L'elevata disponibilità è un requisito per molti sistemi, indipendentemente dalla tecnologia in uso. Ciò è particolarmente importante per i database, poiché memorizzano i dati su cui fanno affidamento le applicazioni. A seconda dei requisiti, esistono diversi modi per implementare un ambiente ad alta disponibilità per PostgreSQL, ma è sempre necessario utilizzare uno strumento complementare poiché le funzionalità native di PostgreSQL non sono sufficienti.
In questo blog, vedremo come distribuire Percona Distribution per PostgreSQL per l'alta disponibilità e che tipo di strumenti sono necessari per farlo.
Distribuzione Percona per PostgreSQL
È una raccolta di strumenti per assisterti nella gestione del tuo sistema di database PostgreSQL. Installa PostgreSQL e lo integra con una selezione di estensioni che consentono di risolvere in modo efficiente compiti pratici essenziali, tra cui:
- pg_repack :Ricostruisce gli oggetti del database PostgreSQL.
- pgaudit :Fornisce una registrazione dettagliata della sessione o dell'audit degli oggetti tramite la funzione di registrazione standard di PostgreSQL.
- pgBackRest :È una soluzione di backup e ripristino per PostgreSQL.
- Patroni :È una soluzione ad alta disponibilità per PostgreSQL.
- pg_stat_monitor :raccoglie e aggrega le statistiche per PostgreSQL e fornisce informazioni sull'istogramma.
- Una raccolta di estensioni contrib PostgreSQL aggiuntive.
Alta disponibilità su PostgreSQL
Ci sono diverse architetture per l'alta disponibilità di PostgreSQL, ma la più comune è avere una topologia Master-Slave (Primary-Standby). Si basa su un database primario con uno o più nodi standby. Questi database in standby rimarranno sincronizzati (o quasi sincronizzati) con il database primario, a seconda che la replica sia sincrona o asincrona. Se il server principale si guasta, lo standby contiene quasi tutti i dati del server principale e può essere rapidamente trasformato nel nuovo server di database primario.
Ma una configurazione master-slave non è sufficiente per garantire un'elevata disponibilità in modo efficace, poiché è necessario anche gestire i guasti. Una volta rilevato un errore, dovresti essere in grado di selezionare un nodo di standby e di eseguire il failover su di esso con il minor ritardo possibile. PostgreSQL stesso non include un meccanismo di failover automatico, quindi richiederà alcuni script personalizzati o strumenti di terze parti per questa automazione.
Dopo che si verifica un failover, le applicazioni devono essere informate di conseguenza, in modo che possano iniziare a utilizzare il nuovo nodo primario. Inoltre, è necessario valutare lo stato della nostra architettura dopo un failover, perché è possibile eseguire in una situazione in cui è in esecuzione solo il nuovo nodo primario (ovvero, prima del problema avevi un nodo primario e un solo standby). In tal caso, dovrai aggiungere in qualche modo un nuovo nodo di standby in modo da ricreare la configurazione master-slave che avevi originariamente per l'alta disponibilità.
Per farlo funzionare, avrai bisogno di diversi strumenti/servizi che ti aiutino in questo compito.
Bilanciatori di carico
I bilanciatori di carico sono strumenti che possono essere utilizzati per gestire il traffico dalla tua applicazione per ottenere il massimo dall'architettura del tuo database.
Non solo è utile per bilanciare il carico dei nostri database, ma aiuta anche le applicazioni a essere reindirizzate ai nodi disponibili/integri e persino a specificare porte con ruoli diversi.
HAProxy è un sistema di bilanciamento del carico che distribuisce il traffico da un'origine a una o più destinazioni e può definire regole e/o protocolli specifici per questa attività. Se una qualsiasi delle destinazioni smette di rispondere, viene contrassegnata come offline e il traffico viene inviato alle altre destinazioni disponibili.
