Qualche settimana fa ho scritto di quanto fossi sorpreso dalle prestazioni di una nuova funzione nativa in SQL Server 2016, STRING_SPLIT() :
- Sorprese e presupposti sulle prestazioni:STRING_SPLIT()
Dopo la pubblicazione del post, ho ricevuto alcuni commenti (pubblicamente e privatamente) con questi suggerimenti (o domande che ho trasformato in suggerimenti):
- Specificare un tipo di dati di output esplicito per l'approccio JSON, in modo che tale metodo non subisca un potenziale sovraccarico delle prestazioni dovuto al fallback di
nvarchar(max). - Testare un approccio leggermente diverso, in cui qualcosa viene effettivamente fatto con i dati, ovvero
SELECT INTO #temp. - Mostra il confronto tra il conteggio delle righe stimato e i metodi esistenti, in particolare durante la nidificazione di operazioni di divisione.
Ho risposto ad alcune persone offline, ma ho pensato che sarebbe valsa la pena pubblicare un follow-up qui.
Essere più equi con JSON
La funzione JSON originale era simile a questa, senza alcuna specifica per il tipo di dati di output:
CREATE FUNCTION dbo.SplitStrings_JSON
...
RETURN (SELECT value FROM OPENJSON( CHAR(91) + @List + CHAR(93) )); L'ho rinominato e ne ho creati altri due, con le seguenti definizioni:
CREATE FUNCTION dbo.SplitStrings_JSON_int
...
RETURN (SELECT value FROM OPENJSON( CHAR(91) + @List + CHAR(93) )
WITH ([value] int '$'));
GO
CREATE FUNCTION dbo.SplitStrings_JSON_varchar
...
RETURN (SELECT value FROM OPENJSON( CHAR(91) + @List + CHAR(93) )
WITH ([value] varchar(100) '$')); Pensavo che questo avrebbe migliorato drasticamente le prestazioni, ma purtroppo non era così. Ho eseguito nuovamente i test e i risultati sono stati i seguenti:
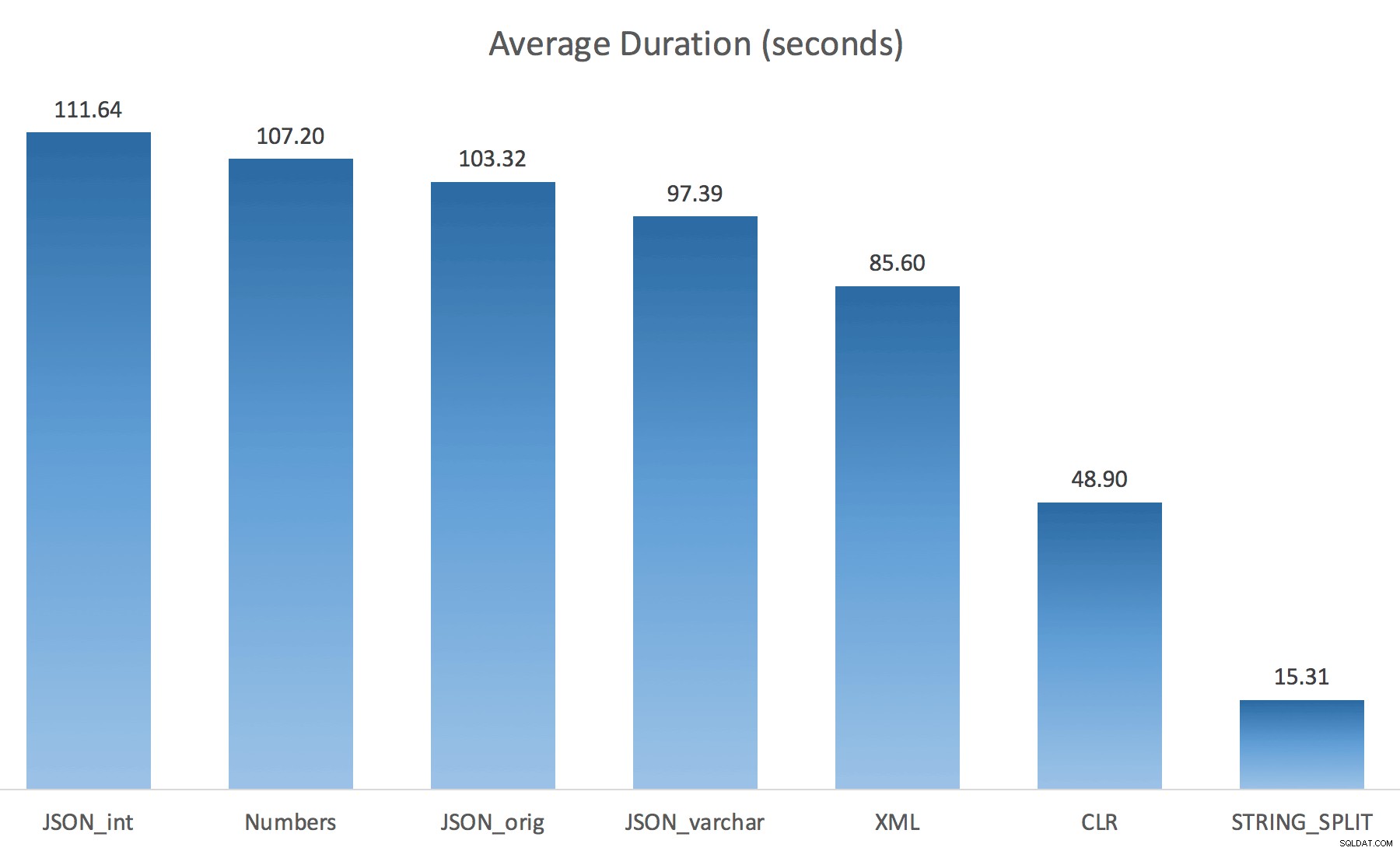
Le attese osservate durante un'istanza casuale del test (filtrate a quelle> 25):
| CLR | IO_COMPLETION | 1.595 |
| SOS_SCHEDULER_YIELD | 76 | |
| RESERVED_MEMORY_ALLOCATION_EXT | 76 | |
| MEMORY_ALLOCATION_EXT | 28 | |
| JSON_int | MEMORY_ALLOCATION_EXT | 6.294 |
| SOS_SCHEDULER_YIELD | 95 | |
| JSON_original | MEMORY_ALLOCATION_EXT | 4.307 |
| SOS_SCHEDULER_YIELD | 83 | |
| JSON_varchar | MEMORY_ALLOCATION_EXT | 6.110 |
| SOS_SCHEDULER_YIELD | 87 | |
| Numeri | SOS_SCHEDULER_YIELD | 96 |
| XML | MEMORY_ALLOCATION_EXT | 1.917 |
| IO_COMPLETION | 1.616 | |
| SOS_SCHEDULER_YIELD | 147 | |
| RESERVED_MEMORY_ALLOCATION_EXT | 73 |
Attese osservate> 25 (nota che non ci sono voci per STRING_SPLIT )
Durante il passaggio dall'impostazione predefinita a varchar(100) ha migliorato leggermente le prestazioni, il guadagno è stato trascurabile e il passaggio a int anzi ha peggiorato le cose. Aggiungi a questo che probabilmente devi aggiungere STRING_ESCAPE() alla stringa in entrata in alcuni scenari, nel caso in cui abbiano caratteri che incasinano l'analisi JSON. La mia conclusione è ancora che questo è un modo accurato per utilizzare la nuova funzionalità JSON, ma soprattutto una novità inappropriata per una scala ragionevole.
