I dati sono probabilmente una delle risorse più preziose di un'azienda. Per questo motivo dovremmo sempre avere un Disaster Recovery Plan (DRP) per prevenire la perdita di dati in caso di incidente o guasto dell'hardware.
Un backup è la forma più semplice di DR, tuttavia potrebbe non essere sempre sufficiente per garantire un Recovery Point Objective (RPO) accettabile. Si consiglia di avere almeno tre backup archiviati in luoghi fisici diversi.
La migliore pratica impone che i file di backup ne abbiano uno archiviato localmente sul server del database (per un ripristino più rapido), un altro in un server di backup centralizzato e l'ultimo nel cloud.
Per questo blog, daremo un'occhiata alle opzioni fornite da Amazon AWS per l'archiviazione dei backup di PostgreSQL nel cloud e mostreremo alcuni esempi su come farlo.
Informazioni su Amazon AWS
Amazon AWS è uno dei provider cloud più avanzati al mondo in termini di funzionalità e servizi, con milioni di clienti. Se vogliamo eseguire i nostri database PostgreSQL su Amazon AWS abbiamo alcune opzioni...
-
Amazon RDS:ci consente di creare, gestire e ridimensionare un database PostgreSQL (o diverse tecnologie di database) nel cloud in modo facile e veloce.
-
Amazon Aurora:è un database compatibile con PostgreSQL creato per il cloud. Secondo il sito Web di AWS, è tre volte più veloce dei database PostgreSQL standard.
-
Amazon EC2:è un servizio Web che fornisce capacità di calcolo ridimensionabile nel cloud. Ti fornisce il controllo completo delle tue risorse di elaborazione e ti consente di impostare e configurare tutto ciò che riguarda le tue istanze dal tuo sistema operativo fino alle tue applicazioni.
Ma, in effetti, non è necessario che i nostri database siano in esecuzione su Amazon per archiviare i nostri backup qui.
Memorizzazione dei backup su Amazon AWS
Ci sono diverse opzioni per archiviare il nostro backup PostgreSQL su AWS. Se eseguiamo il nostro database PostgreSQL su AWS abbiamo più opzioni e (dato che siamo nella stessa rete) potrebbe anche essere più veloce. Vediamo come AWS può aiutarci a archiviare i nostri backup.
AWS CLI
Per prima cosa, prepariamo il nostro ambiente per testare le diverse opzioni AWS. Per i nostri esempi, utilizzeremo un server PostgreSQL 11 in locale, in esecuzione su CentOS 7. Qui è necessario installare l'AWS CLI seguendo le istruzioni di questo sito.
Quando abbiamo installato la nostra AWS CLI, possiamo testarla dalla riga di comando:
[example@sqldat.com ~]# aws --version
aws-cli/1.16.225 Python/2.7.5 Linux/4.15.18-14-pve botocore/1.12.215Ora, il passaggio successivo consiste nel configurare il nostro nuovo client eseguendo il comando aws con l'opzione configure.
[example@sqldat.com ~]# aws configure
AWS Access Key ID [None]: AKIA7TMEO21BEBR1A7HR
AWS Secret Access Key [None]: SxrCECrW/RGaKh2FTYTyca7SsQGNUW4uQ1JB8hRp
Default region name [None]: us-east-1
Default output format [None]:Per ottenere queste informazioni, puoi andare alla sezione IAM AWS e controllare l'utente corrente oppure, se preferisci, puoi crearne uno nuovo per questa attività.
Dopo questo, siamo pronti per utilizzare l'AWS CLI per accedere ai nostri servizi Amazon AWS.
Amazon S3
Questa è probabilmente l'opzione più comunemente utilizzata per archiviare i backup nel cloud. Amazon S3 può archiviare e recuperare qualsiasi quantità di dati da qualsiasi punto di Internet. È un semplice servizio di archiviazione che offre un'infrastruttura di archiviazione dati estremamente durevole, altamente disponibile e infinitamente scalabile a costi contenuti.
Amazon S3 fornisce una semplice interfaccia del servizio Web che puoi utilizzare per archiviare e recuperare qualsiasi quantità di dati, in qualsiasi momento, da qualsiasi punto del Web e (con l'AWS CLI o l'SDK AWS) tu può integrarlo con diversi sistemi e linguaggi di programmazione.
Come usarlo
Amazon S3 utilizza Bucket. Sono contenitori unici per tutto ciò che memorizzi in Amazon S3. Quindi, il primo passaggio consiste nell'accedere alla Console di gestione Amazon S3 e creare un nuovo Bucket.
Nel primo passaggio, dobbiamo solo aggiungere il nome del Bucket e il Regione AWS.
Ora possiamo configurare alcuni dettagli sul nostro nuovo Bucket, come il controllo delle versioni e registrazione.

E poi, possiamo specificare i permessi per questo nuovo Bucket.
Ora abbiamo creato il nostro Bucket, vediamo come usarlo per archivia i nostri backup PostgreSQL.
Per prima cosa, testiamo il nostro client collegandolo a S3.
[example@sqldat.com ~]# aws s3 ls
2019-08-23 19:29:02 s9stesting1Funziona! Con il comando precedente, elenchiamo i Bucket attualmente creati.
Quindi, ora possiamo semplicemente caricare il backup sul servizio S3. Per questo, possiamo usare il comando aws sync o aws cp.
[example@sqldat.com ~]# aws s3 sync /root/backups/BACKUP-5/ s3://s9stesting1/backups/
upload: backups/BACKUP-5/cmon_backup.metadata to s3://s9stesting1/backups/cmon_backup.metadata
upload: backups/BACKUP-5/cmon_backup.log to s3://s9stesting1/backups/cmon_backup.log
upload: backups/BACKUP-5/base.tar.gz to s3://s9stesting1/backups/base.tar.gz
[example@sqldat.com ~]#
[example@sqldat.com ~]# aws s3 cp /root/backups/BACKUP-6/pg_dump_2019-08-23_205919.sql.gz s3://s9stesting1/backups/
upload: backups/BACKUP-6/pg_dump_2019-08-23_205919.sql.gz to s3://s9stesting1/backups/pg_dump_2019-08-23_205919.sql.gz
[example@sqldat.com ~]# Possiamo controllare il contenuto del Bucket dal sito Web di AWS.
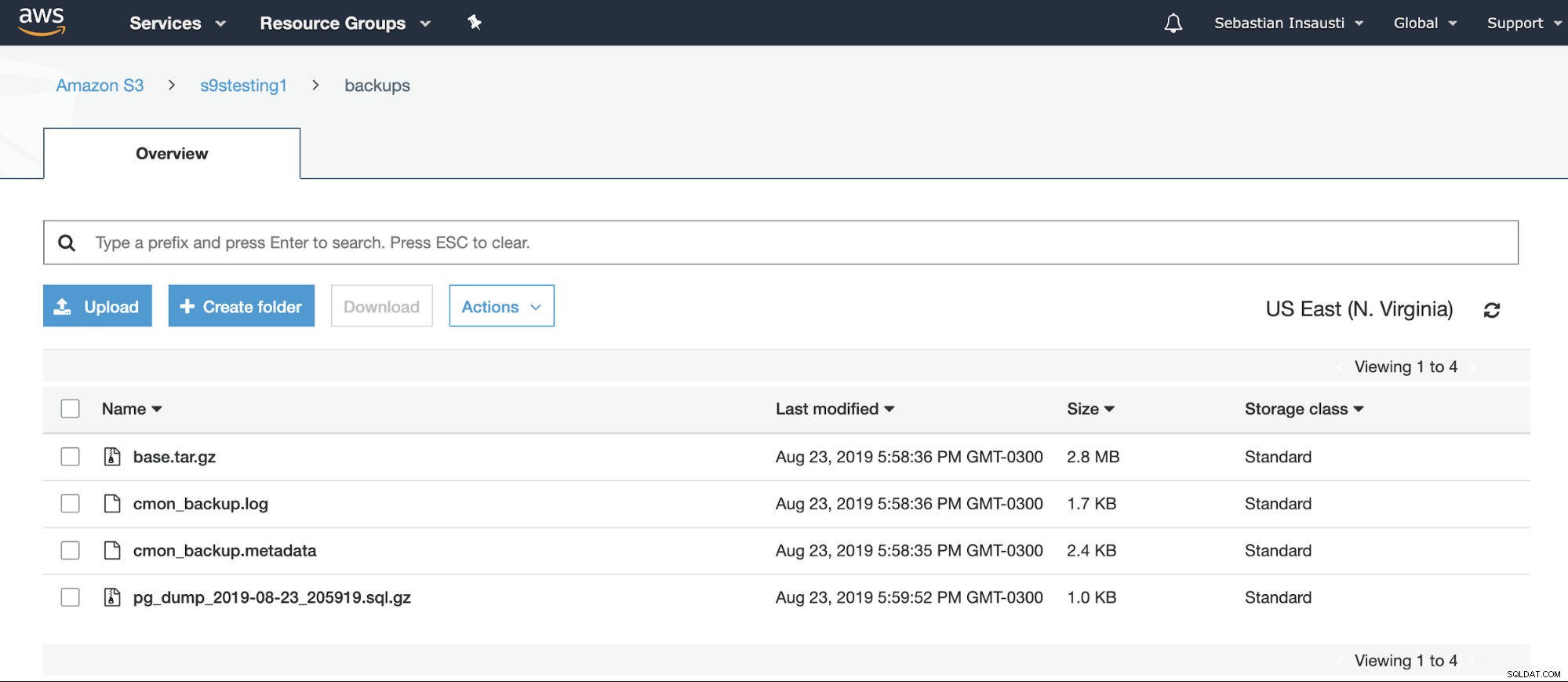
O anche utilizzando l'AWS CLI.
