Non appena inizi a eseguire un server di database e il tuo utilizzo aumenta, sei esposto a molti tipi di problemi tecnici, degrado delle prestazioni e malfunzionamenti del database. Ognuno di questi potrebbe portare a problemi molto più grandi, come guasti catastrofici o perdita di dati. È come una reazione a catena, in cui una cosa può portare a un'altra, causando sempre più problemi. È necessario adottare contromisure proattive per avere un ambiente stabile il più a lungo possibile.
In questo post del blog, esamineremo una serie di fantastiche funzionalità offerte da ClusterControl che possono aiutarci notevolmente a risolvere e risolvere i problemi del nostro database MySQL quando si verificano.
Database Allarmi e Notifiche
Per tutti gli eventi indesiderati, ClusterControl registrerà tutto sotto Allarmi, accessibile dall'Attività (Menu in alto) della pagina ClusterControl. Questo è comunemente il primo passo per iniziare la risoluzione dei problemi quando qualcosa va storto. Da questa pagina, possiamo farci un'idea di cosa sta effettivamente succedendo con il nostro cluster di database:
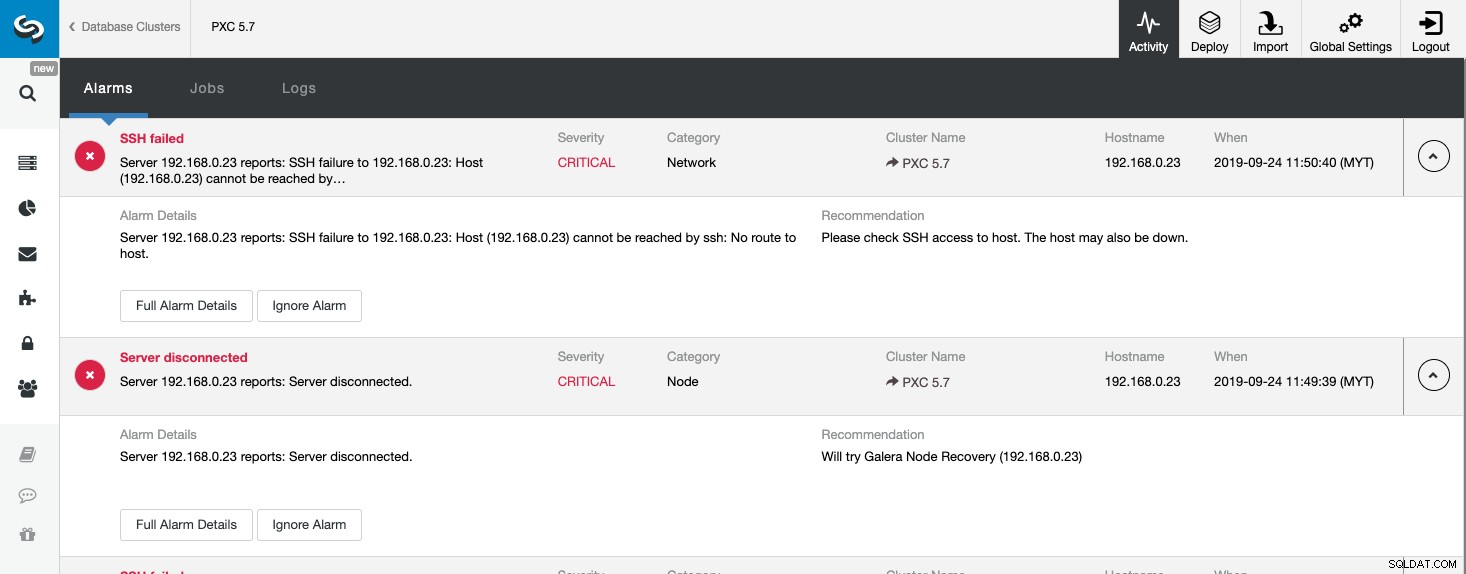
Lo screenshot sopra mostra un esempio di evento irraggiungibile del server, con gravità CRITICA , rilevato da due componenti, Rete e Nodo. Se hai configurato l'impostazione delle notifiche e-mail, dovresti ricevere una copia di questi allarmi nella tua casella di posta.