Keepalived è un servizio che consente di configurare un IP virtuale all'interno di un gruppo di server attivo/passivo. Questo IP virtuale è assegnato a un server attivo. Se questo server si guasta, l'IP viene automaticamente migrato sul server passivo "Secondario", consentendogli di continuare a lavorare con lo stesso IP in modo trasparente per i sistemi.
Per implementare tutte queste cose puoi farlo manualmente, il che significherà lavoro extra e attività che richiedono tempo, oppure puoi farlo da un solo sistema utilizzando ClusterControl.
Vediamo come importare la tua distribuzione Percona esistente per PostgreSQL in ClusterControl, quindi come configurare un ambiente ad alta disponibilità utilizzando HAProxy e Keepalived attorno a questa configurazione da un'interfaccia intuitiva e facile da usare.
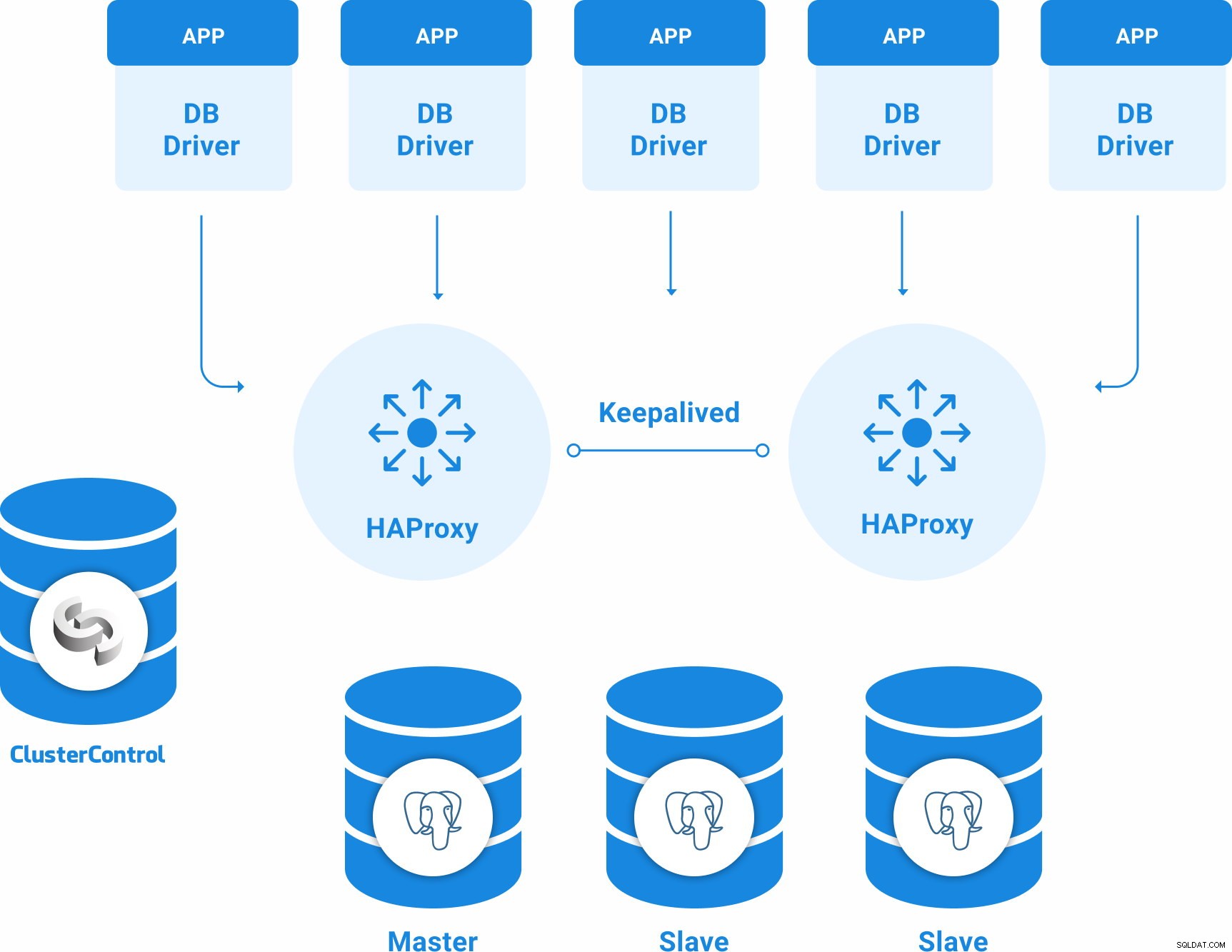
Topologia PostgreSQL per alta disponibilità
Una topologia di base ad alta disponibilità per PostgreSQL può essere:
- 3 server PostgreSQL 12 (un nodo primario e due in standby).