[example@sqldat.com ~]# aws s3 ls s3://s9stesting1/backups/
2019-08-23 19:29:31 0
2019-08-23 20:58:36 2974633 base.tar.gz
2019-08-23 20:58:36 1742 cmon_backup.log
2019-08-23 20:58:35 2419 cmon_backup.metadata
2019-08-23 20:59:52 1028 pg_dump_2019-08-23_205919.sql.gzPer ulteriori informazioni sull'AWS S3 CLI, puoi consultare la documentazione ufficiale di AWS.
Ghiacciaio Amazon S3
Questa è la versione a basso costo di Amazon S3. La principale differenza tra loro è la velocità e l'accessibilità. Puoi utilizzare Amazon S3 Glacier se il costo dello storage deve rimanere basso e non hai bisogno di un accesso di millisecondi ai tuoi dati. L'utilizzo è un'altra importante differenza tra loro.
Come usarlo
Invece di Bucket, Amazon S3 Glacier utilizza i Vault. È un contenitore per riporre qualsiasi oggetto. Quindi, il primo passaggio consiste nell'accedere alla Amazon S3 Glacier Management Console e creare un nuovo Vault.
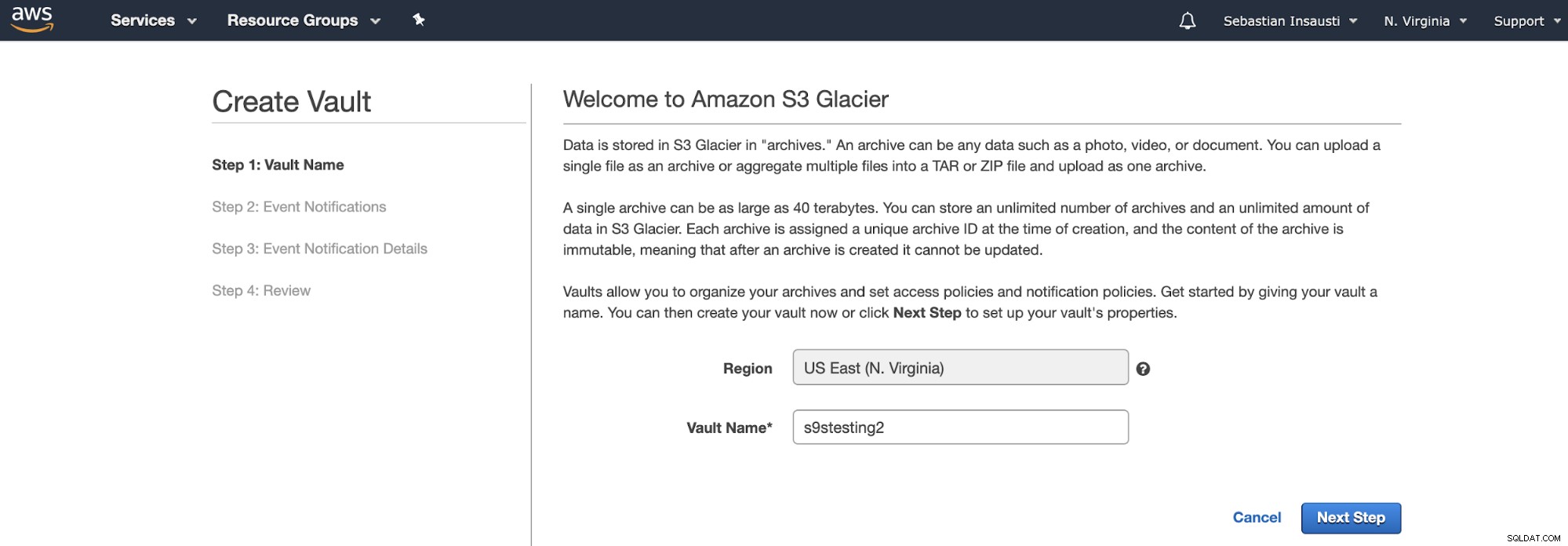
Qui, dobbiamo aggiungere il nome del vault e la regione e, in il passaggio successivo, possiamo abilitare le notifiche di eventi che utilizzano Amazon Simple Notification Service (Amazon SNS).
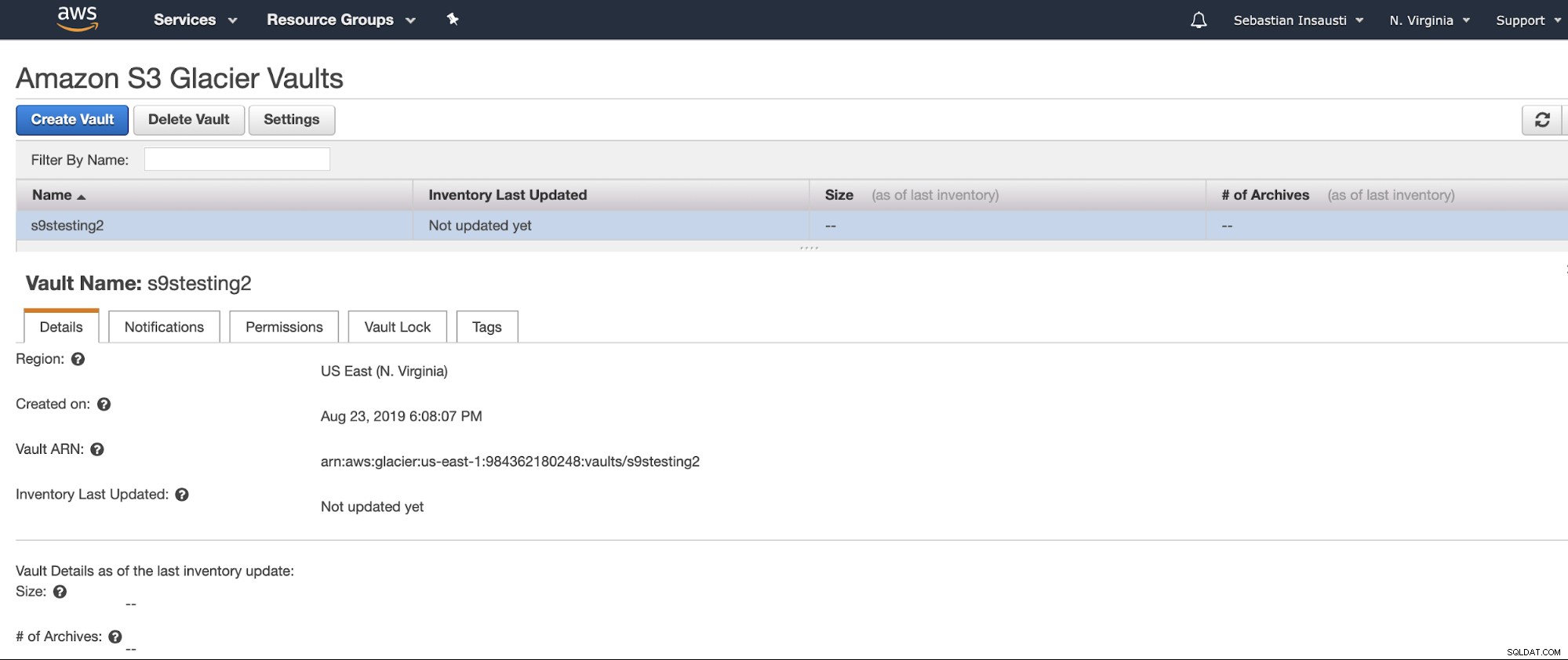
Ora abbiamo creato il nostro Vault, possiamo accedervi dall'AWS CLI .
[example@sqldat.com ~]# aws glacier describe-vault --account-id - --vault-name s9stesting2
{
"SizeInBytes": 0,
"VaultARN": "arn:aws:glacier:us-east-1:984227183428:vaults/s9stesting2",
"NumberOfArchives": 0,
"CreationDate": "2019-08-23T21:08:07.943Z",
"VaultName": "s9stesting2"
}Funziona. Quindi ora possiamo caricare il nostro backup qui.