Quando fai clic su "Dettagli allarme completo", puoi ottenere i dettagli importanti dell'allarme come nome host, timestamp, nome del cluster e così via. Fornisce inoltre il passaggio successivo consigliato da eseguire. Puoi anche inviare questo avviso come e-mail ad altri destinatari configurati nelle Impostazioni di notifica e-mail.
Puoi anche scegliere di silenziare un allarme facendo clic sul pulsante "Ignora allarme" e non apparirà più nell'elenco. Ignorare un avviso può essere utile se si dispone di un avviso di bassa gravità e si sa come gestirlo o aggirarlo. Ad esempio, se ClusterControl rileva un indice duplicato nel database, dove in alcuni casi sarebbe necessario per le applicazioni legacy.
Guardando questa pagina, possiamo ottenere una comprensione immediata di cosa sta succedendo con il nostro cluster di database e quale sarà il passo successivo per risolvere il problema. Come in questo caso, uno dei nodi del database si è interrotto ed è diventato irraggiungibile tramite SSH dall'host ClusterControl. Anche un SysAdmin principiante ora saprebbe cosa fare dopo se viene visualizzato questo allarme.
File di registro del database centralizzato
Qui è dove possiamo approfondire cosa c'era di sbagliato nel nostro server di database. In ClusterControl -> Registri -> Registri di sistema, è possibile visualizzare tutti i file di registro relativi al cluster di database. Per quanto riguarda il cluster di database basato su MySQL, ClusterControl estrae il log ProxySQL, il log degli errori MySQL e i log di backup:
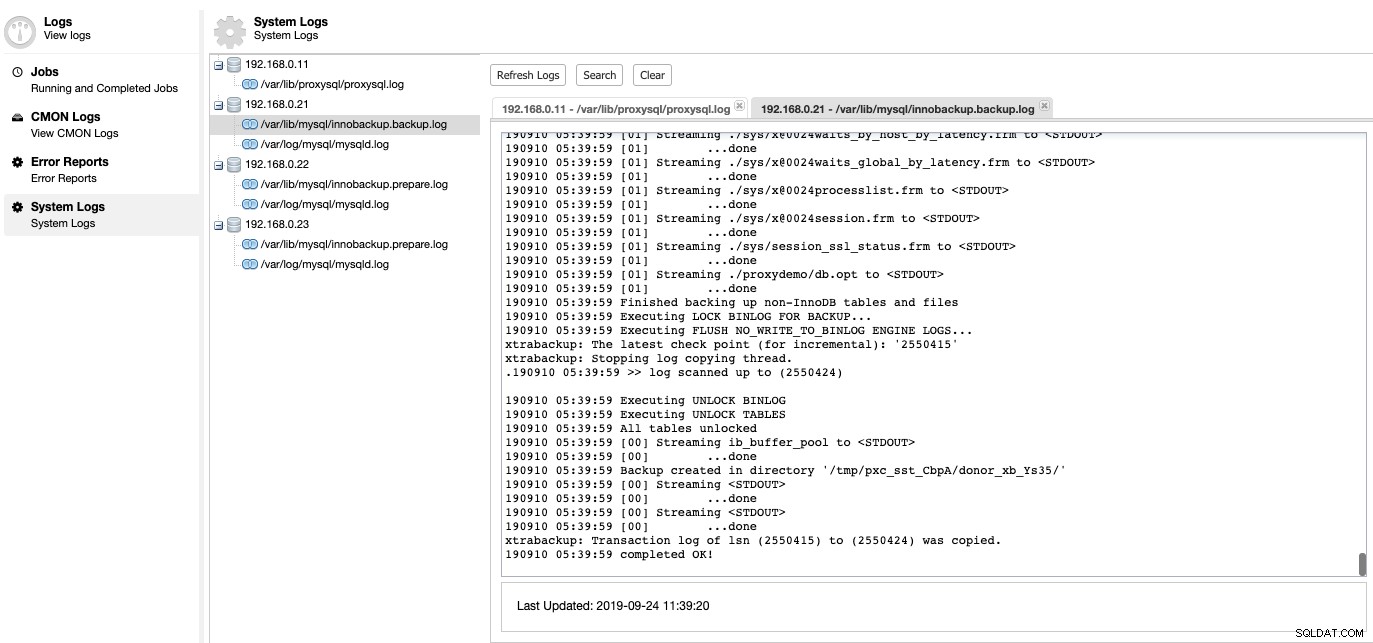
Fare clic su "Aggiorna registro" per recuperare il registro più recente da tutti gli host accessibili in quel particolare momento. Se un nodo è irraggiungibile, ClusterControl visualizzerà comunque il login obsoleto poiché queste informazioni sono archiviate all'interno del database CMON. Per impostazione predefinita ClusterControl continua a recuperare i registri di sistema ogni 10 minuti, configurabili in Impostazioni -> Intervallo registro.