Materializzare l'output
Jonathan Magnan ha fatto questa astuta osservazione nel mio post precedente:
STRING_SPLIT è davvero molto veloce, tuttavia anche lento quando si lavora con la tabella temporanea (a meno che non venga risolto in una build futura).SELECT f.value INTO #test FROM dbo.SourceTable AS s CROSS APPLY string_split(s.StringValue, ',') AS f
Sarà MOLTO più lento della soluzione SQL CLR (15 volte e più!).
Quindi, ho scavato. Ho creato un codice che avrebbe chiamato ciascuna delle mie funzioni e scaricato i risultati in una tabella #temp e cronometrandoli:
SET NOCOUNT ON; SELECT N'SET NOCOUNT ON; TRUNCATE TABLE dbo.Timings; GO '; SELECT N'DECLARE @d DATETIME = SYSDATETIME(); INSERT dbo.Timings(dt, test, point, wait_type, wait_time_ms) SELECT @d, test = ''' + name + ''', point = ''Start'', wait_type, wait_time_ms FROM sys.dm_exec_session_wait_stats WHERE session_id = @@SPID; GO SELECT f.value INTO #test FROM dbo.SourceTable AS s CROSS APPLY dbo.'+name+'(s.StringValue, '','') AS f; GO DECLARE @d DATETIME = SYSDATETIME(); INSERT dbo.Timings(dt, test, point, wait_type, wait_time_ms) SELECT @d, '''+name+''', ''End'', wait_type, wait_time_ms FROM sys.dm_exec_session_wait_stats WHERE session_id = @@SPID; DROP TABLE #test; GO' FROM sys.objects WHERE name LIKE '%split%';
Ho eseguito ogni test una volta (anziché ripetere il ciclo 100 volte), perché non volevo rovinare completamente l'I/O sul mio sistema. Tuttavia, dopo aver ottenuto una media di tre test, Jonathan aveva assolutamente ragione al 100%. Ecco le durate di compilazione di una tabella #temp con circa 500.000 righe utilizzando ciascun metodo:
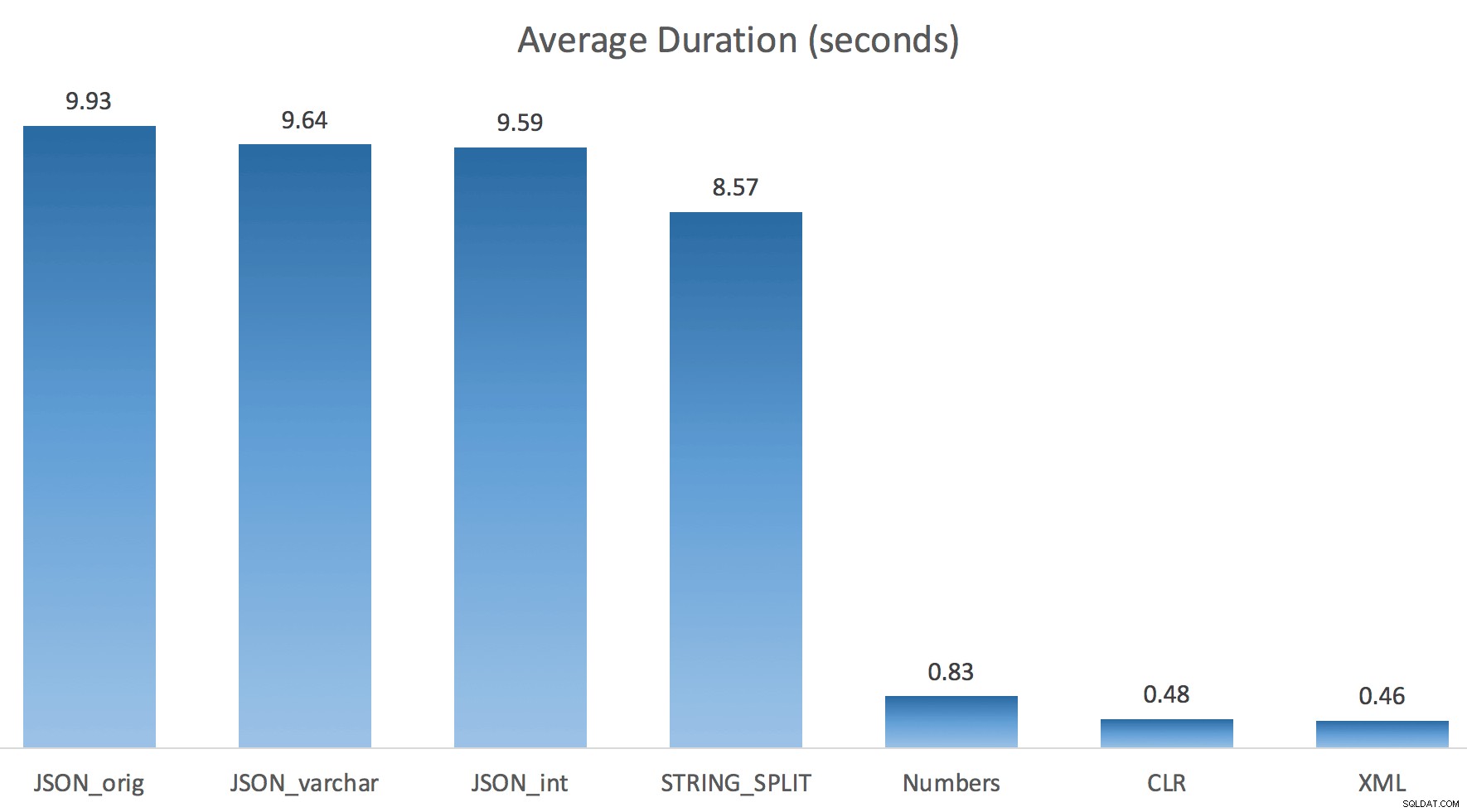
Quindi qui, JSON e STRING_SPLIT i metodi hanno richiesto circa 10 secondi ciascuno, mentre gli approcci tabella di Numbers, CLR e XML hanno richiesto meno di un secondo. Perplesso, ho studiato le attese e, in effetti, i quattro metodi a sinistra hanno riscontrato un significativo LATCH_EX attese (circa 25 secondi) non viste negli altri tre, e non c'erano altre attese significative di cui parlare.