[example@sqldat.com ~]# aws glacier upload-archive --body /root/backups/BACKUP-6/pg_dump_2019-08-23_205919.sql.gz --account-id - --archive-description "Backup upload test" --vault-name s9stesting2
{
"archiveId": "ddgCJi_qCJaIVinEW-xRl4I_0u2a8Ge5d2LHfoFBlO6SLMzG_0Cw6fm-OLJy4ZH_vkSh4NzFG1hRRZYDA-QBCEU4d8UleZNqsspF6MI1XtZFOo_bVcvIorLrXHgd3pQQmPbxI8okyg",
"checksum": "258faaa90b5139cfdd2fb06cb904fe8b0c0f0f80cba9bb6f39f0d7dd2566a9aa",
"location": "/984227183428/vaults/s9stesting2/archives/ddgCJi_qCJaIVinEW-xRl4I_0u2a8Ge5d2LHfoFBlO6SLMzG_0Cw6fm-OLJy4ZH_vkSh4NzFG1hRRZYDA-QBCEU4d8UleZNqsspF6MI1XtZFOo_bVcvIorLrXHgd3pQQmPbxI8okyg"
}Una cosa importante è che lo stato del Vault viene aggiornato circa una volta al giorno, quindi dovremmo aspettare per vedere il file caricato.
[example@sqldat.com ~]# aws glacier describe-vault --account-id - --vault-name s9stesting2
{
"SizeInBytes": 33796,
"VaultARN": "arn:aws:glacier:us-east-1:984227183428:vaults/s9stesting2",
"LastInventoryDate": "2019-08-24T06:37:02.598Z",
"NumberOfArchives": 1,
"CreationDate": "2019-08-23T21:08:07.943Z",
"VaultName": "s9stesting2"
}Qui abbiamo il nostro file caricato sul nostro Glacier Vault S3.
Per ulteriori informazioni su AWS Glacier CLI, puoi consultare la documentazione ufficiale di AWS.
EC2
Questa opzione di archiviazione di backup è quella più costosa e dispendiosa in termini di tempo, ma è utile se si desidera avere il controllo completo sull'ambiente di archiviazione di backup e si desidera eseguire attività personalizzate sui backup (ad es. Verifica del backup .)
Amazon EC2 (Elastic Compute Cloud) è un servizio Web che fornisce capacità di calcolo ridimensionabile nel cloud. Ti fornisce il controllo completo delle tue risorse informatiche e ti consente di impostare e configurare tutto ciò che riguarda le tue istanze dal tuo sistema operativo fino alle tue applicazioni. Ti consente inoltre di scalare rapidamente la capacità, sia verso l'alto che verso il basso, al variare dei requisiti di elaborazione.
Amazon EC2 supporta diversi sistemi operativi come Amazon Linux, Ubuntu, Windows Server, Red Hat Enterprise Linux, SUSE Linux Enterprise Server, Fedora, Debian, CentOS, Gentoo Linux, Oracle Linux e FreeBSD.
Come usarlo
Vai alla sezione Amazon EC2 e premi su Avvia istanza. Nel primo passaggio, devi scegliere il sistema operativo dell'istanza EC2.
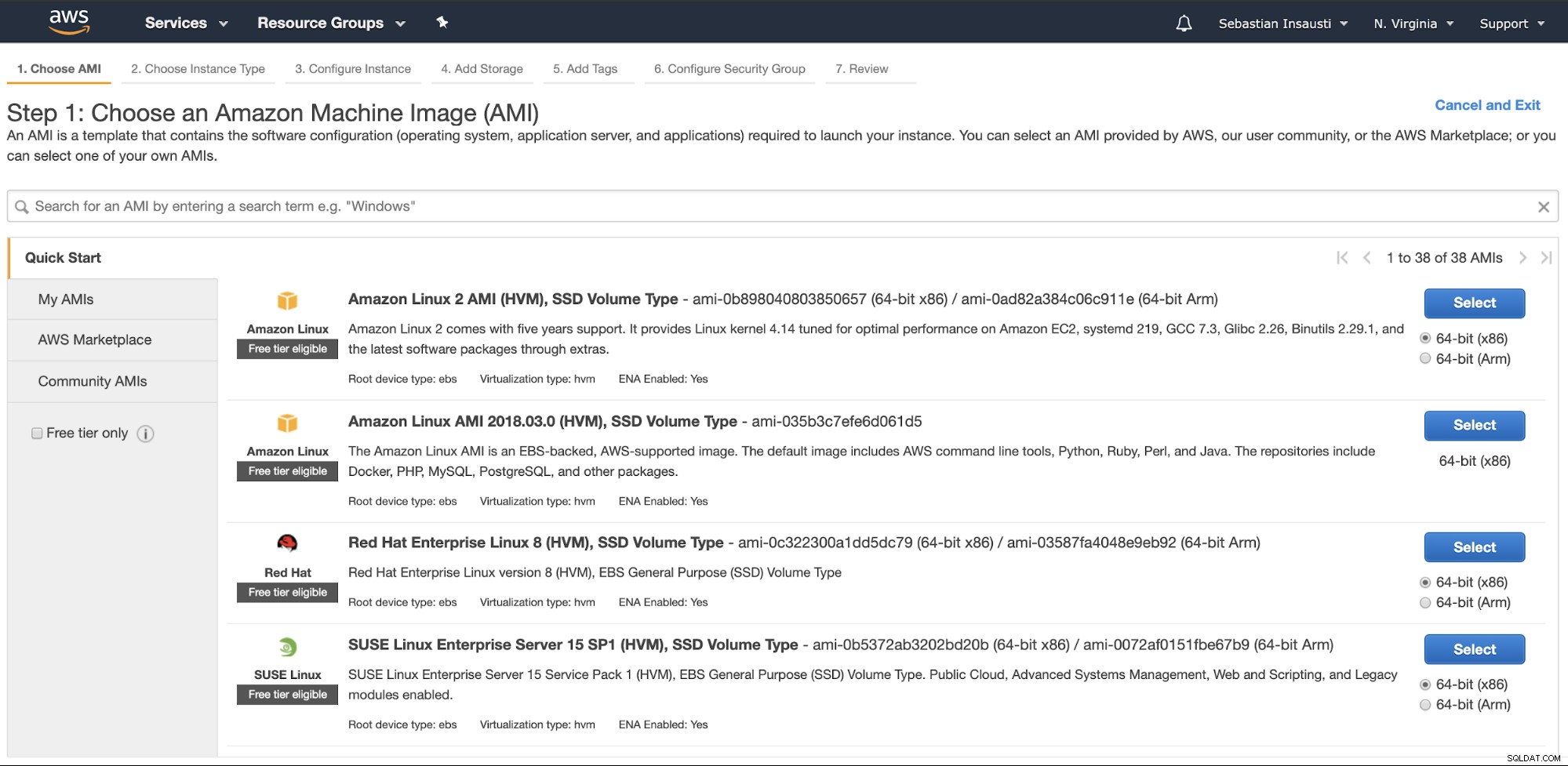
Nel passaggio successivo, devi scegliere le risorse per la nuova istanza.
