Di recente abbiamo scritto diversi blog che trattano di come diversi provider di servizi cloud gestiscono il failover del database. Abbiamo confrontato le prestazioni di failover in Amazon Aurora, Amazon RDS e ClusterControl, testato il comportamento di failover in Amazon RDS e anche su Google Cloud Platform. Sebbene questi servizi offrano ottime opzioni quando si tratta di failover, potrebbero non essere adatti a tutte le applicazioni.
In questo post del blog dedicheremo un po' di tempo ad analizzare i pro ei contro dell'utilizzo delle soluzioni DBaaS rispetto alla progettazione di un ambiente manualmente o utilizzando una piattaforma di gestione di database, come ClusterControl.
Implementazione di database ad alta disponibilità con soluzioni gestite
Il motivo principale per utilizzare le soluzioni esistenti è la facilità d'uso. Puoi distribuire una soluzione ad alta disponibilità con failover automatico in un paio di clic. Non è necessario combinare diversi strumenti insieme, gestire manualmente i database, distribuire strumenti, scrivere script, progettare il monitoraggio o qualsiasi altra operazione di gestione del database. Tutto è già a posto. Ciò può ridurre seriamente la curva di apprendimento e richiede meno esperienza per creare un ambiente altamente disponibile per i database; consentendo praticamente a tutti di distribuire tali configurazioni.
Nella maggior parte dei casi con queste soluzioni, il processo di failover viene eseguito entro un tempo ragionevole. Potrebbe essere velocissimo come con Amazon Aurora o un po' più lento come con i nodi SQL di Google Cloud Platform. Per la maggior parte dei casi, questi tipi di risultati sono accettabili.
La linea di fondo. Se puoi accettare 30 - 60 secondi di inattività, dovresti essere a posto usando una qualsiasi delle piattaforme DBaaS.
Lo svantaggio dell'utilizzo di una soluzione gestita per HA
Sebbene le soluzioni DBaaS siano semplici da usare, presentano anche alcuni seri inconvenienti. Per cominciare, c'è sempre un componente di blocco del fornitore da considerare. Dopo aver distribuito un cluster in Amazon Web Services, è piuttosto complicato migrare da quel provider. Non esistono metodi semplici per scaricare l'intero set di dati tramite un backup fisico. Con la maggior parte dei provider, sono disponibili solo backup logici eseguiti manualmente. Certo, ci sono sempre opzioni per raggiungere questo obiettivo, ma in genere si tratta di un processo complesso e che richiede tempo, che dopotutto potrebbe richiedere comunque dei tempi di inattività.
Anche l'utilizzo di un provider come Amazon RDS comporta delle limitazioni. Non è possibile eseguire facilmente alcune operazioni che sarebbero molto semplici da eseguire su ambienti distribuiti in modo completamente controllato dall'utente (ad es. AWS EC2). Alcune di queste limitazioni sono già state trattate in altri blog, ma per riassumere è che nessun servizio DBaaS offre lo stesso livello di flessibilità della normale replica basata su MySQL GTID. Puoi promuovere qualsiasi slave, puoi riattivare ogni nodo da qualsiasi altro... praticamente ogni azione è possibile. Con strumenti come RDS devi affrontare limitazioni indotte dal design che non puoi aggirare.
Il problema riguarda anche la capacità di comprendere i dettagli delle prestazioni. Quando si progetta la propria configurazione ad alta disponibilità, si diventa consapevoli dei potenziali problemi di prestazioni che potrebbero presentarsi. D'altra parte, RDS e ambienti simili sono praticamente "scatole nere". Sì, abbiamo appreso che Amazon RDS utilizza DRBD per creare una copia shadow del master, sappiamo che Aurora utilizza lo storage condiviso e replicato per implementare failover molto veloci. Questa è solo una conoscenza generale. Non possiamo dire quali siano le implicazioni sulle prestazioni di tali soluzioni oltre a ciò che potremmo notare casualmente. Quali sono i problemi comuni ad essi associati? Quanto sono stabili queste soluzioni? Solo gli sviluppatori dietro la soluzione lo sanno per certo.
Qual è l'alternativa alle soluzioni DBaaS?
Ci si potrebbe chiedere, esiste un'alternativa a DBaaS? Dopotutto, è così conveniente eseguire il servizio gestito in cui è possibile accedere alla maggior parte delle azioni tipiche tramite l'interfaccia utente. Puoi creare e ripristinare backup, il failover viene gestito automaticamente per te. L'ambiente è facile da usare e può essere interessante per le aziende che non dispongono di personale dedicato ed esperto per gestire i database.
ClusterControl offre un'ottima alternativa ai servizi DBaaS basati su cloud. Fornisce un'interfaccia utente grafica, che può essere utilizzata per distribuire, gestire e monitorare database open source.
