, C2.empid AS empid2, C2.nome AS nome2, C2.cognome AS cognome2 DA C AS C1 INNER JOIN C AS C2 ON C1.n =C2.n + 1;Il piano per questa query è mostrato nella Figura 7.
Figura 7:piano per la query 7Osservare che i due riferimenti a C vengono espansi separatamente e che i numeri di riga vengono calcolati indipendentemente per ogni riferimento ordinato da invocazioni indipendenti dell'espressione CHECKSUM(NEWID()). Ciò significa che non è garantito che lo stesso dipendente ottenga lo stesso numero di riga nei due riferimenti espansi. Se un dipendente ottiene la riga numero x in C1 e la riga numero x – 1 in C2, la query abbinerà il dipendente a se stesso. Ad esempio, ho ottenuto il seguente risultato in una delle esecuzioni:
empid1 nome1 cognome1 empid2 nome2 cognome2 ----------- ---------- -------------------- ----------- ---------- -------------------- 3 Judy Lew 6 Paul Suurs 9 Patricia Doyle *** 9 Patricia Doyle *** 5 Sven Mortensen 4 Yael Peled 6 Paul Suurs 8 Maria Cameron 8 Maria Cameron 5 Sven Mortensen 2 Don Funk *** 2 Don Funk *** 4 Yael Peled 3 Judy Lew 7 Russell King ** * 7 Re Russell ***Osserva che qui ci sono tre casi di auto-coppie. Questo è più facile da vedere aggiungendo un filtro alla query esterna che cerca specificamente le coppie automatiche, in questo modo:
CON C AS ( SELECT empid, firstname, lastname, ROW_NUMBER() OVER(ORDER BY CHECKSUM(NEWID())) AS n FROM HR.Employees ) SELECT C1.empid AS empid1, C1.firstname AS firstname1, C1. cognome AS cognome1, C2.empid AS empid2, C2.nome AS nome2, C2.cognome AS cognome2 DA C AS C1 INNER JOIN C AS C2 ON C1.n =C2.n + 1 WHERE C1.empid =C2.empid;Potrebbe essere necessario eseguire questa query più volte per visualizzare il problema. Ecco un esempio del risultato che ho ottenuto in una delle esecuzioni:
empid1 nome1 cognome1 empid2 nome2 cognome2 ----------- ---------- -------------------- ----------- ---------- -------------------- 5 Sven Mortensen 5 Sven Mortensen 2 Don Funk 2 Don FunkSeguendo la procedura consigliata, un modo per risolvere questo problema consiste nel rendere persistente il risultato della query interna in una tabella temporanea e quindi eseguire query su più istanze della tabella temporanea in base alle esigenze.
Un altro esempio illustra i bug che possono derivare dall'uso di un ordine non deterministico e più riferimenti a un'espressione di tabella. Si supponga di dover interrogare la tabella Sales.Orders e per eseguire l'analisi delle tendenze, si desidera accoppiare ogni ordine con il successivo in base alla data dell'ordine. La soluzione deve essere compatibile con i sistemi precedenti a SQL Server 2012, il che significa che non è possibile utilizzare le ovvie funzioni LAG/LEAD. Decidi di utilizzare un CTE che calcola i numeri di riga per posizionare le righe in base all'ordinamento della data dell'ordine, quindi unisci due istanze del CTE, accoppiando gli ordini in base a un offset di 1 tra i numeri di riga, in questo modo (chiama questa query 8):
CON C AS ( SELECT *, ROW_NUMBER() OVER(ORDER BY orderdate DESC) AS n FROM Sales.Orders ) SELECT C1.orderid AS orderid1, C1.orderdate AS orderdate1, C1.custid AS custid1, C2.orderid AS orderid2, C2.orderdate AS orderdate2 DA C AS C1 ESTERNO SINISTRO UNISCI C AS C2 SU C1.n =C2.n + 1;Il piano per questa query è mostrato nella Figura 8.
Figura 8:piano per la query 8
L'ordinamento del numero di riga non è deterministico poiché orderdate non è univoco. Si osservi che i due riferimenti al CTE vengono ampliati separatamente. Curiosamente, poiché la query cerca un diverso sottoinsieme di colonne da ciascuna delle istanze, l'ottimizzatore decide di utilizzare un indice diverso in ogni caso. In un caso utilizza una scansione all'indietro ordinata dell'indice su orderdate, scansionando effettivamente le righe con la stessa data in base all'ordine decrescente di orderid. Nell'altro caso esegue la scansione dell'indice cluster, ordinato false e quindi ordina, ma effettivamente tra righe con la stessa data, accede alle righe in ordine crescente orderid. Ciò è dovuto a un ragionamento simile che ho fornito nella sezione sull'ordine non deterministico in precedenza. Ciò può comportare che la stessa riga ottenga il numero di riga x in un'istanza e il numero di riga x – 1 nell'altra istanza. In tal caso, il join finirà per abbinare un ordine con se stesso anziché con quello successivo come dovrebbe.