- 2 bilanciatori di carico HAProxy.
- Mantenuto configurato tra i server del servizio di bilanciamento del carico.
- 1 server ClusterControl
Quindi, avrai la seguente topologia:
Come installare Percona Distribution per PostgreSQL
Iniziamo con l'installazione di Percona Distribution per PostgreSQL. Per questo esempio useremo CentOS 7 e PostgreSQL 12.
Se hai installato il tuo cluster, vai alla sezione successiva per importare il tuo database esistente in ClusterControl.
Installa epel-release e percona-release
$ yum install epel-release
$ yum install https://repo.percona.com/yum/percona-release-latest.noarch.rpmAbilita il repository PostgreSQL 12
$ percona-release setup ppg-12
* Disabling all Percona Repositories
* Enabling the Percona Distribution for PostgreSQL 12 repository
<*> All done!Installa il pacchetto server
$ yum install percona-postgresql12-serverNota che questo pacchetto non installerà tutti i componenti di Percona Distribution. Per installare questi componenti, utilizzare i pacchetti opzionali appropriati come mostrato di seguito:
$ yum install percona-pg_repack12
$ yum install percona-pgaudit
$ yum install percona-pgbackrest
$ yum install percona-patroni
$ yum install percona-pg-stat-monitor12
$ yum install percona-postgresql12-contribInizializza il database
$ /usr/pgsql-12/bin/postgresql-12-setup initdb
Initializing database ... OKAssicurati di avere la configurazione corretta per poter configurare una replica PostgreSQL, simile a:
$ vi /var/lib/pgsql/12/data/postgresql.conf
listen_addresses = '*'
wal_level=logical
max_wal_senders = 16
wal_keep_segments = 32
hot_standby = onQuindi, avvia il servizio di database
$ systemctl start postgresql-12Ora, se vuoi aggiungere nodi in standby, ripeti i passaggi 1, 2 e 3 in tutti i nodi che vuoi aggiungere al cluster. Per quei nodi, non è necessario configurare nient'altro poiché ClusterControl creerà la configurazione corrispondente.
Importazione della distribuzione Percona per PostgreSQL in ClusterControl
Con ClusterControl puoi distribuire o importare diversi motori di database open source dallo stesso sistema e per usarlo sono necessari solo l'accesso SSH e un utente privilegiato.
Vai alla sezione "Importa" e completa le informazioni richieste del tuo server PostgreSQL.
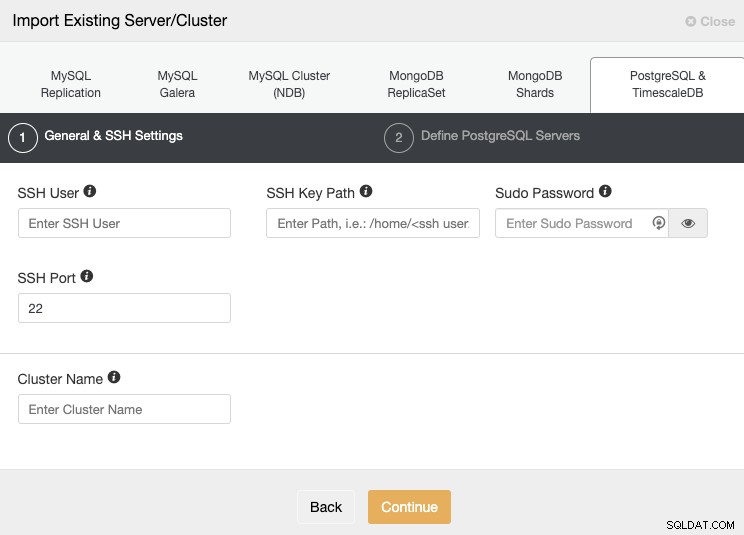
È necessario specificare Utente, Chiave o Password e porta per connettersi tramite SSH ai tuoi server. Hai anche bisogno di un nome per il tuo nuovo cluster, altrimenti ClusterControl te ne assegnerà uno generico.
