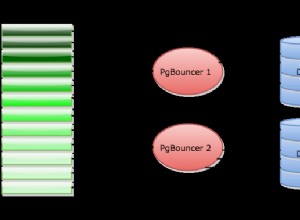
L'apertura di una connessione al database è un'operazione costosa e il pool di connessioni viene utilizzato per mantenere aperte le connessioni al database in modo che possano essere riutilizzate. Ciò evita di dover aprire ripetutamente sessioni di rete, autenticarsi e verificare l'autorizzazione. Il pooling mantiene attive le connessioni in modo che, quando viene successivamente richiesta una connessione, ne venga utilizzata una di quelle attive anziché doverne crearne una da zero.
Collegamento di connessioni
Il pool di connessioni è diventato uno dei metodi più comuni per gestire le connessioni al database prima di una richiesta di query. Normalmente pensiamo che una connessione al database sia veloce, ma non è così soprattutto quando si connette un gran numero di client. Senza il pool di connessioni, una richiesta richiederebbe fino a 35-50 ms per la connessione, ma 1-2 ms se si utilizza il pool di connessioni. Il pool di connessioni sta quindi preallocando le connessioni al database e quindi le ricicla quando si connettono nuovi client
Motivi del pool di connessioni
- Per evitare di mandare in crash il tuo server. I server PostgreSQL sono limitati a un numero di client che gestiscono alla volta a seconda del parametro di memoria. Se questo numero viene superato, finirai per arrestare il server in modo anomalo. Con il pool di connessioni, i client utilizzano un determinato numero di connessioni.
- Facilita l'elaborazione delle query. Normalmente, le richieste del database vengono eseguite in modo seriale con un criterio first-in first-out. Con una vasta gamma di clienti, ciò richiederebbe anni per raggiungere questo processo. Pertanto l'approccio dovrebbe essere quello di creare un'unica connessione con richieste pipeline che possono essere eseguite simultaneamente anziché ciascuna alla volta.
- Migliora la sicurezza. Spesso una connessione comporta un handshake che può richiedere in media 25-35 ms durante i quali viene stabilito un SSL, vengono controllate le password e la condivisione delle informazioni di configurazione. Tutto questo lavoro per ogni utente connesso comporterà un ampio utilizzo della memoria. Tuttavia, con il pool di connessioni, il numero di connessioni viene ridotto, risparmiando così memoria.
Tipi di pool di connessioni
Esistono fondamentalmente due tipi di pool di connessioni, tuttavia esiste un terzo tipo di soluzione alternativa che agisce come una strategia di pool di connessioni nota come connessioni persistenti.
pooling di connessioni persistente
Questo approccio intende mantenere attiva una connessione iniziale dal momento in cui viene avviata. Non mantiene completamente le funzionalità di pooling delle connessioni, ma abbastanza bene da fornire una connessione continua. È abbastanza utile per un piccolo insieme di connessioni client il cui sovraccarico può variare tra 25-50 ms. Una limitazione di questo approccio è che è limitato a un numero di connessioni al db con normalmente una singola connessione per voce al server.
pooling di connessioni quadro
Il pool di connessioni del framework si verifica a livello di applicazione per cui, ogni volta che viene avviato lo script del server, viene stabilito un pool di connessioni per gestire le richieste di query che arriveranno in seguito.
Pooling di connessioni autonomo
Per ogni connessione al database, viene utilizzata una memoria di sovraccarico compresa tra 5 e 10 MB per soddisfare una richiesta di query. Questo non è abbastanza buono per un gran numero di connessioni. L'uso del pool di connessioni del framework può essere limitato da questo numero di connessioni poiché potrebbe verificarsi un utilizzo di grandi dimensioni della memoria. Scegliamo quindi di utilizzare il pool di connessioni autonomo che è configurato in base alle sessioni, alle dichiarazioni e alle transazioni di Postgres. Il vantaggio principale associato a questo approccio è:costi generali minimi di circa 2kb per ogni connessione.
