Nel mio precedente articolo sui database di sistema di SQL Server, abbiamo appreso di ogni database di sistema che fa parte dell'installazione di SQL Server. L'articolo corrente si concentrerà sui problemi frequenti relativi al database tempdb e su come risolverli correttamente.
TempDB di SQL Server
Come indica il nome di questo database di sistema, tempdb contiene oggetti temporanei creato da SQL Server. Si riferiscono a diverse operazioni e fungono da area di lavoro globale per tutti gli utenti che si connettono alle istanze di SQL Server.
Il database Tempdb conterrà i tipi di oggetto seguenti mentre gli utenti eseguono le loro operazioni:
- Gli oggetti temporanei vengono creati esplicitamente dagli utenti. Possono essere tabelle e indici temporanei locali o globali, variabili di tabella, tabelle utilizzate nelle funzioni con valori di tabella e cursori.
- Oggetti interni creati dal Motore di database come
- Tabelle di lavoro che memorizzano risultati intermedi per spool, cursori, ordinamenti e oggetti temporanei di grandi dimensioni (LOB).
- File di lavoro durante l'esecuzione di operazioni di aggregazione hash o hash.
- Risultati di ordinamento intermedio durante la creazione o la ricostruzione di indici se SORT_IN_TEMPDB è impostato su ON e altre operazioni come query GROUP BY, ORDER BY o SQL UNION.
- Gli archivi versioni che supportano la funzione di controllo delle versioni delle righe, sia l'archivio versioni comuni che l'archivio versioni build dell'indice in linea utilizzano i file di database tempdb.
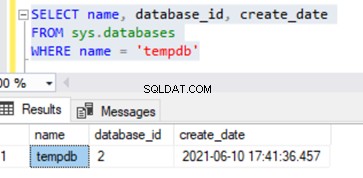
Il database Tempdb viene creato ogni volta che viene avviato il servizio SQL Server. Pertanto, l'ora della creazione del database tempdb può essere considerata come un'ora approssimativa di avvio del servizio SQL Server. Possiamo identificarlo da sys.databases DMV utilizzando la query mostrata di seguito:
SELECT name, database_id, create_date
FROM sys.databases
WHERE name = 'tempdb'
Tuttavia, l'avvio effettivo del servizio SQL Server implica l'avvio di tutti i database di sistema in una sequenza specifica. Potrebbe verificarsi un po' prima dell'ora di creazione di tempdb. Possiamo ottenere il valore utilizzando sys.databases DMV eseguendo la query seguente su sys.dm_os_sys_info DMV .
SELECT ms_ticks, sqlserver_start_time_ms_ticks, sqlserver_start_time
FROM sys.dm_os_sys_info
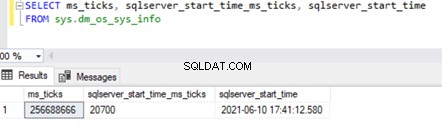
I ms_tick colonna specifica il numero di millisecondi dall'avvio del computer o del server. Gli sqlserver_start_time_ms_ticks colonna specifica il numero di millisecondi trascorsi da ms_ticks numero all'avvio del servizio SQL Server.
È possibile trovare ulteriori informazioni sull'ordine dei database avviati durante l'avvio dei servizi di SQL Server nel registro degli errori di SQL Server.