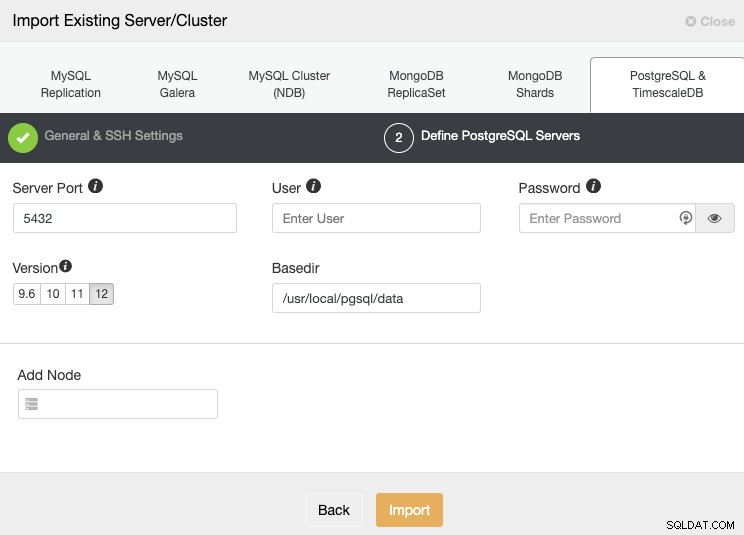
Dopo aver impostato le informazioni di accesso SSH, è necessario definire le credenziali del database, version, basedir e l'indirizzo IP o il nome host per ciascun nodo del database.
Se non hai ancora configurato la replica, devi solo aggiungere l'indirizzo IP o il nome host per il nodo primario, poiché ti mostreremo come aggiungere il resto dei nodi in seguito.
Assicurati di avere il segno di spunta verde quando inserisci il nome host o l'indirizzo IP, a indicare che ClusterControl è in grado di comunicare con il nodo. Quindi fare clic sul pulsante Importa e attendere che ClusterControl termini il proprio lavoro. È possibile monitorare il processo nella sezione Attività ClusterControl. Al termine, vedrai il nuovo cluster nella schermata principale di ClusterControl. Per aggiungere una nuova replica, vai alle azioni del cluster e seleziona l'opzione "Aggiungi slave di replica".