ClusterControl attiverà il lavoro per estrarre il registro più recente da ciascun server, come mostrato nel seguente lavoro "Raccogli registri":
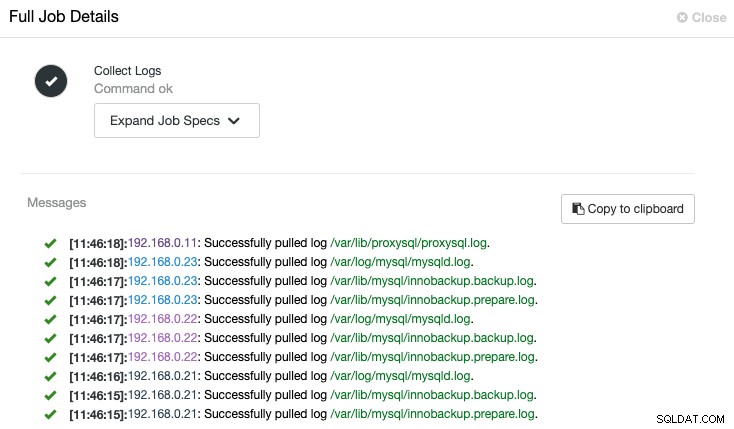
Una visualizzazione centralizzata del file di registro ci consente di comprendere più rapidamente cosa è successo sbagliato. Per un cluster di database che comunemente coinvolge più nodi e livelli, questa funzionalità migliorerà notevolmente la lettura dei registri in cui un amministratore di sistema può confrontare questi registri fianco a fianco e individuare gli eventi critici, riducendo il tempo totale di risoluzione dei problemi.
Console Web SSH
ClusterControl fornisce una console SSH basata sul Web in modo da poter accedere al server DB direttamente tramite l'interfaccia utente di ClusterControl (poiché l'utente SSH è configurato per connettersi agli host del database). Da qui, possiamo raccogliere molte più informazioni che ci consentono di risolvere il problema ancora più velocemente. Tutti sanno quando un problema di database colpisce il sistema di produzione, ogni secondo di inattività conta.
Per accedere alla console SSH via web, seleziona semplicemente i nodi in Nodi -> Azioni nodo -> Console SSH, oppure fai semplicemente clic sull'icona a forma di ingranaggio per una scorciatoia:
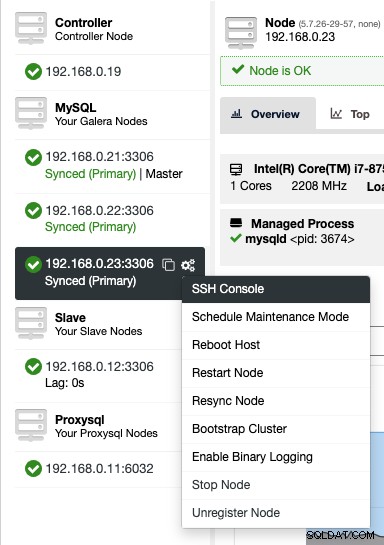
A causa di problemi di sicurezza che potrebbero essere imposti con questa funzione, in particolare per -utente o ambiente multi-tenant, è possibile disabilitarlo andando su /var/www/html/clustercontrol/bootstrap.php sul server ClusterControl e impostando la seguente costante su false:
define('SSH_ENABLED', false);Aggiorna la pagina dell'interfaccia utente di ClusterControl per caricare le nuove modifiche.