In un paio di clic puoi distribuire facilmente un cluster di database ad alta disponibilità, con failover automatizzato (più veloce della maggior parte delle offerte DBaaS), gestione del backup, monitoraggio avanzato e altre funzionalità come l'integrazione con strumenti esterni (es. Slack o PagerDuty) o gestione degli aggiornamenti. Tutto questo evitando completamente il blocco del fornitore.
ClusterControl non si preoccupa di dove si trovano i tuoi database fintanto che può connettersi ad essi tramite SSH. Puoi avere configurazioni nel cloud, in locale o in un ambiente misto di più fornitori di servizi cloud. Finché la connettività è presente, ClusterControl sarà in grado di gestire l'ambiente. L'utilizzo delle soluzioni che desideri (e non quelle che non conosci né di cui non sei a conoscenza) ti consente di assumere il pieno controllo dell'ambiente in qualsiasi momento.
Qualunque configurazione sia stata implementata con ClusterControl, puoi gestirla facilmente in un modo più tradizionale, manuale o tramite script. ClusterControl fornisce anche un'interfaccia a riga di comando, che consente di incorporare le attività eseguite da ClusterControl negli script della shell. Hai tutto il controllo che desideri:niente è una scatola nera, ogni pezzo dell'ambiente verrebbe costruito utilizzando soluzioni open source combinate insieme e distribuite da ClusterControl.
Diamo un'occhiata alla facilità con cui è possibile distribuire un cluster di replica MySQL utilizzando ClusterControl. Supponiamo che tu abbia l'ambiente preparato con ClusterControl installato su un'istanza e tutti gli altri nodi accessibili tramite SSH dall'host ClusterControl.
Inizieremo selezionando la procedura guidata "Distribuisci".
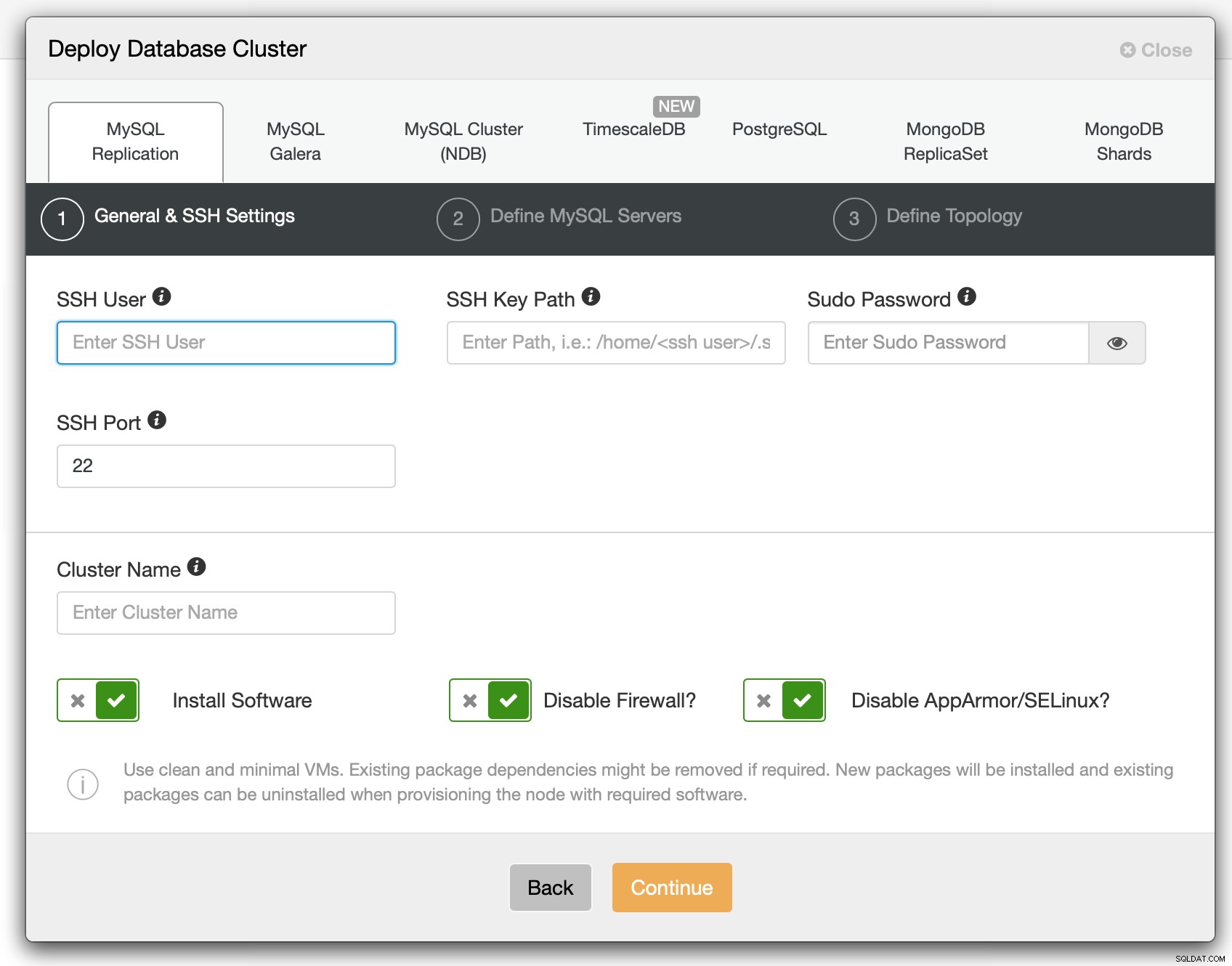
Nel primo passaggio dobbiamo definire come ClusterControl deve connettersi ai nodi su quali database devono essere distribuiti. Sono supportati sia l'accesso root che sudo (con o senza password).