E poiché le attese di latch erano maggiori della durata totale, mi ha dato un indizio che ciò avesse a che fare con il parallelismo (questa macchina particolare ha 4 core). Quindi ho generato di nuovo il codice di test, modificando solo una riga per vedere cosa sarebbe successo senza parallelismo:
CROSS APPLY dbo.'+name+'(s.StringValue, '','') AS f OPTION (MAXDOP 1);
Ora STRING_SPLIT è andata molto meglio (come hanno fatto i metodi JSON), ma comunque almeno il doppio del tempo impiegato da CLR:
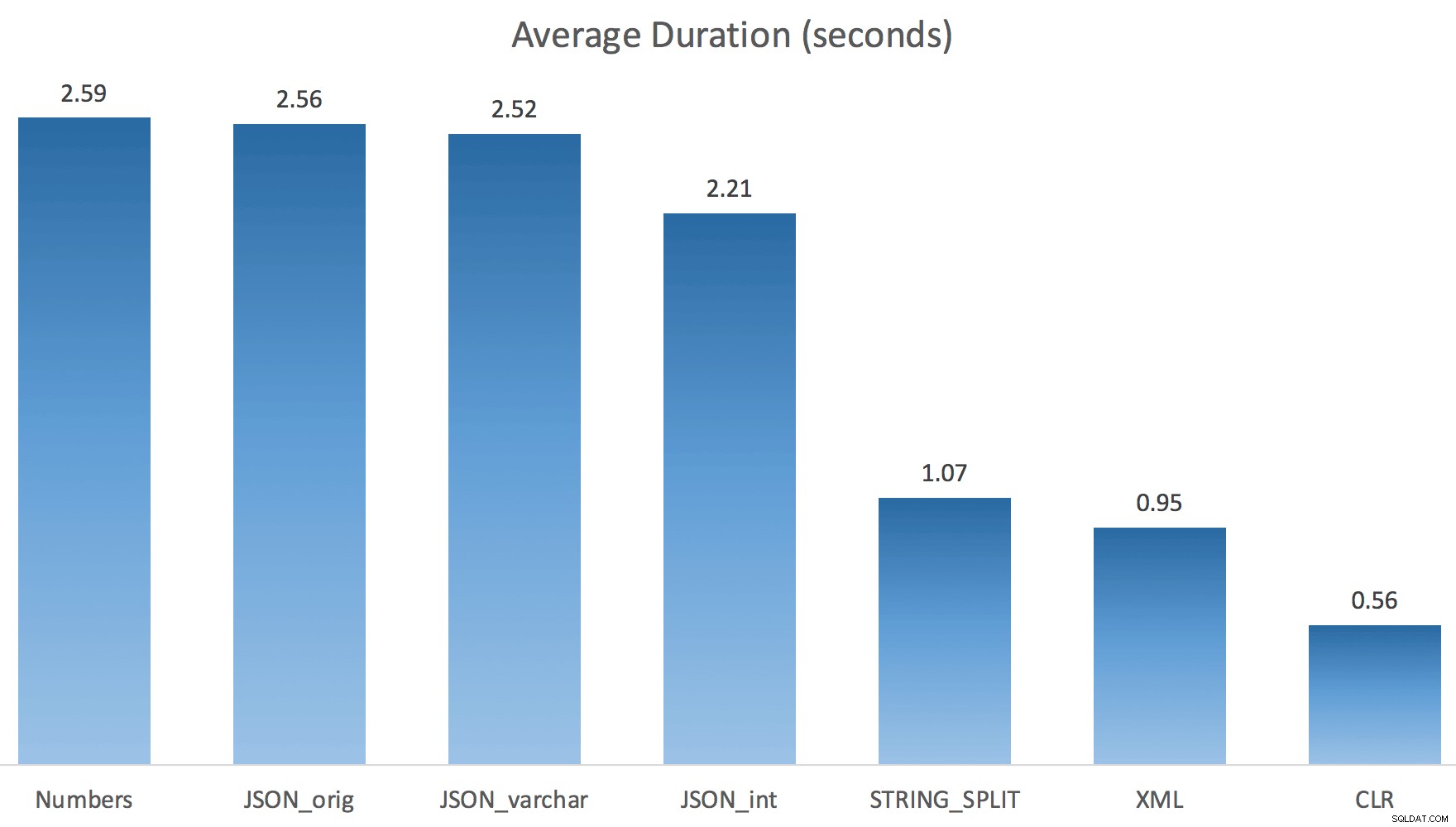
Quindi, potrebbe esserci un problema rimanente in questi nuovi metodi quando è coinvolto il parallelismo. Non era un problema di distribuzione dei thread (l'ho verificato) e CLR in realtà aveva stime peggiori (100 volte effettive rispetto a solo 5 volte per STRING_SPLIT ); solo qualche problema di fondo con il coordinamento dei fermi tra i thread suppongo. Per ora, potrebbe essere utile usare MAXDOP 1 se sai che stai scrivendo l'output su nuove pagine.
