In qualsiasi motore di database relazionali, è necessario generare un miglior piano possibile che corrisponda all'esecuzione della query con il minor tempo e risorse. In genere, tutti i database generano piani in un formato struttura ad albero, in cui il nodo foglia di ogni albero del piano è chiamato nodo di scansione tabella. Questo particolare nodo del piano corrisponde all'algoritmo da utilizzare per recuperare i dati dalla tabella di base.
Ad esempio, considera un semplice esempio di query come SELECT * FROM TBL1, TBL2 dove TBL2.ID>1000; e supponiamo che il piano generato sia il seguente:
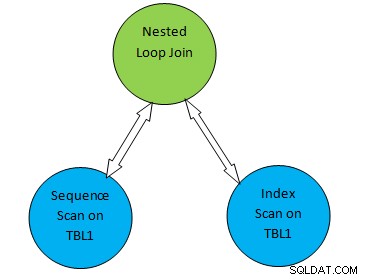
Quindi nell'albero del piano sopra, "Scansione sequenziale su TBL1" e " Scansione indice su TBL2” corrisponde al metodo di scansione tabella sulle tabelle TBL1 e TBL2 rispettivamente. Pertanto, secondo questo piano, TBL1 verrà recuperato in sequenza dalle pagine corrispondenti e sarà possibile accedere a TBL2 utilizzando INDEX Scan.
La scelta del metodo di scansione corretto come parte del piano è molto importante in termini di prestazioni complessive delle query.
Prima di entrare in tutti i tipi di metodi di scansione supportati da PostgreSQL, esaminiamo alcuni dei principali punti chiave che verranno utilizzati frequentemente durante la lettura del blog.
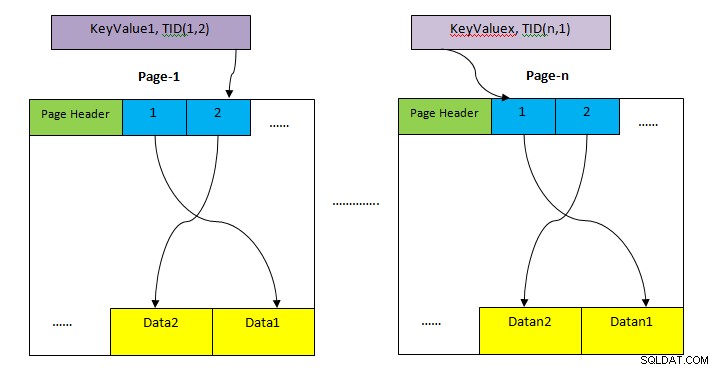
- HEAP: Area di archiviazione per la memorizzazione dell'intera riga della tabella. Questo è diviso in più pagine (come mostrato nell'immagine sopra) e ogni dimensione di pagina è di default 8 KB. All'interno di ogni pagina, ogni puntatore dell'elemento (ad es. 1, 2, ….) punta ai dati all'interno della pagina.
- Archiviazione dell'indice: Questa memoria archivia solo i valori chiave, ad esempio il valore delle colonne contenuto dall'indice. Anche questo è diviso in più pagine e ciascuna dimensione di pagina è di default 8 KB.
- Identificatore tupla (TID): TID è un numero di 6 byte composto da due parti. La prima parte è il numero di pagina di 4 byte e l'indice di tupla di 2 byte rimanenti all'interno della pagina. La combinazione di questi due numeri punta in modo univoco alla posizione di archiviazione per una particolare tupla.
Attualmente, PostgreSQL supporta i seguenti metodi di scansione con cui tutti i dati richiesti possono essere letti dalla tabella:
- Scansione sequenziale
- Scansione indice
- Scansione solo indice
- Scansione bitmap
- Scansione TID
Ciascuno di questi metodi di scansione è ugualmente utile a seconda della query e di altri parametri, ad es. cardinalità della tabella, selettività della tabella, costo dell'I/O del disco, costo dell'I/O casuale, costo dell'I/O della sequenza, ecc. Creiamo una tabella di pre-impostazione e popolarla con alcuni dati, che verranno usati frequentemente per spiegare meglio questi metodi di scansione .
postgres=# CREATE TABLE demotable (num numeric, id int);
CREATE TABLE
postgres=# CREATE INDEX demoidx ON demotable(num);
CREATE INDEX
postgres=# INSERT INTO demotable SELECT random() * 1000, generate_series(1, 1000000);
INSERT 0 1000000
postgres=# analyze;
ANALYZEQuindi, in questo esempio, viene inserito un milione di record e quindi la tabella viene analizzata in modo che tutte le statistiche siano aggiornate.