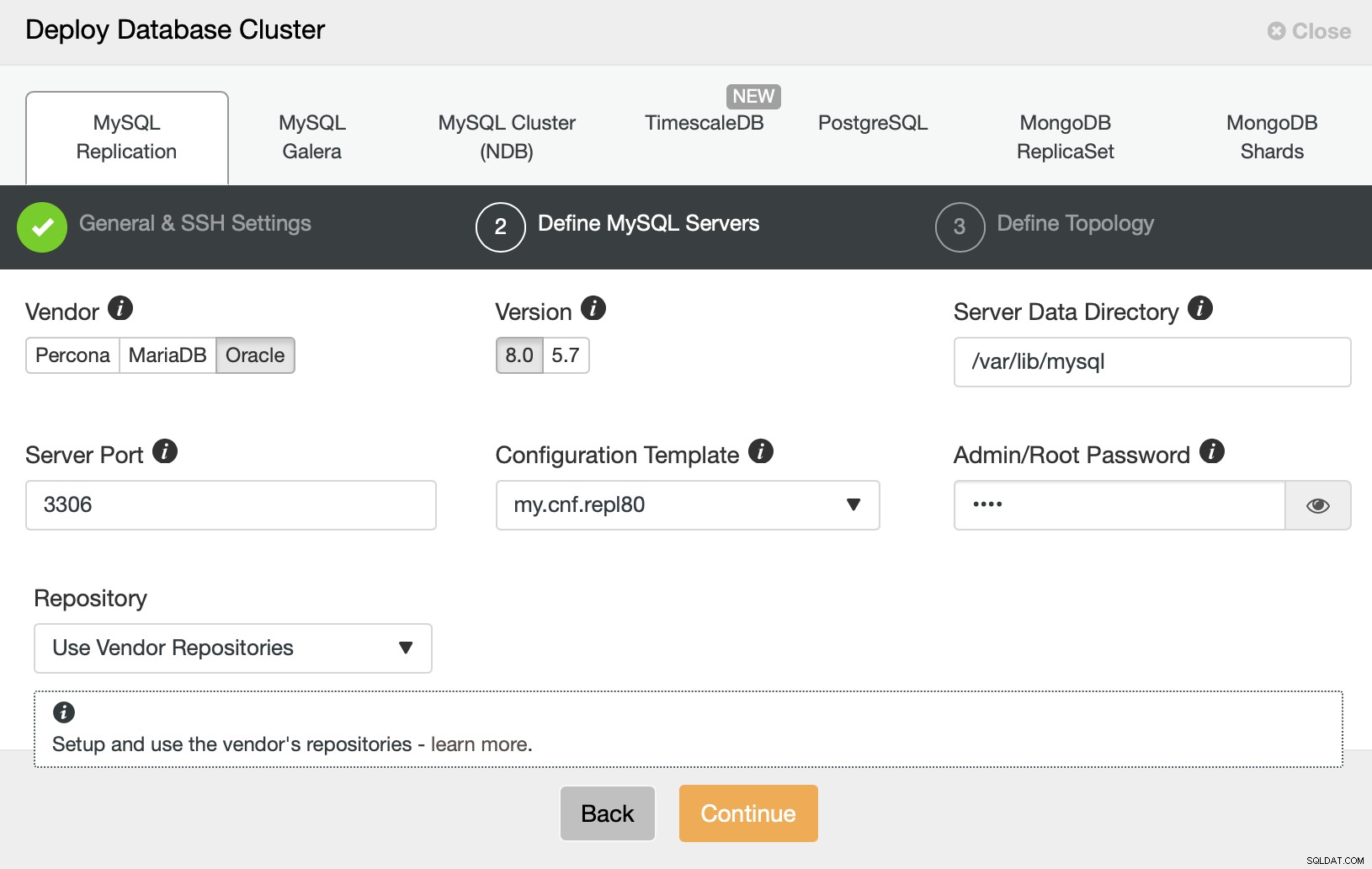
Quindi, vogliamo scegliere un fornitore, una versione e passare la password per l'utente amministrativo nel nostro database MySQL.