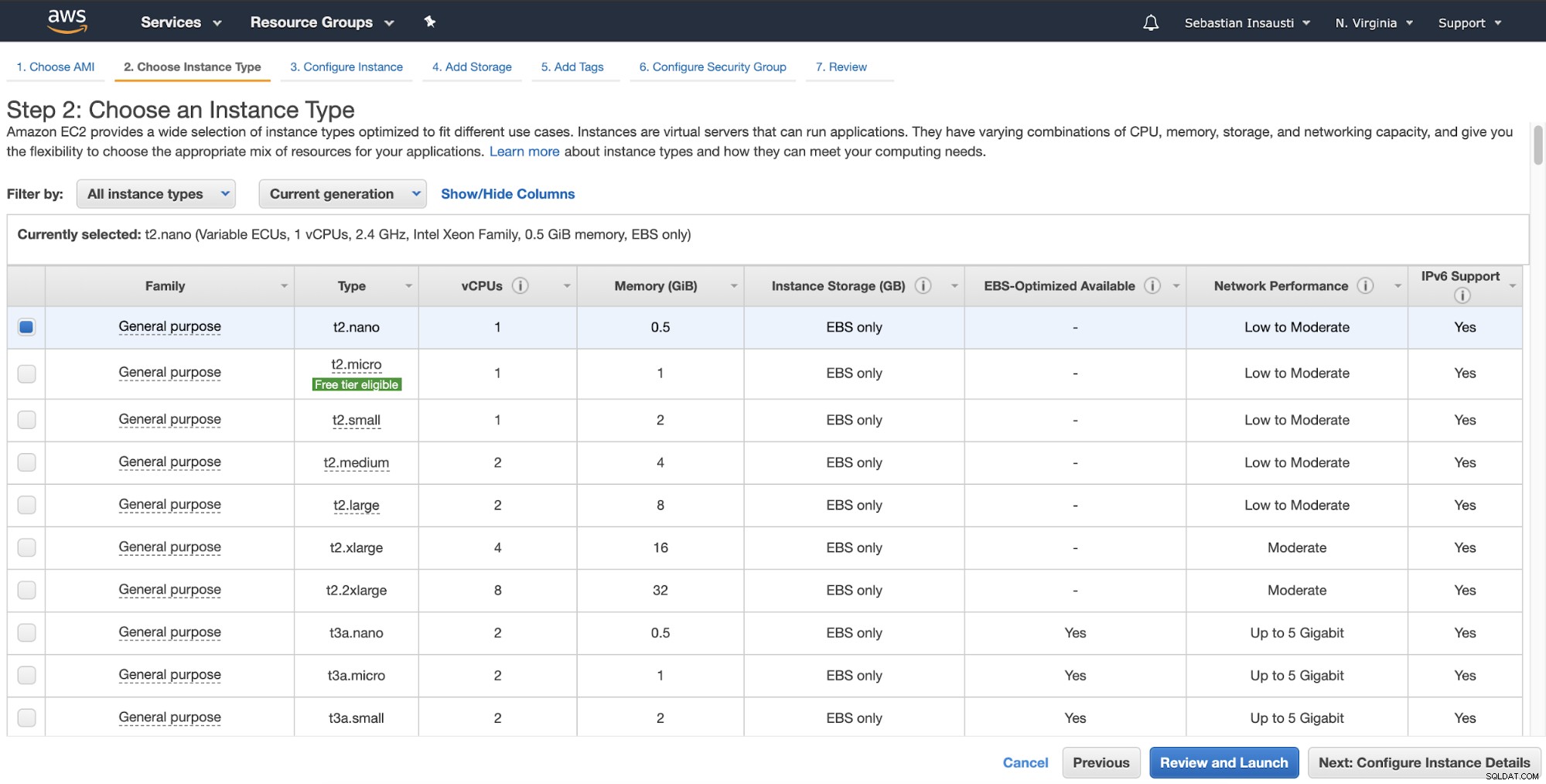
Quindi, puoi specificare una configurazione più dettagliata come rete, sottorete e altro .
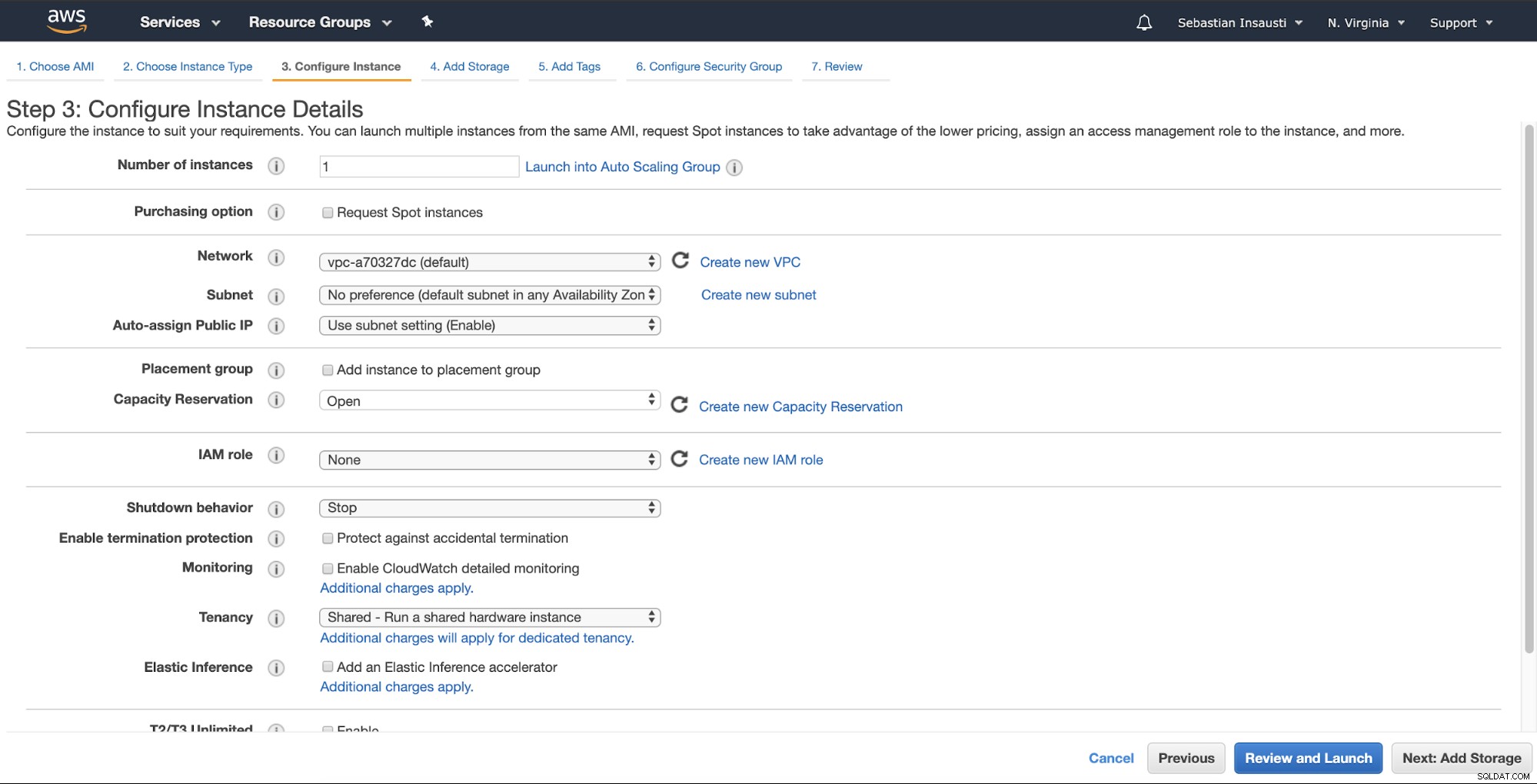
Ora possiamo aggiungere più capacità di archiviazione su questa nuova istanza e, come un server di backup, dovremmo farlo.
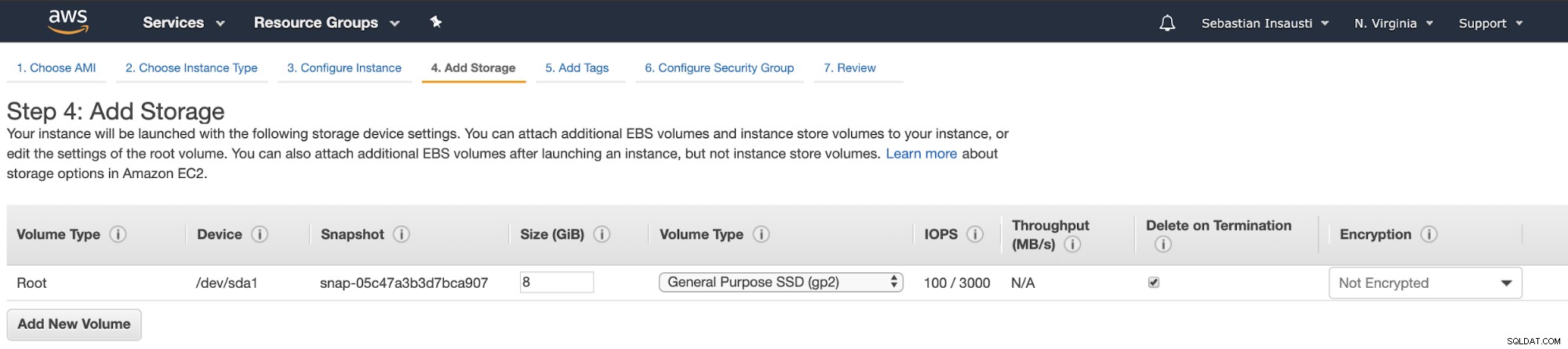
Al termine dell'attività di creazione, possiamo andare alla sezione Istanze per guarda la nostra nuova istanza EC2.