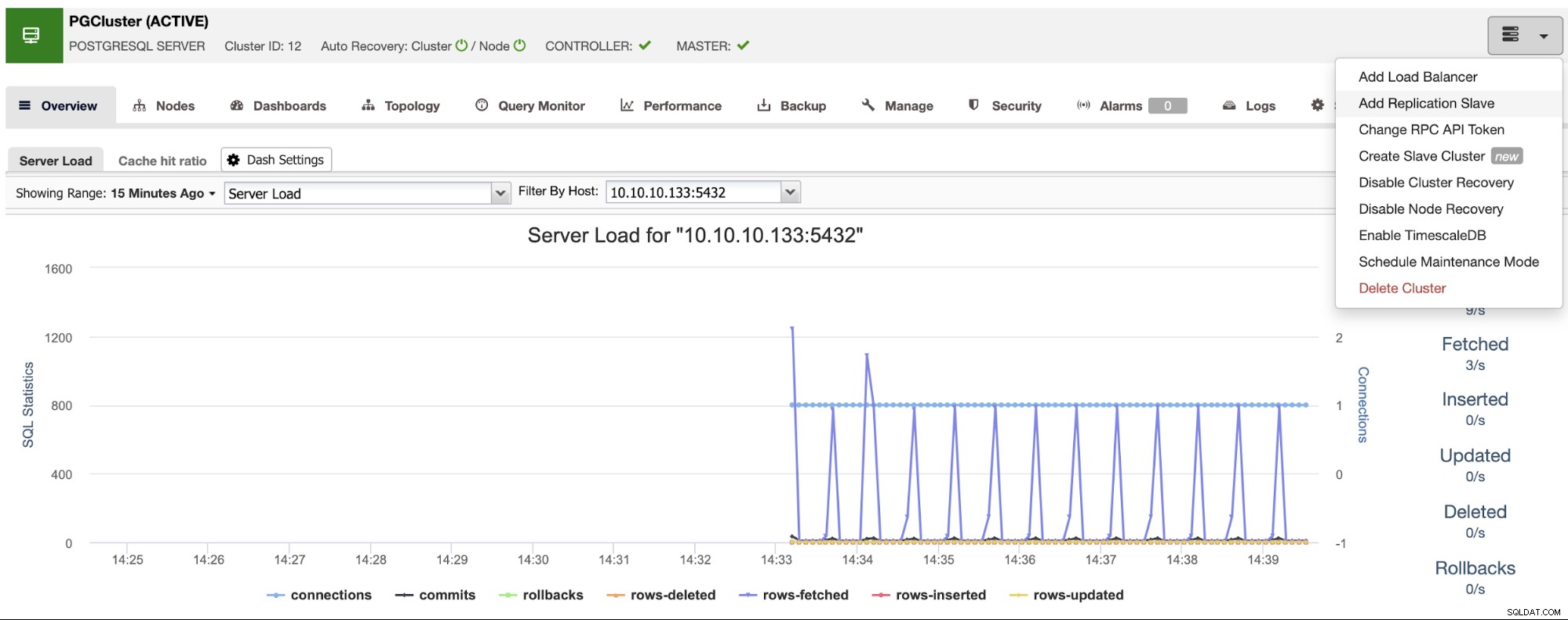
Se hai seguito i passaggi precedenti, avrai installato Percona Distribution for PostgreSQL in tutti i nodi di standby, quindi è necessario disabilitare il "Installa software PostgreSQL" in questa sezione.
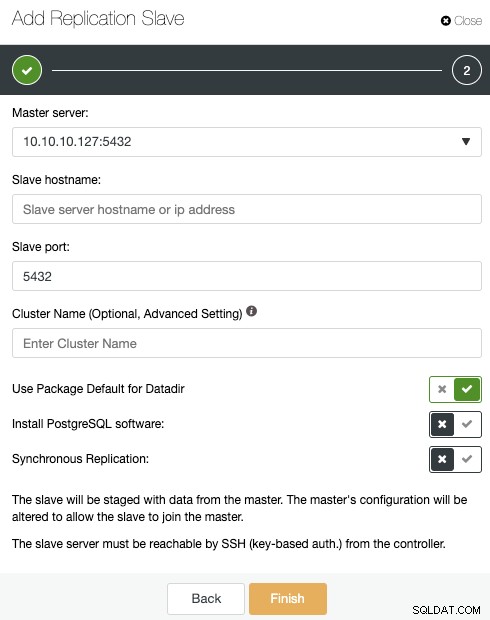
In questo modo, ClusterControl utilizzerà invece la distribuzione Percona installata per i pacchetti PostgreSQL di installare i pacchetti PostgreSQL ufficiali.
Al termine, vedrai tutti i nodi nel cluster e lo stato di tutti loro nella sezione panoramica.