Problemi di prestazioni del database
Oltre alle funzioni di monitoraggio e trend, ClusterControl invia in modo proattivo vari allarmi e avvisi relativi alle prestazioni del database, ad esempio:
- Utilizzo eccessivo - Risorsa che supera determinate soglie come CPU, memoria, utilizzo di swap e spazio su disco.
- Degrado del cluster - Cluster e partizionamento della rete.
- Deriva dell'ora del sistema - Differenza di tempo tra tutti i nodi del cluster (incluso il nodo ClusterControl).
- Vari altri advisor relativi a MySQL:
- Replica:ritardo di replica, scadenza binlog, posizione e crescita
- Galera - Metodo SST, scansione del file di registro GRA, controllo dell'indirizzo del cluster
- Controllo schema - Esistenza di tabelle non transazionali su Galera Cluster.
- Connessioni - Rapporto di connessione dei thread
- InnoDB - Rapporto pagine sporche, crescita del file di registro InnoDB
- Query lente:per impostazione predefinita ClusterControl genererà un allarme se rileva una query in esecuzione per più di 30 secondi. Questo è ovviamente configurabile in Impostazioni -> Configurazione runtime -> Query lunga.
- Deadlock:deadlock delle transazioni InnoDB e deadlock di Galera.
- Indici - Chiavi duplicate, tabella senza chiavi primarie.
Consulta la pagina Advisor in Performance -> Advisor per ottenere i dettagli sulle cose che possono essere migliorate come suggerito da ClusterControl. Per ogni advisor, fornisce giustificazioni e consigli come mostrato nell'esempio seguente per l'advisor "Controllo dell'utilizzo dello spazio su disco":
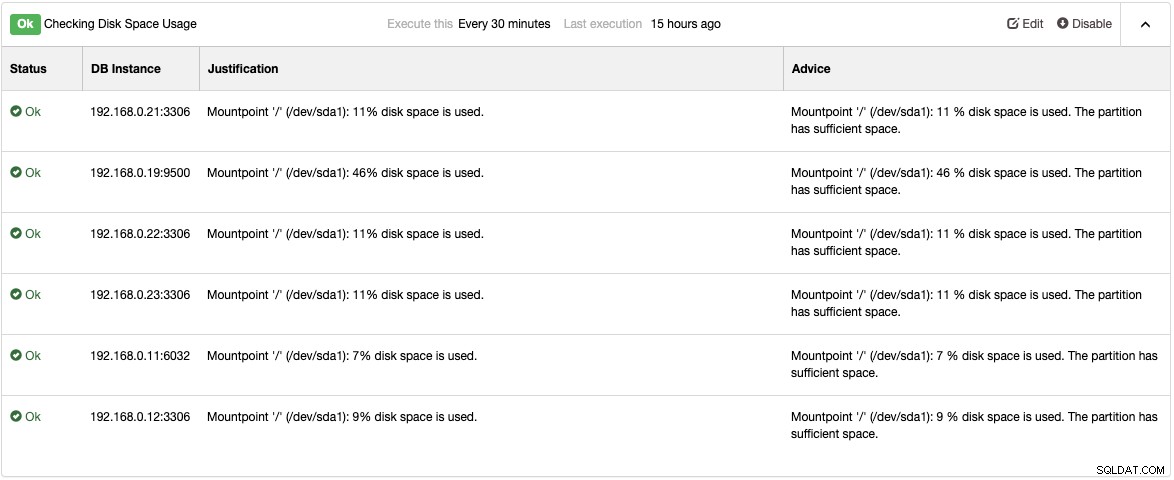
Quando si verifica un problema di prestazioni verrà visualizzato "Avviso" (giallo) o Stato "Critico" (rosso) su questi consulenti. Un'ulteriore messa a punto è comunemente necessaria per superare il problema. Gli advisor generano allarmi, il che significa che gli utenti riceveranno una copia di questi allarmi all'interno della casella di posta se le notifiche e-mail sono configurate di conseguenza. Per ogni allarme lanciato da ClusterControl o dai suoi consulenti, gli utenti riceveranno anche un'e-mail se l'allarme è stato cancellato. Questi sono preconfigurati in ClusterControl e non richiedono alcuna configurazione iniziale. Ulteriori personalizzazioni sono sempre possibili in Gestisci -> Developer Studio. Puoi dare un'occhiata a questo post del blog su come scrivere il tuo consulente.