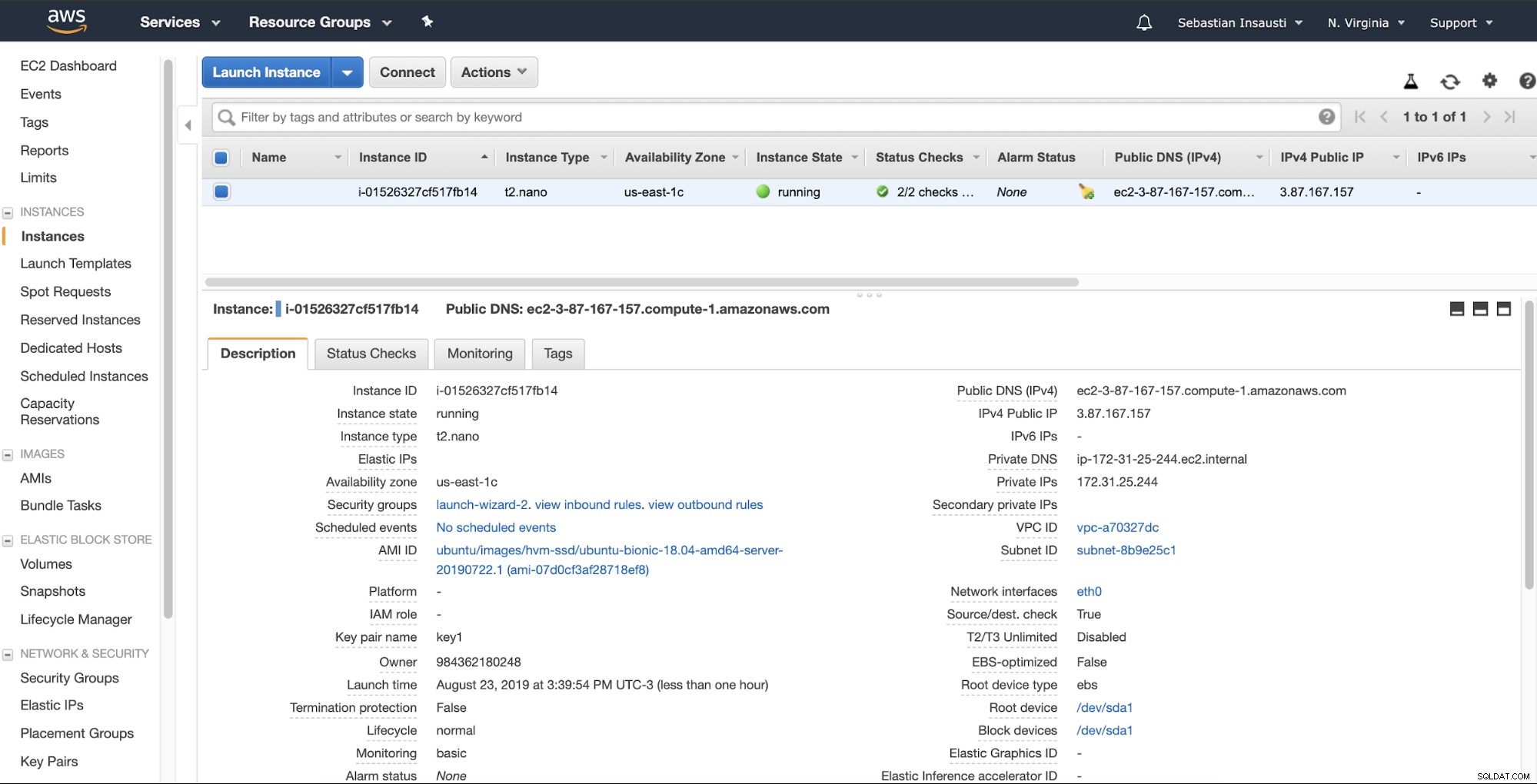
Quando l'istanza è pronta (stato dell'istanza in esecuzione), è possibile memorizzare il backup qui, ad esempio, inviandolo tramite SSH o FTP utilizzando il DNS pubblico creato da AWS. Vediamo un esempio con Rsync e un altro con il comando SCP Linux.
[example@sqldat.com ~]# rsync -avzP -e "ssh -i /home/user/key1.pem" /root/backups/BACKUP-11/base.tar.gz example@sqldat.com:/backups/20190823/
sending incremental file list
base.tar.gz
4,091,563 100% 2.18MB/s 0:00:01 (xfr#1, to-chk=0/1)
sent 3,735,675 bytes received 35 bytes 574,724.62 bytes/sec
total size is 4,091,563 speedup is 1.10
[example@sqldat.com ~]#
[example@sqldat.com ~]# scp -i /tmp/key1.pem /root/backups/BACKUP-12/pg_dump_2019-08-25_211903.sql.gz example@sqldat.com:/backups/20190823/
pg_dump_2019-08-25_211903.sql.gz 100% 24KB 76.4KB/s 00:00Backup AWS
AWS Backup è un servizio di backup centralizzato che fornisce funzionalità di gestione del backup, come la pianificazione del backup, la gestione della conservazione e il monitoraggio del backup, nonché funzionalità aggiuntive, come il ciclo di vita dei backup a basso costo livello di archiviazione, archiviazione di backup e crittografia indipendente dai dati di origine e dalle politiche di accesso al backup.
Puoi utilizzare AWS Backup per gestire i backup di volumi EBS, database RDS, tabelle DynamoDB, file system EFS e volumi Storage Gateway.
Come usarlo
Vai alla sezione AWS Backup nella Console di gestione AWS.
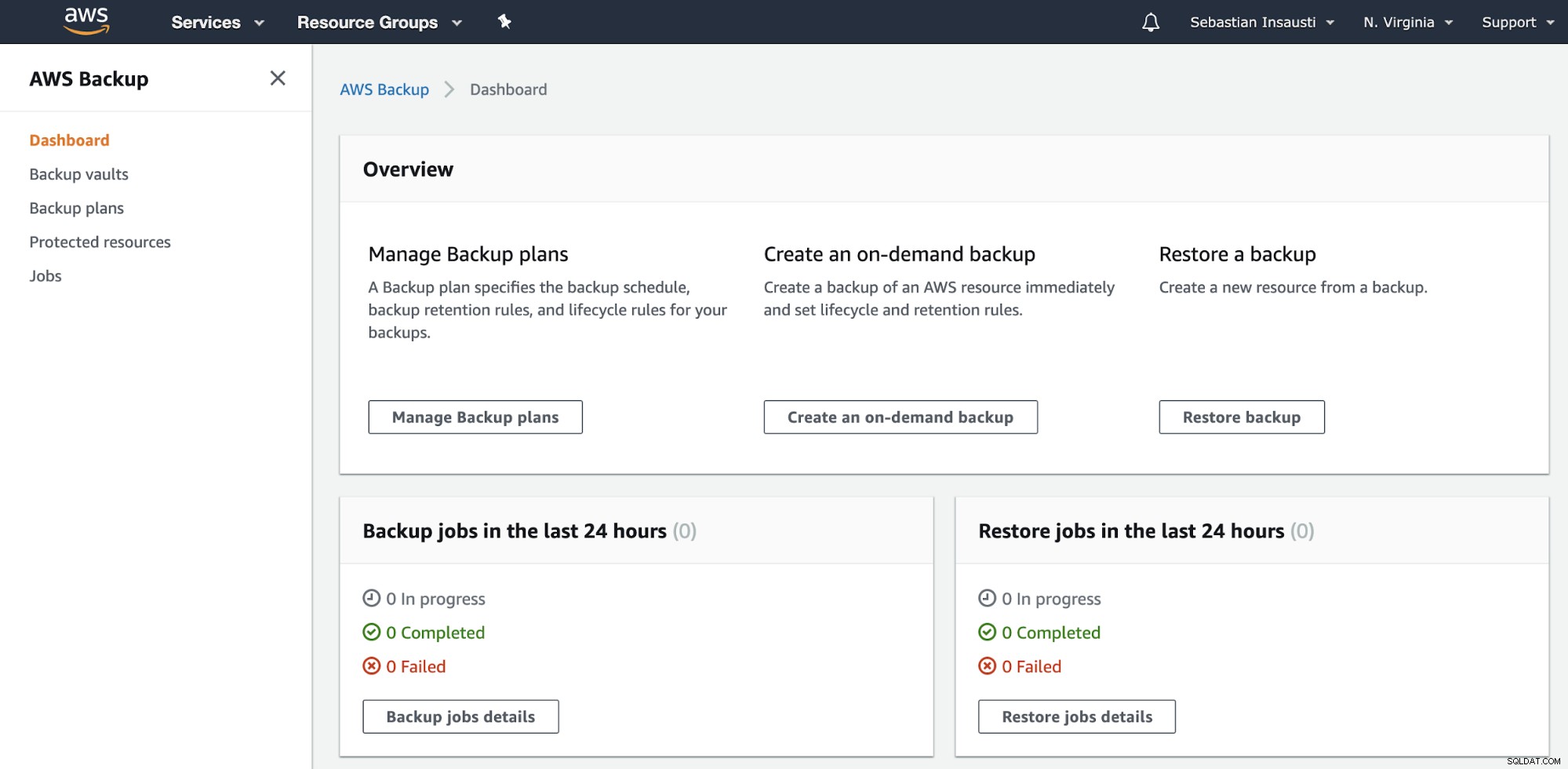
Qui hai diverse opzioni, come Pianifica, Crea o Ripristina un backup . Vediamo come creare un nuovo backup.
