L'assicurazione sulla vita è qualcosa di cui tutti speriamo di non aver bisogno, ma come sappiamo, la vita è imprevedibile. In questo articolo, ci concentreremo sulla formulazione di un modello di dati che una compagnia di assicurazioni sulla vita può utilizzare per archiviare le proprie informazioni.
L'assicurazione sulla vita come concetto
Prima di iniziare a discutere del modello di dati effettivo per una compagnia di assicurazioni sulla vita, ricorderemo brevemente a noi stessi cosa sono le assicurazioni e come funzionano in modo da avere un'idea migliore di ciò con cui stiamo lavorando.
L'assicurazione è un concetto piuttosto vecchio che risale addirittura a prima del Medioevo, quando molte corporazioni offrivano polizze per proteggere i propri membri in situazioni inaspettate. Anche il famoso astronomo, matematico, scienziato e inventore Edmund Halley si dilettava di assicurazioni, lavorando su statistiche e tassi di mortalità che costituivano la spina dorsale dei moderni modelli assicurativi.
Perché dovresti pagare l'assicurazione? L'idea è abbastanza semplice:paghi un certo importo (il premio) in cambio della garanzia della compagnia assicurativa che tu o la tua famiglia sarete risarciti finanziariamente se succede qualcosa di inaspettato a voi o alla vostra proprietà. Nel caso di una polizza di assicurazione sulla vita, designi un beneficiario che riceverà una somma di denaro (il beneficio) in caso di tuo decesso. L'idea è che questo denaro li aiuterà a riprendersi dalla perdita, soprattutto se la tua morte crea problemi finanziari.
Naturalmente, le compagnie di assicurazione in genere pagano molto meno in benefici di quanto guadagnano dai premi e dall'investimento, ad esempio, del mercato azionario. Altrimenti, andrebbero in bancarotta e l'intero sistema crollerebbe!
Questo è praticamente il succo della questione. Ora che l'abbiamo tolto di mezzo, andiamo avanti e diamo un'occhiata al modello di dati per una tipica compagnia di assicurazioni sulla vita.
Il modello di dati:panoramica
Il modello di dati con cui lavoreremo è composto da cinque aree tematiche:
- Dipendenti
- Prodotti
- Clienti
- Offerte
- Pagamenti
Tratteremo ciascuna di queste sezioni in modo più dettagliato, nell'ordine in cui sono elencate sopra.
Area tematica n. 1:Dipendenti
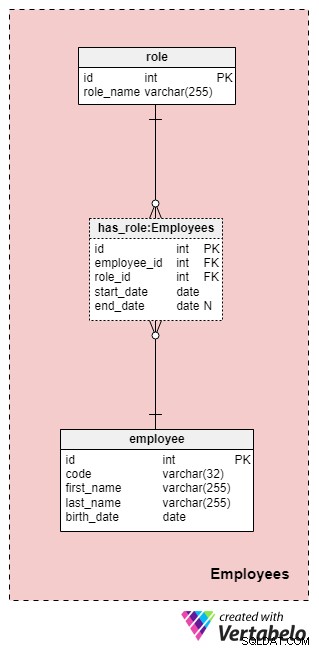
Quest'area non è necessariamente specifica per questo modello di dati, ma è comunque molto importante perché le tabelle qui contenute saranno referenziate da altre aree tematiche. Ai fini del nostro modello di dati della compagnia assicurativa, dovremo ovviamente sapere chi ha eseguito quale azione (ad esempio, chi ha rappresentato la nostra azienda quando lavora con il cliente/cliente, chi ha firmato la polizza e così via).
L'elenco di tutti i dipendenti dell'azienda è memorizzato nel employee tavolo. Per ogni dipendente, memorizzeremo le seguenti informazioni:
code— una chiave univoca che identifica un singolo dipendente. Poiché il codice verrà utilizzato come attributo in altre tabelle, fungerà da chiave alternativa in questa tabella.first_nameelast_name— rispettivamente il nome e il cognome del dipendente.birth_date— la data di nascita del dipendente.
Naturalmente, potremmo certamente includere molti altri attributi relativi ai dipendenti in questa tabella, ma per ora questi quattro sono più che sufficienti. Seguiremo questo schema per tutto l'articolo e cercheremo di mantenere le cose il più semplici possibile, ma tieni presente che puoi sicuramente espandere questo modello di dati per includere informazioni aggiuntive.
