Introduzione
Indipendentemente dalla tecnologia del database, è necessario disporre di un'impostazione di monitoraggio, sia per rilevare problemi e agire, sia semplicemente per conoscere lo stato attuale dei nostri sistemi.
A tale scopo ci sono diversi strumenti, a pagamento e gratuiti. In questo blog ci concentreremo su uno in particolare:Nagios Core.
Cos'è Nagios Core?
Nagios Core è un sistema Open Source per il monitoraggio di host, reti e servizi. Consente di configurare gli avvisi e ha diversi stati per loro. Consente l'implementazione di plug-in, sviluppati dalla community, o addirittura ci consente di configurare i nostri script di monitoraggio.
Come installare Nagios?
La documentazione ufficiale ci mostra come installare Nagios Core su sistemi CentOS o Ubuntu.
Vediamo un esempio dei passaggi necessari per l'installazione su CentOS 7.
Pacchetti richiesti
[example@sqldat.com ~]# yum install -y wget httpd php gcc glibc glibc-common gd gd-devel make net-snmp unzipScarica Nagios Core, Nagios Plugin e NRPE
[example@sqldat.com ~]# wget https://assets.nagios.com/downloads/nagioscore/releases/nagios-4.4.2.tar.gz
[example@sqldat.com ~]# wget https://nagios-plugins.org/download/nagios-plugins-2.2.1.tar.gz
[example@sqldat.com ~]# wget https://github.com/NagiosEnterprises/nrpe/releases/download/nrpe-3.2.1/nrpe-3.2.1.tar.gzAggiungi utente e gruppo Nagios
[example@sqldat.com ~]# useradd nagios
[example@sqldat.com ~]# groupadd nagcmd
[example@sqldat.com ~]# usermod -a -G nagcmd nagios
[example@sqldat.com ~]# usermod -a -G nagios,nagcmd apacheInstallazione di Nagios
[example@sqldat.com ~]# tar zxvf nagios-4.4.2.tar.gz
[example@sqldat.com ~]# cd nagios-4.4.2
[example@sqldat.com nagios-4.4.2]# ./configure --with-command-group=nagcmd
[example@sqldat.com nagios-4.4.2]# make all
[example@sqldat.com nagios-4.4.2]# make install
[example@sqldat.com nagios-4.4.2]# make install-init
[example@sqldat.com nagios-4.4.2]# make install-config
[example@sqldat.com nagios-4.4.2]# make install-commandmode
[example@sqldat.com nagios-4.4.2]# make install-webconf
[example@sqldat.com nagios-4.4.2]# cp -R contrib/eventhandlers/ /usr/local/nagios/libexec/
[example@sqldat.com nagios-4.4.2]# chown -R nagios:nagios /usr/local/nagios/libexec/eventhandlers
[example@sqldat.com nagios-4.4.2]# /usr/local/nagios/bin/nagios -v /usr/local/nagios/etc/nagios.cfgInstallazione del plug-in Nagios e NRPE
[example@sqldat.com ~]# tar zxvf nagios-plugins-2.2.1.tar.gz
[example@sqldat.com ~]# cd nagios-plugins-2.2.1
[example@sqldat.com nagios-plugins-2.2.1]# ./configure --with-nagios-user=nagios --with-nagios-group=nagios
[example@sqldat.com nagios-plugins-2.2.1]# make
[example@sqldat.com nagios-plugins-2.2.1]# make install
[example@sqldat.com ~]# yum install epel-release
[example@sqldat.com ~]# yum install nagios-plugins-nrpe
[example@sqldat.com ~]# tar zxvf nrpe-3.2.1.tar.gz
[example@sqldat.com ~]# cd nrpe-3.2.1
[example@sqldat.com nrpe-3.2.1]# ./configure --disable-ssl --enable-command-args
[example@sqldat.com nrpe-3.2.1]# make all
[example@sqldat.com nrpe-3.2.1]# make install-pluginAggiungiamo la seguente riga alla fine del nostro file /usr/local/nagios/etc/objects/command.cfg per utilizzare NRPE durante il controllo dei nostri server:
define command{
command_name check_nrpe
command_line /usr/local/nagios/libexec/check_nrpe -H $HOSTADDRESS$ -c $ARG1$
}Nagios inizia
[example@sqldat.com nagios-4.4.2]# systemctl start nagios
[example@sqldat.com nagios-4.4.2]# systemctl start httpdAccesso al Web
Creiamo l'utente per accedere all'interfaccia web e possiamo entrare nel sito.