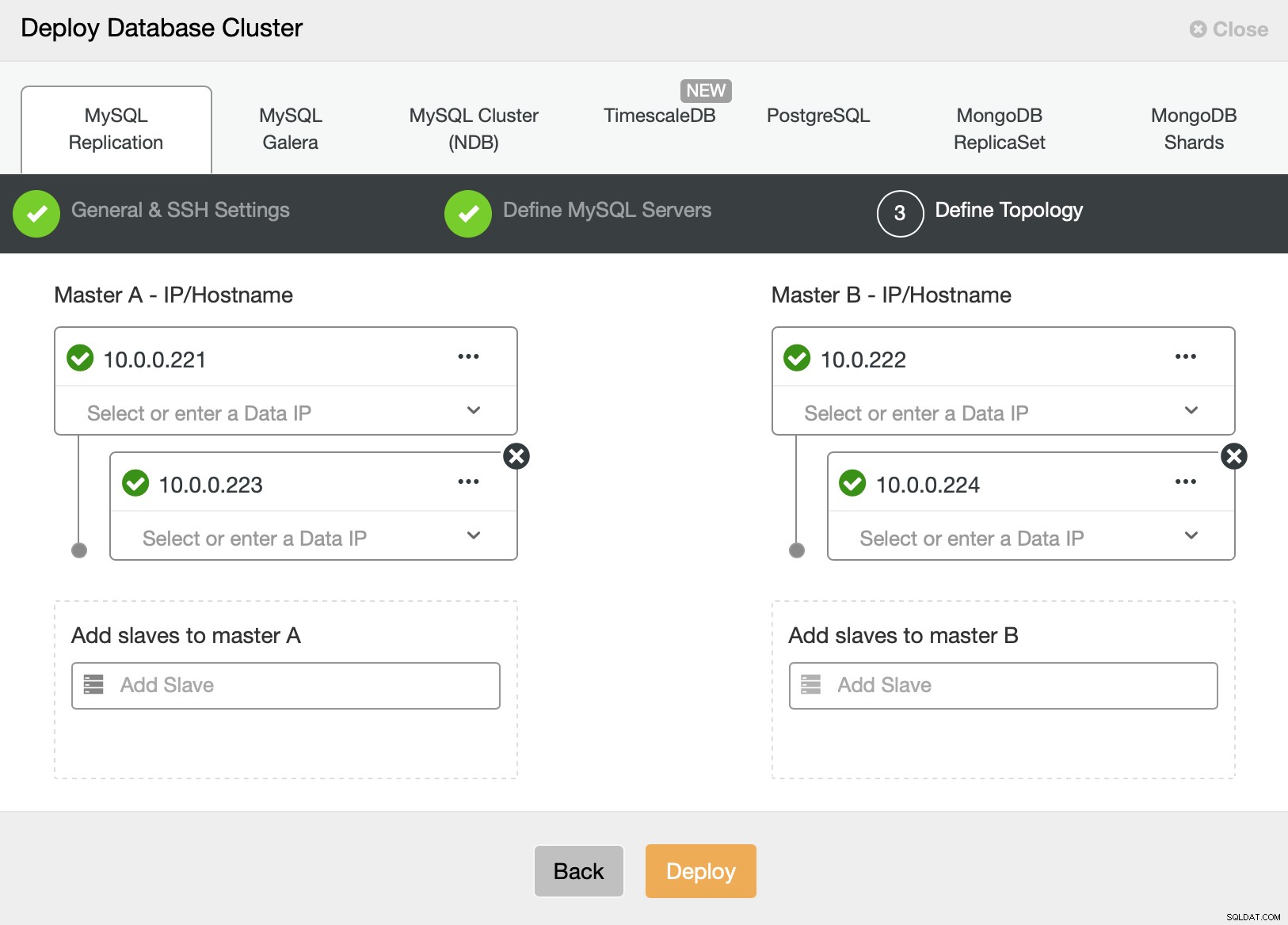
Infine, vogliamo definire la topologia per il nostro nuovo cluster. Come puoi vedere, questa è già una configurazione piuttosto complessa, a differenza di qualcosa che puoi distribuire utilizzando AWS RDS o il nodo SQL GCP.
