In questa terza parte di analisi comparativa delle soluzioni cloud PostgreSQL gestite , ho approfittato dell'offerta del piano gratuito GCP di Google. È stata un'esperienza utile e come amministratore di sistema che trascorre la maggior parte del suo tempo alla console non potevo perdere l'opportunità di provare la shell cloud, una delle funzionalità della console che distingue Google dal provider di servizi cloud con cui ho più familiarità , Servizi Web Amazon.
Per ricapitolare rapidamente, nella parte 1 ho esaminato gli strumenti di benchmark disponibili e ho spiegato perché ho scelto AWS Benchmark Procedure per Aurora. Ho anche confrontato Amazon Aurora per PostgreSQL versione 10.6. Nella parte 2 ho esaminato AWS RDS per PostgreSQL versione 11.1.
Durante questo round, i test basati sulla procedura di benchmark AWS per Aurora verranno eseguiti su Google Cloud SQL per PostgreSQL 9.6 poiché la versione 11.1 è ancora in versione beta.
Istanze cloud
Prerequisiti
Come accennato nei due articoli precedenti, ho optato per lasciare le impostazioni di PostgreSQL con le impostazioni predefinite del GUC cloud, a meno che non impediscano l'esecuzione dei test (vedi più in basso). Ricordiamo dagli articoli precedenti che il presupposto era che immediatamente il provider cloud dovrebbe avere l'istanza del database configurata per fornire prestazioni ragionevoli.
La patch di temporizzazione di AWS pgbench per PostgreSQL 9.6.5 è stata applicata in modo pulito alla versione Google Cloud di PostgreSQL 9.6.10.
Utilizzando le informazioni pubblicate da Google nel loro blog Google Cloud for AWS Professionals, ho confrontato le specifiche per il client e le istanze di destinazione rispetto ai componenti di elaborazione, archiviazione e rete. Ad esempio, l'equivalente di Google Cloud di AWS Enhanced Networking si ottiene ridimensionando il nodo di calcolo in base alla formula:
max( [vCPUs x 2Gbps/vCPU], 16Gbps)Quando si tratta di configurare l'istanza del database di destinazione, analogamente ad AWS, Google Cloud non consente repliche, tuttavia, lo storage è crittografato a riposo e non è possibile disabilitarlo.
Infine, per ottenere le migliori prestazioni di rete, il client e le istanze di destinazione devono trovarsi nella stessa zona di disponibilità.
Cliente
Le specifiche dell'istanza client che corrispondono a quelle più vicine all'istanza AWS sono:
- vCPU:32 (16 core x 2 thread/core)
- RAM:208 GiB (massimo per l'istanza da 32 vCPU)
- Archiviazione:disco persistente di Compute Engine
- Rete:16 Gbps (massimo [32 vCPU x 2 Gbps/vCPU] e 16 Gbps)
Dettagli dell'istanza dopo l'inizializzazione:
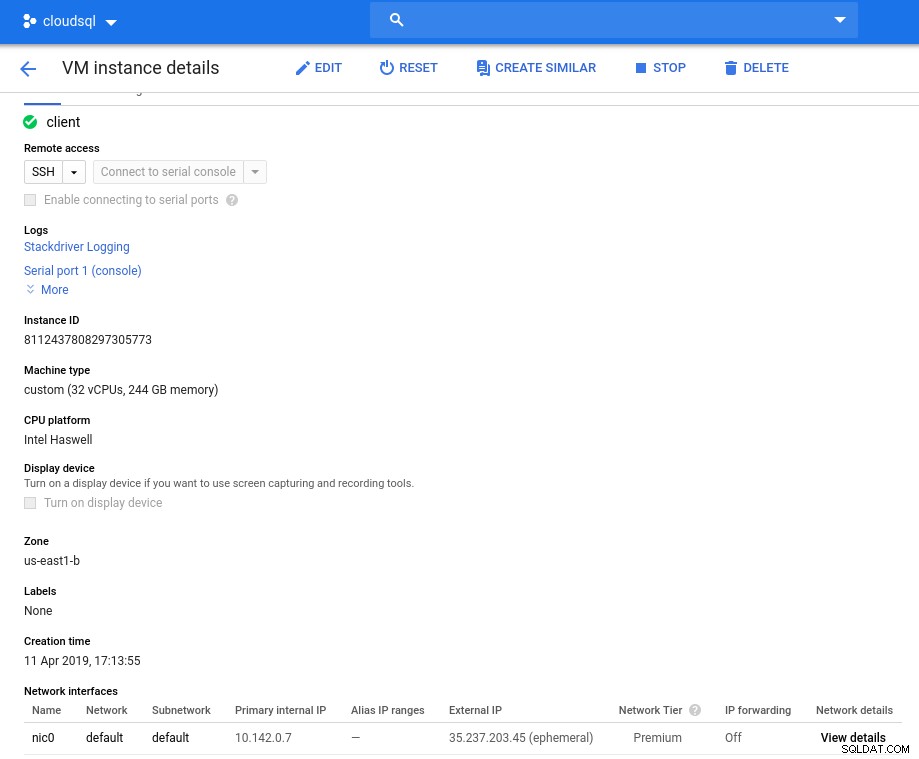 Istanza client:calcolo e rete
Istanza client:calcolo e rete Nota:per impostazione predefinita, le istanze sono limitate a 24 vCPU. L'assistenza tecnica di Google deve approvare l'aumento della quota a 32 vCPU per istanza.