[example@sqldat.com nagios-4.4.2]# htpasswd -c /usr/local/nagios/etc/htpasswd.users nagiosadminhttps://Indirizzo_IP/nagios/
 Nagios Web Access
Nagios Web Access Come configurare Nagios?
Ora che abbiamo installato i nostri Nagios, possiamo continuare con la configurazione. Per questo dobbiamo andare nella posizione corrispondente alla nostra installazione, nel nostro esempio /usr/local/nagios/etc.
Ci sono diversi file di configurazione che dovrai creare o modificare prima di iniziare a monitorare qualsiasi cosa.
[example@sqldat.com etc]# ls /usr/local/nagios/etc
cgi.cfg htpasswd.users nagios.cfg objects resource.cfg- cgi.cfg: Il file di configurazione CGI contiene una serie di direttive che influiscono sul funzionamento dei CGI. Contiene anche un riferimento al file di configurazione principale, in modo che i CGI sappiano come hai configurato Nagios e dove sono archiviate le definizioni dei tuoi oggetti.
- htpasswd.users: Questo file contiene gli utenti creati per accedere all'interfaccia web di Nagios.
- nagios.cfg: Il file di configurazione principale contiene una serie di direttive che influenzano il funzionamento del demone Nagios Core.
- oggetti: Quando installi Nagios, qui vengono inseriti diversi file di configurazione degli oggetti di esempio. È possibile utilizzare questi file di esempio per vedere come funziona l'ereditarietà degli oggetti e imparare a definire le proprie definizioni di oggetti. Gli oggetti sono tutti gli elementi coinvolti nella logica di monitoraggio e notifica.
- risorsa.cfg: Viene utilizzato per specificare un file di risorse facoltativo che può contenere definizioni di macro. Le macro ti consentono di fare riferimento alle informazioni di host, servizi e altre fonti nei tuoi comandi.
All'interno degli oggetti, possiamo trovare modelli, che possono essere utilizzati durante la creazione di nuovi oggetti. Ad esempio, possiamo vedere che nel nostro file /usr/local/nagios/etc/objects/templates.cfg è presente un modello chiamato linux-server, che verrà utilizzato per aggiungere i nostri server.
define host {
name linux-server ; The name of this host template
use generic-host ; This template inherits other values from the generic-host template
check_period 24x7 ; By default, Linux hosts are checked round the clock
check_interval 5 ; Actively check the host every 5 minutes
retry_interval 1 ; Schedule host check retries at 1 minute intervals
max_check_attempts 10 ; Check each Linux host 10 times (max)
check_command check-host-alive ; Default command to check Linux hosts
notification_period workhours ; Linux admins hate to be woken up, so we only notify during the day
; Note that the notification_period variable is being overridden from
; the value that is inherited from the generic-host template!
notification_interval 120 ; Resend notifications every 2 hours
notification_options d,u,r ; Only send notifications for specific host states
contact_groups admins ; Notifications get sent to the admins by default
register 0 ; DON'T REGISTER THIS DEFINITION - ITS NOT A REAL HOST, JUST A TEMPLATE!
}Utilizzando questo modello, i nostri host erediteranno la configurazione senza doverli specificare uno per uno su ogni server che aggiungiamo.
Abbiamo anche comandi, contatti e periodi di tempo predefiniti.