Ho ottenuto il seguente risultato durante l'esecuzione di questa query:
orderid1 orderdate1 custid1 orderid2 orderdate2 ----------- ---------- ----------- ---------- - ---------- 11074 2019-05-06 73 NULL NULL 11075 2019-05-06 68 11077 2019-05-06 11076 2019-05-06 9 11076 2019-05-06 *** 11077 2019-05-06 65 11075 2019-05-06 11070 2019-05-05 44 11074 2019-05-06 11071 2019-05-05 46 11073 2019-05-05 11072 2019-05-05-792 20 10 05 *** ...Osserva le corrispondenze automatiche nel risultato. Anche in questo caso, il problema può essere identificato più facilmente aggiungendo un filtro alla ricerca di corrispondenze automatiche, in questo modo:
CON C AS ( SELECT *, ROW_NUMBER() OVER(ORDER BY orderdate DESC) AS n FROM Sales.Orders ) SELECT C1.orderid AS orderid1, C1.orderdate AS orderdate1, C1.custid AS custid1, C2.orderid AS orderid2, C2.orderdate AS orderdate2 DA C AS C1 ESTERNO SINISTRO UNISCI C AS C2 SU C1.n =C2.n + 1 DOVE C1.orderid =C2.orderid;Ho ottenuto il seguente output da questa query:
orderid1 orderdate1 custid1 orderid2 orderdate2 ----------- ---------- ----------- ---------- - ---------- 11076 2019-05-06 9 11076 2019-05-06 11072 2019-05-05 20 11072 2019-05-05 11062 2019-04-30 66 11062 2019-04-30 11052 2019-04-27 34 11052 2019-04-27 11042 2019-04-22 15 11042 2019-04-22 ...La migliore pratica qui è assicurarsi di utilizzare un ordine univoco per garantire il determinismo aggiungendo un tiebreaker come orderid alla clausola dell'ordine della finestra. Quindi, anche se hai più riferimenti allo stesso CTE, i numeri di riga saranno gli stessi in entrambi. Se desideri evitare la ripetizione dei calcoli, potresti anche considerare la persistenza del risultato interno della query, ma devi considerare il costo aggiuntivo di tale lavoro.
CASO/NULLIF e funzioni non deterministiche
Quando in una query sono presenti più riferimenti a una funzione non deterministica, ogni riferimento viene valutato separatamente. Ciò che potrebbe sorprendere e persino causare bug è che a volte scrivi un riferimento, ma implicitamente viene convertito in più riferimenti. Tale è la situazione con alcuni usi dell'espressione CASE e della funzione IIF.
Considera il seguente esempio:
SELECT CASE ABS(CHECKSUM(NEWID())) % 2 QUANDO 0 POI 'Pari' QUANDO 1 POI 'Dispari' END;Qui il risultato dell'espressione testata è un valore intero non negativo, quindi chiaramente deve essere pari o dispari. Non può essere né pari né dispari. However, if you run this code enough times, you will sometimes get a NULL indicating that the implied ELSE NULL clause of the CASE expression was activated. The reason for this is that the above expression translates to the following:
SELECT CASE WHEN ABS(CHECKSUM(NEWID())) % 2 =0 THEN 'Even' WHEN ABS(CHECKSUM(NEWID())) % 2 =1 THEN 'Odd' ELSE NULL END;In the converted expression there are two separate references to the tested expression that generates a random nonnegative value, and each gets evaluated separately. One possible path is that the first evaluation produces an odd number, the second produces an even number, and then the ELSE NULL clause is activated.
Here’s a very similar situation with the NULLIF function:
SELECT NULLIF(ABS(CHECKSUM(NEWID())) % 2, 0);This expression generates a random nonnegative value, and is supposed to return 1 when it’s odd, and NULL otherwise. It’s never supposed to return 0 since in such a case the 0 is supposed to be replaced with a NULL. Run it a few times and you will see that in some cases you get a 0. The reason for this is that the above expression internally translates to the following one:
SELECT CASE WHEN ABS(CHECKSUM(NEWID())) % 2 =0 THEN NULL ELSE ABS(CHECKSUM(NEWID())) % 2 END;A possible path is that the first WHEN clause generates a random odd value, so the ELSE clause is activated, and the ELSE clause generates a random even value so the % 2 calculation results in a 0.
In both cases this behavior is standard, so the bug is more in the eyes of the beholder based on your expectations and your choice of how to write the code. The best practice in both cases is to persist the result of the original calculation and then interact with the persisted result. If it’s a single value, store the result in a variable first. If you’re querying tables, first persist the result of the nondeterministic calculation in a column in a temporary table, and then apply the CASE/IIF logic in the query against the temporary table.
Conclusione
This article is the first in a series about T-SQL bugs, pitfalls and best practices, and is the result of discussions with fellow Microsoft Data Platform MVPs who shared their experiences. This time I focused on bugs and pitfalls that resulted from using nondeterministic order and nondeterministic calculations. In future articles I’ll continue with other themes. If you have bugs and pitfalls that you often stumble into, or that you find as particularly interesting, please do share!