Sebbene tali richieste vengano generalmente gestite entro 2 giorni lavorativi, devo ringraziare i Servizi di assistenza Google per aver completato la mia richiesta in sole 2 ore.
Per i curiosi, la formula della velocità di rete si basa sulla documentazione del motore di calcolo a cui si fa riferimento in questo blog GCP.
Gruppo database
Di seguito sono riportate le specifiche dell'istanza del database:
- vCPU:8
- RAM:52 GiB (massimo)
- Memoria:144 MB/s, 9.000 IOPS
- Rete:2.000 MB/s
Tieni presente che la memoria massima disponibile per un'istanza da 8 vCPU è 52 GiB. È possibile allocare più memoria selezionando un'istanza più grande (più vCPU):
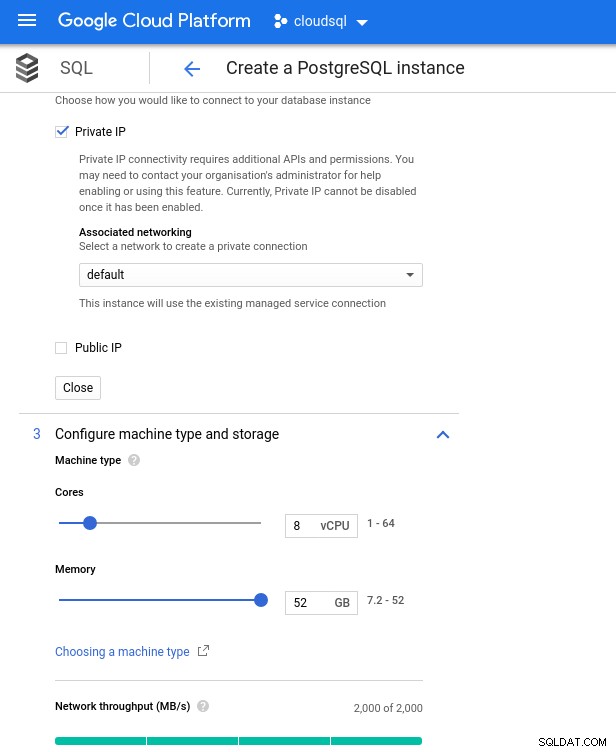 CPU del database e dimensionamento della memoria
CPU del database e dimensionamento della memoria Sebbene Google SQL possa espandere automaticamente lo storage sottostante, che tra l'altro è una funzionalità davvero interessante, ho scelto di disabilitare l'opzione per essere coerente con il set di funzionalità AWS ed evitare un potenziale impatto I/O durante l'operazione di ridimensionamento. ("potenziale", perché non dovrebbe avere alcun impatto negativo, tuttavia nella mia esperienza il ridimensionamento di qualsiasi tipo di storage sottostante aumenta l'I/O, anche se per pochi secondi).
Ricordiamo che l'istanza del database AWS è stata sottoposta a backup da uno storage EBS ottimizzato che ha fornito un massimo di:
- Larghezza di banda 1.700 Mbps
- Velocità effettiva di 212,5 MB/s
- 12.000 IOPS
Con Google Cloud otteniamo una configurazione simile regolando il numero di vCPU (vedi sopra) e la capacità di archiviazione:
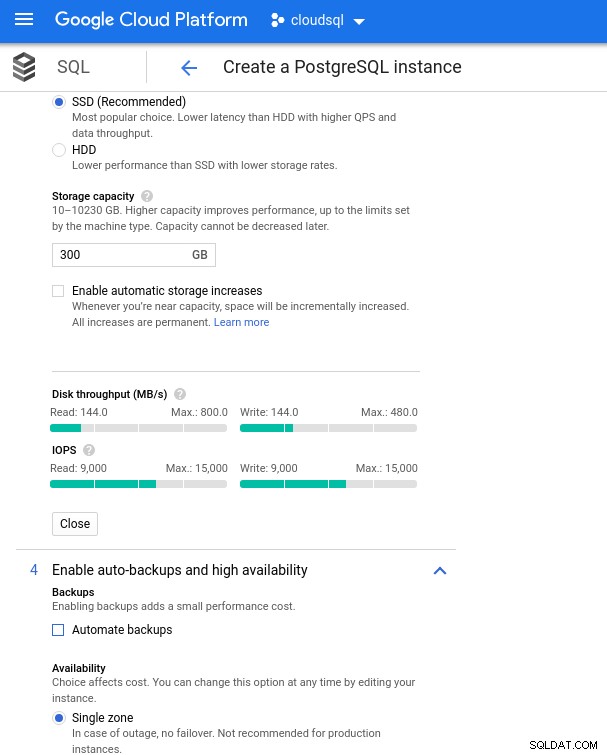 Configurazione dell'archiviazione del database e impostazioni di backup
Configurazione dell'archiviazione del database e impostazioni di backup Esecuzione dei benchmark
Configurazione
Quindi, installa gli strumenti di benchmark, pgbench e sysbench seguendo le istruzioni nella guida Amazon adattata a PostgreSQL versione 9.6.10.