In SSMS, espandi Gestione > Registri degli errori di SQL Server > apri la corrente registro degli errori. Applica l'Inizio su database filtrare e fare clic su Data per ordinarlo in ordine crescente:
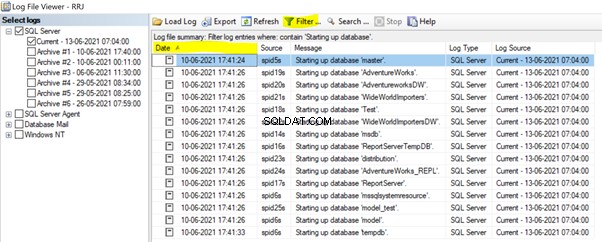
Possiamo vedere che il database master è stato avviato per primo durante l'avvio del servizio SQL Server. Quindi sono seguiti tutti i database utente e tutti gli altri database di sistema. Alla fine, il tempdb è iniziato. Puoi anche recuperare queste informazioni a livello di codice eseguendo il xp_readerrorlog procedura di sistema:
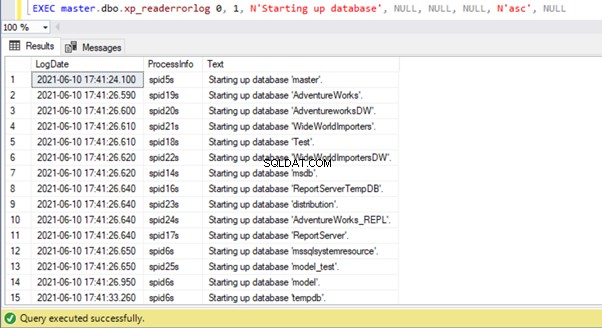
Nota :entrambi gli approcci precedenti potrebbero non mostrare le informazioni necessarie se il servizio SQL Server non è stato riavviato di recente e il registro degli errori di SQL Server è stato riciclato, il che potrebbe aver eseguito il push dei registri degli errori più vecchi in file meno recenti. In tal caso, potrebbe essere necessario eseguire la scansione dei dati nei file di registro degli errori di SQL Server archiviati.
Problemi frequenti nel database SQL TempDB
Poiché tempdb fornisce un'area di lavoro globale per tutte le sessioni o attività utente, può diventare un collo di bottiglia delle prestazioni per le operazioni dell'utente se non configurato con attenzione. Nel mio articolo precedente, abbiamo discusso le procedure consigliate da implementare nel database tempdb. Tuttavia, anche dopo averli implementati, potremmo riscontrare problemi frequentemente:
- Crescita irregolare dei file tra i file di dati tempdb.
- I file di dati Tempdb stanno raggiungendo un valore enorme e devono ridurre Tempdb.
Crescita di file non uniforme nei file di dati TempDB
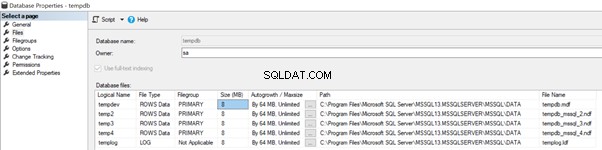
A partire da SQL Server 2000, l'impostazione predefinita prevede più file di dati in base al conteggio dei core logici disponibili nel server.
Quando abbiamo più file di dati, ad esempio, 4 file di dati tempdb come nell'immagine seguente, la crescita automatica dei file di dati tempdb avverrà di 64 MB in modo round-robin a partire da tempdev> temp2> temp3> temp4> tempdev> e così via.
Se una delle dimensioni del file non può crescere automaticamente per qualche motivo, si tradurrà in dimensioni enormi di alcuni file rispetto ad altri file. Porta a un sovraccarico aggiuntivo su file di grandi dimensioni e un impatto negativo sulle prestazioni del database tempdb.
È necessario garantire manualmente che tutti i file di dati tempdb siano dimensionati in modo uniforme in qualsiasi momento per evitare conflitti o problemi di prestazioni fino a SQL Server 2014. Microsoft ha modificato questo comportamento a partire da SQL Server 2016 e versioni successive implementando alcune funzionalità che saranno discusso più avanti in questo articolo.
Per superare i problemi di prestazioni di cui sopra, SQL Server ha introdotto 2 flag di traccia denominato 1117 e 1118 per evitare problemi di contesa attorno a tempdb.