Poiché i dipendenti possono cambiare i loro ruoli nella nostra azienda in qualsiasi momento, avremo bisogno di una tabella dizionario per rappresentare i ruoli aziendali e una tabella per memorizzare i valori. L'elenco di tutti i possibili ruoli che i dipendenti possono assumere presso la nostra compagnia di assicurazioni sulla vita è archiviato nel role dizionario. Ha un solo attributo chiamato role_name che contiene valori identificativi univoci.
Metteremo in relazione dipendenti e ruoli utilizzando has_role tavolo. Oltre alle chiavi esterne employee_id e role_id , memorizzeremo due valori:start_date e end_date . Questi due valori denotano l'intervallo in cui questo ruolo aziendale era attivo per un determinato dipendente. Il end_date conterrà un valore nullo fino a quando non sarà stata determinata una data di fine per il ruolo di questo dipendente. La chiave alternativa per questa tabella è la combinazione di employee_id , role_id e start_date . Per evitare di duplicare lo stesso ruolo per lo stesso dipendente, dovremo controllare a livello di codice eventuali sovrapposizioni ogni volta che aggiungiamo un nuovo record alla tabella o ne aggiorniamo uno esistente.
Area tematica n. 2:Prodotti
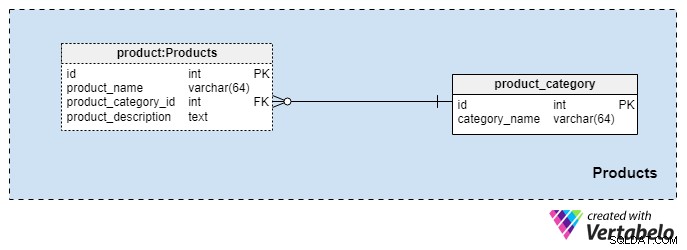
Questa area tematica è piuttosto piccola e contiene solo due tabelle. I valori di queste tabelle sono prerequisiti per le altre nostre aree tematiche, quindi ne discuteremo brevemente.
Il product_category Il dizionario memorizza le categorie più generali di prodotti che intendiamo offrire ai nostri clienti. L'unico valore che memorizzeremo in questa tabella è il category_name univoco per indicare il tipo di assicurazione che offriamo, che potrebbe essere un'assicurazione sulla vita personale, un'assicurazione sulla vita familiare e così via.
Classificheremo ulteriormente i nostri prodotti utilizzando il product tavolo. Questa tabella rappresenta i prodotti effettivi che vendiamo e non le loro categorie. Come puoi immaginare, possiamo raggruppare i prodotti per durata (ad esempio, 10 o 20 anni, o anche una vita). Se scegliamo di farlo, probabilmente avremo prodotti con lo stesso product_category_id ma nomi e descrizioni differenti. Per ogni prodotto, memorizzeremo le seguenti informazioni di base:
product_name— il nome di questo prodotto. Viene utilizzata come chiave alternativa per questa tabella in combinazione conproduct_category_idattributo. È improbabile che avremo due prodotti con lo stesso nome che appartengono a categorie diverse, ma è comunque una possibilità.product_category_id— identifica la categoria a cui appartiene questo prodotto.product_description— descrizione testuale di questo prodotto.