Inizializza le variabili di ambiente PostgreSQL in .bashrc e imposta i percorsi dei binari e delle librerie PostgreSQL:
export PGHOST=10.101.208.7
export PGUSER=postgres
export PGPASSWORD=postgres
export PGDATABASE=postgres
export PGPORT=5432
export PATH=$PATH:/usr/local/pgsql/bin
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/pgsql/libLista di controllo preliminare:
[example@sqldat.com ~]# psql --version
psql (PostgreSQL) 9.6.10
[example@sqldat.com ~]# pgbench --version
pgbench (PostgreSQL) 9.6.10
[example@sqldat.com ~]# sysbench --version
sysbench 0.5
postgres=> select version();
version
---------------------------------------------------------------------------------------------------------
PostgreSQL 9.6.10 on x86_64-pc-linux-gnu, compiled by gcc (Ubuntu 4.8.4-2ubuntu1~14.04.3) 4.8.4, 64-bit
(1 row)E siamo pronti per il decollo:
pannello di gioco
Inizializza il database di pgbench.
[example@sqldat.com ~]# pgbench -i --fillfactor=90 --scale=10000…e qualche minuto dopo:
NOTICE: table "pgbench_history" does not exist, skipping
NOTICE: table "pgbench_tellers" does not exist, skipping
NOTICE: table "pgbench_accounts" does not exist, skipping
NOTICE: table "pgbench_branches" does not exist, skipping
creating tables...
100000 of 1000000000 tuples (0%) done (elapsed 0.09 s, remaining 872.42 s)
200000 of 1000000000 tuples (0%) done (elapsed 0.19 s, remaining 955.00 s)
300000 of 1000000000 tuples (0%) done (elapsed 0.33 s, remaining 1105.08 s)
400000 of 1000000000 tuples (0%) done (elapsed 0.53 s, remaining 1317.56 s)
500000 of 1000000000 tuples (0%) done (elapsed 0.63 s, remaining 1258.72 s)
...
500000000 of 1000000000 tuples (50%) done (elapsed 943.93 s, remaining 943.93 s)
500100000 of 1000000000 tuples (50%) done (elapsed 944.08 s, remaining 943.71 s)
500200000 of 1000000000 tuples (50%) done (elapsed 944.22 s, remaining 943.46 s)
500300000 of 1000000000 tuples (50%) done (elapsed 944.33 s, remaining 943.20 s)
500400000 of 1000000000 tuples (50%) done (elapsed 944.47 s, remaining 942.96 s)
500500000 of 1000000000 tuples (50%) done (elapsed 944.59 s, remaining 942.70 s)
500600000 of 1000000000 tuples (50%) done (elapsed 944.73 s, remaining 942.47 s)
...
999600000 of 1000000000 tuples (99%) done (elapsed 1878.28 s, remaining 0.75 s)
999700000 of 1000000000 tuples (99%) done (elapsed 1878.41 s, remaining 0.56 s)
999800000 of 1000000000 tuples (99%) done (elapsed 1878.58 s, remaining 0.38 s)
999900000 of 1000000000 tuples (99%) done (elapsed 1878.70 s, remaining 0.19 s)
1000000000 of 1000000000 tuples (100%) done (elapsed 1878.83 s, remaining 0.00 s)
vacuum...
set primary keys...
total time: 5978.44 s (insert 1878.90 s, commit 0.04 s, vacuum 2484.96 s, index 1614.54 s)
done.Come ormai siamo abituati, la dimensione del database deve essere 160 GB. Verifichiamo che:
postgres=> SELECT
postgres-> d.datname AS Name,
postgres-> pg_catalog.pg_get_userbyid(d.datdba) AS Owner,
postgres-> pg_catalog.pg_size_pretty(pg_catalog.pg_database_size(d.datname)) AS SIZE
postgres-> FROM pg_catalog.pg_database d
postgres-> WHERE d.datname = 'postgres';
name | owner | size
----------+-------------------+--------
postgres | cloudsqlsuperuser | 160 GB
(1 row)Con tutti i preparativi completati inizia il test di lettura/scrittura:
[example@sqldat.com ~]# pgbench --protocol=prepared -P 60 --time=600 --client=1000 --jobs=2048
starting vacuum...end.
connection to database "postgres" failed:
FATAL: sorry, too many clients already :: proc.c:341
connection to database "postgres" failed:
FATAL: sorry, too many clients already :: proc.c:341
connection to database "postgres" failed:
FATAL: remaining connection slots are reserved for non-replication superuser connectionsOps! Qual è il massimo?
postgres=> show max_connections ;
max_connections
-----------------
600
(1 row)Quindi, mentre AWS imposta un max_connections in gran parte sufficiente poiché non ho riscontrato questo problema, Google Cloud richiede una piccola modifica... Torna alla console cloud, aggiorna il parametro del database, attendi qualche minuto e quindi controlla:
postgres=> show max_connections ;
max_connections
-----------------
1005
(1 row)Riavviando il test tutto sembra funzionare bene:
starting vacuum...end.