- Traccia bandiera 1117 – abilita la crescita automatica di tutti i file all'interno di un singolo Filegroup
- Traccia bandiera 1118 – abilita UNIFORM FULL EXTENTS per tempdb
Traccia bandiera 1117
Senza il flag di traccia 1117 abilitato, ogni volta che tempdb è configurato con più file di dati di dimensioni uniformi e i file di dati devono crescere automaticamente, SQL Server per impostazione predefinita tenterà di aumentare le dimensioni dei file in modo round-robin se tutti i file. Se i file di dati non sono dimensionati in modo uniforme, SQL Server tenterà di aumentare la dimensione del file di dati più grande di tempdb e utilizzerà questo file di dimensioni maggiori per la maggior parte delle operazioni dell'utente che provocano problemi di contesa di tempdb.
Per risolvere questo problema, SQL Server ha introdotto il flag di traccia 1117. Una volta abilitato, se un file all'interno di un filegroup deve crescere automaticamente, aumenterà automaticamente tutti i file all'interno di quel filegroup. Risolve i problemi di contesa di tempdb. Tuttavia, il problema è che una volta abilitato il flag di traccia 1117, la crescita automatica è configurata anche per tutti i database utente.
Traccia bandiera 1118
Il flag di traccia 1118 viene utilizzato per abilitare UNIFORM FULL EXTENTS. Facciamo un passo indietro per capire come SQL Server archivia i dati di base.
Pagina è l'unità di archiviazione fondamentale in SQL Server con una dimensione di 8 Kilobyte (KB).
Estensione è un insieme di 8 pagine fisicamente contigue con una dimensione di 64KB(8*8KB). In base a quanti oggetti o proprietari memorizzano i dati all'interno di un'estensione, l'estensione può essere classificata in:
- Estensioni uniformi sono 8 pagine contigue utilizzate o accessibili da un singolo oggetto o proprietario;
- Misto Estensioni – sono 8 pagine contigue utilizzate o accessibili da un minimo di 2 a un massimo di 8 oggetti o proprietari
L'abilitazione di Trace Flag 1118 consentirà a tempdb di avere estensioni uniformi con conseguente miglioramento delle prestazioni.
Come abilitare i flag di traccia 1117 e 1118
I flag di traccia possono essere abilitati tramite diversi approcci. Puoi definire il modo adatto dalle seguenti opzioni:
Parametri di avvio del servizio SQL Server
Permanentemente disponibile anche dopo il riavvio del servizio SQL. Il metodo consigliato è abilitare i flag di traccia 1117 e 1118 tramite i parametri di avvio del servizio SQL Server .
Apri Gestione configurazione SQL Server e fare clic su Servizi SQL Server per elencare i servizi disponibili in quel server:

- Fai clic con il pulsante destro del mouse su SQL Server (MSSQLSERVER) > Proprietà > Parametri di avvio .
- Digitare –T nel campo vuoto per indicare il Trace Flag .
- Fornisci valori 1117 e 1118 come mostrato di seguito.
- Fai clic su Aggiungi per avere i flag di traccia aggiunti come parametri di avvio.
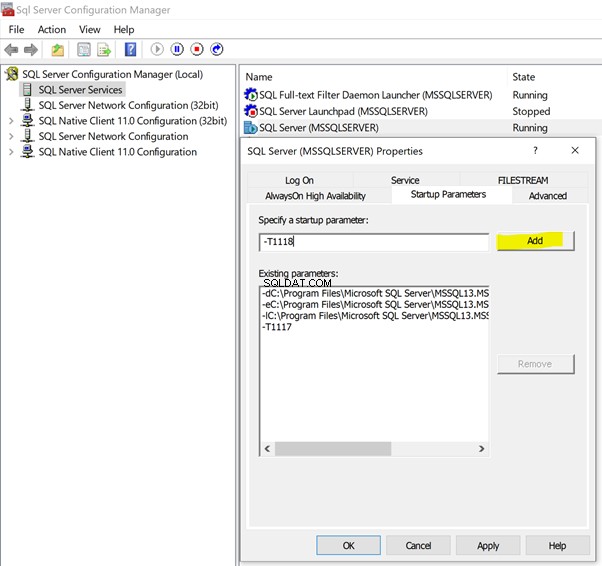
Quindi fai clic su OK per fare in modo che i flag di traccia vengano aggiunti in modo permanente per questa istanza di SQL Server. Riavvia il servizio SQL Server per visualizzare le modifiche.