Ho incluso i piani grafici confrontando l'approccio CLR con quello nativo, sia per l'esecuzione parallela che seriale (ho anche caricato un file di analisi delle query che puoi aprire in SQL Sentry Plan Explorer per curiosare da solo):
STRING_SPLIT
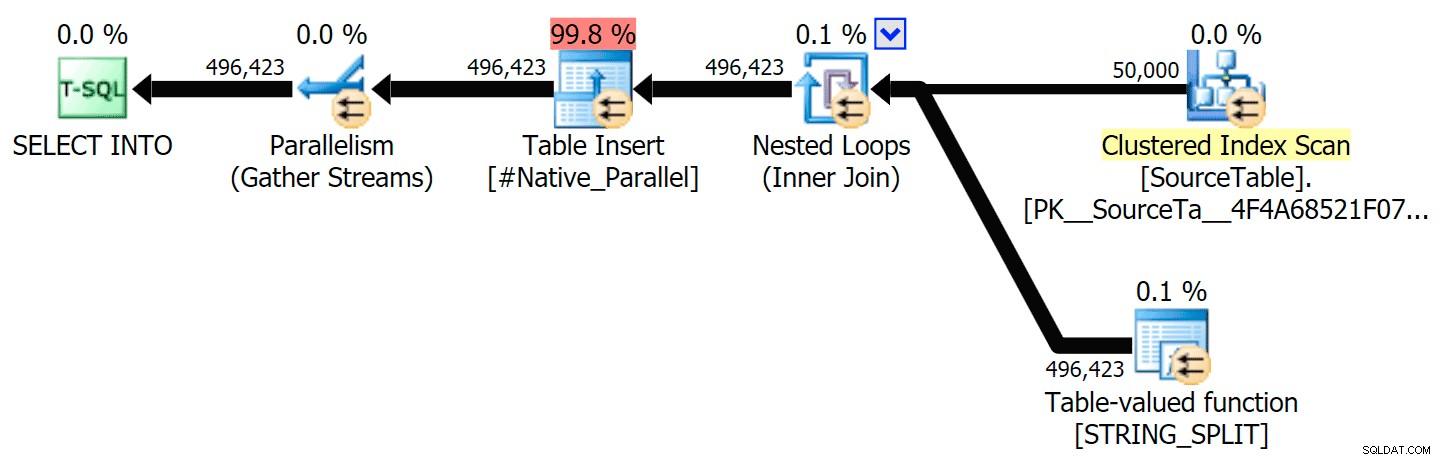
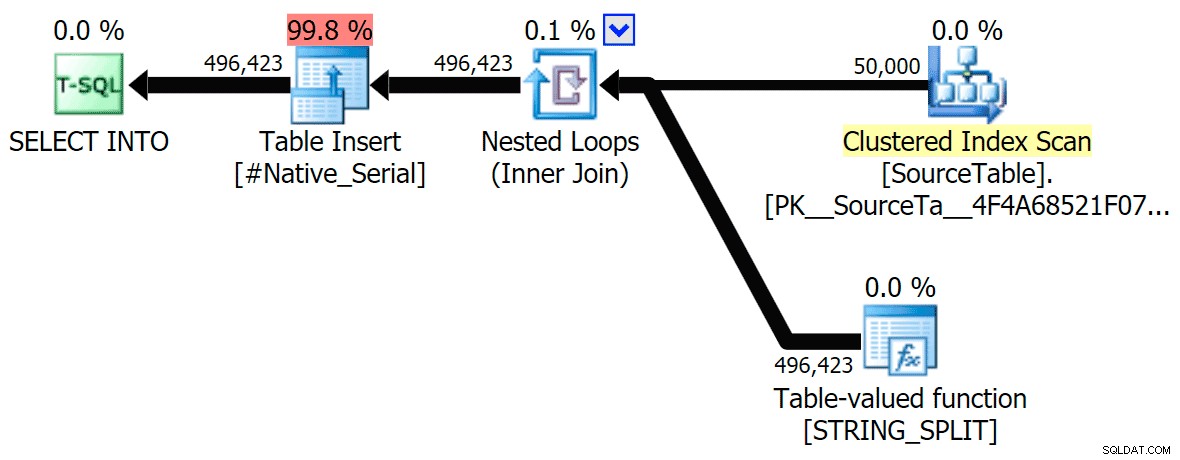
CLR
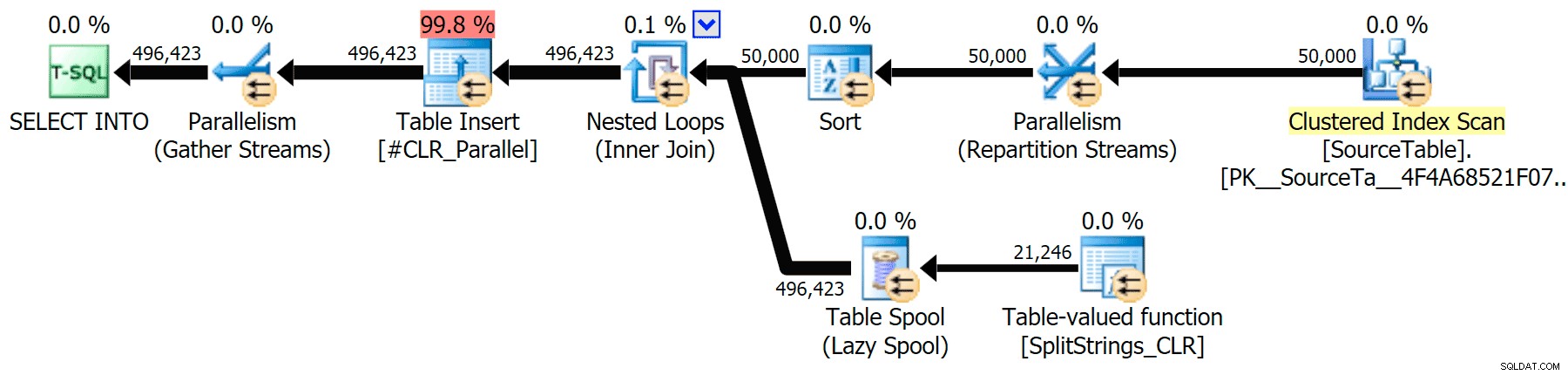
L'avviso di ordinamento, per tua informazione, non è stato niente di troppo scioccante e ovviamente non ha avuto effetti tangibili sulla durata della query:

- StringSplit.queryanalysis.zip (25kb)