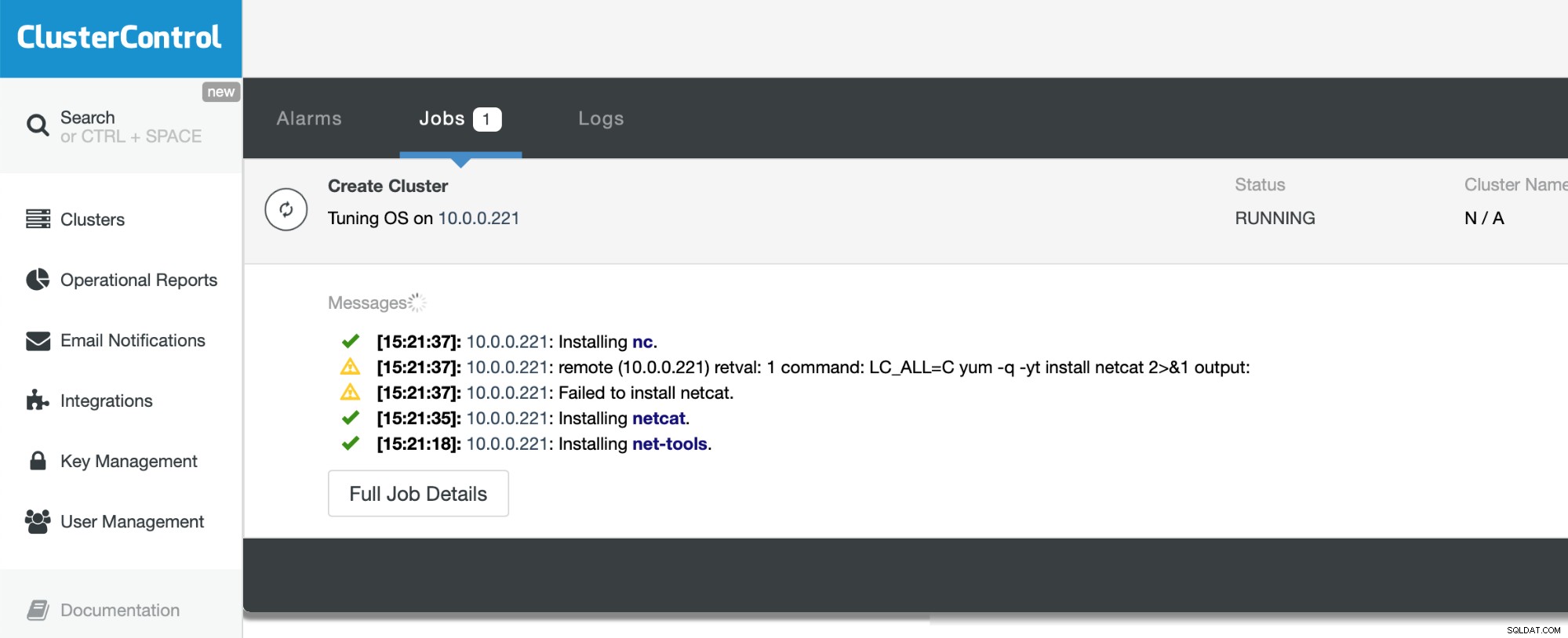
Tutto ciò che dobbiamo fare ora è attendere il completamento del processo. ClusterControl farà del suo meglio per comprendere l'ambiente in cui viene distribuito e installare il set di pacchetti richiesto, incluso il database stesso.

Una volta che il cluster è attivo e funzionante, puoi procedere con la distribuzione il livello proxy (che fornirà alla tua applicazione un unico punto di ingresso nel livello del database). Questo è più o meno ciò che accade dietro le quinte con DBaaS, dove hai anche endpoint per la connessione al cluster di database. È abbastanza comune utilizzare un singolo endpoint per le scritture e più endpoint per raggiungere repliche particolari.