DBCC TRACEON (, -1)
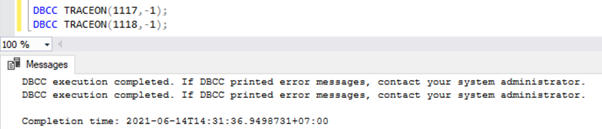
Abilita un flag di traccia a livello globale. Il servizio SQL Server perderà i flag di traccia al riavvio del servizio. Per abilitare un flag di traccia a livello globale, esegui lo script seguente in una nuova finestra di query:
DBCC TRACEON(1117,-1);
DBCC TRACEON(1118,-1);
DBCC TRACEON ()
Abilita il flag di traccia a livello di sessione. Si applica solo alla sessione corrente creata dall'utente. Per abilitare un flag di traccia a livello di sessione, esegui lo script seguente in una nuova finestra di query:
DBCC TRACEON(1117);
DBCC TRACEON(1118);
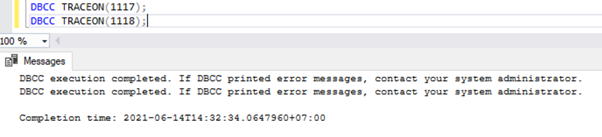
Per visualizzare l'elenco dei flag di traccia abilitati in un'istanza di SQL Server, possiamo utilizzare il DBCC TRACESTATUS comando:
DBCC TRACESTATUS();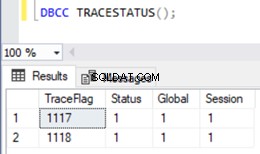
Come possiamo vedere, I flag di traccia 1117 e 1118 sono abilitati a livello globale nella mia istanza insieme a Session .
Per disattivare un flag di traccia, possiamo utilizzare il comando DBCC TRACEOFF come:
DBCC TRACEOFF(1117,-1);
DBCC TRACEOFF(1118,-1);
Miglioramenti di SQL Server 2016 TempDB
In tutte le versioni di SQL Server da SQL Server 2000 a SQL Server 2014, è necessario abilitare i flag di traccia 1117 e 1118 insieme al monitoraggio completo di tempdb per evitare problemi di contesa di tempdb. A partire da SQL Server 2016 e versioni successive, i flag di traccia 1117 e 1118 sono implementati per impostazione predefinita.
Tuttavia, in base alla mia esperienza personale, è meglio pre-creare tempdb a una dimensione enorme per evitare la necessità di crescita automatica più volte ed eliminare dimensioni di file irregolari o singoli file ampiamente utilizzati da SQL Server .
Possiamo verificare come vengono implementati i flag di traccia 1117 e 1118 in SQL Server 2016:
Traccia bandiera 1117 che imposta la crescita automatica di tutti i file all'interno di un filegroup è ora una proprietà del filegroup . Possiamo configurarlo mentre creiamo un nuovo Filegroup o ne modifichiamo uno esistente.
Per verificare la proprietà di crescita automatica del Filegroup , esegui lo script seguente da sys.filegroups DMV :
SELECT name Filegroup_Name, is_autogrow_all_files
FROM sys.filegroups
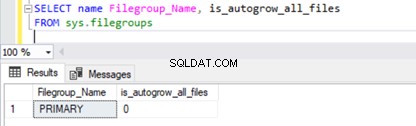
Per modificare la proprietà di crescita automatica del filegroup principale del database AdventureWorks , eseguiamo lo script seguente con AUTOGROW_ALL_FILES per aumentare automaticamente tutti i file allo stesso modo o AUTOGROW_SINGLE_FILE per consentire la crescita automatica di un solo file di dati.