I comandi verranno utilizzati da Nagios per i suoi controlli, ed è ciò che aggiungiamo all'interno del file di configurazione di ogni server per monitorarlo. Ad esempio, PING:
define command {
command_name check_ping
command_line $USER1$/check_ping -H $HOSTADDRESS$ -w $ARG1$ -c $ARG2$ -p 5
}Abbiamo la possibilità di creare contatti o gruppi e specificare quali avvisi voglio raggiungere a quale persona o gruppo.
define contact {
contact_name nagiosadmin ; Short name of user
use generic-contact ; Inherit default values from generic-contact template (defined above)
alias Nagios Admin ; Full name of user
email example@sqldat.com ; <<***** CHANGE THIS TO YOUR EMAIL ADDRESS ******
}Per i nostri controlli e avvisi, possiamo configurare in quali ore e giorni vogliamo riceverli. Se abbiamo un servizio non critico, probabilmente non vogliamo svegliarci all'alba, quindi sarebbe bene avvisare solo in orario di lavoro per evitare che ciò accada.
define timeperiod {
name workhours
timeperiod_name workhours
alias Normal Work Hours
monday 09:00-17:00
tuesday 09:00-17:00
wednesday 09:00-17:00
thursday 09:00-17:00
friday 09:00-17:00
}Vediamo ora come aggiungere avvisi ai nostri Nagios.
Monitoreremo i nostri server PostgreSQL, quindi prima li aggiungiamo come host nella nostra directory degli oggetti. Creeremo 3 nuovi file:
[example@sqldat.com ~]# cd /usr/local/nagios/etc/objects/
[example@sqldat.com objects]# vi postgres1.cfg
define host {
use linux-server ; Name of host template to use
host_name postgres1 ; Hostname
alias PostgreSQL1 ; Alias
address 192.168.100.123 ; IP Address
}
[example@sqldat.com objects]# vi postgres2.cfg
define host {
use linux-server ; Name of host template to use
host_name postgres2 ; Hostname
alias PostgreSQL2 ; Alias
address 192.168.100.124 ; IP Address
}
[example@sqldat.com objects]# vi postgres3.cfg
define host {
use linux-server ; Name of host template to use
host_name postgres3 ; Hostname
alias PostgreSQL3 ; Alias
address 192.168.100.125 ; IP Address
}Quindi dobbiamo aggiungerli al file nagios.cfg e qui abbiamo 2 opzioni.
Aggiungi i nostri host (file cfg) uno per uno usando la variabile cfg_file (opzione predefinita) o aggiungi tutti i file cfg che abbiamo all'interno di una directory usando la variabile cfg_dir.
Aggiungeremo i file uno per uno seguendo la strategia predefinita.
cfg_file=/usr/local/nagios/etc/objects/postgres1.cfg
cfg_file=/usr/local/nagios/etc/objects/postgres2.cfg
cfg_file=/usr/local/nagios/etc/objects/postgres3.cfgCon questo monitoriamo i nostri host. Ora non ci resta che aggiungere quali servizi vogliamo monitorare. Per questo utilizzeremo alcuni controlli già definiti (check_ssh e check_ping) e aggiungeremo alcuni controlli di base del sistema operativo come il carico e lo spazio su disco, tra gli altri, utilizzando NRPE.
Scarica il whitepaper oggi Gestione e automazione di PostgreSQL con ClusterControlScopri cosa devi sapere per distribuire, monitorare, gestire e ridimensionare PostgreSQLScarica il whitepaperCos'è NRPE?
Nagios Remote Plugin Executor. Questo strumento ci consente di eseguire i plug-in Nagios su un host remoto nel modo più trasparente possibile.
Per utilizzarlo, dobbiamo installare il server in ogni nodo che vogliamo monitorare e i nostri Nagios si collegheranno come client a ciascuno di essi, eseguendo i plug-in corrispondenti.
Come si installa NRPE?