Spool fuori per l'estate
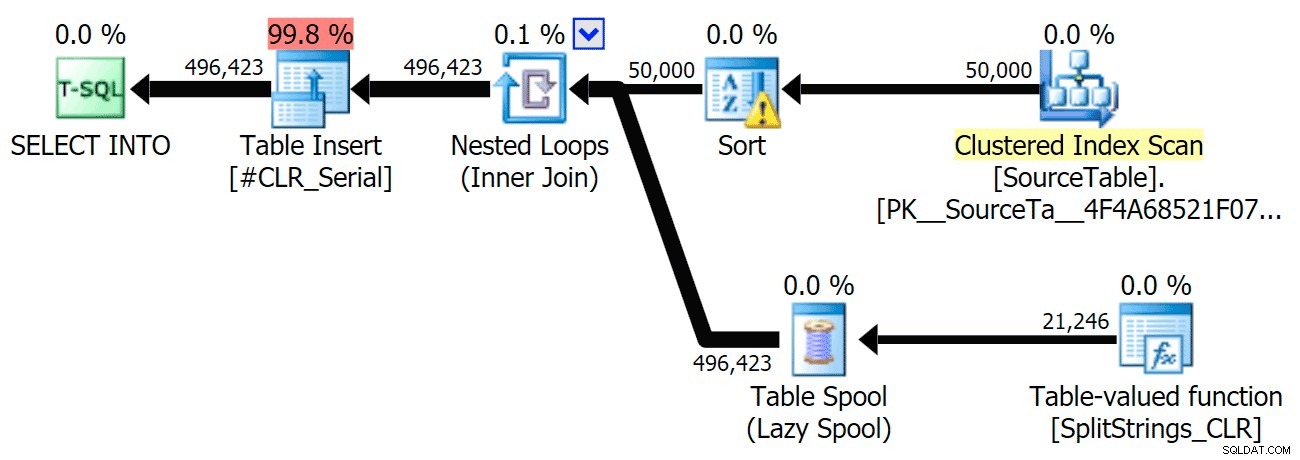
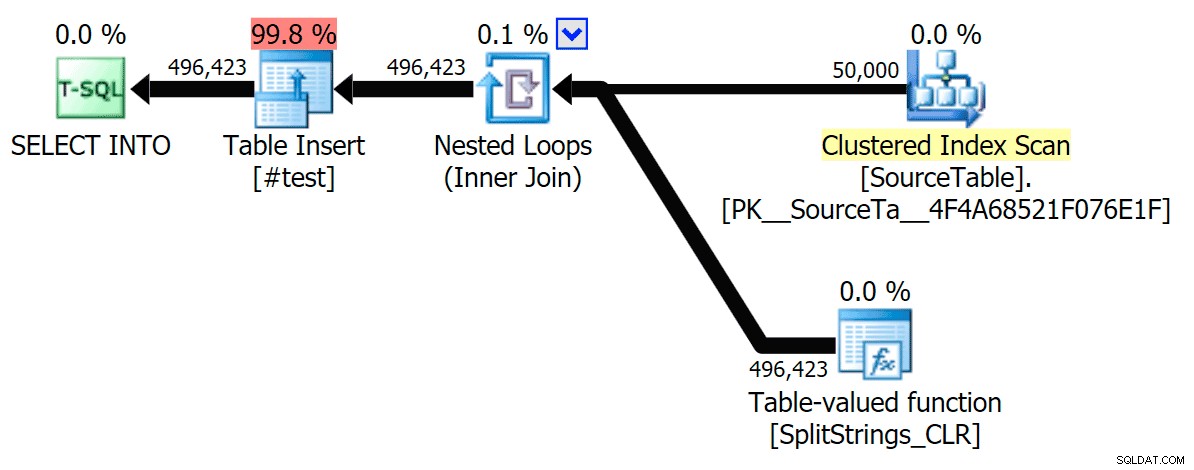
Quando ho guardato un po' più da vicino quei piani, ho notato che nel piano CLR c'è una bobina pigra. Questo è stato introdotto per assicurarsi che i duplicati vengano elaborati insieme (per risparmiare lavoro eseguendo una divisione meno effettiva), ma questo spool non è sempre possibile in tutte le forme del piano e può dare un po' di vantaggio a coloro che possono usarlo ( es. il piano CLR), a seconda delle stime. Per confrontare senza spool, ho abilitato il