Questo fa parte di una serie di operatori problematici interni di SQL Server. Assicurati di leggere il primo e il secondo post di Kalen su questo argomento.
SQL Server esiste da oltre 30 anni e lavoro con SQL Server da quasi lo stesso tempo. Ho visto molti cambiamenti nel corso degli anni (e decenni!) e delle versioni di questo incredibile prodotto. In questi post, condividerò con te il modo in cui considero alcune delle funzionalità o aspetti di SQL Server, a volte insieme a un po' di prospettiva storica.
L'ultima volta ho parlato dell'hashing in un piano di query di SQL Server come operatore potenzialmente problematico nella diagnostica del server SQL. L'hashing viene spesso utilizzato per i join e l'aggregazione quando non sono disponibili indici utili. E come le scansioni (di cui ho parlato nel primo post di questa serie), ci sono momenti in cui l'hashing è in realtà una scelta migliore rispetto alle alternative. Per gli hash join, una delle alternative è LOOP JOIN, di cui ti ho parlato anche l'ultima volta.
In questo post, ti parlerò di un'altra alternativa per l'hashing. La maggior parte delle alternative all'hashing richiede l'ordinamento dei dati, quindi il piano deve includere un operatore SORT oppure i dati richiesti devono essere già ordinati a causa degli indici esistenti.
Diversi tipi di join per la diagnostica di SQL Server
Per le operazioni JOIN, il tipo più comune e utile di JOIN è un LOOP JOIN. Ho descritto l'algoritmo per un LOOP JOIN nel post precedente. Sebbene i dati stessi non debbano essere ordinati per un LOOP JOIN, la presenza di un indice nella tabella interna rende il join molto più efficiente e, come dovresti sapere, la presenza di un indice implica un certo ordinamento. Mentre un indice cluster ordina i dati stessi, un indice non cluster ordina le colonne della chiave dell'indice. Infatti, nella maggior parte dei casi, senza l'indice, l'ottimizzatore di SQL Server sceglierà di utilizzare l'algoritmo HASH JOIN. L'abbiamo visto nell'esempio l'ultima volta, che senza indici è stato scelto HASH JOIN e con gli indici abbiamo ottenuto un LOOP JOIN.
Il terzo tipo di join è un MERGE JOIN. Questo algoritmo funziona su due set di dati già ordinati. Se stiamo cercando di combinare (o UNIRE) due set di dati che sono già ordinati, basta un solo passaggio attraverso ciascun set per trovare le righe corrispondenti. Ecco lo pseudocodice per l'algoritmo di merge join:
get first row R1 from input 1
get first row R2 from input 2
while not at the end of either input
begin
if R1 joins with R2
begin
output (R1, R2)
get next row R2 from input 2
end
else if R1 < R2
get next row R1 from input 1
else
get next row R2 from input 2
end
Sebbene MERGE JOIN sia un algoritmo molto efficiente, richiede che entrambi i set di dati di input siano ordinati in base alla chiave di unione, il che di solito significa avere un indice cluster sulla chiave di unione per entrambe le tabelle. Dal momento che ottieni un solo indice cluster per tabella, scegliere la colonna della chiave cluster solo per consentire l'esecuzione di MERGE JOINS potrebbe non essere la scelta generale migliore per la chiave di clustering.
Quindi, di solito, non ti consiglio di provare a creare indici solo allo scopo di MERGE JOINS, ma se finisci per ottenere un MERGE JOIN a causa di indici già esistenti, di solito è una buona cosa. Oltre a richiedere l'ordinamento di entrambi i set di dati di input, MERGE JOIN richiede anche che almeno uno dei set di dati abbia valori univoci per la chiave di unione.
Diamo un'occhiata a un esempio. Innanzitutto, ricreeremo le Intestazioni e Dettagli tabelle:
USE AdventureWorks2016;
GO
DROP TABLE IF EXISTS Details;
GO
SELECT * INTO Details FROM Sales.SalesOrderDetail;
GO
DROP TABLE IF EXISTS Headers;
GO
SELECT * INTO Headers FROM Sales.SalesOrderHeader;
GO
CREATE CLUSTERED INDEX Header_index on Headers(SalesOrderID);
GO
CREATE CLUSTERED INDEX Detail_index on Details(SalesOrderID);
GO
Quindi, guarda il piano per un join tra queste tabelle:
SELECT *
FROM Details d JOIN Headers h
ON d.SalesOrderID = h.SalesOrderID;
GO
Ecco il piano:

Nota che anche con un indice cluster su entrambe le tabelle, otteniamo un HASH JOIN. Possiamo ricostruire uno degli indici in modo che sia UNICO. In questo caso, deve essere l'indice sulle Intestazioni tabella, perché è l'unico che ha valori univoci per SalesOrderID.
CREATE UNIQUE CLUSTERED INDEX Header_index on Headers(SalesOrderID) WITH DROP_EXISTING;
GO
Ora, esegui di nuovo la query e nota che il piano funziona come MERGE JOIN.