Area tematica n. 3:Clienti
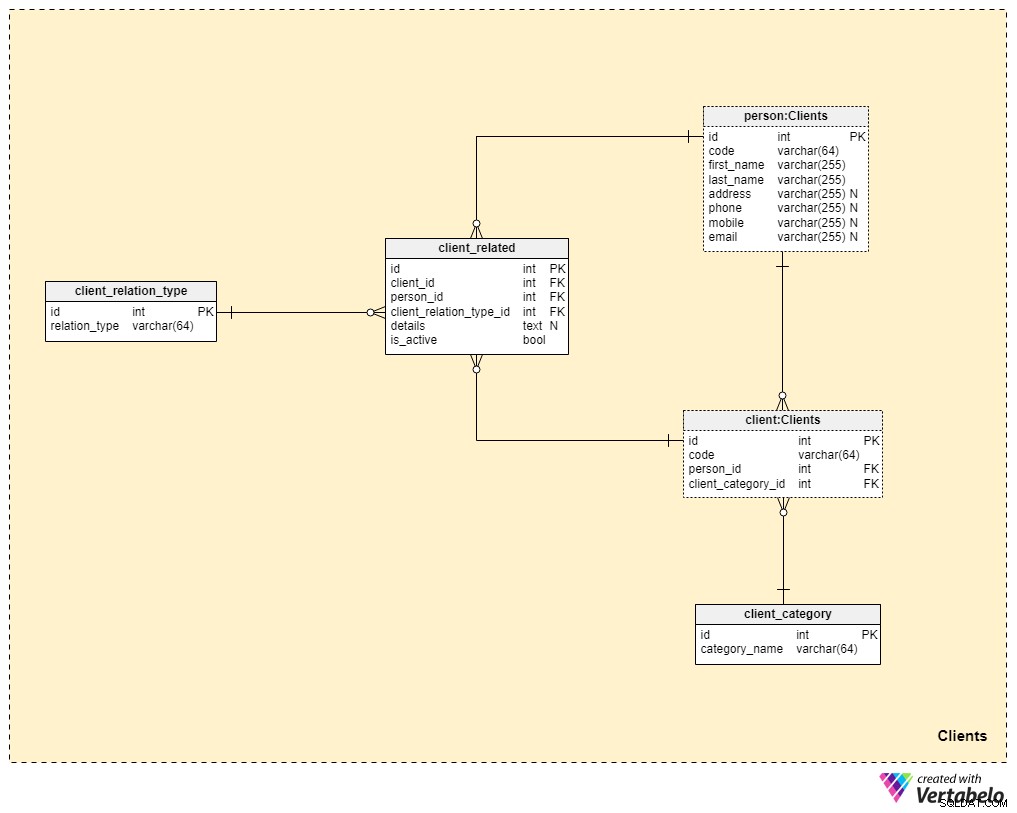
Ora ci stiamo avvicinando molto al nucleo del nostro modello di dati, ma non ci siamo ancora del tutto. L'assicurazione sulla vita è unica perché una polizza può essere trasferita a un familiare o qualcun altro, mentre le polizze per altre forme assicurative (come l'assicurazione sanitaria o l'assicurazione auto) appartengono a un unico cliente e non possono essere trasferite. Per questo motivo, dovremo archiviare non solo le informazioni sul cliente a cui appartiene la polizza, ma anche informazioni su eventuali persone correlate e sulla loro relazione con il cliente.
Inizieremo con il client tavolo. Per ogni cliente memorizzeremo il codice univoco generato o inserito manualmente per quel cliente, nonché le chiavi esterne che fanno riferimento alla tabella con i propri dati personali (person_id ) e la tabella contenente la nostra categorizzazione interna (client_category_id ).
La client_category Il dizionario ci consente di raggruppare i clienti in base ai loro dati demografici e finanziari. Le categorie di clienti verranno quindi utilizzate per determinare la polizza assicurativa che siamo pronti a offrire a un determinato cliente. Qui memorizzeremo solo un elenco di valori univoci che poi assegneremo ai clienti.
Dal momento che stiamo parlando di assicurazione sulla vita, quindi supponiamo che un cliente sia un singolo individuo. Tuttavia, come accennato in precedenza, potrebbero esserci altre persone legate al cliente a cui la polizza potrebbe essere trasferita o che potrebbero ricevere il beneficio della polizza alla morte del cliente. Per questo motivo, abbiamo creato una person tavolo. Per ogni record in questa tabella, memorizzeremo le seguenti informazioni:
code— un valore generato automaticamente o inserito manualmente utilizzato per identificare in modo univoco la persona correlata.first_nameelast_name— rispettivamente il nome e il cognome della persona.address,phone,mobileeemail— i dettagli di contatto di questa persona, che contengono tutti valori arbitrari.
Le restanti due tabelle in questa area tematica sono necessarie per descrivere la natura della relazione tra i clienti e le altre persone.
L'elenco di tutti i possibili tipi di relazione è memorizzato nel client_relation_type dizionario. Come con altri dizionari, questo conterrà un elenco di nomi univoci che utilizzeremo in seguito per descrivere la relazione tra un particolare cliente e un'altra persona.