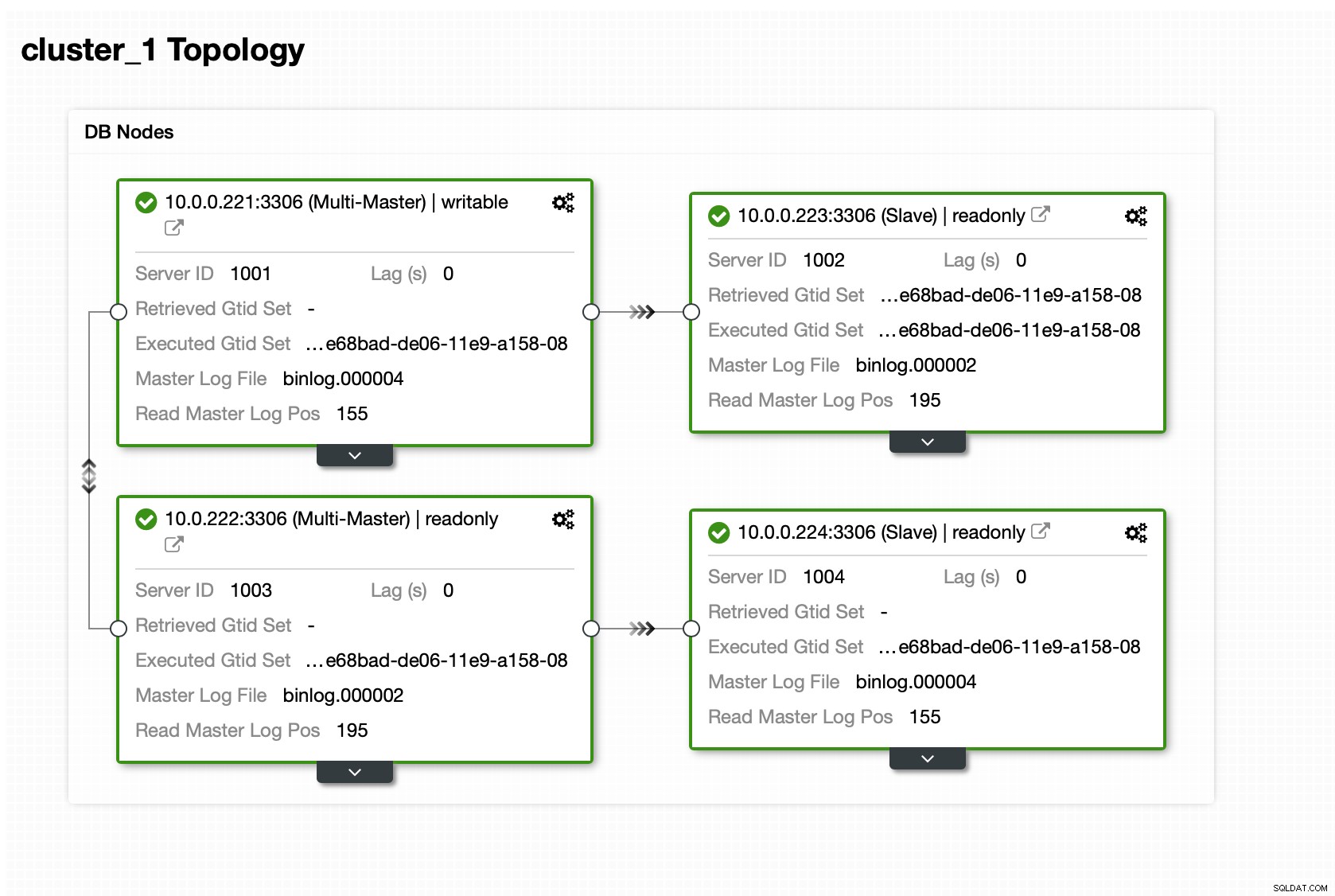
Qui useremo ProxySQL, che farà il lavoro sporco per noi - comprenderà la topologia, invia le scritture solo al master e bilancia il carico delle query di sola lettura su tutte le repliche di cui disponiamo.
Per distribuire ProxySQL andremo su Gestisci -> Bilanciatori di carico.
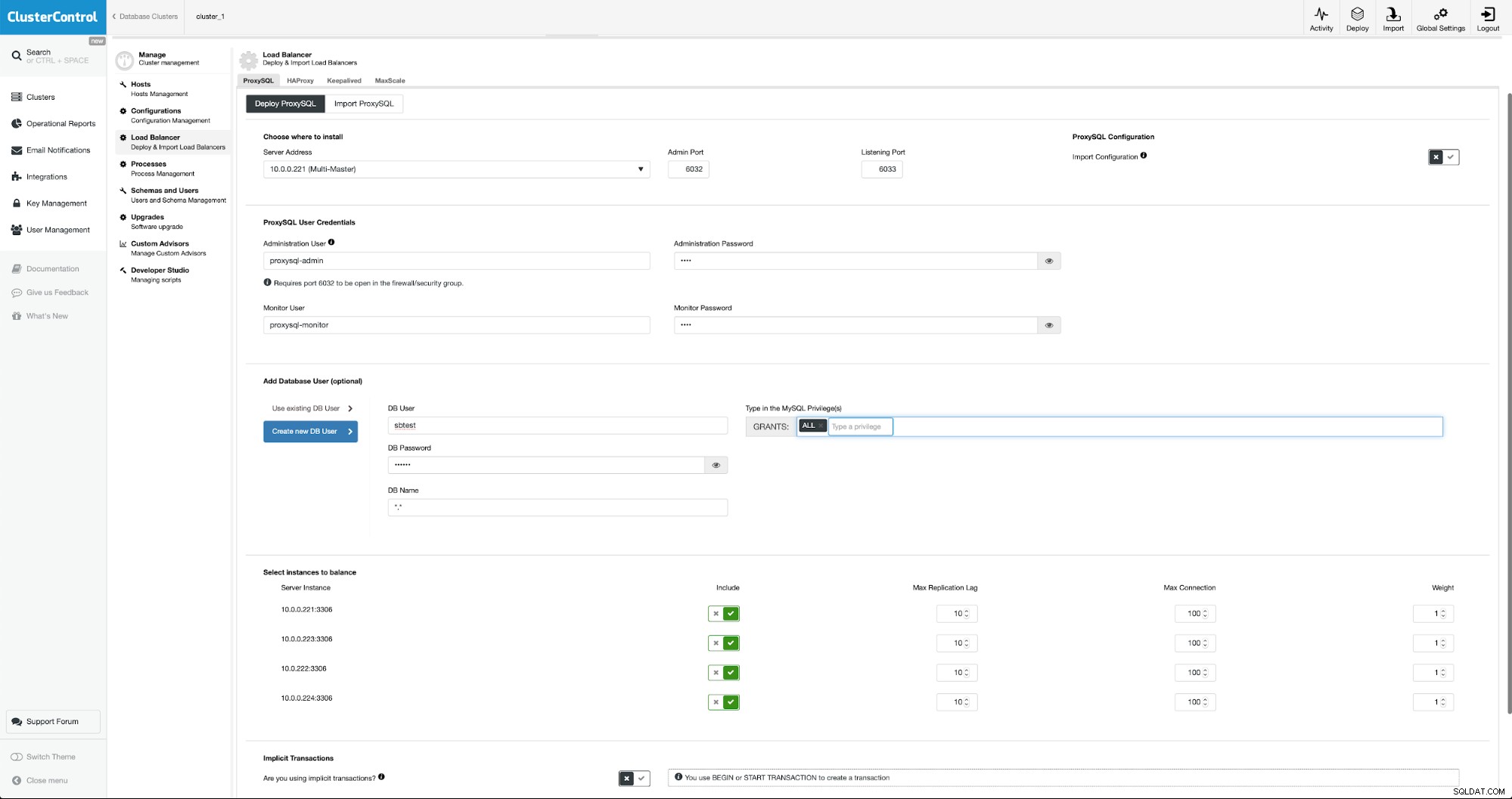
Dobbiamo compilare tutti i campi obbligatori:host su cui eseguire il deployment, credenziali per l'utente amministrativo e di monitoraggio, possiamo importare l'utente esistente da MySQL in ProxySQL o crearne uno nuovo. Tutti i dettagli su ProxySQL possono essere facilmente trovati in più blog nella nostra sezione blog.