ALTER DATABASE Adventureworks MODIFY FILEGROUP [PRIMARY]
AUTOGROW_SINGLE_FILE
-- AUTOGROW_ALL_FILES is the default behavior
GO
Traccia bandiera 1118 che imposta la proprietà Uniform Extent dei file di dati è abilitato per impostazione predefinita per tempdb e tutti i database utente a partire da SQL Server 2016 . Non possiamo modificare le proprietà di tempdb, poiché ora supporta solo l'opzione Estensione uniforme.
Per i database utente, possiamo modificare questo parametro. Il master, il modello e il msdb dei database di sistema supportano estensioni miste per impostazione predefinita e non possono essere modificati.
Per modificare i valori delle proprietà di allocazione delle pagine miste per i database utente, utilizzare lo script seguente:
ALTER DATABASE Adventureworks SET MIXED_PAGE_ALLOCATION ON
-- OFF is the default behavior
GO
Per verificare la proprietà di allocazione di pagine miste, possiamo eseguire una query su is_mixed_page_allocation_on colonna da sys.databases DMV con un valore pari a 0, che indica l'allocazione di pagine di estensione uniforme e 1 per indicare l'allocazione di pagine di estensione mista.
SELECT name, is_mixed_page_allocation_on
FROM sys.databases
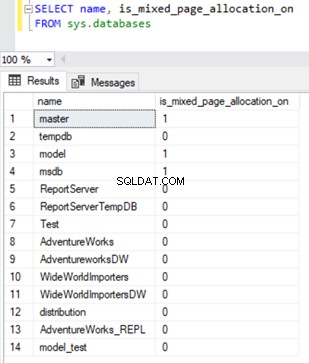
File di dati TempDB che crescono a un valore enorme che richiede la riduzione di TempDB
In SQL Server 2014 o versioni precedenti, se i flag di traccia 1117 e 1118 non sono configurati correttamente insieme a più file di dati creati per il database tempdb, alcuni di questi file diventeranno inevitabilmente enormi. In tal caso, un DBA in genere tenta di ridurre i file di dati tempdb. Ma è un improprio approccio per gestire questo scenario.
Sono disponibili altre opzioni per ridurre il tempdb.
Consideriamo i comandi DBCC disponibili per Shrink tempdb e l'impatto di queste operazioni.
DBCC SHRINKDATABASE
Il DBCC SHRINKDATABASE il comando della console funziona riducendo la fine dei file di dati\log .
Per ridurre correttamente un database, il comando necessita di spazio libero alla fine del file. Se sono presenti transazioni attive alla fine del file, i file del database non possono essere ridotti.
L'impatto dell'esecuzione di DBCC SHRINKDATABASE è che proverà a liberare lo spazio libero disponibile alla fine di ogni file di dati o file di registro che potrebbe essere stato riservato per la crescita futura dei dati della tabella. Pertanto, l'esecuzione di questo comando potrebbe comportare dimensioni di file non uniformi che portano a problemi di contesa tempdb.
La sintassi per ridurre un database utente, ad esempio il database Adventureworks, sarebbe
DBCC SHRINKDATABASE (AdventureWorks, TRUNCATEONLY);FILE TERMORETRAIBILE DBCC
Il FILE TERMORETRAIBILE DBCC il comando della console funziona in modo simile a DBCC SHRINKDATABASE, ma riduce i dati del database oi file di registro specificati .
Se identifichi che un particolare file di dati tempdb è enorme, possiamo provare a ridurre quel particolare elemento utilizzando DBCC SHRINKFILE come mostrato di seguito.
Prestare attenzione durante l'utilizzo di questo comando su tempdb perché se un file viene ridotto a un valore inferiore o superiore ad altri file di dati, quel particolare file di dati non verrà utilizzato in modo efficace. In alternativa, verrà utilizzato più frequentemente causando problemi di contesa di tempdb.