progress: 60.0 s, 5461.7 tps, lat 172.821 ms stddev 251.666
progress: 120.0 s, 4444.5 tps, lat 225.162 ms stddev 365.695
progress: 180.0 s, 4338.5 tps, lat 230.484 ms stddev 373.998...ma c'è un altro problema. Ho avuto una sorpresa quando ho tentato di aprire una nuova sessione psql per contare il numero di connessioni:
psql: FATAL: remaining connection slots are reserved for non-replication superuser connectionsPotrebbe essere che superuser_reserved_connections non sia al suo valore predefinito?
postgres=> show superuser_reserved_connections ;
superuser_reserved_connections
--------------------------------
3
(1 row)Questa è l'impostazione predefinita, quindi cos'altro potrebbe essere?
postgres=> select usename from pg_stat_activity ;
usename
---------------
cloudsqladmin
cloudsqlagent
postgres
(3 rows)Bingo! Un altro aumento di max_connections se ne occupa, tuttavia, ha richiesto il riavvio del test pgbench. E questa è la storia dietro l'apparente duplicato eseguito nei grafici sottostanti.
E infine, i risultati sono in:
progress: 60.0 s, 4553.6 tps, lat 194.696 ms stddev 250.663
progress: 120.0 s, 3646.5 tps, lat 278.793 ms stddev 434.459
progress: 180.0 s, 3130.4 tps, lat 332.936 ms stddev 711.377
progress: 240.0 s, 3998.3 tps, lat 250.136 ms stddev 319.215
progress: 300.0 s, 3305.3 tps, lat 293.250 ms stddev 549.216
progress: 360.0 s, 3547.9 tps, lat 289.526 ms stddev 454.484
progress: 420.0 s, 3770.5 tps, lat 265.977 ms stddev 470.451
progress: 480.0 s, 3050.5 tps, lat 327.917 ms stddev 643.983
progress: 540.0 s, 3591.7 tps, lat 273.906 ms stddev 482.020
progress: 600.0 s, 3350.9 tps, lat 296.303 ms stddev 566.792
transaction type: <builtin: TPC-B (sort of)>
scaling factor: 10000
query mode: prepared
number of clients: 1000
number of threads: 1000
duration: 600 s
number of transactions actually processed: 2157735
latency average = 278.149 ms
latency stddev = 503.396 ms
tps = 3573.331659 (including connections establishing)
tps = 3591.759513 (excluding connections establishing)sistema di analisi
Compila il database:
sysbench --test=/usr/local/share/sysbench/oltp.lua \
--pgsql-host=${PGHOST} \
--pgsql-db=${PGDATABASE} \
--pgsql-user=${PGUSER} \
--pgsql-password=${PGPASSWORD} \
--pgsql-port=${PGPORT} \
--oltp-tables-count=250\
--oltp-table-size=450000 \
prepareUscita:
sysbench 0.5: multi-threaded system evaluation benchmark
Creating table 'sbtest1'...
Inserting 450000 records into 'sbtest1'
Creating secondary indexes on 'sbtest1'...
Creating table 'sbtest2'...
Inserting 450000 records into 'sbtest2'
...
Creating table 'sbtest249'...
Inserting 450000 records into 'sbtest249'
Creating secondary indexes on 'sbtest249'...
Creating table 'sbtest250'...
Inserting 450000 records into 'sbtest250'
Creating secondary indexes on 'sbtest250'...E ora esegui il test:
sysbench --test=/usr/local/share/sysbench/oltp.lua \
--pgsql-host=${PGHOST} \
--pgsql-db=${PGDATABASE} \
--pgsql-user=${PGUSER} \
--pgsql-password=${PGPASSWORD} \
--pgsql-port=${PGPORT} \
--oltp-tables-count=250 \
--oltp-table-size=450000 \
--max-requests=0 \
--forced-shutdown \
--report-interval=60 \
--oltp_simple_ranges=0 \
--oltp-distinct-ranges=0 \
--oltp-sum-ranges=0 \
--oltp-order-ranges=0 \
--oltp-point-selects=0 \
--rand-type=uniform \
--max-time=600 \
--num-threads=1000 \
runE i risultati:
sysbench 0.5: multi-threaded system evaluation benchmark
Running the test with following options:
Number of threads: 1000
Report intermediate results every 60 second(s)
Random number generator seed is 0 and will be ignored
Forcing shutdown in 630 seconds
Initializing worker threads...
Threads started!