ClusterControl fornisce anche una pagina dedicata alle prestazioni del database in ClusterControl -> Performance. Fornisce tutti i tipi di informazioni dettagliate sul database seguendo le migliori pratiche come la visualizzazione centralizzata dello stato del database, delle variabili, dello stato di InnoDB, dell'analizzatore di schemi, dei registri delle transazioni. Questi sono abbastanza autoesplicativi e semplici da capire.
Per le prestazioni delle query, è possibile esaminare le query principali e i valori anomali della query, in cui ClusterControl evidenzia le query eseguite significativamente diverse dalla query media. Abbiamo trattato questo argomento in dettaglio in questo post del blog, MySQL Query Performance Tuning.
Rapporti errori database
ClusterControl viene fornito con uno strumento generatore di rapporti sugli errori, per raccogliere informazioni di debug sul cluster di database per aiutare a comprendere la situazione e lo stato attuali. Per generare un rapporto di errore, vai semplicemente su ClusterControl -> Registri -> Rapporti di errore -> Crea rapporto di errore:
Il rapporto di errore generato può essere scaricato da questa pagina una volta pronto. Questo rapporto generato sarà in formato TAR ball (tar.gz) e puoi allegarlo a una richiesta di supporto. Poiché il ticket di supporto ha il limite di 10 MB di dimensione del file, se la dimensione del tarball è maggiore di quella, puoi caricarlo su un'unità cloud e condividere con noi il link per il download solo con l'autorizzazione adeguata. Puoi rimuoverlo in seguito una volta che abbiamo già ottenuto il file. Puoi anche generare il rapporto di errore tramite riga di comando come spiegato nella pagina della documentazione del rapporto di errore.
In caso di interruzione, consigliamo vivamente di generare più rapporti di errore durante e subito dopo l'interruzione. Tali rapporti saranno molto utili per cercare di capire cosa è andato storto, le conseguenze dell'interruzione e per verificare che il cluster sia effettivamente tornato allo stato operativo dopo un evento disastroso.
Conclusione
Il monitoraggio proattivo di ClusterControl, insieme a una serie di funzionalità di risoluzione dei problemi, fornisce agli utenti una piattaforma efficiente per risolvere qualsiasi tipo di problema relativo al database MySQL. È ormai lontano il modo tradizionale di risoluzione dei problemi in cui è necessario aprire più sessioni SSH per accedere a più host ed eseguire più comandi ripetutamente per individuare la causa principale.
Se le funzionalità sopra menzionate non ti aiutano a risolvere il problema o a risolvere il problema del database, contatta sempre il team di supporto di Manynines per eseguire il backup. I nostri esperti tecnici dedicati 24/7/365 sono disponibili per soddisfare la tua richiesta in qualsiasi momento. Il nostro tempo medio per la prima risposta è generalmente inferiore a 30 minuti.