La sintassi per eseguire l'operazione DBCC SHRINKFILE sul file di dati AdventureWorks a 1 GB (1024 MB) sarebbe:
DBCC SHRINKFILE (AdventureWorks, 1024);
GO
DBCC DROPCLEANBUFFERS
I DBCC DROPCLEANBUFFERS il comando console viene utilizzato per cancellare tutti i buffer puliti dal pool di buffer e gli oggetti columnstore dal pool di oggetti columnstore .
Basta eseguire il comando seguente:
DBCC DROPCLEANBUFFERSDBCC FREEPROCCACHE
Il DBCC FREEPROCCACHE il comando cancella tutta la cache del piano di esecuzione della stored procedure .
La cache del piano di esecuzione delle procedure viene utilizzata da SQL Server per eseguire più rapidamente le stesse chiamate di procedura. Dopo aver eseguito DBCC FREEPROCCACHE, la Plan Cache viene cancellata. Pertanto, SQL Server deve creare nuovamente quella cache quando la stored procedure viene eseguita nell'istanza. Lascia un grave impatto negativo quando viene eseguito nelle istanze database di produzione.
Non è consigliabile eseguire DBCC FREEPROCCACHE sull'istanza del database di produzione!
La sintassi per eseguire DBCC FREEPROCCACHE è la seguente:
DBCC FREEPROCCACHECACHE FREESESSION DBCC
Il DBCC FREESESSIONCACHE comando cancella la cache di connessione della query di distribuzione dall'istanza di SQL Server . Sarà utile quando ci sono molte query distribuite in esecuzione su una particolare istanza di SQL Server.
La sintassi per eseguire DBCC FREESESSIONCACHE sarebbe:
DBCC FREESESSIONCACHEDBCC FREESYSTEMCACHE
Il DBCC FREESYSTEMCACHE comando cancella tutte le voci della cache inutilizzate da tutta la cache . SQL Server esegue questa operazione per impostazione predefinita per rendere disponibile più memoria per le nuove operazioni. Tuttavia, possiamo eseguirlo manualmente usando il comando seguente:
DBCC FREESYSTEMCACHECome sappiamo, tempdb archivia tutti gli oggetti utente temporanei o gli oggetti interni, inclusi la cache del piano di esecuzione, i dati del pool di buffer, le cache di sessione e le cache di sistema. Pertanto, l'esecuzione dei 6 comandi DBCC precedenti aiuterà a cancellare i file di dati tempdb che impediscono il normale processo di riduzione.
Anche se abbiamo seguito i passaggi su come ridurre tempdb tramite vari approcci, le procedure consigliate per gestire il database tempdb sono elencate di seguito:
a. Riavviare i servizi SQL Server, se possibile, per ricreare i file di dati tempdb in modo uniforme. Il potenziale impatto sarebbe che perderemo tutti i piani di esecuzione e altre informazioni sulla cache discusse sopra.
b. Pre-crescita i file di dati tempdb in un'enorme dimensione di file disponibile nell'unità che contiene i file di dati tempdb. Ciò impedirà a SQL Server di aumentare le dimensioni dei file in modo non uniforme in SQL Server versioni 2014 e precedenti.
c. Se i servizi SQL Server non possono essere riavviati a causa di RTO o RPO, prova i comandi DBCC sopra dopo aver compreso chiaramente gli impatti.
d. La riduzione del database tempdb o dei file di dati non è un approccio consigliato e quindi non farlo mai nell'ambiente di produzione, a meno che non ci siano altre opzioni.
Conclusione
Abbiamo appreso di più sugli elementi interni del funzionamento di tempdb in modo da poter configurare tempdb per prestazioni migliori evitando problemi di contesa su tempdb. Abbiamo anche esaminato i problemi frequenti in tempdb, le misure disponibili in SQL Server in varie versioni e come gestirle in modo efficiente. Inoltre, abbiamo esaminato il motivo per cui la riduzione del database tempdb o dei file di dati non è un approccio consigliato durante la gestione del database tempdb.