I dati di relazione effettivi sono memorizzati nel client_related tavolo. Per ogni record in questa tabella, memorizzeremo i riferimenti al client (client_id ), la persona correlata (person_id ), la natura di tale relazione (client_relation_type_id ), tutti i dettagli dell'aggiunta (details ), se presente, e un flag che indica se la relazione è attualmente attiva (is_active ). La chiave alternativa in questa tabella è definita dalla combinazione di client_id , person_id e client_relation_type_id .
Area tematica n. 4:Offerte
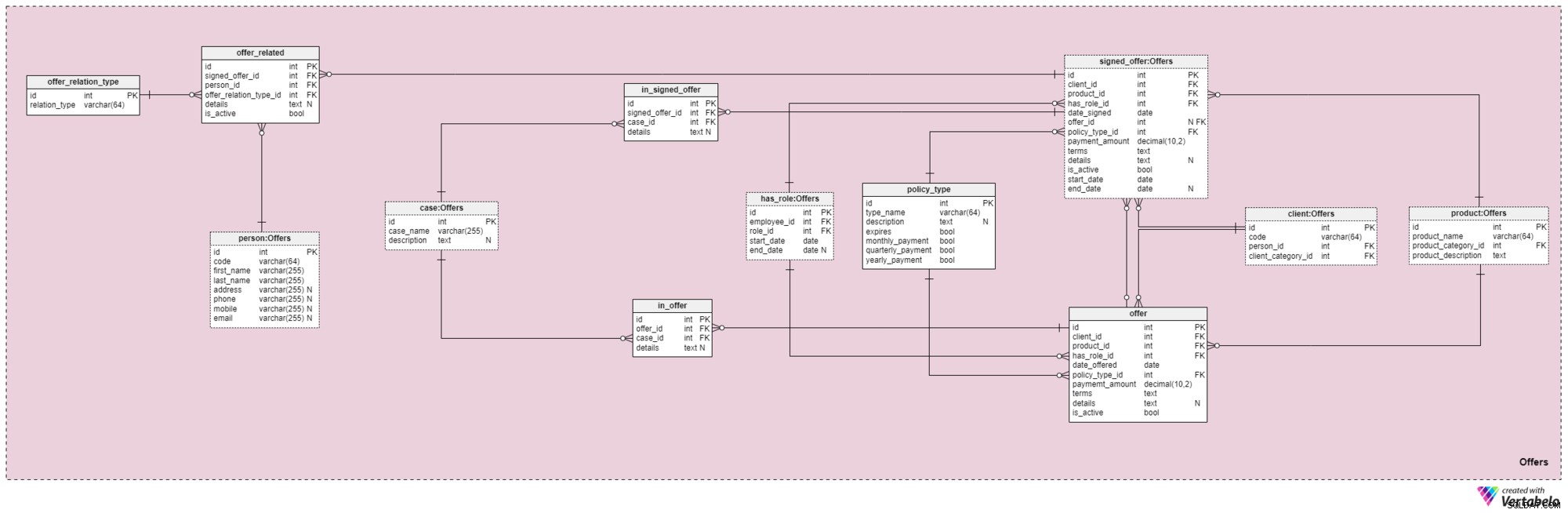
Questa area tematica e quella che segue sono al centro di questo modello di dati. Coprono le offerte e le polizze firmate, nonché i pagamenti relativi alle offerte. In primo luogo, descriveremo l'area tematica Offerte. Può sembrare complesso perché contiene 12 tabelle. Tuttavia, quattro di questi 12 (has_role , product , client e person ) sono stati descritti nelle aree tematiche precedenti, quindi non ripeteremo la nostra discussione qui.
