Introduzione
Alcuni anni fa ci è stato affidato un requisito aziendale per i dati delle carte in un formato specifico allo scopo di qualcosa chiamato "riconciliazione". L'idea era di presentare i dati in una tabella a un'applicazione che avrebbe consumato ed elaborato i dati che avrebbero avuto un periodo di conservazione di sei mesi. Abbiamo dovuto creare un nuovo database per questa esigenza aziendale e quindi creare la tabella principale come tabella partizionata. Il processo qui descritto è il processo che utilizziamo per garantire che i dati più vecchi di sei mesi vengano spostati fuori dalla tabella in modo pulito.
Un po' di partizionamento
Il partizionamento delle tabelle è una tecnologia di database che consente di archiviare i dati appartenenti a un'unità logica (la tabella) come un insieme di partizioni che rimarranno su una struttura fisica separata, i file di dati, attraverso un livello di astrazione chiamato File Groups in SQL Server. Il processo di creazione di questa tabella partizionata coinvolge due oggetti chiave:
Una funzione di partizione :una funzione di partizione definisce come vengono mappate le righe di una tabella partizionata in base ai valori di una colonna specificata (la colonna di partizione). Una tabella partizionata può essere basata su un elenco o un intervallo. Ai fini del nostro caso d'uso (conservando solo sei mesi di dati), abbiamo utilizzato una partizione di intervallo . Una funzione di partizione può essere definita come RANGE DESTRA o RANGE SINISTRA. Abbiamo utilizzato RANGE RIGHT come mostrato nel codice nel Listato 1, il che significa che il valore limite apparterrà al lato destro dell'intervallo del valore limite quando i valori sono ordinati in ordine crescente da sinistra a destra.
-- Listing 1: Create a Partition Function
USE [post_office_history]
GO
CREATE PARTITION FUNCTION
PostTranPartFunc (datetime)
AS RANGE RIGHT
FOR VALUES
('20190201'
,'20190301'
,'20190401'
,'20190501'
,'20190601'
,'20190701'
,'20190801'
,'20190901'
,'20191001'
,'20191101'
,'20191201'
)
GO Uno schema di partizione :Uno schema di partizione si basa sulla funzione di partizione e determina su quali strutture fisiche verranno posizionate le righe appartenenti a ciascuna partizione. Ciò si ottiene mappando tali righe in filegroup. Il Listato 2 mostra il codice per creare uno schema di partizione. Prima di creare lo schema di partizione, devono esistere i filegroup a cui farà riferimento.
-- Listing 2: Create Partition Scheme -- -- Step 1: Create Filegroups -- USE [master] GO ALTER DATABASE [post_office_history] ADD FILEGROUP [JAN] ALTER DATABASE [post_office_history] ADD FILEGROUP [FEB] ALTER DATABASE [post_office_history] ADD FILEGROUP [MAR] ALTER DATABASE [post_office_history] ADD FILEGROUP [APR] ALTER DATABASE [post_office_history] ADD FILEGROUP [MAY] ALTER DATABASE [post_office_history] ADD FILEGROUP [JUN] ALTER DATABASE [post_office_history] ADD FILEGROUP [JUL] ALTER DATABASE [post_office_history] ADD FILEGROUP [AUG] ALTER DATABASE [post_office_history] ADD FILEGROUP [SEP] ALTER DATABASE [post_office_history] ADD FILEGROUP [OCT] ALTER DATABASE [post_office_history] ADD FILEGROUP [NOV] ALTER DATABASE [post_office_history] ADD FILEGROUP [DEC] GO -- Step 2: Add Data Files to each Filegroup -- USE [master] GO ALTER DATABASE [post_office_history] ADD FILE (NAME = N'post_office_history_part_01', FILENAME = N'E:\MSSQL\DATA\post_office_history_part_01.ndf', SIZE = 2097152KB, FILEGROWTH = 1048576KB) TO FILEGROUP [JAN] ALTER DATABASE [post_office_history] ADD FILE (NAME = N'post_office_history_part_02', FILENAME = N'E:\MSSQL\DATA\post_office_history_part_02.ndf', SIZE = 2097152KB, FILEGROWTH = 1048576KB) TO FILEGROUP [FEB] ALTER DATABASE [post_office_history] ADD FILE (NAME = N'post_office_history_part_03', FILENAME = N'E:\MSSQL\DATA\post_office_history_part_03.ndf', SIZE = 2097152KB, FILEGROWTH = 1048576KB) TO FILEGROUP [MAR] ALTER DATABASE [post_office_history] ADD FILE (NAME = N'post_office_history_part_04', FILENAME = N'E:\MSSQL\DATA\post_office_history_part_04.ndf', SIZE = 2097152KB, FILEGROWTH = 1048576KB) TO FILEGROUP [APR] ALTER DATABASE [post_office_history] ADD FILE (NAME = N'post_office_history_part_05', FILENAME = N'E:\MSSQL\DATA\post_office_history_part_05.ndf', SIZE = 2097152KB, FILEGROWTH = 1048576KB) TO FILEGROUP [MAY] ALTER DATABASE [post_office_history] ADD FILE (NAME = N'post_office_history_part_06', FILENAME = N'G:\MSSQL\DATA\post_office_history_part_06.ndf', SIZE = 2097152KB, FILEGROWTH = 1048576KB) TO FILEGROUP [JUN] ALTER DATABASE [post_office_history] ADD FILE (NAME = N'post_office_history_part_07', FILENAME = N'G:\MSSQL\DATA\post_office_history_part_07.ndf', SIZE = 2097152KB, FILEGROWTH = 1048576KB) TO FILEGROUP [JUL] ALTER DATABASE [post_office_history] ADD FILE (NAME = N'post_office_history_part_08', FILENAME = N'G:\MSSQL\DATA\post_office_history_part_08.ndf', SIZE = 2097152KB, FILEGROWTH = 1048576KB) TO FILEGROUP [AUG] ALTER DATABASE [post_office_history] ADD FILE (NAME = N'post_office_history_part_09', FILENAME = N'G:\MSSQL\DATA\post_office_history_part_09.ndf', SIZE = 2097152KB, FILEGROWTH = 1048576KB) TO FILEGROUP [SEP] ALTER DATABASE [post_office_history] ADD FILE (NAME = N'post_office_history_part_10', FILENAME = N'G:\MSSQL\DATA\post_office_history_part_10.ndf', SIZE = 2097152KB, FILEGROWTH = 1048576KB) TO FILEGROUP [OCT] GO ALTER DATABASE [post_office_history] ADD FILE (NAME = N'post_office_history_part_09', FILENAME = N'G:\MSSQL\DATA\post_office_history_part_11.ndf', SIZE = 2097152KB, FILEGROWTH = 1048576KB) TO FILEGROUP [NOV] ALTER DATABASE [post_office_history] ADD FILE (NAME = N'post_office_history_part_10', FILENAME = N'G:\MSSQL\DATA\post_office_history_part_12.ndf', SIZE = 2097152KB, FILEGROWTH = 1048576KB) TO FILEGROUP [DEC] GO -- Step 3: Create Partition Scheme -- PRINT 'creating partition scheme ...' GO USE [post_office_history] GO CREATE PARTITION SCHEME PostTranPartSch AS PARTITION PostTranPartFunc TO ( JAN, FEB, MAR, APR, MAY, JUN, JUL, AUG, SEP, OCT, NOV, DEC ) GO
Si noti che per N partizioni, ci sarà sempre N-1 confini. È necessario prestare attenzione quando si definisce il primo Filegroup nello schema di partizione. Il primo limite elencato nella funzione di partizione si troverà tra il primo e il secondo filegroup, quindi questo valore limite (20190201) si troverà nella seconda partizione (FEB). Inoltre, è effettivamente possibile posizionare tutte le partizioni in un singolo filegroup, ma in questo caso abbiamo scelto filegroup separati.
Ci sporchiamo le mani
Quindi tuffiamoci nel compito di cambiare le partizioni!
La prima cosa che dobbiamo fare è determinare esattamente come i nostri dati sono distribuiti tra le partizioni in modo da poter sapere quale partizione vorremmo cambiare. In genere cambieremo la partizione più vecchia.