[ 60s] threads: 1000, tps: 1320.25, reads: 0.00, writes: 5312.62, response time: 1484.54ms (95%), errors: 0.00, reconnects: 0.00
[ 120s] threads: 1000, tps: 1486.77, reads: 0.00, writes: 5944.30, response time: 1290.87ms (95%), errors: 0.00, reconnects: 0.00
[ 180s] threads: 1000, tps: 1143.62, reads: 0.00, writes: 4585.67, response time: 1649.50ms (95%), errors: 0.02, reconnects: 0.00
[ 240s] threads: 1000, tps: 1498.23, reads: 0.00, writes: 5993.06, response time: 1269.03ms (95%), errors: 0.00, reconnects: 0.00
[ 300s] threads: 1000, tps: 1520.53, reads: 0.00, writes: 6058.57, response time: 1439.90ms (95%), errors: 0.02, reconnects: 0.00
[ 360s] threads: 1000, tps: 1234.57, reads: 0.00, writes: 4958.08, response time: 1550.39ms (95%), errors: 0.02, reconnects: 0.00
[ 420s] threads: 1000, tps: 1722.25, reads: 0.00, writes: 6890.98, response time: 1132.25ms (95%), errors: 0.00, reconnects: 0.00
[ 480s] threads: 1000, tps: 2306.25, reads: 0.00, writes: 9233.84, response time: 842.11ms (95%), errors: 0.00, reconnects: 0.00
[ 540s] threads: 1000, tps: 1432.85, reads: 0.00, writes: 5720.15, response time: 1709.83ms (95%), errors: 0.02, reconnects: 0.00