L'offer e signed_offer le tabelle hanno strutture simili perché verranno utilizzate per memorizzare dati molto simili nel nostro modello. Tuttavia, mentre offer verrà utilizzato principalmente per memorizzare tutte le politiche (e i relativi dettagli) che abbiamo offerto ai nostri clienti, il signed_offer la tabella verrà utilizzata rigorosamente per memorizzare informazioni sui clienti che hanno effettivamente firmato le politiche con la nostra azienda. Tratteremo queste tabelle insieme, notando eventuali differenze dove appaiono. Gli attributi in queste due tabelle sono i seguenti:
client_id— riferimento all'identificativo univoco del cliente che ha firmato una particolare offerta.product_id— riferimento all'identificatore univoco del prodotto incluso nell'offerta firmata.has_role_id— riferimento all'identificativo del dipendente e al ruolo ricoperto al momento della presentazione/firma dell'offerta.date_offerededate_signed— date effettive che indicano rispettivamente quando questa offerta è stata presentata al cliente e quando è stata firmata.offer_id— un riferimento all'offerta precedente per questo cliente. Questo può contenere un valore nullo perché il cliente potrebbe aver firmato una polizza senza avere alcuna offerta precedente da parte dell'azienda, come se si fosse rivolto a noi da solo. Questo attributo appartiene strettamente asigned_offertabella.policy_type_id— riferimento al dizionario del tipo di polizza che denota il tipo di polizza che abbiamo offerto al cliente o che abbiamo fatto firmare.payment_amount— l'importo che il cliente deve pagare regolarmente per la polizza.terms— tutti i termini dell'accordo, in formato testuale (XML). L'idea è di memorizzare tutti i dettagli importanti riguardanti la parte finanziaria della polizza in questo attributo. Esempi di testo che potremmo memorizzare sono l'importo totale della polizza, il numero di pagamenti che il cliente deve effettuare e così via.details— eventuali dettagli aggiuntivi, in formato testuale.is_active— flag che indica se il record è ancora attivo.start_dateeend_date— indicare l'intervallo di tempo in cui questa politica è/era attiva. Se la norma è stata firmata per tutta la vita, end_date conterrà un valore null.
C'è anche il policy_type dizionario che abbiamo brevemente accennato prima. Abbiamo bisogno di un certo grado di flessibilità nel modo in cui offriamo lo stesso prodotto a clienti diversi, in base a fattori quali età, salute, stato civile, rischio di credito e così via. Per ogni tipo di policy, memorizzeremo un type_name identificatore, una description testuale aggiuntiva , un contrassegno denominato scade a indicare se la polizza può scadere e un altro contrassegno che indica se i premi di questo tipo di polizza devono essere pagati mensilmente, trimestralmente o annualmente. Alcuni tipi di polizza previsti sono:Vita a termine, Vita intera, Vita universale, Vita universale garantita, Vita variabile, Vita universale variabile e Assicurazione sulla vita dopo il pensionamento.
Andando avanti, ora dobbiamo definire tutti i casi e le situazioni che una particolare polizza può coprire. Dobbiamo mettere in relazione questi casi con offerte specifiche e offerte firmate.
L'elenco di tutti i possibili casi coperti dalle nostre polizze è archiviato nel case dizionario. Ciascun record in questa tabella può essere identificato in modo univoco dal suo case_name e ha una description aggiuntiva , se necessario.
Il in_offer e in_signed_offer le tabelle condividono la stessa struttura perché memorizzano gli stessi dati. L'unica differenza tra i due è che il primo memorizza i casi coperti nella polizza che è stata semplicemente offerta al cliente, mentre il secondo memorizza i casi nella polizza firmata dal cliente. Per ogni record in queste due tabelle, memorizzeremo la coppia univoca di offer_id /signed_offer_id e case_id , l'ultimo dei quali denota il caso o l'incidente coperto dalla polizza. Tutti gli altri dettagli verranno memorizzati in un attributo testuale, se necessario.
Come accennato in precedenza, le polizze assicurative sulla vita sono quasi sempre legate non solo ai clienti ma anche ai loro familiari o parenti. Dobbiamo immagazzinare queste relazioni anche in quest'area. Saranno definiti al momento della sottoscrizione di una polizza, ma potrebbero anche essere modificati per tutta la durata della polizza.
La prima cosa che dobbiamo fare è creare un dizionario contenente tutti i possibili valori che possono essere assegnati a una relazione. Nel nostro modello, questo è il offer_relation_type dizionario. A parte la chiave primaria, questa tabella contiene solo un attributo:il relation_type – che può contenere solo valori univoci.