-- Listing 3: Check Data Distribution in Partitions -- USE POST_OFFICE_HISTORY GO SELECT $PARTITION.POSTTRANPARTFUNC(DATETIME_TRAN_LOCAL) AS [PARTITION NUMBER] , MIN(DATETIME_TRAN_LOCAL) AS [MIN DATE] , MAX(DATETIME_TRAN_LOCAL) AS [MAX DATE] , COUNT(*) AS [ROWS IN PARTITION] FROM DBO.POST_TRAN_TAB -- PARTITIONED TABLE GROUP BY $PARTITION.POSTTRANPARTFUNC(DATETIME_TRAN_LOCAL) ORDER BY [PARTITION NUMBER] GO
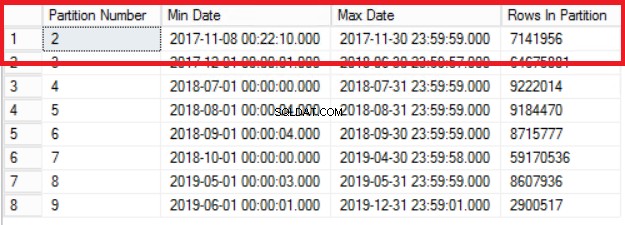
Fig. 1 Output del Listato 3
La Fig. 1 ci mostra l'output della query nel Listato 3. La partizione più vecchia è la Partizione 2 che contiene righe dell'anno 2017. Lo verifichiamo con la query nel Listato 4. Il Listato 4 ci mostra anche quale Filegroup contiene i dati nella Partizione 2.
-- Listing 4: Check Filegroup Associated with Partition --
USE POST_OFFICE_HISTORY
GO
SELECT PS.NAME AS PSNAME,
DDS.DESTINATION_ID AS PARTITIONNUMBER,
FG.NAME AS FILEGROUPNAME
FROM (((SYS.TABLES AS T
INNER JOIN SYS.INDEXES AS I
ON (T.OBJECT_ID = I.OBJECT_ID))
INNER JOIN SYS.PARTITION_SCHEMES AS PS
ON (I.DATA_SPACE_ID = PS.DATA_SPACE_ID))
INNER JOIN SYS.DESTINATION_DATA_SPACES AS DDS
ON (PS.DATA_SPACE_ID = DDS.PARTITION_SCHEME_ID))
INNER JOIN SYS.FILEGROUPS AS FG
ON DDS.DATA_SPACE_ID = FG.DATA_SPACE_ID
WHERE (T.NAME = 'POST_TRAN_TAB') AND (I.INDEX_ID IN (0,1))
AND DDS.DESTINATION_ID = $PARTITION.POSTTRANPARTFUNC('20171108') ; Fig. 1 Output del Listato 3
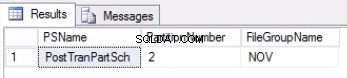
Fig. 2 Output del Listato 4
Il Listato 4 ci mostra che il filegroup associato alla Partizione 2 è NOV . Per cambiare la partizione 2, abbiamo bisogno di una tabella della cronologia che è una replica della tabella live ma si trova sullo stesso filegroup della partizione che intendiamo cambiare. Dal momento che abbiamo già questa tabella, tutto ciò di cui abbiamo bisogno viene ricreata sul Filegroup desiderato. È inoltre necessario ricreare l'indice cluster. Tieni presente che questo indice cluster ha la stessa definizione dell'indice cluster sulla tabella post_tran_tab e si trova anche sullo stesso filegroup di post_tran_tab_hist tabella.
-- Listing 5: Re-create the History Table -- Re-create the History Table -- USE [post_office_history] GO SET ANSI_NULLS ON GO SET QUOTED_IDENTIFIER ON GO SET ANSI_PADDING ON GO DROP TABLE [dbo].[post_tran_tab_hist] GO CREATE TABLE [dbo].