Scansione sequenziale
Come suggerisce il nome, una scansione sequenziale di una tabella viene eseguita scansionando in sequenza tutti i puntatori degli elementi di tutte le pagine delle tabelle corrispondenti. Quindi, se ci sono 100 pagine per una tabella particolare e quindi ci sono 1000 record in ogni pagina, come parte della scansione sequenziale recupererà 100 * 1000 record e verificherà se corrisponde al livello di isolamento e anche alla clausola del predicato. Quindi, anche se viene selezionato solo 1 record come parte dell'intera scansione della tabella, dovrà scansionare 100.000 record per trovare un record qualificato secondo la condizione.
In base alla tabella e ai dati sopra riportati, la seguente query risulterà in una scansione sequenziale poiché la maggior parte dei dati viene selezionata.
postgres=# explain SELECT * FROM demotable WHERE num < 21000;
QUERY PLAN
--------------------------------------------------------------------
Seq Scan on demotable (cost=0.00..17989.00 rows=1000000 width=15)
Filter: (num < '21000'::numeric)
(2 rows)NOTA
Sebbene senza calcolare e confrontare il costo del piano, è quasi impossibile dire quale tipo di scansioni verrà utilizzato. Ma affinché la scansione sequenziale possa essere utilizzata almeno i criteri seguenti devono corrispondere:
- Nessun indice disponibile sulla chiave, che fa parte del predicato.
- La maggior parte delle righe viene recuperata come parte della query SQL.
CONSIGLI
Nel caso in cui venga recuperata solo una piccola percentuale di righe e il predicato si trovi su una (o più) colonne, prova a valutare le prestazioni con o senza indice.
Scansione indice
A differenza della scansione sequenziale, la scansione dell'indice non recupera tutti i record in sequenza. Piuttosto utilizza una struttura di dati diversa (a seconda del tipo di indice) corrispondente all'indice coinvolto nella query e individua la clausola dei dati richiesti (come da predicato) con scansioni molto minime. Quindi la voce trovata utilizzando la scansione dell'indice punta direttamente ai dati nell'area dell'heap (come mostrato nella figura sopra), che viene quindi recuperata per verificare la visibilità in base al livello di isolamento. Quindi ci sono due passaggi per la scansione dell'indice:
- Recupera i dati dalla struttura dei dati relativa all'indice. Restituisce il TID dei dati corrispondenti nell'heap.
- Quindi si accede direttamente alla pagina heap corrispondente per ottenere dati interi. Questo passaggio aggiuntivo è necessario per i seguenti motivi:
- La query potrebbe aver richiesto di recuperare più colonne rispetto a quelle disponibili nell'indice corrispondente.
- Le informazioni sulla visibilità non vengono mantenute insieme ai dati dell'indice. Quindi, per verificare la visibilità dei dati in base al livello di isolamento, è necessario accedere ai dati dell'heap.
Ora potremmo chiederci perché non usare sempre Index Scan se è così efficiente. Quindi, come sappiamo, tutto ha un costo. Qui il costo è correlato al tipo di I/O che stiamo facendo. Nel caso della scansione dell'indice, è coinvolto l'I/O casuale poiché per ogni record trovato nella memoria dell'indice, deve recuperare i dati corrispondenti dalla memoria HEAP mentre nel caso della scansione sequenziale, è coinvolto l'I/O della sequenza che richiede circa il 25% di temporizzazione I/O casuale.
Quindi la scansione dell'indice dovrebbe essere scelta solo se il guadagno complessivo supera l'overhead sostenuto a causa del costo di I/O casuale.
In base alla tabella e ai dati precedenti, la query seguente risulterà in una scansione dell'indice poiché viene selezionato un solo record. Quindi l'I/O casuale è inferiore e la ricerca del record corrispondente è rapida.
postgres=# explain SELECT * FROM demotable WHERE num = 21000;
QUERY PLAN
--------------------------------------------------------------------------
Index Scan using demoidx on demotable (cost=0.42..8.44 rows=1 width=15)
Index Cond: (num = '21000'::numeric)
(2 rows)Scansione solo indice
Index Only Scan è simile a Index Scan ad eccezione del secondo passaggio, ovvero, come suggerisce il nome, esegue la scansione solo della struttura dei dati dell'indice. Ci sono due prerequisiti aggiuntivi per scegliere la scansione solo indice confronta con la scansione indice:
- La query deve recuperare solo le colonne chiave che fanno parte dell'indice.
- Tutte le tuple (record) nella pagina heap selezionata dovrebbero essere visibili. Come discusso nella sezione precedente, la struttura dei dati dell'indice non mantiene le informazioni sulla visibilità, quindi per selezionare i dati solo dall'indice dovremmo evitare di controllare la visibilità e ciò potrebbe accadere se tutti i dati di quella pagina sono considerati visibili.