Vogliamo distribuire almeno due nodi ProxySQL per garantire un'elevata disponibilità. Quindi, una volta distribuiti, distribuiremo Keepalived su ProxySQL. Ciò garantirà che l'IP virtuale venga configurato e che punti a una delle istanze ProxySQL, purché sia presente almeno un nodo integro.
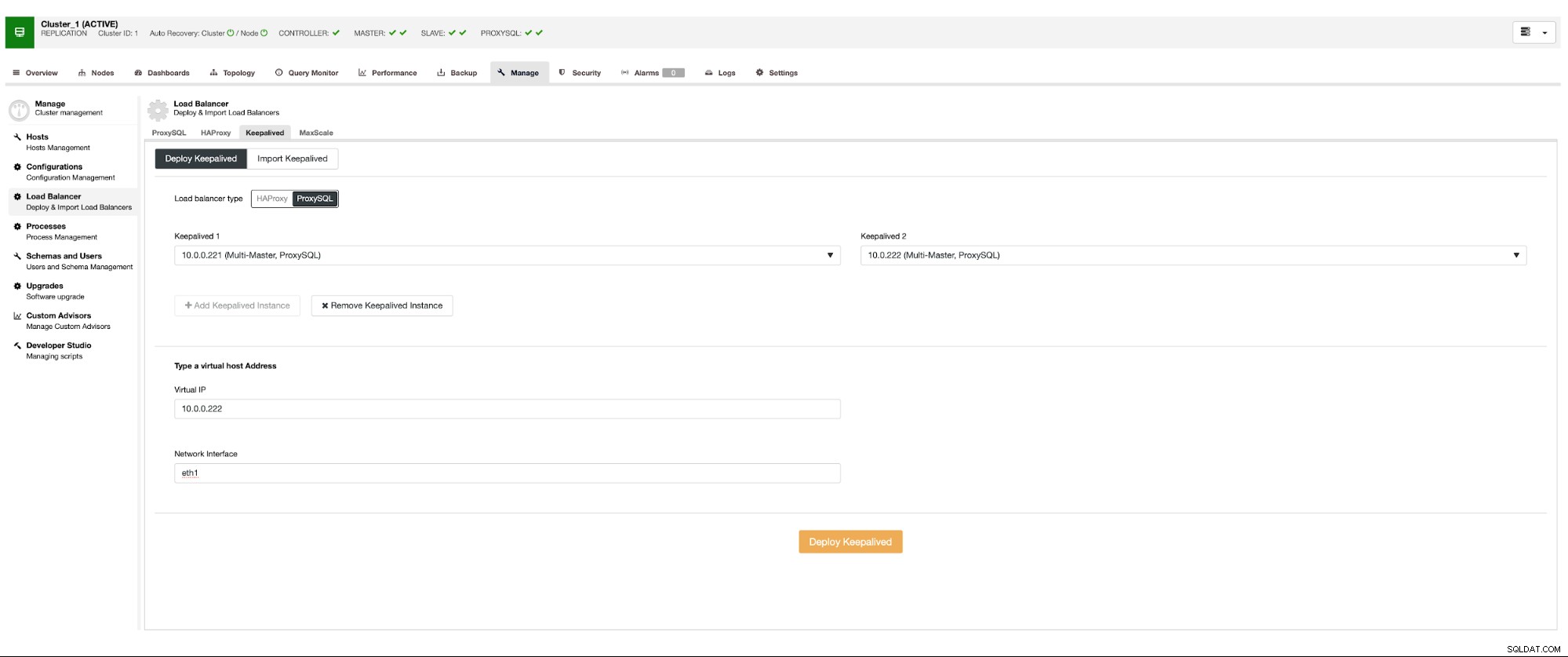
Ecco l'unico problema potenziale se utilizzi ambienti cloud in cui funziona il routing in un modo che non è possibile visualizzare facilmente un'interfaccia di rete. In tal caso dovrai modificare la configurazione di Keepalived, introdurre lo script 'notify_master' e utilizzare uno script, che apporterà le modifiche IP necessarie - nel caso di EC2 dovrebbe staccare l'IP elastico da un host e allegarlo al altro ospite.