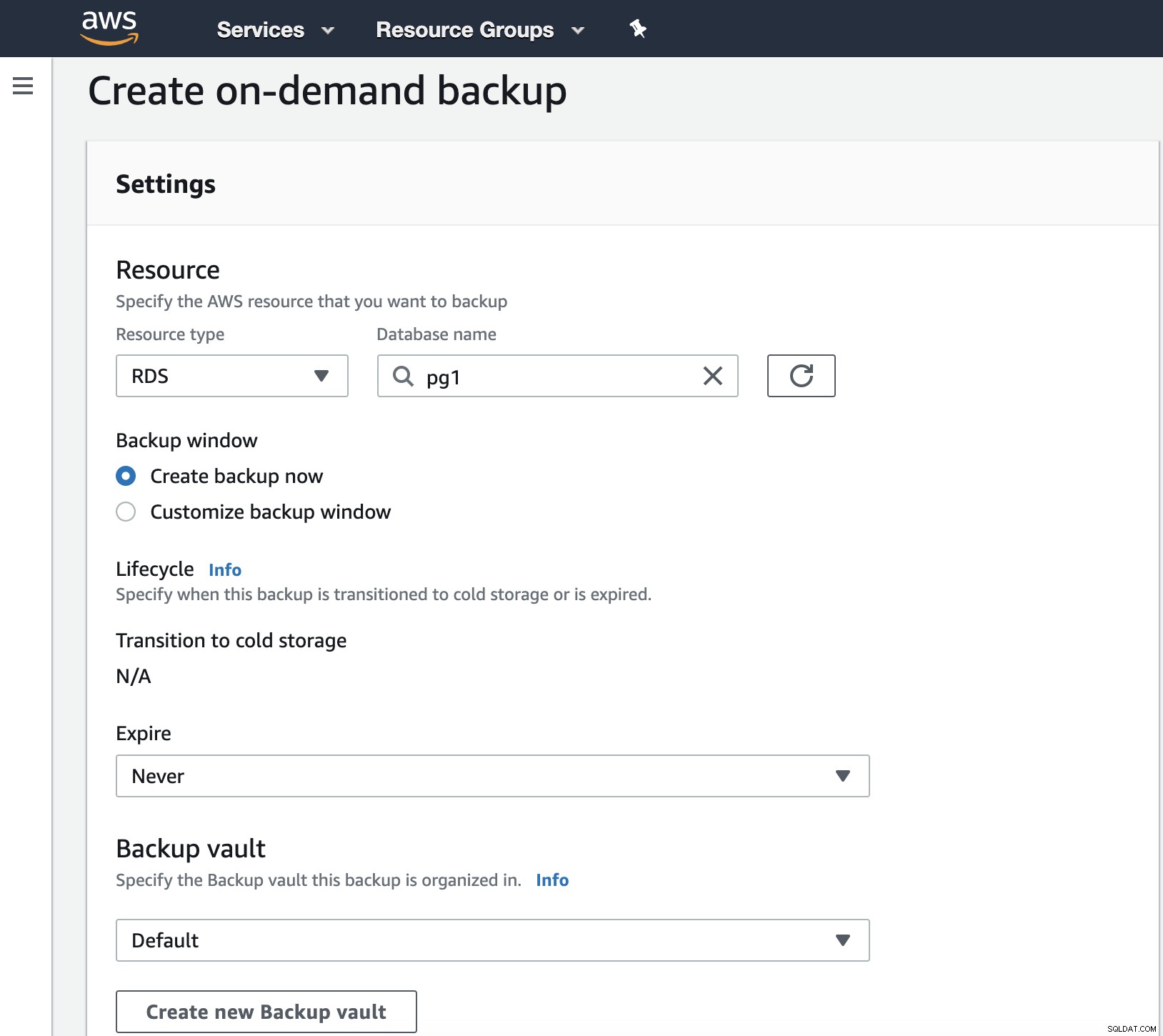
In questo passaggio, dobbiamo scegliere il tipo di risorsa che può essere DynamoDB, RDS, EBS, EFS o Storage Gateway e altri dettagli come la data di scadenza, il deposito di backup e il ruolo IAM.
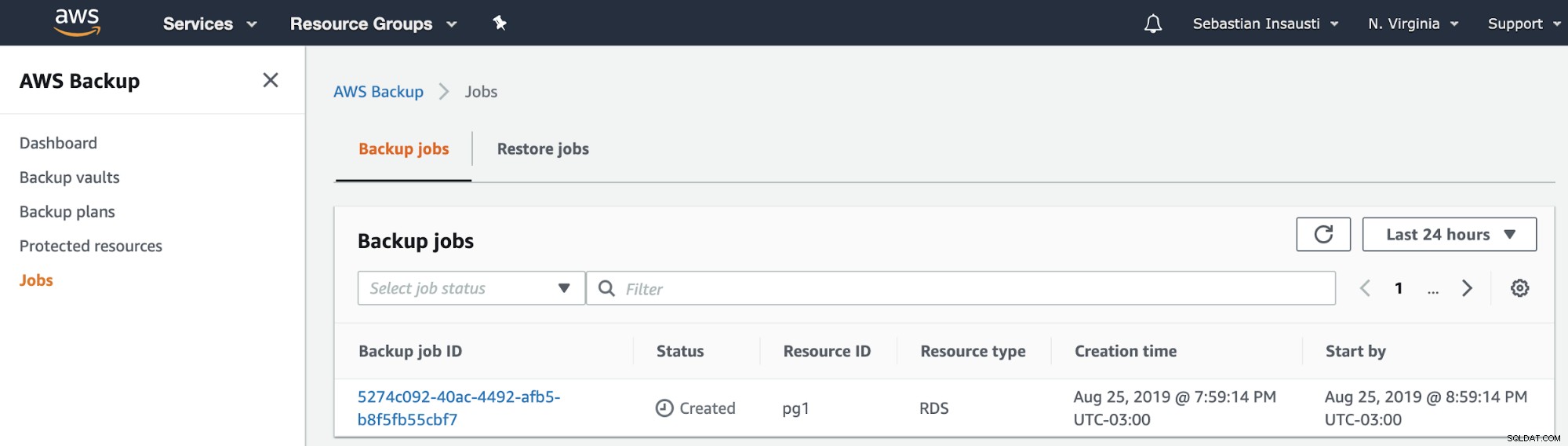
Quindi, possiamo vedere il nuovo lavoro creato nella sezione Lavori di backup di AWS .
Istantanea
Ora possiamo citare questa opzione nota in tutti gli ambienti di virtualizzazione. Lo snapshot è un backup eseguito in un momento specifico e AWS ci consente di utilizzarlo per i prodotti AWS. Facciamo un esempio di uno snapshot RDS.
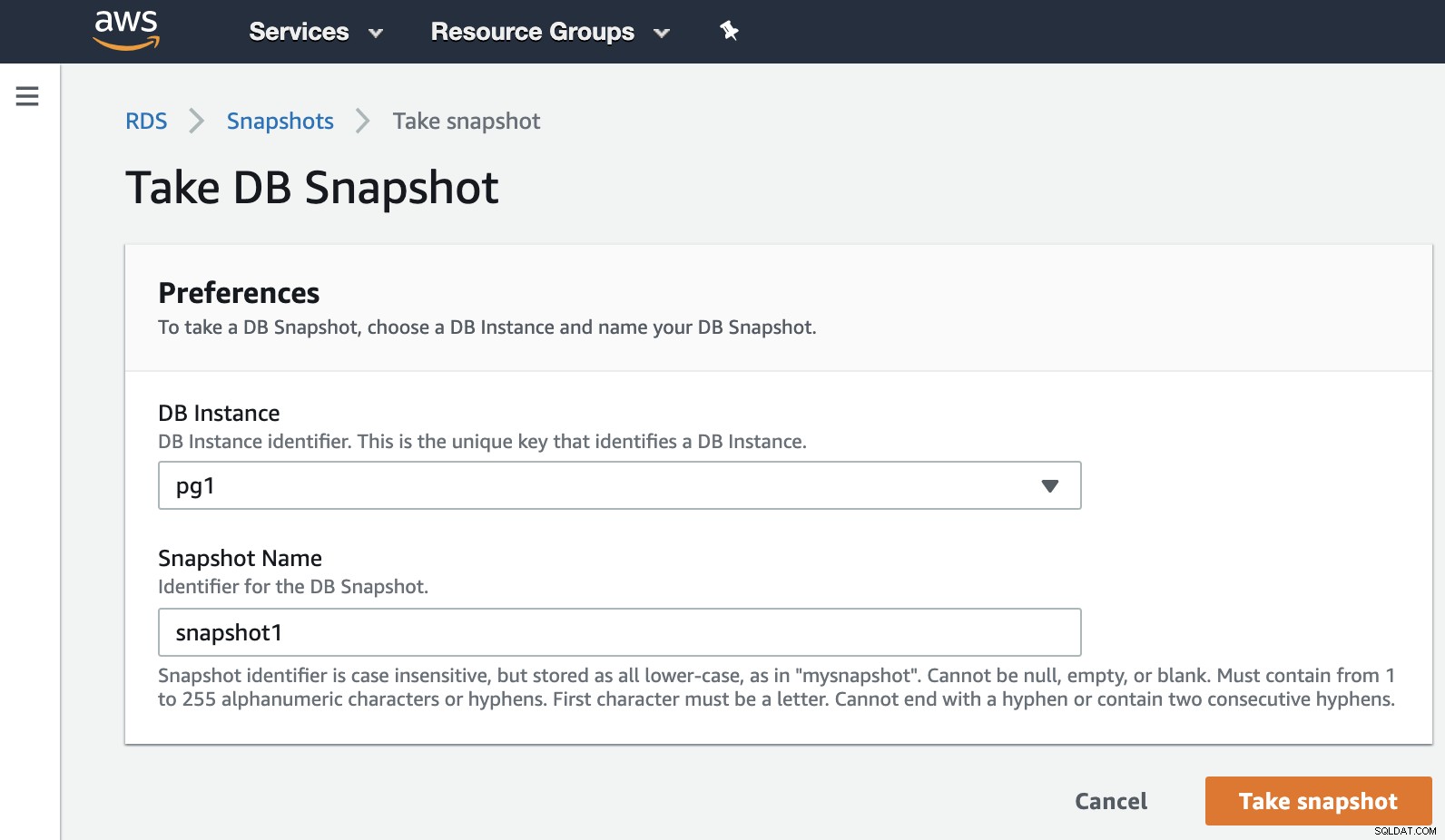
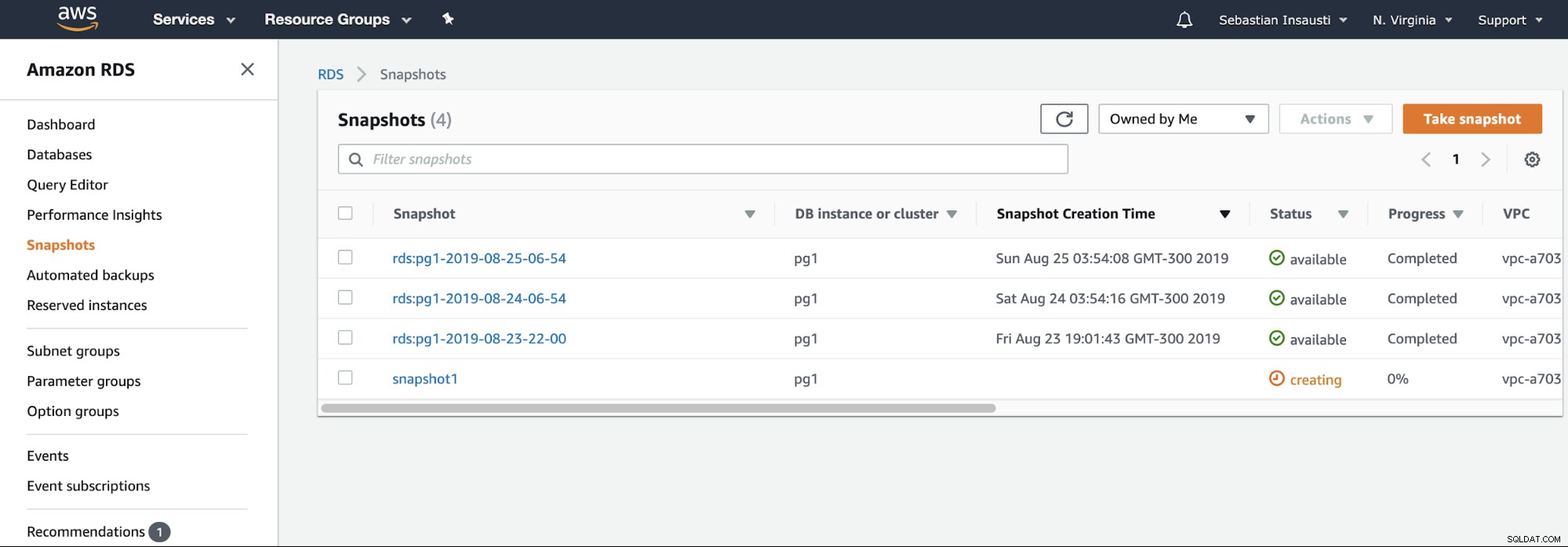
Dobbiamo solo scegliere l'istanza e aggiungere il nome dello snapshot, e basta esso. Possiamo vedere questo e l'istantanea precedente nella sezione Istantanea RDS.
Gestione dei backup con ClusterControl