flag di traccia 8690 ed ho eseguito di nuovo i test. Innanzitutto, ecco il piano CLR parallelo senza lo spool:
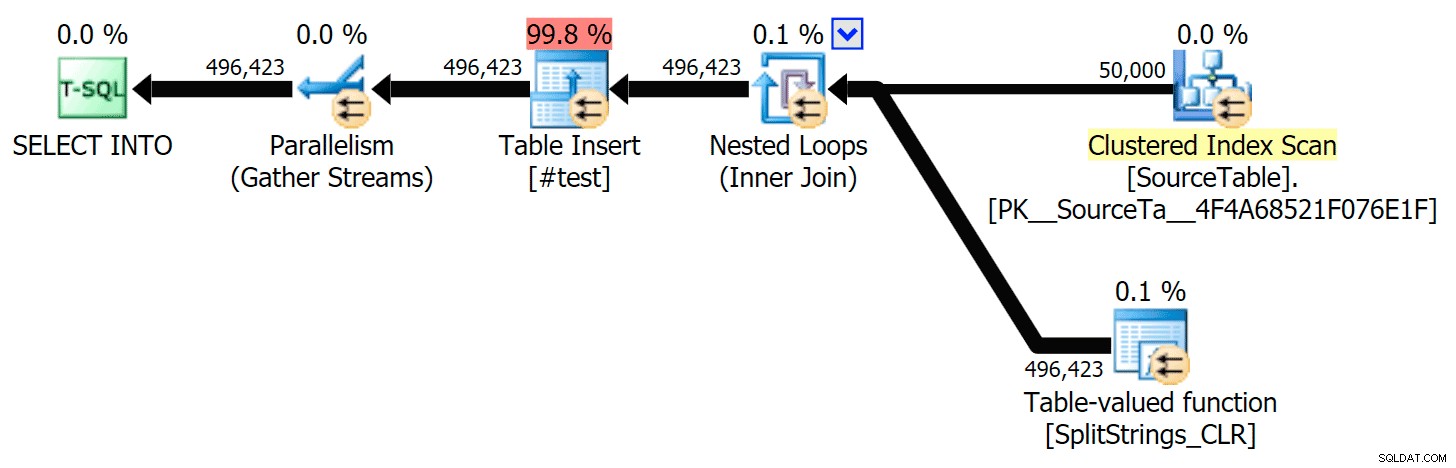
Ed ecco le nuove durate per tutte le query che vanno in parallelo con TF 8690 abilitato:
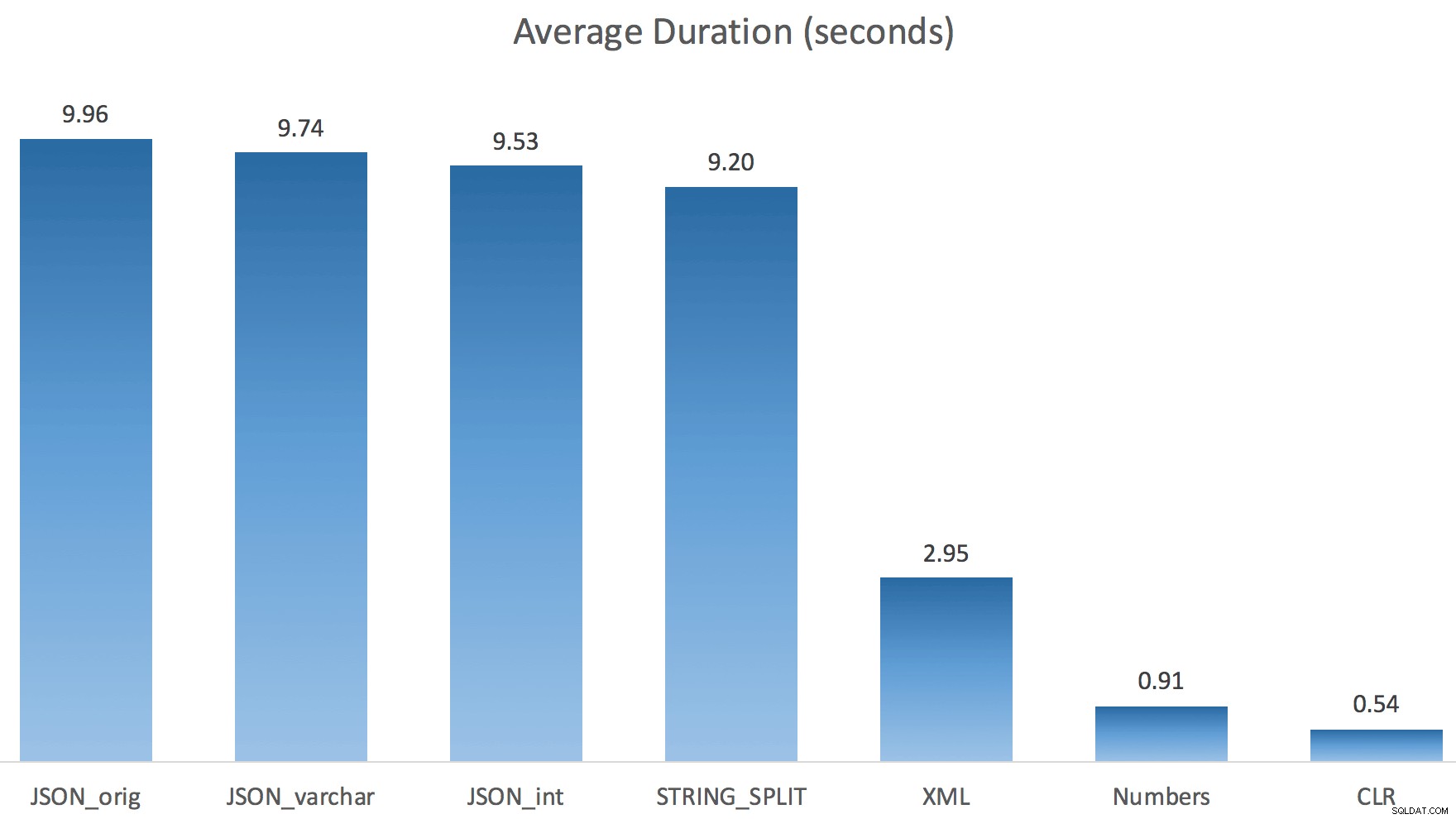
Ora, ecco il piano CLR seriale senza lo spool:
Ed ecco i risultati temporali per le query che utilizzano sia TF 8690 che MAXDOP 1 :
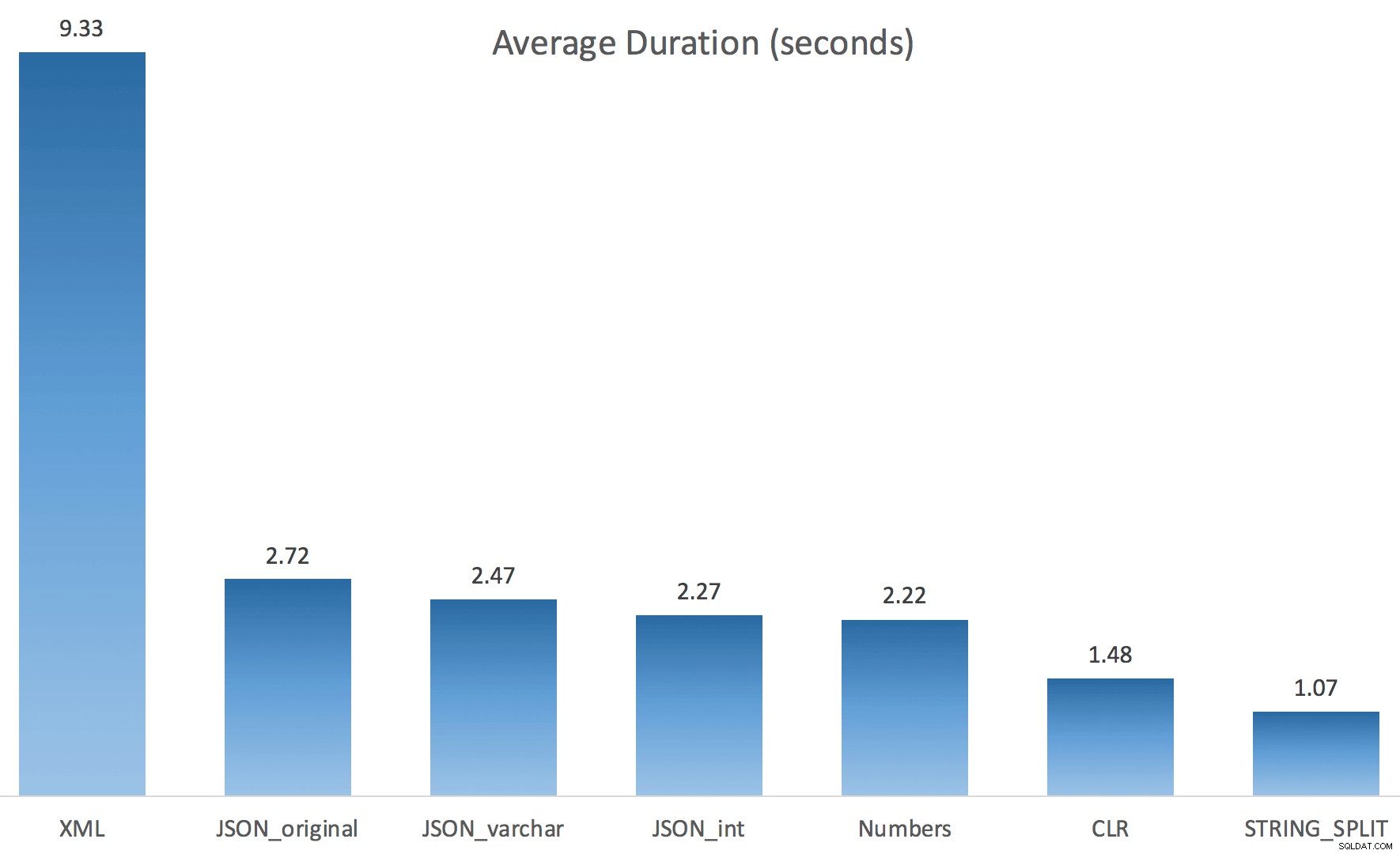
(Nota che, a parte il piano XML, la maggior parte degli altri non è cambiata affatto, con o senza il flag di traccia.)