Ci sono molte istruzioni su come farlo utilizzando il software open source ampiamente testato nelle configurazioni distribuite da ClusterControl. Puoi trovare facilmente ulteriori informazioni, suggerimenti e procedure rilevanti per il tuo particolare ambiente.
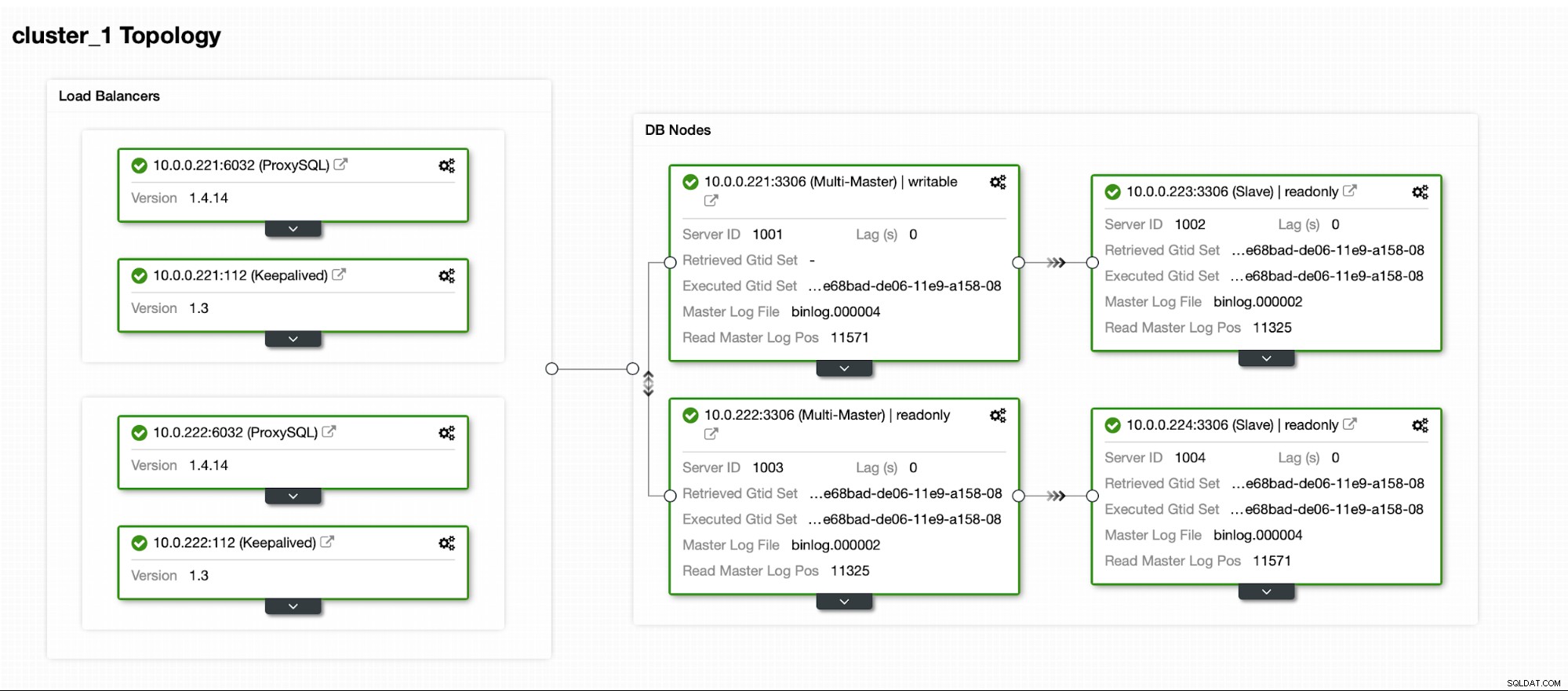
Conclusione
Ci auguriamo che tu abbia trovato questo post del blog perspicace. Se desideri testare ClusterControl, viene fornito con una versione di prova aziendale di 30 giorni in cui hai a disposizione tutte le funzionalità. Puoi scaricarlo gratuitamente e testare se si adatta al tuo ambiente.