Quando crei una classe di pool di connessioni, dovrebbe soddisfare i seguenti fattori per migliorare le prestazioni del database:
- Preallocare le connessioni
- Controlla i collegamenti disponibili
- Assegna nuove connessioni
- Attendere che sia disponibile una connessione
- Chiudi connessione
Preallocazione delle Connessioni
Garantire più connessioni in anticipo faciliterà la gestione delle richieste nel momento in cui l'applicazione è stata avviata. Ad esempio, se il tuo server è sviluppato con Java, puoi utilizzare i vettori per memorizzare le connessioni inattive disponibili utilizzando il codice seguente.
availableConnections = new Vector(connections);
busyConnections = new Vector();
for(int i=0; i<connections; i++) {
availableConnections.addElement(makeNewConnection());
}Controllare le connessioni disponibili
La classe dovrebbe essere in grado di controllare eventuali connessioni inattive in un elenco di connessioni occupate e restituirle. Questo è fondamentalmente fatto per riutilizzare una connessione o chiudere le connessioni che non sono in uso. A volte le connessioni si interrompono, quindi durante il ripristino di una connessione è abbastanza importante verificare se è ancora aperta. In caso contrario, dovrai eliminare questa connessione e ripetere il processo. Quando una connessione viene annullata, viene aperto uno slot che può essere utilizzato per elaborare una nuova connessione una volta raggiunto il limite. Questo può essere ottenuto con
public synchronized Connection getConnection() throws SQLException {
if (!availableConnections.isEmpty()) { Connection existingConnection =
(Connection)availableConnections.lastElement(); int lastIndex = availableConnections.size() - 1; availableConnections.removeElementAt(lastIndex); if (existingConnection.isClosed()) {
notifyAll(); // Freed up a spot for anybody waiting.
return(getConnection()); // Repeat process. } else {
busyConnections.addElement(existingConnection);
return(existingConnection); }
} }Assegnazione di una nuova connessione
Dovresti essere in grado di avviare un thread in background per assegnare una nuova connessione se non è disponibile alcun inattivo e se il limite di connessione è quasi raggiunto.
if ((totalConnections() < maxConnections) && !connectionPending) { // Pending = connecting in bg
makeBackgroundConnection(); }
try {
wait(); // Give up lock and suspend self.
} catch(InterruptedException ie) {} return(getConnection()); // Try again.In attesa di una nuova connessione
Quando non è presente alcuna connessione inattiva ed è stato raggiunto il limite di connessione, la configurazione dovrebbe essere in grado di attendere la disponibilità di una nuova connessione senza il pool continuo. Possiamo farlo utilizzando il metodo wait che fornisce un blocco della sincronizzazione del thread e sospende il thread fino a quando non viene fornita una notifica.
try {
wait();
} catch(InterruptedException ie) {}
return(getConnection());Per una buona etica dell'applicazione, i client non dovrebbero attendere in tempo reale per una connessione, ma genererai un'eccezione quando le connessioni sono assenti con il codice seguente:
throw new SQLException("Connection limit reached");Chiusura della connessione
Quando le connessioni vengono raccolte in modo obsoleto, dovresti chiuderle anziché farlo in modo esplicito. Tuttavia, se desideri un approccio esplicito per chiudere una connessione, puoi utilizzare:
public synchronized void closeAllConnections() {
// The closeConnections method loops down Vector, calling // close and ignoring any exceptions thrown. closeConnections(availableConnections); availableConnections = new Vector(); closeConnections(busyConnections);
busyConnections = new Vector();
}Conclusione
Il pool di connessioni per PostgreSQL ci aiuta a ridurre il numero di risorse necessarie per la connessione al database e migliora la velocità di connettività al database. Ciò si ottiene raggruppando le connessioni al DB, mantenendo queste connessioni e riducendo di conseguenza il numero di connessioni che devono essere aperte.