ClusterControl è un sistema di gestione completo per database open source che automatizza le funzioni di distribuzione e gestione, nonché il monitoraggio dello stato e delle prestazioni. ClusterControl supporta l'implementazione, la gestione, il monitoraggio e il ridimensionamento per diverse tecnologie e ambienti di database, incluso EC2. Quindi, possiamo, ad esempio, creare la nostra istanza EC2 su AWS e distribuire/importare il nostro servizio di database con ClusterControl.

Creazione di un backup
Per questa attività, vai su ClusterControl -> Seleziona Cluster -> Backup -> Crea backup.
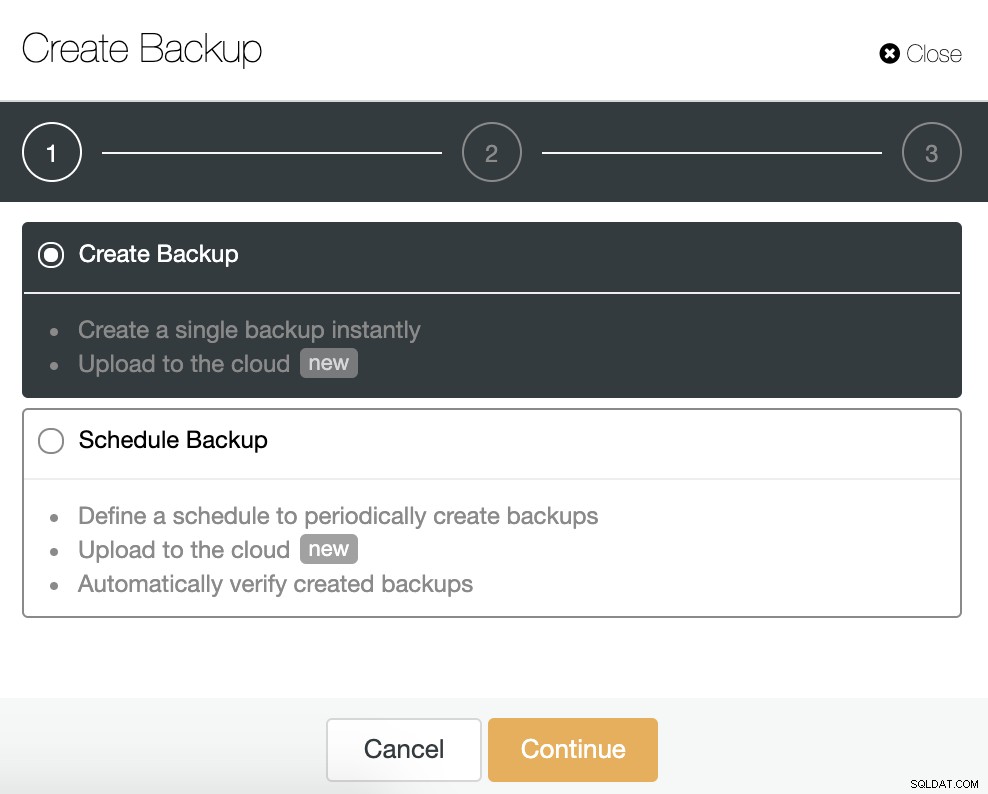
Possiamo creare un nuovo backup o configurarne uno pianificato. Per il nostro esempio, creeremo istantaneamente un singolo backup.
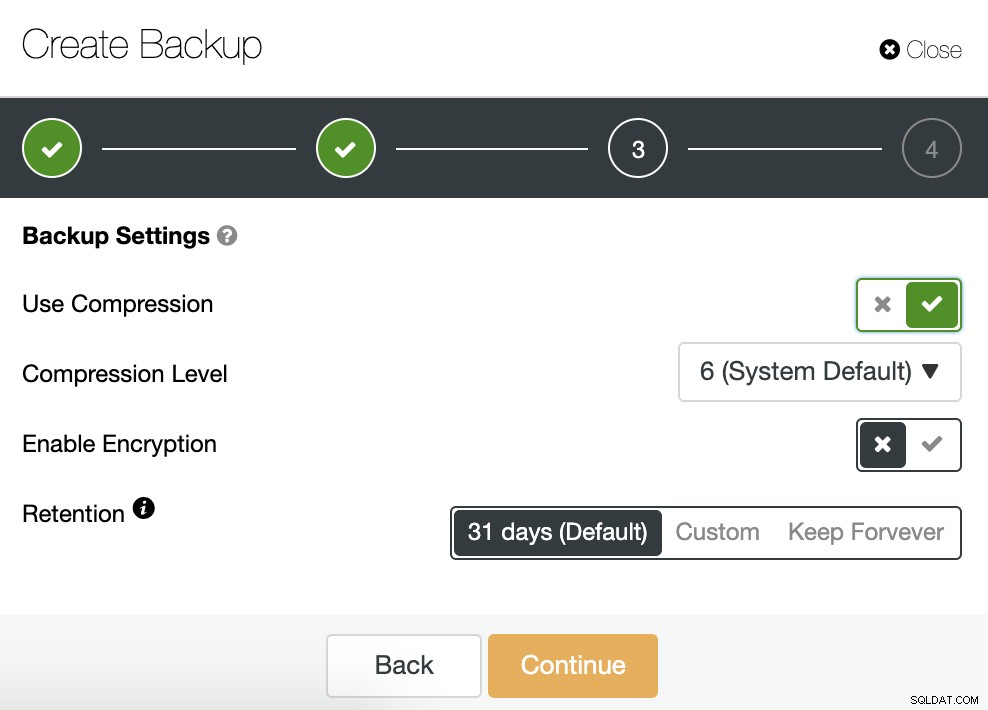
Dobbiamo scegliere un metodo, il server da cui verrà eseguito il backup e dove vogliamo archiviare il backup. Possiamo anche caricare il nostro backup sul cloud (AWS, Google o Azure) abilitando il pulsante corrispondente.