[post_tran_tab_hist]( [tran_nr] [bigint] NOT NULL, [tran_type] [char](2) NULL, [tran_reversed] [char](2) NULL, [batch_nr] [int] NULL, [message_type] [char](4) NULL, [source_node_name] [varchar](12) NULL, [system_trace_audit_nr] [char](6) NULL, [settle_currency_code] [char](3) NULL, [sink_node_name] [varchar](30) NULL, [sink_node_currency_code] [char](3) NULL, [to_account_id] [varchar](30) NULL, [pan] [varchar](19) NOT NULL, [pan_encrypted] [char](18) NULL, [pan_reference] [char](70) NULL, [datetime_tran_local] [datetime] NOT NULL, [tran_amount_req] [float] NOT NULL, [tran_amount_rsp] [float] NOT NULL, [tran_cash_req] [float] NOT NULL, [tran_cash_rsp] [float] NOT NULL, [datetime_tran_gmt] [char](10) NULL, [merchant_type] [char](4) NULL, [pos_entry_mode] [char](3) NULL, [pos_condition_code] [char](2) NULL, [acquiring_inst_id_code] [varchar](11) NULL, [retrieval_reference_nr] [char](12) NULL, [auth_id_rsp] [char](6) NULL, [rsp_code_rsp] [char](2) NULL, [service_restriction_code] [char](3) NULL, [terminal_id] [char](8) NULL, [terminal_owner] [varchar](25) NULL, [card_acceptor_id_code] [char](15) NULL, [card_acceptor_name_loc] [char](40) NULL, [from_account_id] [varchar](28) NULL, [auth_reason] [char](1) NULL, [auth_type] [char](1) NULL, [message_reason_code] [char](4) NULL, [datetime_req] [datetime] NULL, [datetime_rsp] [datetime] NULL, [from_account_type] [char](2) NULL, [to_account_type] [char](2) NULL, [insert_date] [datetime] NOT NULL, [tran_postilion_originated] [int] NOT NULL, [card_product] [varchar](20) NULL, [card_seq_nr] [char](3) NULL, [expiry_date] [char](4) NULL, [srcnode_cash_approved] [float] NOT NULL, [tran_completed] [char](2) NULL ) ON [NOV] GO SET ANSI_PADDING OFF GO -- Re-create the Clustered Index -- USE [post_office_history] GO CREATE CLUSTERED INDEX [IX_Datetime_Local] ON [dbo].[post_tran_tab_hist] ( [datetime_tran_local] ASC, [tran_nr] ASC ) WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [NOV] GO
La sostituzione dell'ultima partizione è ora un comando a una riga. Il conteggio di entrambe le tabelle prima e dopo l'esecuzione di questo comando su una riga garantirà di avere tutti i dati desiderati.
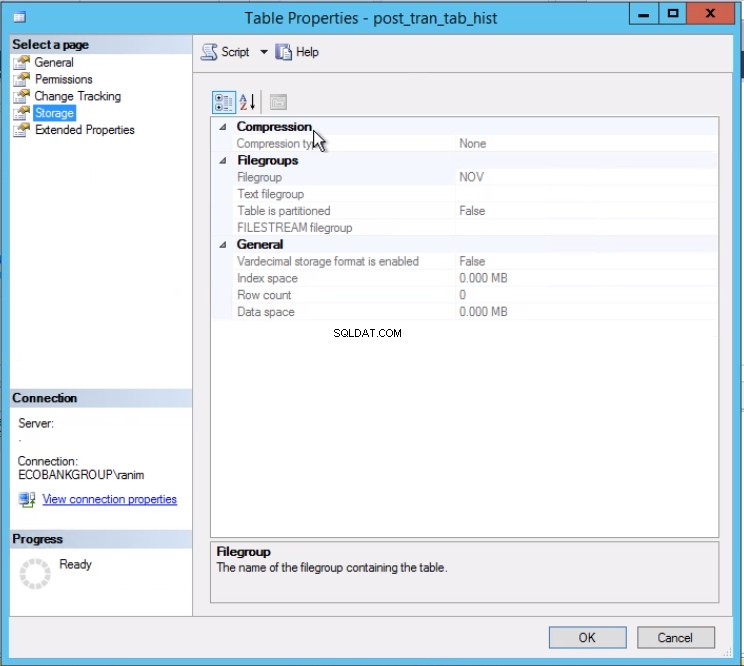
Fig. 3 La tabella post_tran_tab_hist si trova nel filegroup NOV
-- Listing 6: Switching Out the Last Partition SELECT COUNT(*) FROM 'POST_TRAN_TAB'; SELECT COUNT(*) FROM 'POST_TRAN_TAB_HIST'; USE [POST_OFFICE_HISTORY] GO ALTER TABLE POST_TRAN_TAB SWITCH PARTITION 2 TO POST_TRAN_TAB_HIST GO SELECT COUNT(*) FROM 'POST_TRAN_TAB'; SELECT COUNT(*) FROM 'POST_TRAN_TAB_HIST';
Dal momento che abbiamo cambiato l'ultima partizione, non abbiamo più bisogno del confine. Uniamo i due intervalli precedentemente divisi da quel limite usando il comando nel Listato 7. Tronchiamo ulteriormente la tabella della cronologia come mostrato nel Listato 8. Lo stiamo facendo perché questo è il punto centrale:rimuovere i vecchi dati di cui non abbiamo più bisogno.