Confronto del numero di righe stimato
Dan Holmes ha posto la seguente domanda:
In che modo stima la dimensione dei dati quando è unito a un'altra (o multipla) funzione di divisione? Il collegamento seguente è un riassunto di un'implementazione divisa basata su CLR. Il 2016 fa un lavoro "migliore" con le stime dei dati? (purtroppo non ho ancora la possibilità di installare RC).https://sql.dnhlms.com/2016/02/sql-clr-based-string-splitting-and. html
Quindi, ho fatto scorrere il codice dal post di Dan, l'ho modificato per utilizzare le mie funzioni e l'ho eseguito tramite Plan Explorer:
DECLARE @s VARCHAR(MAX); SELECT * FROM dbo.SplitStrings_CLR(@s, ',') s CROSS APPLY dbo.SplitStrings_CLR(s.value, ';') s1 CROSS APPLY dbo.SplitStrings_CLR(s1.value, '!') s2 CROSS APPLY dbo.SplitStrings_CLR(s2.value, '#') s3; SELECT * FROM dbo.SplitStrings_Numbers(@s, ',') s CROSS APPLY dbo.SplitStrings_Numbers(s.value, ';') s1 CROSS APPLY dbo.SplitStrings_Numbers(s1.value, '!') s2 CROSS APPLY dbo.SplitStrings_Numbers(s2.value, '#') s3; SELECT * FROM dbo.SplitStrings_Native(@s, ',') s CROSS APPLY dbo.SplitStrings_Native(s.value, ';') s1 CROSS APPLY dbo.SplitStrings_Native(s1.value, '!') s2 CROSS APPLY dbo.SplitStrings_Native(s2.value, '#') s3;
Il SPLIT_STRING l'approccio sicuramente fornisce stime *migliori* rispetto a CLR, ma ancora grossolanamente superate (in questo caso, quando la stringa è vuota; questo potrebbe non essere sempre il caso). La funzione ha un default integrato che stima che la stringa in entrata avrà 50 elementi, quindi quando li annidi ottieni 50 x 50 (2.500); se li annidi di nuovo, 50 x 2.500 (125.000); e infine 50 x 125.000 (6.250.000):
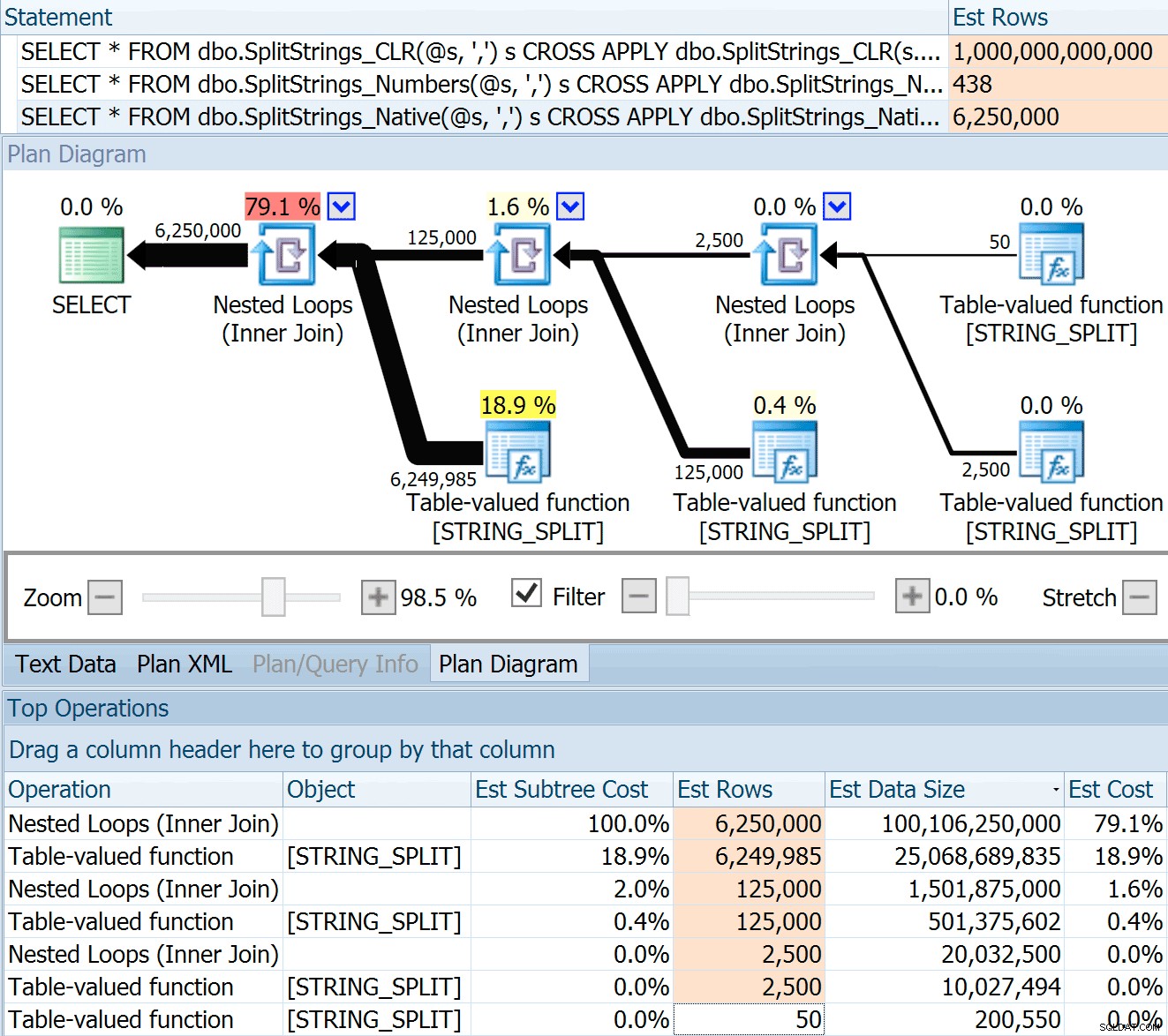
Nota:OPENJSON() si comporta esattamente allo stesso modo di STRING_SPLIT – anch'esso presuppone che 50 righe usciranno da una determinata operazione di divisione. Penso che potrebbe essere utile avere un modo per suggerire la cardinalità per funzioni come questa, oltre a flag di traccia come 4137 (pre-2014), 9471 e 9472 (2014+) e ovviamente 9481...
Questa stima di 6,25 milioni di righe non è eccezionale, ma è molto migliore dell'approccio CLR di cui parlava Dan, che stima TRIMILIONI DI RIGHE e ho perso il conteggio delle virgole per determinare la dimensione dei dati:16 petabyte? exabyte?