Ci siamo quasi! L'ultima tabella in questa area tematica è intitolata offer_related . Riferisce un'offerta firmata a chiunque sia imparentato con il cliente. Pertanto, dovremo memorizzare i riferimenti alla politica firmata (signed_offer_id ) e la persona correlata (person_id ) e specificare anche la natura di tale relazione (offer_relation_type_id ). Inoltre, dovremo memorizzare details relativo a questo record e creare un flag per verificare se è ancora valido nel nostro sistema.
Area tematica n. 5:Pagamenti
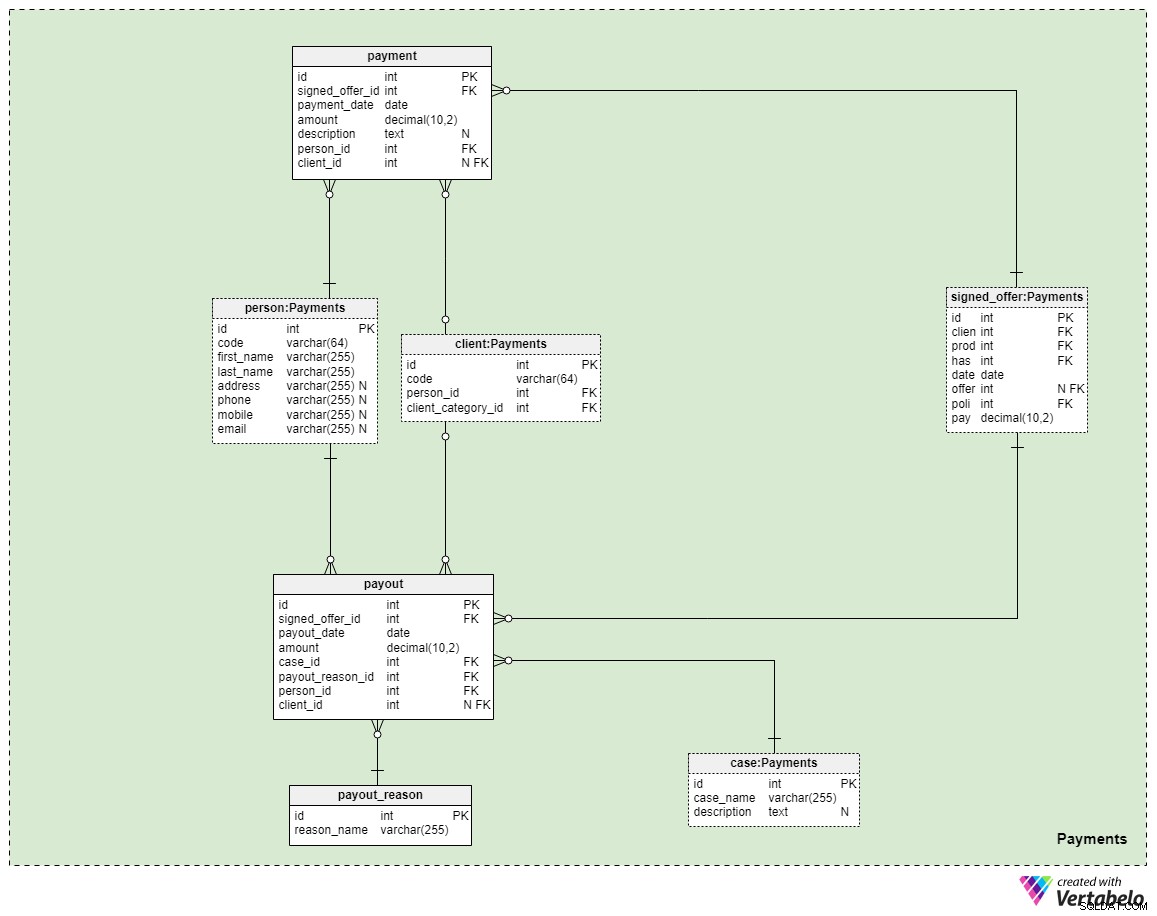
L'ultima area tematica del nostro modello riguarda i pagamenti. Qui stiamo introducendo solo tre nuove tabelle:payment , payout_reason e payment .