La seguente query risulterà in una scansione solo dell'indice. Anche se questa query è quasi simile in termini di selezione del numero di record, ma poiché viene selezionato solo il campo chiave (ad esempio "num"), sceglierà Scansione solo indice.
postgres=# explain SELECT num FROM demotable WHERE num = 21000;
QUERY PLAN
-----------------------------------------------------------------------------
Index Only Scan using demoidx on demotable (cost=0.42..8.44 rows=1 Width=11)
Index Cond: (num = '21000'::numeric)
(2 rows)Scansione bitmap
La scansione bitmap è un mix di scansione indice e scansione sequenziale. Cerca di risolvere lo svantaggio della scansione dell'indice, ma mantiene comunque il suo pieno vantaggio. Come discusso in precedenza, per ogni dato trovato nella struttura dei dati dell'indice, è necessario trovare i dati corrispondenti nella pagina dell'heap. Quindi, in alternativa, deve recuperare la pagina dell'indice una volta e quindi seguita dalla pagina dell'heap, che causa molti I/O casuali. Quindi il metodo di scansione bitmap sfrutta il vantaggio della scansione dell'indice senza I/O casuali. Funziona su due livelli come di seguito:
- Scansione dell'indice bitmap:per prima cosa recupera tutti i dati dell'indice dalla struttura dei dati dell'indice e crea una mappa dei bit di tutti i TID. Per una semplice comprensione, puoi considerare che questa bitmap contiene un hash di tutte le pagine (hash basato sulla pagina n.) e ogni voce di pagina contiene un array di tutti gli offset all'interno di quella pagina.
- Scansione dell'heap bitmap:come suggerisce il nome, legge la bitmap delle pagine e quindi scansiona i dati dall'heap corrispondente alla pagina memorizzata e all'offset. Alla fine, controlla la visibilità, il predicato ecc. e restituisce la tupla in base all'esito di tutti questi controlli.
La query sottostante risulterà in una scansione bitmap in quanto non seleziona pochissimi record (cioè troppi per la scansione dell'indice) e allo stesso tempo non seleziona un numero enorme di record (cioè troppo poco per un sequenziale scansione).
postgres=# explain SELECT * FROM demotable WHERE num < 210;
QUERY PLAN
-----------------------------------------------------------------------------
Bitmap Heap Scan on demotable (cost=5883.50..14035.53 rows=213042 width=15)
Recheck Cond: (num < '210'::numeric)
-> Bitmap Index Scan on demoidx (cost=0.00..5830.24 rows=213042 width=0)
Index Cond: (num < '210'::numeric)
(4 rows)Ora considera la query seguente, che seleziona lo stesso numero di record ma solo i campi chiave (cioè solo le colonne dell'indice). Poiché seleziona solo la chiave, non è necessario che faccia riferimento alle pagine dell'heap per altre parti di dati e quindi non sono coinvolti I/O casuali. Quindi questa query sceglierà Scansione solo indice invece di Scansione bitmap.
postgres=# explain SELECT num FROM demotable WHERE num < 210;
QUERY PLAN
---------------------------------------------------------------------------------------
Index Only Scan using demoidx on demotable (cost=0.42..7784.87 rows=208254 width=11)
Index Cond: (num < '210'::numeric)
(2 rows)Scansione TID
TID, come accennato in precedenza, è un numero di 6 byte che consiste in un numero di pagina di 4 byte e un indice di tupla di 2 byte rimanenti all'interno della pagina. La scansione TID è un tipo molto specifico di scansione in PostgreSQL e viene selezionata solo se è presente TID nel predicato della query. Considera la query di seguito che mostra la scansione TID:
postgres=# select ctid from demotable where id=21000;
ctid
----------
(115,42)
(1 row)
postgres=# explain select * from demotable where ctid='(115,42)';
QUERY PLAN
----------------------------------------------------------
Tid Scan on demotable (cost=0.00..4.01 rows=1 width=15)
TID Cond: (ctid = '(115,42)'::tid)
(2 rows)Quindi qui nel predicato, invece di fornire un valore esatto della colonna come condizione, viene fornito TID. Questo è qualcosa di simile alla ricerca basata su ROWID in Oracle.
Bonus
Tutti i metodi di scansione sono ampiamente utilizzati e famosi. Inoltre, questi metodi di scansione sono disponibili in quasi tutti i database relazionali. Ma c'è un altro metodo di scansione recentemente in discussione nella comunità di PostgreSQL e anche recentemente aggiunto in altri database relazionali. Si chiama "Loose IndexScan" in MySQL, "Index Skip Scan" in Oracle e "Jump Scan" in DB2.
Questo metodo di scansione viene utilizzato per uno scenario specifico in cui è selezionato un valore distinto della colonna chiave iniziale dell'indice B-Tree. Come parte di questa scansione, evita di attraversare tutti i valori di colonna chiave uguali piuttosto che attraversare semplicemente il primo valore univoco e quindi passare a quello grande successivo.
Questo lavoro è ancora in corso in PostgreSQL con il nome provvisorio "Scansione con salto dell'indice" e potremmo aspettarci di vederlo in una versione futura.