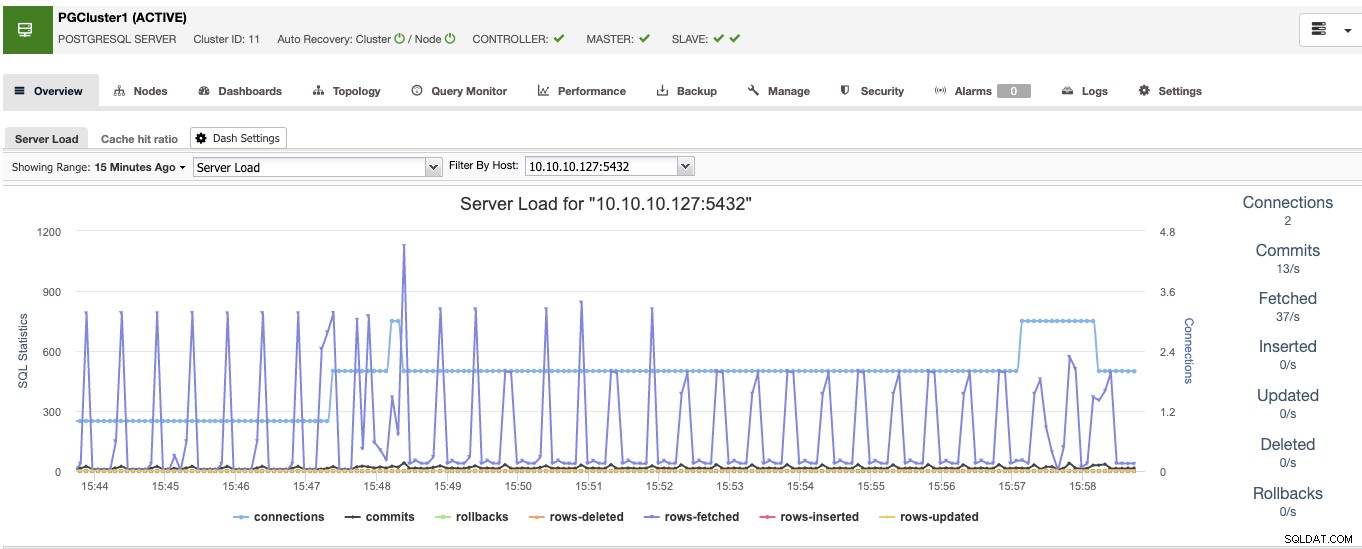
Ora hai il lato database pronto, vediamo come completare l'High Ambiente di disponibilità aggiungendo il resto degli strumenti utilizzando ClusterControl.
Distribuzione del sistema di bilanciamento del carico
Per eseguire una distribuzione del sistema di bilanciamento del carico, seleziona l'opzione "Aggiungi Load Balancer" nelle azioni del cluster e inserisci le informazioni richieste. 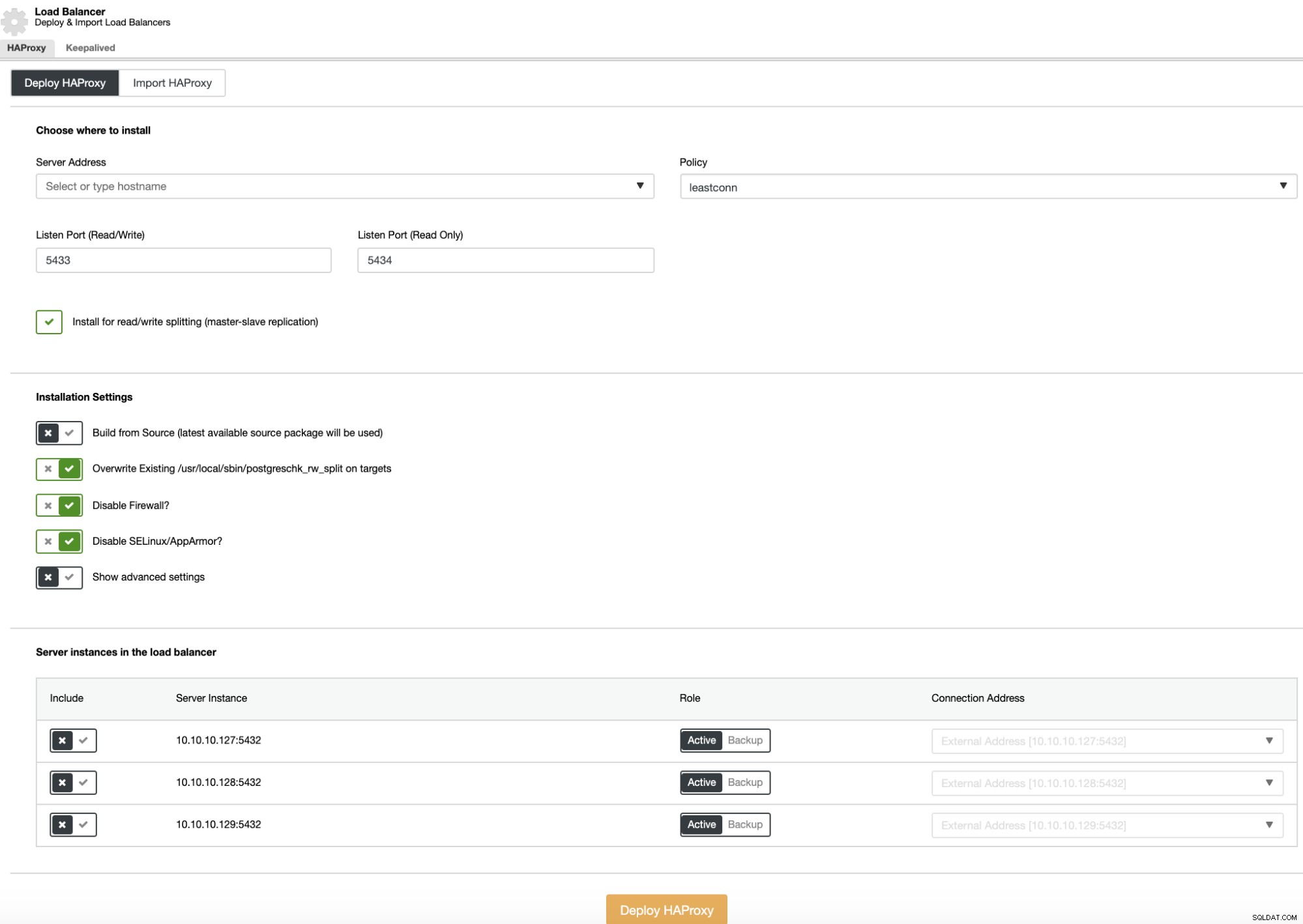
Devi solo aggiungere l'indirizzo IP o il nome host, la porta, la policy e i nodi che intendi aggiungere alla configurazione del sistema di bilanciamento del carico.
Distribuzione mantenuta
Per eseguire una distribuzione Keepalived, seleziona il cluster, vai alle azioni del cluster, seleziona "Aggiungi Load Balancer", quindi vai alla sezione "Keepalived".
