Ho trascorso una settimana nella magnifica città di Lisbona partecipando alla conferenza annuale europea di PostgeSQL. Questo ha segnato il decimo anniversario dalla prima conferenza europea di PostgreSQL e la mia sesta partecipazione.
Prime impressioni
La città era fantastica, l'atmosfera era fantastica e sembrava che sarebbe stata una settimana molto produttiva e istruttiva, piena di conversazioni interessanti con persone intelligenti e amichevoli. Quindi, in pratica, la prima cosa davvero interessante che ho imparato a Lisbona è quanto siano fantastici Lisbona e il Portogallo, ma immagino che tu sia venuto qui per il resto della storia!


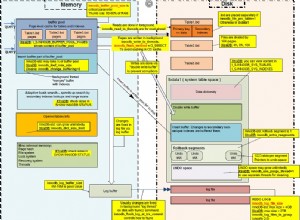
Buffer condivisi
Abbiamo partecipato alla sessione di formazione "Toolbelt DBA PostgreSQL per le operazioni quotidiane"
di Kaarel Moppel (Cybertec) . Una cosa che ho notato è stata l'impostazione di shared_buffers. Poiché shared_buffers effettivamente compete o integra la cache di sistema, non dovrebbe essere impostato su alcun valore compreso tra il 25% e il 75% della RAM totale disponibile. Quindi, mentre, in generale, l'impostazione consigliata per i carichi di lavoro tipici è il 25% della RAM, potrebbe essere impostata su>=75% per casi speciali, ma non nel mezzo.
Altre cose che abbiamo imparato in questa sessione:
- sfortunatamente l'attivazione/abilitazione online (o offline) dei checksum dei dati non è ancora in 11 (initdb/replica logica rimane l'unica opzione)
- attenzione a vm.overcommit_memory, è meglio disabilitarlo impostandolo su 2. Impostare vm.overcommit_ratio su circa 80.
Replica logica avanzata

Nel discorso di Petr Jelinek (2° quadrante) , gli autori originali della replica logica, abbiamo appreso degli usi più avanzati di questa nuova entusiasmante tecnologia:
- Raccolta centralizzata dei dati:potremmo avere più editori e quindi un sistema centrale con un abbonato a ciascuno di questi editori, rendendo disponibili i dati da varie fonti in un sistema centrale. (uso tipico:OLAP)
- Dati globali condivisi o in altre parole un sistema centrale per il mantenimento di dati e parametri globali (come valute, azioni, valori di mercato/merce, meteo, ecc.) che pubblica su uno o più abbonati. Quindi questi dati vengono mantenuti solo in un sistema ma disponibili in tutti gli abbonati.
- La replica logica può essere asincrona ma anche sincrona (garantita al commit)
- Nuove possibilità con la decodifica logica:
- integrazione con Debezium/Kafka tramite plugin di decodifica logica
- plug-in wal2json
- Replica bidirezionale
- Aggiornamenti con tempi di inattività prossimi allo zero:
- impostare la replica logica sul nuovo server (possibilmente initdb con abilitazione dei checksum dei dati)
- aspetta finché il ritardo non è relativamente piccolo
- da pgbouncer metti in pausa i database
- aspetta finché il ritardo non è zero
- modifica la configurazione di pgbouncer in modo che punti al nuovo server, ricarica la configurazione di pgbouncer
- da pgbouncer riprendere i database
Novità di PostgreSQL 11

In questa entusiasmante presentazione, Magnus Hagander (Redpill Linpro AB) ci ha presentato le meraviglie di PostgreSQL 11:
- pg_stat_statements supporta queryid a 64 bit.
- pg_prewarm (un metodo per riscaldare la cache del sistema o i buffer condivisi):aggiunta di nuovi parametri di configurazione
- Nuovi ruoli predefiniti che facilitano l'allontanamento da postgres (l'utente intendo :))
- Stored procedure con controllo xazionale
- Ricerca full-text migliorata
- La replica logica supporta TRUNCATE
- I backup di base (pg_basebackup) convalidano i checksum
- Diversi miglioramenti nella parallelizzazione delle query
- Partizionamento ancora più raffinato rispetto a 10
- partizione predefinita
- aggiornamenti tra partizioni (sposta la riga da una partizione all'altra)
- indici di partizione locali
- Chiave univoca su tutte le partizioni (ancora non referenziabile)
- partizionamento hash
- join a livello di partizione
- aggregati per partizione
- le partizioni potrebbero essere tabelle esterne in diversi server esterni. Ciò apre grandi possibilità per una frammentazione a grana più fine.
- Compilazione JIT
zheap:una risposta ai problemi di rigonfiamento di PostgreSQL
Questo non è ancora in 11, ma sembra così promettente che ho dovuto includerlo nell'elenco delle cose interessanti. La presentazione è stata tenuta da Amit Kapila (EnterpriseDB) uno dei principali autori di questa nuova tecnologia che mira ad essere eventualmente integrata nel core di PostgreSQL come tipo alternativo di heap. Questo sarà integrato con la nuova Pluggable Storage API in PostgreSQL, che supporterà più metodi di accesso alle tabelle (allo stesso modo dei vari metodi di accesso [Indice] trattati nel mio primo blog).
Questo cercherà di risolvere le carenze croniche che PostgreSQL ha con:
- gonfiore da tavola
- necessità di (auto)vuotare
- potenzialmente un wraparound dell'ID transazione
Tutti questi non sono un problema per le medie e grandi imprese (sebbene questo sia molto relativo), conosciamo banche e altri istituti finanziari che eseguono PostgreSQL di decine di TB di dati e diverse transazioni di 1000 secondi al secondo senza problemi. Il rigonfiamento della tabella è gestito da autovacuum e il blocco delle righe risolve il problema del wraparound dell'ID transazione, ma questo non è ancora esente da manutenzione. La comunità di PostgreSQL lavora per un database veramente esente da manutenzione, quindi viene proposta l'architettura zheap. Questo porterà:
- un nuovo registro UNDO
- Il registro UNDO renderà visibili i dati alle vecchie transazioni vedendo le vecchie versioni
- UNDO verrà utilizzato per annullare gli effetti delle transazioni interrotte
- i cambiamenti avvengono sul posto. Le vecchie versioni non sono più conservate nei file di dati.
Obiettivi di alto livello:
- migliore controllo del gonfiore
- meno scritture
- intestazioni di tupla più piccole
Ciò porterà PostgreSQL alla pari con MySql e Oracle in questo senso.
Query parallela in PostgreSQL:come non (mal)usarla?
In questa presentazione di Amit Kapila e Rafia Sabih (EnterpriseDB) abbiamo appreso i segreti della parallelizzazione e anche suggerimenti per evitare errori comuni e alcune impostazioni GUC consigliate:
- Il parallelismo supporta solo gli indici B-tree
- max_parallel_workers_per_gather impostato su 1→ 4 (a seconda dei core disponibili)
- prestare attenzione alle seguenti impostazioni:
- parallel_tuple_cost:costo per il trasferimento di una tupla da un processo di lavoro parallelo a un altro processo
- parallel_setup_cost:costo per avviare i lavoratori paralleli e inizializzare la memoria condivisa dinamica
- min_parallel_table_scan_size:la dimensione minima delle relazioni da considerare per la scansione di sequenze parallele
- min_parallel_index_scan_size:la dimensione minima dell'indice da considerare per una scansione parallela
- random_page_cost:costo stimato per l'accesso a una pagina casuale nel disco