Tutti i pagamenti relativi alle politiche sono memorizzati nel payment tavolo. Abbiamo incluso solo gli attributi più importanti qui:
signed_offer_id— riferimento all'identificativo univoco dell'offerta firmata (polizza).payment_date— la data in cui è stato effettuato il pagamento.amount— l'importo effettivo pagato.description— una descrizione facoltativa del pagamento, in formato testuale.person_id— riferimento all'identificativo univoco della persona che ha effettuato il pagamento. Si noti che il cliente che ha firmato l'offerta non è necessariamente l'unica persona che può effettuare un pagamento.client_id— riferimento all'identificativo univoco del cliente che ha effettuato il pagamento. Questo attributo conterrà un valore solo se il cliente stesso ha effettuato il pagamento.
Le restanti due tabelle rappresentano forse il motivo più importante per cui paghiamo l'assicurazione sulla vita:nel caso in cui dovesse succederci qualcosa, i pagamenti verranno effettuati ai nostri familiari o ai nostri partner commerciali o di vita. Il modo in cui ciò accade dipende tutto dalla tua situazione e dai termini della polizza specifica che hai firmato. Useremo due semplici tabelle per coprire questi casi.
Il primo è un dizionario intitolato payout_reason e presenta una classica struttura a dizionario. A parte l'attributo della chiave primaria, abbiamo un solo attributo:il reason_name – che memorizzerà un elenco di valori univoci che indicano il motivo per cui è stato effettuato questo pagamento.
L'ultima tabella nel modello è il payment tavolo. È molto simile al payment tabella, ma le differenze più importanti sono riportate di seguito:
payment_date— la data in cui è stato effettuato il pagamento.case_id— riferimento all'identificativo univoco del caso o dell'incidente correlato che ha attivato il pagamento. Deve corrispondere a uno degli ID inclusi nella norma.payout_reason_id— rimando al dizionario che descrive più dettagliatamente il motivo del pagamento. Sebbene il caso di pagamento sia più breve e più generale, il motivo del pagamento offrirà dettagli più specifici su ciò che è accaduto.person_ideclient_id— fa riferimento rispettivamente alla persona e al cliente in relazione al pagamento.
Riepilogo
Eccezionale! Abbiamo costruito con successo il nostro modello di dati di assicurazione sulla vita. Prima di concludere la nostra discussione, vale la pena notare che c'è molto di più che può essere coperto in questo modello. In questo articolo, abbiamo principalmente voluto coprire le basi del modello per darti un'idea di come appare e funziona. Ecco alcuni dettagli in più che si potrebbero incorporare in un tale modello di dati:
- Gli aggiornamenti aggiuntivi delle polizze non sono coperti dal nostro modello attuale (ad esempio, se desideri fare offerte annuali per le polizze esistenti, non potrai farlo con questa struttura). Dovremmo aggiungere qualche altra tabella per memorizzare tutte le modifiche alle norme per le offerte presentate/firmate.
- Tutti i documenti sono stati omessi intenzionalmente. Naturalmente, ci saranno molte scartoffie associate a una particolare polizza di assicurazione sulla vita, in particolare per il processo di firma e i pagamenti. Potremmo allegare documenti che descrivono lo stato del cliente al momento della firma della polizza ed eventuali modifiche lungo il percorso, nonché eventuali documenti relativi ai pagamenti.
- Questo modello non incorpora la struttura necessaria per il calcolo del rischio delle polizze. Dovremmo avere tutti i parametri di cui abbiamo bisogno per testare e tutti gli intervalli che determinano in che modo il valore di un cliente influisce sul calcolo generale. I risultati di questi calcoli dovrebbero essere archiviati per ogni offerta e polizza firmata.
- La struttura della fattura in realtà è molto più complessa di quella trattata nell'area tematica dei pagamenti. Non abbiamo nemmeno menzionato i conti finanziari da nessuna parte nel nostro modello.
Chiaramente, il settore assicurativo è piuttosto complesso. In questo articolo abbiamo discusso solo di un modello di dati per l'assicurazione sulla vita:puoi immaginare come si evolverebbe questo modello di dati se dovessimo gestire una società che offre una serie di diversi tipi di assicurazione? Ci vorrebbe sicuramente molta pianificazione e riflessione per presentare un modello di dati organizzato per un'azienda del genere.
Se hai suggerimenti o idee per migliorare il nostro modello di dati, non esitare a farcelo sapere nei commenti qui sotto!