[ 600s] threads: 1000, tps: 1332.93, reads: 0.00, writes: 5347.10, response time: 1443.78ms (95%), errors: 0.02, reconnects: 0.00
OLTP test statistics:
queries performed:
read: 0
write: 3603595
other: 1801795
total: 5405390
transactions: 900895 (1500.68 per sec.)
read/write requests: 3603595 (6002.76 per sec.)
other operations: 1801795 (3001.38 per sec.)
ignored errors: 5 (0.01 per sec.)
reconnects: 0 (0.00 per sec.)
General statistics:
total time: 600.3231s
total number of events: 900895
total time taken by event execution: 600164.2510s
response time:
min: 6.78ms
avg: 666.19ms
max: 4218.55ms
approx. 95 percentile: 1397.02ms
Threads fairness:
events (avg/stddev): 900.8950/14.19
execution time (avg/stddev): 600.1643/0.10Metriche benchmark
Il plug-in PostgreSQL per Stackdriver è stato ritirato dal 28 febbraio 2019. Anche se Google consiglia Blue Medora, ai fini di questo articolo ho scelto di eliminare la creazione di un account e di fare affidamento sulle metriche Stackdriver disponibili.
- Utilizzo CPU:
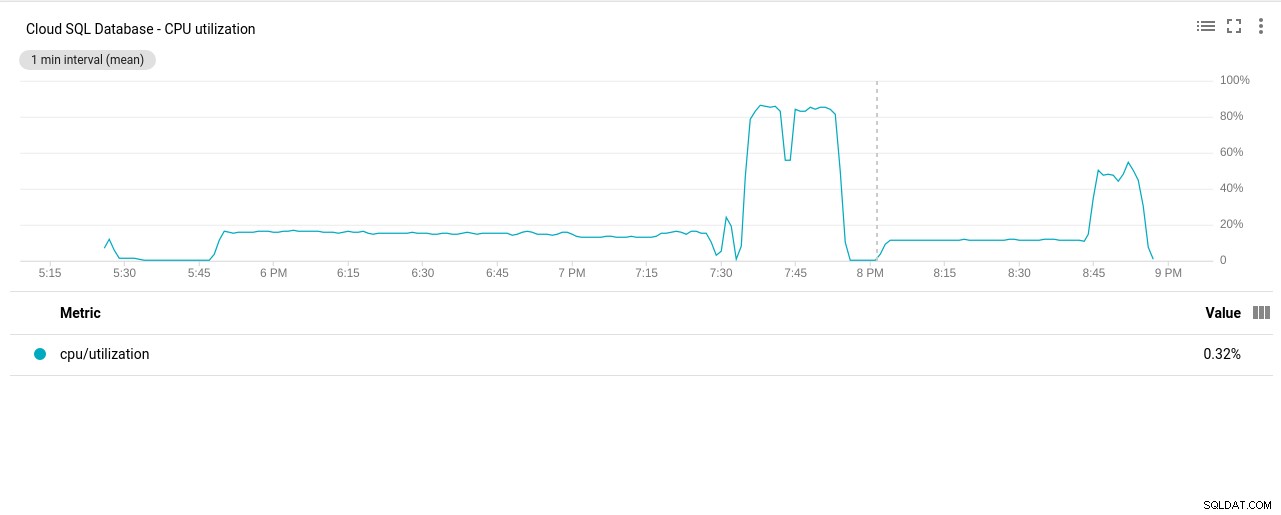 Autore della foto Google Cloud SQL:Utilizzo della CPU PostgreSQL
Autore della foto Google Cloud SQL:Utilizzo della CPU PostgreSQL - Operazioni di lettura/scrittura del disco:
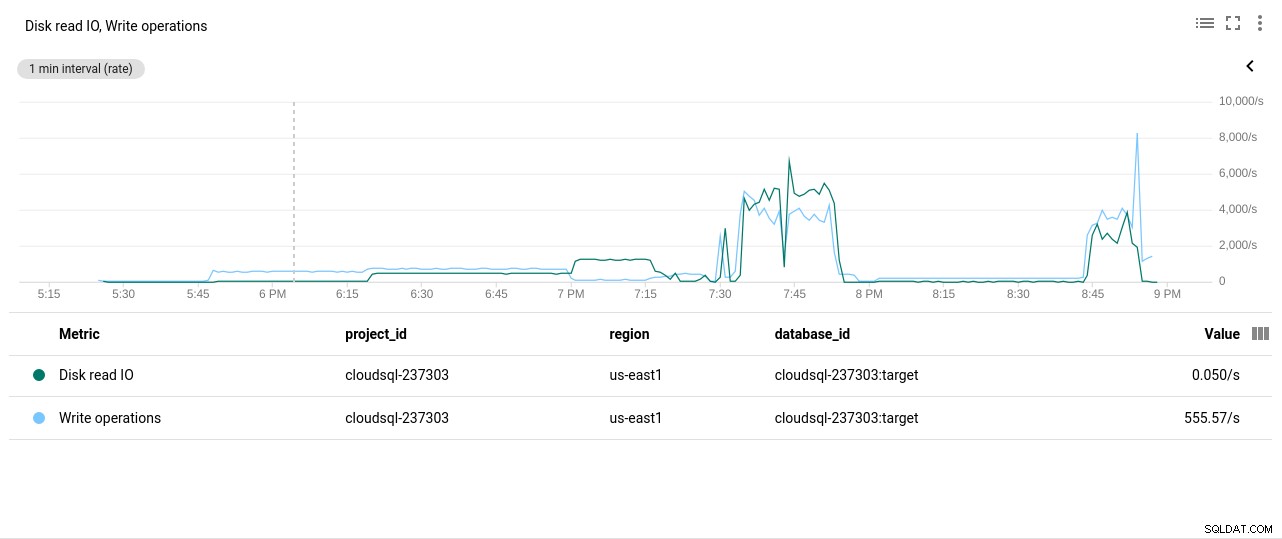 Autore foto Google Cloud SQL:operazioni di lettura/scrittura disco PostgreSQL
Autore foto Google Cloud SQL:operazioni di lettura/scrittura disco PostgreSQL - Byte inviati/ricevuti dalla rete:
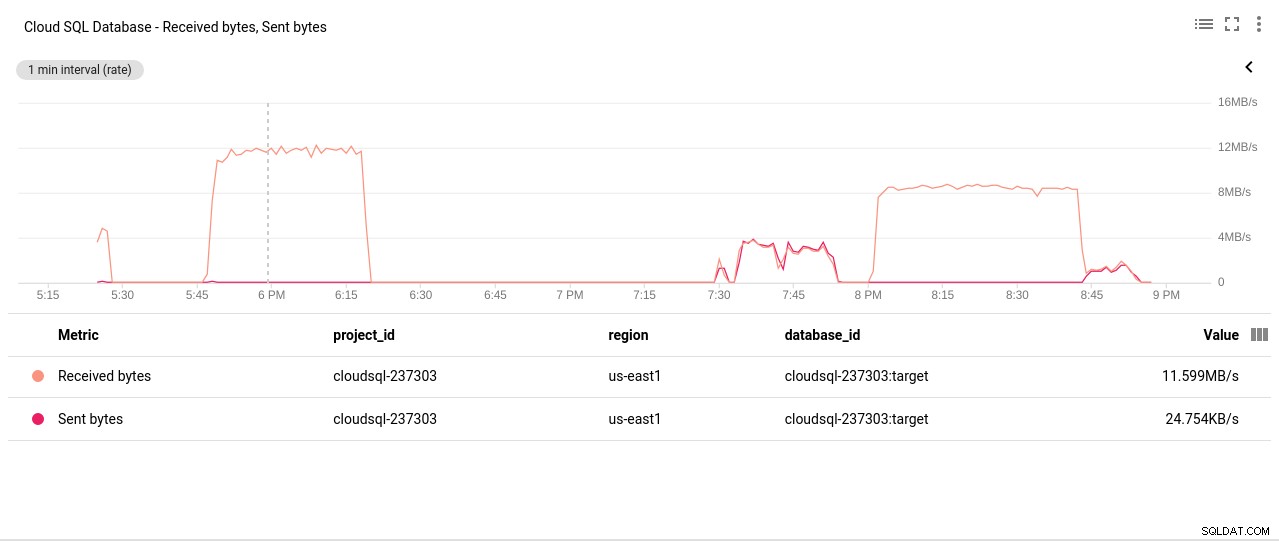 Autore foto Google Cloud SQL:PostgreSQL Network Sent/Received byte
Autore foto Google Cloud SQL:PostgreSQL Network Sent/Received byte - Conteggio connessioni PostgreSQL:
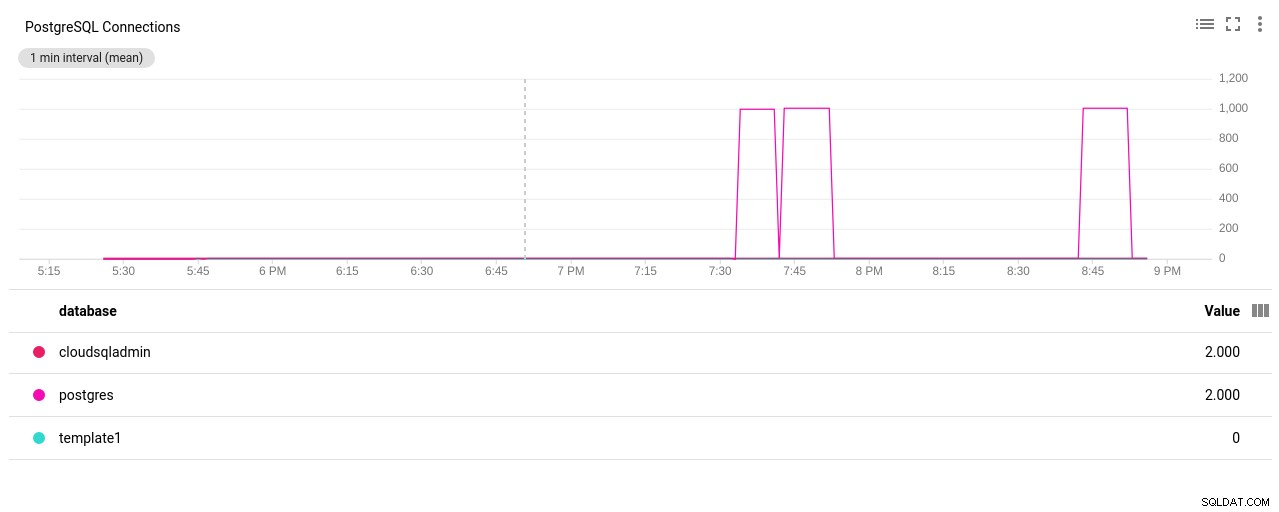 Autore foto Google Cloud SQL:Conteggio connessioni PostgreSQL
Autore foto Google Cloud SQL:Conteggio connessioni PostgreSQL
Risultati benchmark
Inizializzazione di pgbench
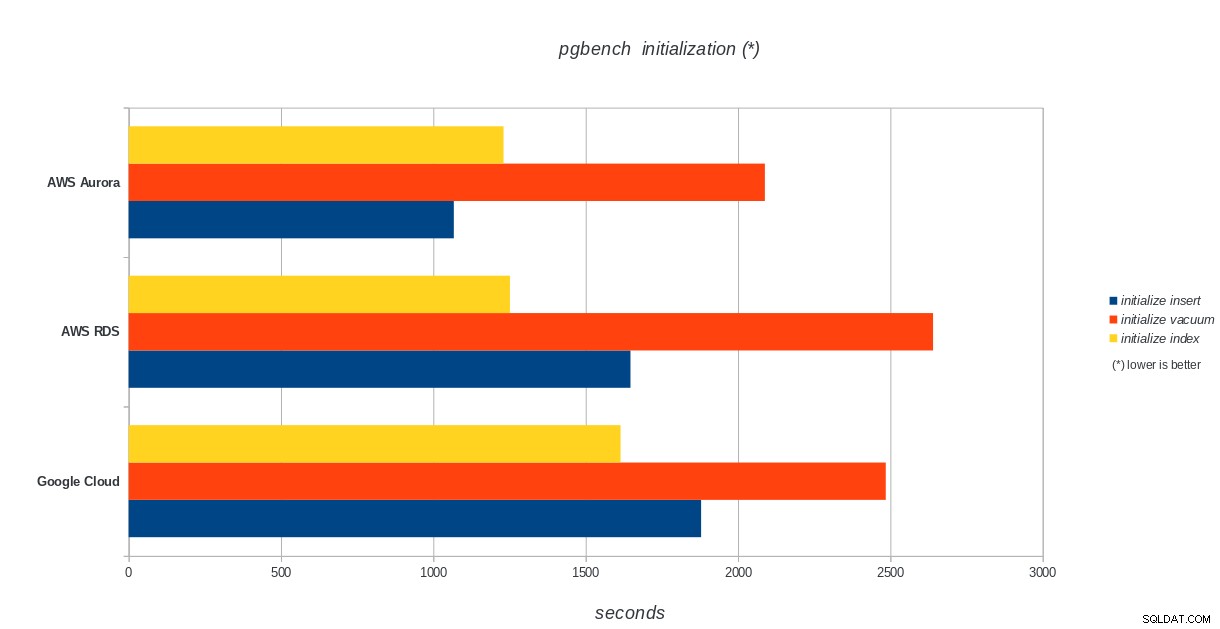 AWS Aurora, AWS RDS, Google Cloud SQL:risultati dell'inizializzazione di PostgreSQL pgbench
AWS Aurora, AWS RDS, Google Cloud SQL:risultati dell'inizializzazione di PostgreSQL pgbench pgbench eseguito