Quindi specifichiamo l'uso della compressione, il livello di compressione, la crittografia e la conservazione periodo per il nostro backup.
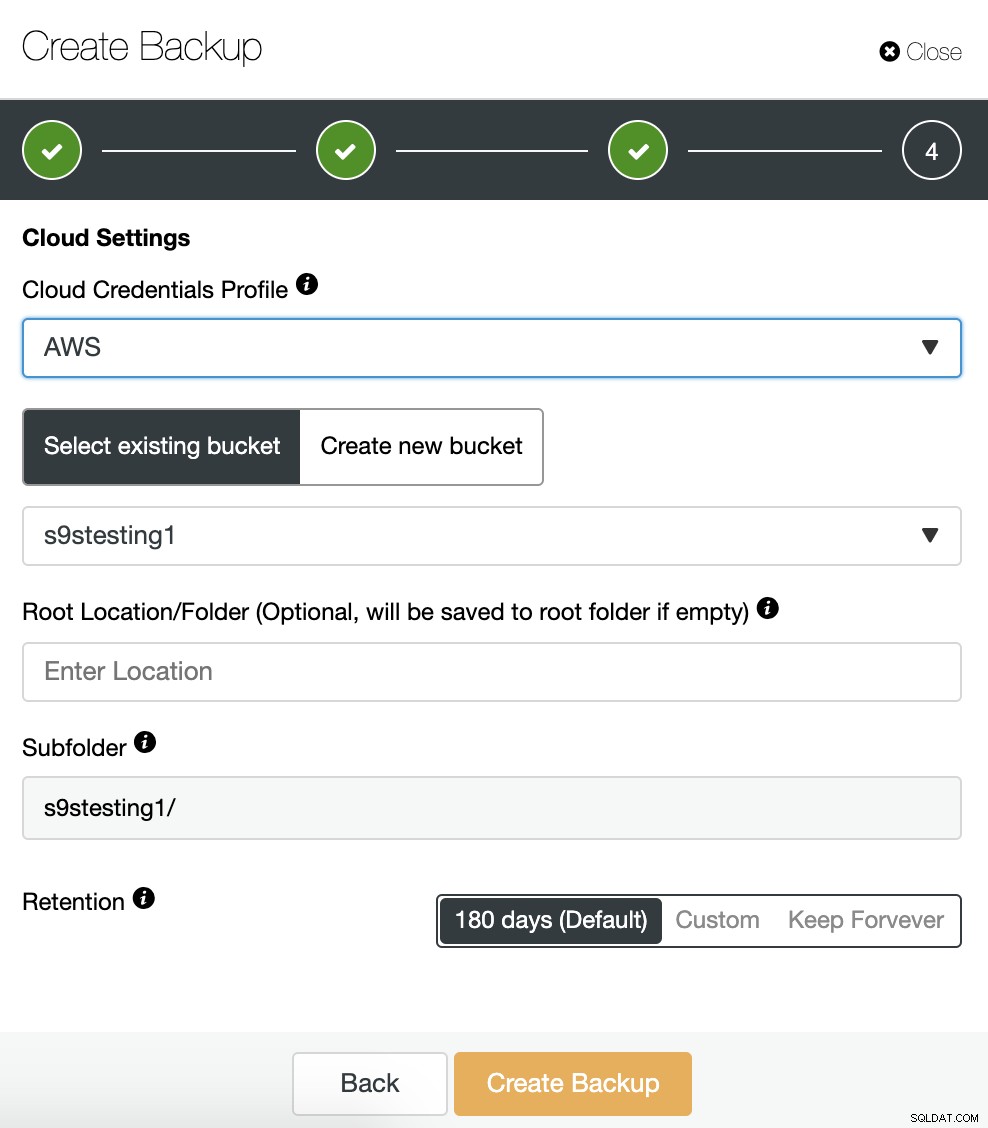
Se abbiamo abilitato l'opzione di caricamento del backup nel cloud, vedremo una sezione per specificare il provider cloud (in questo caso AWS) e le credenziali (ClusterControl -> Integrazioni -> Cloud Provider). Per AWS, utilizza il servizio S3, quindi dobbiamo selezionare un Bucket o addirittura crearne uno nuovo per archiviare i nostri backup.
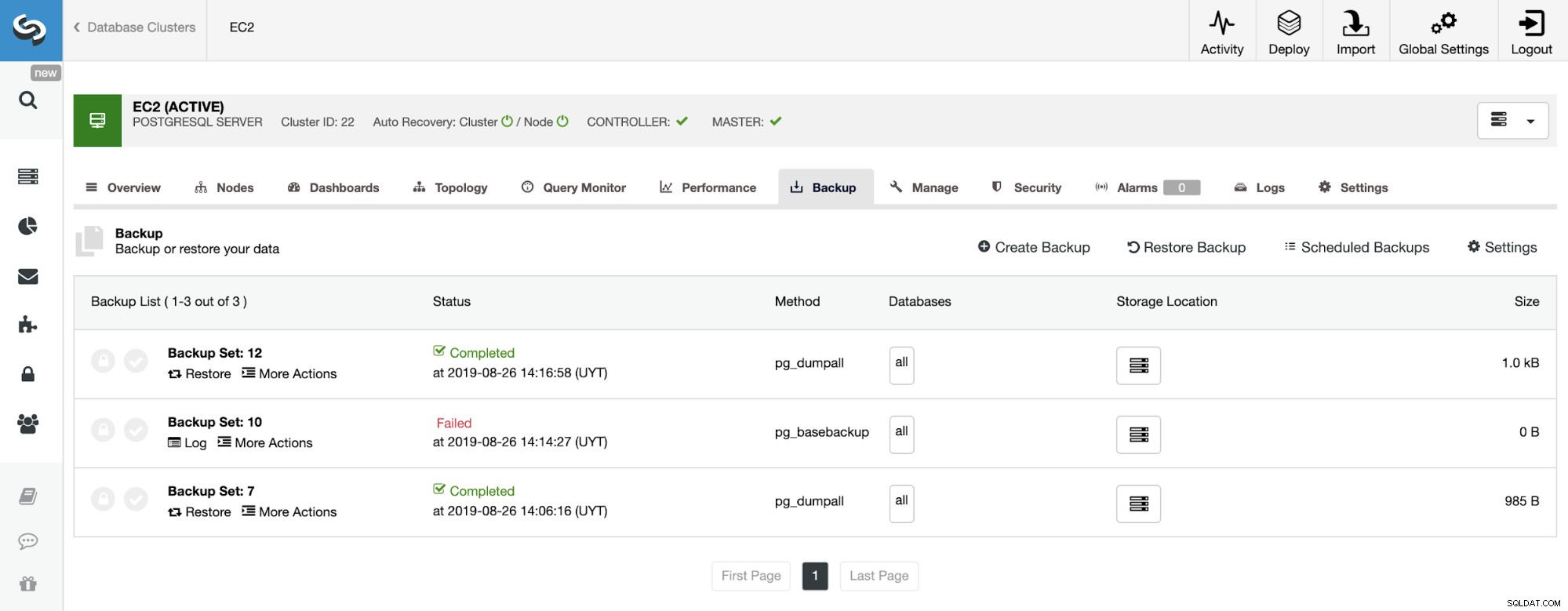
Nella sezione backup, possiamo vedere l'avanzamento del backup e informazioni come metodo, dimensione, posizione e altro.
Conclusione
Amazon AWS ci consente di archiviare i nostri backup PostgreSQL, indipendentemente dal fatto che lo utilizziamo come provider di database cloud o meno. Per avere un piano di backup efficace, dovresti considerare di archiviare almeno una copia di backup del database nel cloud per evitare la perdita di dati in caso di guasto dell'hardware in un altro archivio di backup. Il cloud ti consente di archiviare tutti i backup che desideri archiviare o pagare.