-- Listing 7: Merging Partition Ranges
-- Merge Range
USE [POST_OFFICE_HISTORY]
GO
ALTER PARTITION FUNCTION POSTTRANPARTFUNC() MERGE RANGE ('20171101');
-- Confirm Range Is Merged
USE [POST_OFFICE_HISTORY]
GO
SELECT * FROM SYS.PARTITION_RANGE_VALUES
GO
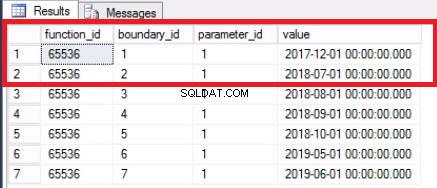
Fig. 4 Confine unito
-- Listing 8: Truncate the History Table USE [post_office_history] GO TRUNCATE TABLE post_tran_tab_hist; GO
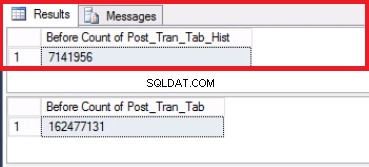
Fig. 5 Conteggio righe per entrambe le tabelle prima del troncamento
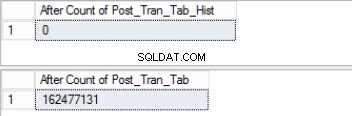
Si noti che il numero di righe nella tabella della cronologia è esattamente lo stesso del numero di righe precedentemente nella partizione 2 come mostrato in Fig. 1. Puoi anche fare uno sforzo in più recuperando lo spazio vuoto nel filegroup appartenente all'ultimo partizione. Questo sarà utile se poiché hai bisogno di questo spazio per i nuovi dati che rimarranno sulla partizione precedente. Questo passaggio potrebbe non essere necessario se ritieni di avere ampio spazio nel tuo ambiente.
-- Listing 9: Recover Space on Operating System -- Determine that File has been emptied USE [post_office_history] GO SELECT DF.FILE_ID, DF.NAME, DF.PHYSICAL_NAME, DS.NAME, DS.TYPE, DF.STATE_DESC FROM SYS.DATABASE_FILES DF JOIN SYS.DATA_SPACES DS ON DF.DATA_SPACE_ID = DS.DATA_SPACE_ID;
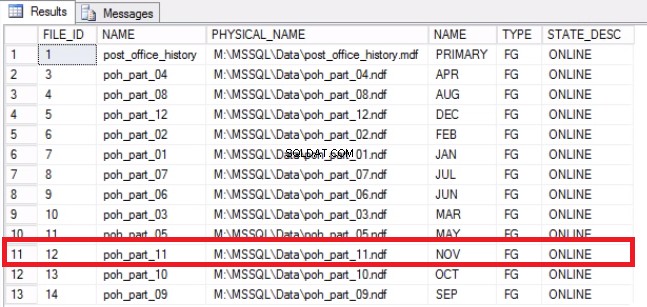
Fig. 7 Mapping da file a filegroup
-- Shrink the file to 2GB USE [post_office_history] GO DBCC SHRINKFILE (N'post_office_history_part_11’, 2048) GO -- From the OS confirm free space on disks SELECT DISTINCT DB_NAME (S.DATABASE_ID) AS DATABASE_NAME, S.DATABASE_ID, S.VOLUME_MOUNT_POINT --, S.VOLUME_ID , S.LOGICAL_VOLUME_NAME , S.FILE_SYSTEM_TYPE , S.TOTAL_BYTES/1024/1024/1024 AS [TOTAL_SIZE (GB)] , S.AVAILABLE_BYTES/1024/1024/1024 AS [FREE_SPACE (GB)] , LEFT ((ROUND (((S.AVAILABLE_BYTES*1.0)/S.TOTAL_BYTES), 4)*100),4) AS PERCENT_FREE FROM SYS.MASTER_FILES AS F CROSS APPLY SYS.DM_OS_VOLUME_STATS (F.DATABASE_ID, F.FILE_ID) AS S WHERE DB_NAME (S.DATABASE_ID) = 'POST_OFFICE_HISTORY';

Fig. 8 Spazio libero sul sistema operativo
Conclusione
In questo articolo, abbiamo eseguito una procedura dettagliata del processo per cambiare le partizioni da una tabella partizionata. Questo è un modo molto efficiente per gestire la crescita dei dati in modo nativo in SQL Server. Tecnologie più avanzate come Stretch Database sono disponibili nelle versioni correnti di SQL Server.
Riferimenti
Isakov, V. (2018). Rif. esame 70-764 Amministrazione di un'infrastruttura di database SQL. Educazione Pearson
Tabelle e indici partizionati in SQL Server