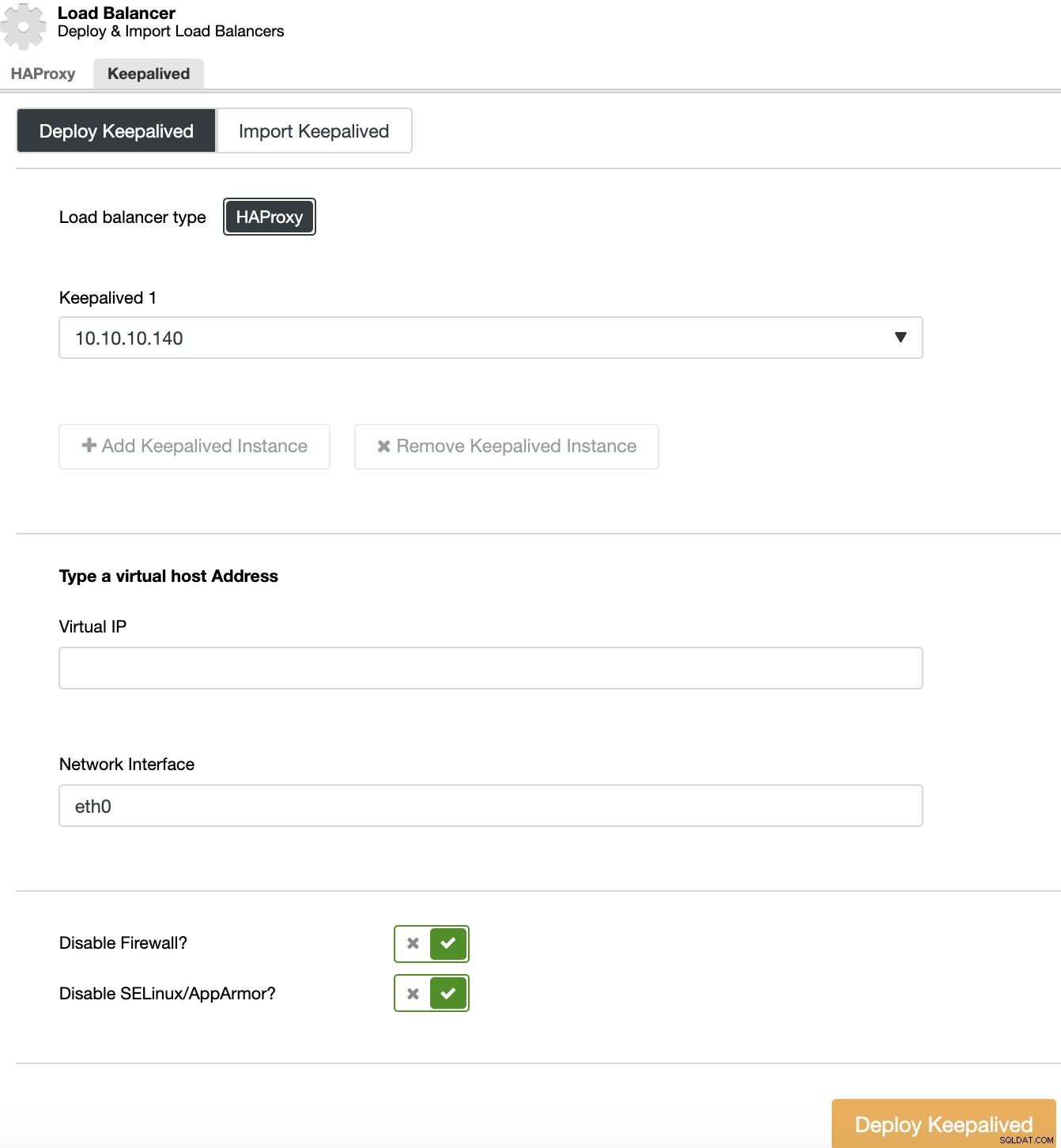
Per il tuo ambiente ad alta disponibilità, devi selezionare i server di bilanciamento del carico e l'indirizzo IP virtuale, che dovrai utilizzare per accedere al tuo cluster. Keepalived configura questo IP virtuale nel servizio di bilanciamento del carico attivo e lo migra da un sistema di bilanciamento del carico all'altro in caso di errore, in modo che la tua configurazione possa continuare a funzionare normalmente.
Conclusione
Poiché non puoi ancora distribuire Percona Distribution per PostgreSQL direttamente da ClusterControl, in questo blog ti abbiamo mostrato come gestirlo utilizzando ClusterControl e come aggiungere diversi strumenti come HAProxy e Keepalived per avere un ambiente ad alta disponibilità in atto in modo semplice.