Questi piani traggono vantaggio dall'avere i dati già ordinati in un indice, poiché il piano di esecuzione può sfruttare l'ordinamento. Ma a volte, SQL Server deve eseguire l'ordinamento come parte dell'esecuzione della query. Occasionalmente potresti vedere un operatore SORT apparire in un piano anche se non chiedi un output ordinato. Se SQL Server ritiene che un MERGE JOIN possa essere una buona opzione, ma una delle tabelle non ha l'indice cluster appropriato ed è sufficientemente piccola da rendere l'ordinamento molto economico, è possibile eseguire un SORT per consentire a MERGE JOIN di essere usato.
Ma di solito, l'operatore SORT compare nelle query in cui abbiamo chiesto dati ordinati con ORDER BY, come nell'esempio seguente.
SELECT * FROM Details
ORDER BY ProductID;
GO

Viene scansionato l'indice cluster (che equivale a scansionare la tabella) e quindi le righe vengono ordinate come richiesto.
Gestione dell'indice cluster già ordinato
Ma cosa succede se i dati sono già ordinati in un indice cluster e la query include un ORDER BY nella colonna della chiave cluster? Nell'esempio precedente, abbiamo creato un indice cluster su SalesOrderID nella tabella Dettagli. Guarda le seguenti due query:
SELECT * FROM Details;
GO
SELECT * FROM Details
ORDER BY SalesOrderID;
GO
Se eseguiamo queste query insieme, la finestra di analisi del pacchetto di ottimizzazione di Quest Spotlight indica che i due piani hanno lo stesso costo; ciascuno è il 50% del totale. Allora, qual è effettivamente la differenza tra loro?
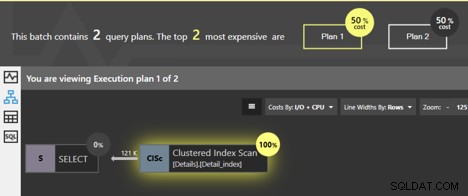
Entrambe le query eseguono la scansione dell'indice cluster e SQL Server sa che se le pagine del livello foglia vengono seguite nell'ordine, i dati torneranno nell'ordine delle chiavi del cluster. Non è necessario eseguire ulteriori ordinamenti, quindi al piano non viene aggiunto alcun operatore SORT. Ma c'è una differenza. Possiamo fare clic sull'operatore Clustered Index Scan e otterremo alcune informazioni dettagliate.
Per prima cosa, guarda le informazioni dettagliate per il primo piano, per la query senza ORDER BY.

I dettagli ci dicono che la proprietà "Ordinato" è Falsa. Non è necessario qui che i dati vengano restituiti in ordine. Si scopre che nella maggior parte dei casi, il modo più semplice per recuperare i dati è seguire le pagine dell'indice cluster, quindi i dati finiranno per essere restituiti in ordine, ma non vi è alcuna garanzia. Il significato della proprietà False è che non è necessario che SQL Server segua le pagine ordinate per restituire il risultato. Esistono in realtà altri modi in cui SQL Server può ottenere tutte le righe per la tabella, senza seguire l'indice cluster. Se durante l'esecuzione SQL Server sceglie di utilizzare un metodo diverso per ottenere le righe, non vedremmo risultati ordinati.
Per la seconda query, i dettagli sono così:
 Poiché la query includeva un ORDER BY, è necessario che i dati vengano restituiti in ordine e SQL Server seguirà le pagine dell'indice cluster, in ordine.
Poiché la query includeva un ORDER BY, è necessario che i dati vengano restituiti in ordine e SQL Server seguirà le pagine dell'indice cluster, in ordine.
La cosa più importante da ricordare qui è che NESSUNA garanzia di dati ordinati se non includi ORDER BY nella tua query. Solo perché hai un indice cluster, non c'è ancora alcuna garanzia! Anche se ogni volta che nell'ultimo anno hai eseguito la query, hai riordinato i dati senza ORDER BY, non vi è alcuna garanzia che continuerai a riordinare i dati. L'utilizzo di ORDER BY è l'unico modo per garantire l'ordine in cui vengono restituiti i risultati.
Suggerimenti per l'utilizzo delle operazioni di ordinamento
Quindi, un SORT è un'operazione da evitare nella diagnostica del server SQL? Proprio come le scansioni e le operazioni di hash, la risposta è, ovviamente, "dipende". L'ordinamento può essere molto costoso, soprattutto su set di dati di grandi dimensioni. L'indicizzazione corretta aiuta SQL Server a evitare di eseguire operazioni SORT perché un indice significa sostanzialmente che i dati sono preordinati. Ma l'indicizzazione ha un costo. C'è un costo di archiviazione, oltre al costo di manutenzione, per ogni indice. Se i tuoi dati sono molto aggiornati, devi mantenere il numero di indici al minimo.
Se si scopre che alcune delle query a esecuzione lenta mostrano operazioni SORT nei loro piani e se tali SORT sono tra gli operatori più costosi nel piano, è possibile considerare la creazione di indici che consentano a SQL Server di evitare l'ordinamento. Ma dovrai eseguire test approfonditi per assicurarti che gli indici aggiuntivi non rallentino altre query che sono cruciali per le prestazioni complessive dell'applicazione.