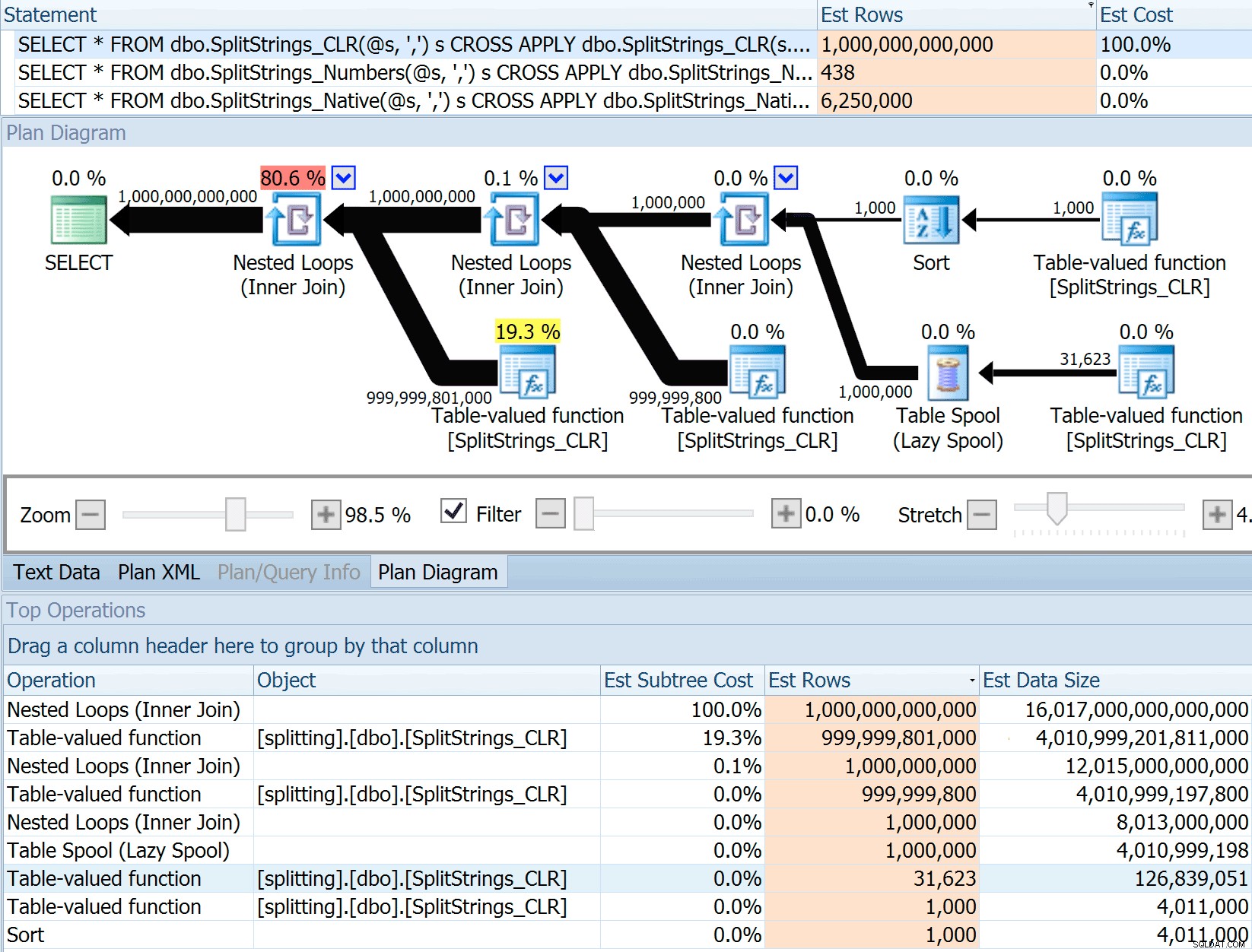
Alcuni degli altri approcci ovviamente vanno meglio in termini di stime. La tabella Numbers, ad esempio, stimava 438 righe molto più ragionevoli (in SQL Server 2016 RC2). Da dove viene questo numero? Bene, ci sono 8.000 righe nella tabella e, se ricordi, la funzione ha sia un predicato di uguaglianza che di disuguaglianza:
WHERE Number <= LEN(@List)
AND SUBSTRING(@Delimiter + @List, [Number], 1) = @Delimiter Quindi, SQL Server moltiplica il numero di righe nella tabella del 10% (a titolo indicativo) per il filtro di uguaglianza, quindi la radice quadrata del 30% (di nuovo, un'ipotesi) per il filtro di disuguaglianza. La radice quadrata è dovuta al backoff esponenziale, che Paul White spiega qui. Questo ci dà:
8000 * 0,1 * SQRT(0,3) =438,178La variazione XML stimava poco più di un miliardo di righe (a causa di uno spooling di tabella stimato in 5,8 milioni di volte), ma il suo piano era troppo complesso per essere illustrato qui. In ogni caso, ricorda che le stime chiaramente non raccontano l'intera storia:solo perché una query ha stime più accurate non significa che avrà prestazioni migliori.
C'erano alcuni altri modi in cui potevo modificare un po' le stime:vale a dire, forzando il vecchio modello di stima della cardinalità (che influiva sia sull'XML che sulle variazioni della tabella di Numbers) e usando TF 9471 e 9472 (che influiva solo sulla variazione della tabella di Numbers, dal momento che entrambi controllano la cardinalità attorno a più predicati). Ecco i modi in cui potevo modificare un po' le stime (o MOLTO , in caso di ripristino del vecchio modello CE):

Il vecchio modello CE ha ridotto le stime XML di un ordine di grandezza, ma per la tabella dei numeri l'ha completamente fatta esplodere. I flag dei predicati hanno alterato le stime per la tabella dei numeri, ma queste modifiche sono molto meno interessanti.
Nessuno di questi flag di traccia ha avuto alcun effetto sulle stime per CLR, JSON o STRING_SPLIT variazioni.
Conclusione
Allora cosa ho imparato qui? Un intero gruppo, in realtà:
- Il parallelismo può aiutare in alcuni casi, ma quando non aiuta, davvero non aiuta. I metodi JSON erano circa 5 volte più veloci senza parallelismo e
STRING_SPLITera quasi 10 volte più veloce. - La bobina ha effettivamente aiutato l'approccio CLR a funzionare meglio in questo caso, ma TF 8690 potrebbe essere utile per sperimentare in altri casi in cui vedi bobine e stai cercando di migliorare le prestazioni. Sono certo che ci sono situazioni in cui eliminare la bobina finirà per essere complessivamente migliore.
- L'eliminazione dello spool ha davvero danneggiato l'approccio XML (ma solo drasticamente quando è stato costretto a essere a thread singolo).
- Un sacco di cose strane possono accadere con le stime a seconda dell'approccio, insieme alle solite statistiche, distribuzione e flag di traccia. Bene, suppongo di averlo già saputo, ma qui ci sono sicuramente un paio di esempi buoni e tangibili.
Grazie alle persone che hanno posto domande o mi hanno spinto a includere ulteriori informazioni. E come avrai intuito dal titolo, rivolgo un'altra domanda in un secondo follow-up, questa sulle TVP:
- STRING_SPLIT() in SQL Server 2016:follow-up n. 2



