Ciao,
L'utilizzo di Index nel database di SQL Server si verifica in ambienti che richiedono il massimo risparmio di prestazioni, velocità e memoria.
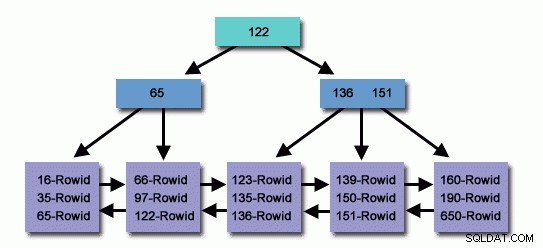
In una tabella con milioni o miliardi di record, possiamo utilizzare un indice per leggere meno record e cercare di meno per trovare record correlati.
Indice creato accuratamente, milioni di record all'interno del database che abbiamo cercato in brevissimo tempo per portare il record di convenienza del chiamante, mentre allo stesso tempo leggiamo meno il record raggiungendo il record di destinazione, utilizziamo le risorse del sistema operativo in modo efficace.
Dovresti creare un indice per la maggior parte delle query di sola lettura su una tabella. Se le operazioni di eliminazione e aggiornamento sono più che query di sola lettura, non dovresti creare l'indice di quella tabella.
È possibile esaminare la raccomandazione sull'indice mancante di SQL Server con lo script seguente. Puoi creare un indice mancante ma dovresti monitorare questi indici, se non sono utili, dovresti eliminarli.
SELECT MID.[statement] AS ObjectName
,MID.equality_columns AS EqualityColumns
,MID.inequality_columns AS InequalityColms
,MID.included_columns AS IncludedColumns
,MIGS.last_user_seek AS LastUserSeek
,MIGS.avg_total_user_cost
* MIGS.avg_user_impact
* (MIGS.user_seeks + MIGS.user_scans) AS Impact
,N'CREATE NONCLUSTERED INDEX <TYPE_Index_Name> ' +
N'ON ' + MID.[statement] +
N' (' + MID.equality_columns
+ ISNULL(', ' + MID.inequality_columns, N'') +
N') ' + ISNULL(N'INCLUDE (' + MID.included_columns + N');', ';')
AS CreateStatement
FROM sys.dm_db_missing_index_group_stats AS MIGS
INNER JOIN sys.dm_db_missing_index_groups AS MIG
ON MIGS.group_handle = MIG.index_group_handle
INNER JOIN sys.dm_db_missing_index_details AS MID
ON MIG.index_handle = MID.index_handle
WHERE database_id = DB_ID()
AND MIGS.last_user_seek >= DATEDIFF(month, GetDate(), -1)
ORDER BY Impact DESC;