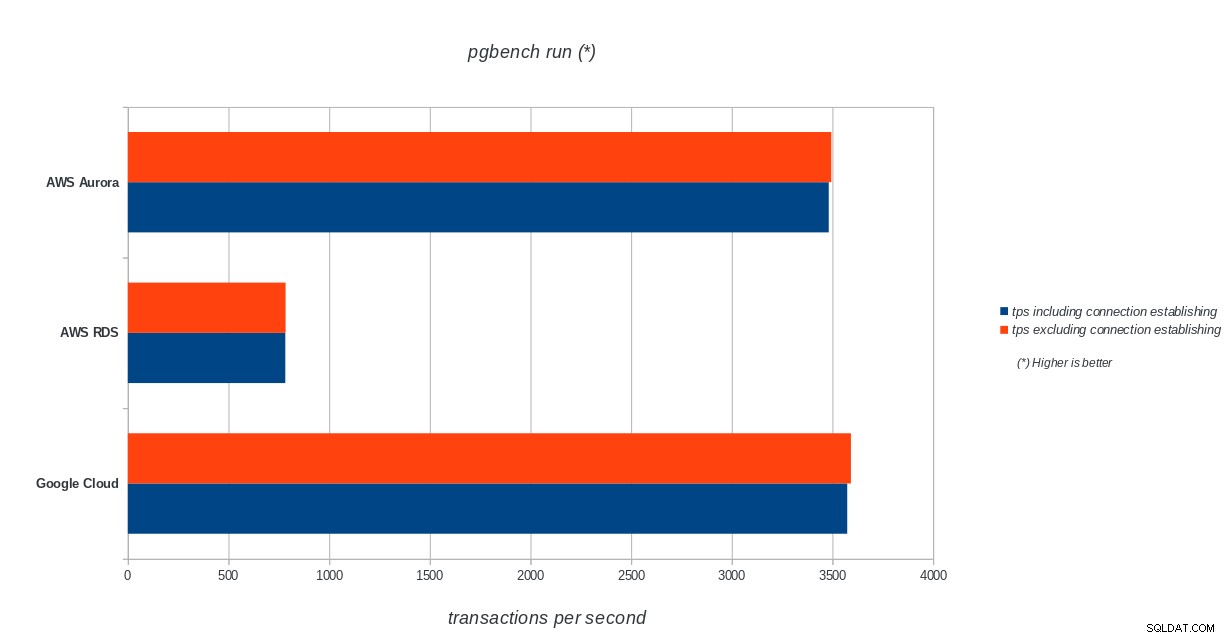 AWS Aurora, AWS RDS, Google Cloud SQL:risultati di esecuzione di PostgreSQL pgbench
AWS Aurora, AWS RDS, Google Cloud SQL:risultati di esecuzione di PostgreSQL pgbench sistema di analisi
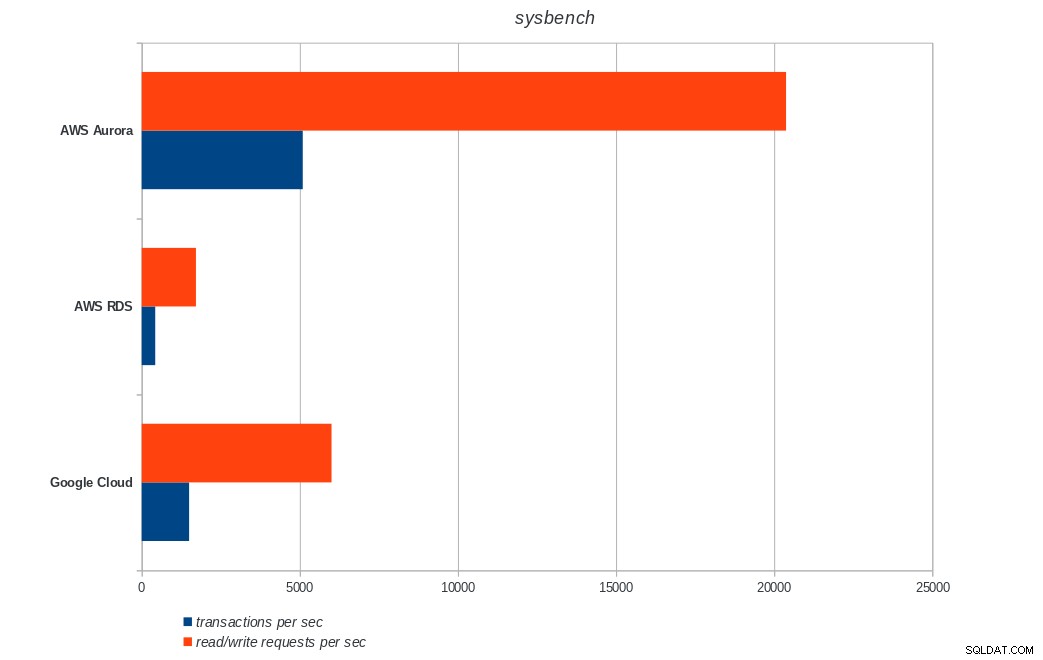 AWS Aurora, AWS RDS, Google Cloud SQL:risultati di PostgreSQL sysbench
AWS Aurora, AWS RDS, Google Cloud SQL:risultati di PostgreSQL sysbench Conclusione
Amazon Aurora è di gran lunga il primo nei test di scrittura pesante (sysbench), pur essendo alla pari con Google Cloud SQL nei test di lettura/scrittura di pgbench. Il test di carico (inizializzazione di pgbench) mette Google Cloud SQL al primo posto, seguito da Amazon RDS. Sulla base di uno sguardo superficiale ai modelli di prezzo per AWS Aurora e Google Cloud SQL, oserei dire che Google Cloud è una scelta migliore per l'utente medio, mentre AWS Aurora è più adatto per ambienti ad alte prestazioni. Seguiranno ulteriori analisi dopo aver completato tutti i benchmark.
La prossima e ultima parte di questa serie di benchmark sarà su Microsoft Azure PostgreSQL.
Grazie per la lettura e per favore commenta di seguito se hai feedback.