[example@sqldat.com ~]# wget https://github.com/NagiosEnterprises/nrpe/releases/download/nrpe-3.2.1/nrpe-3.2.1.tar.gz
[example@sqldat.com ~]# wget https://nagios-plugins.org/download/nagios-plugins-2.2.1.tar.gz
[example@sqldat.com ~]# tar zxvf nagios-plugins-2.2.1.tar.gz
[example@sqldat.com ~]# tar zxvf nrpe-3.2.1.tar.gz
[example@sqldat.com ~]# cd nrpe-3.2.1
[example@sqldat.com nrpe-3.2.1]# ./configure --disable-ssl --enable-command-args
[example@sqldat.com nrpe-3.2.1]# make all
[example@sqldat.com nrpe-3.2.1]# make install-groups-users
[example@sqldat.com nrpe-3.2.1]# make install
[example@sqldat.com nrpe-3.2.1]# make install-config
[example@sqldat.com nrpe-3.2.1]# make install-init
[example@sqldat.com ~]# cd nagios-plugins-2.2.1
[example@sqldat.com nagios-plugins-2.2.1]# ./configure --with-nagios-user=nagios --with-nagios-group=nagios
[example@sqldat.com nagios-plugins-2.2.1]# make
[example@sqldat.com nagios-plugins-2.2.1]# make install
[example@sqldat.com nagios-plugins-2.2.1]# systemctl enable nrpeQuindi modifichiamo il file di configurazione /usr/local/nagios/etc/nrpe.cfg
server_address=<Local IP Address>
allowed_hosts=127.0.0.1,<Nagios Server IP Address>E riavviamo il servizio NRPE:
[example@sqldat.com ~]# systemctl restart nrpePossiamo testare la connessione eseguendo quanto segue dal nostro server Nagios:
[example@sqldat.com ~]# /usr/local/nagios/libexec/check_nrpe -H <Node IP Address>
NRPE v3.2.1Come monitorare PostgreSQL?
Durante il monitoraggio di PostgreSQL, ci sono due aree principali di cui tenere conto:sistema operativo e database.
Per il sistema operativo, NRPE ha alcuni controlli di base configurati come lo spazio su disco e il carico, tra gli altri. Questi controlli possono essere abilitati molto facilmente nel modo seguente.
Nei nostri nodi modifichiamo il file /usr/local/nagios/etc/nrpe.cfg e andiamo dove si trovano le seguenti righe:
command[check_users]=/usr/local/nagios/libexec/check_users -w 5 -c 10
command[check_load]=/usr/local/nagios/libexec/check_load -r -w 15,10,05 -c 30,25,20
command[check_disk]=/usr/local/nagios/libexec/check_disk -w 20% -c 10% -p /
command[check_zombie_procs]=/usr/local/nagios/libexec/check_procs -w 5 -c 10 -s Z
command[check_total_procs]=/usr/local/nagios/libexec/check_procs -w 150 -c 200I nomi tra parentesi quadre sono quelli che utilizzeremo nel nostro server Nagios per abilitare questi controlli.
Nei nostri Nagios, modifichiamo i file dei 3 nodi:
/usr/local/nagios/etc/objects/postgres1.cfg
/usr/local/nagios/etc/objects/postgres2.cfg
/usr/local/nagios/etc/objects/postgres3.cfgAggiungiamo questi controlli che abbiamo visto in precedenza, lasciando i nostri file come segue:
define host {
use linux-server
host_name postgres1
alias PostgreSQL1
address 192.168.100.123
}
define service {
use generic-service
host_name postgres1
service_description PING
check_command check_ping!100.0,20%!500.0,60%
}
define service {
use generic-service
host_name postgres1
service_description SSH
check_command check_ssh
}
define service {
use generic-service
host_name postgres1
service_description Root Partition
check_command check_nrpe!check_disk
}
define service {
use generic-service
host_name postgres1
service_description Total Processes zombie
check_command check_nrpe!check_zombie_procs
}
define service {
use generic-service
host_name postgres1
service_description Total Processes
check_command check_nrpe!check_total_procs
}
define service {
use generic-service
host_name postgres1
service_description Current Load
check_command check_nrpe!check_load
}
define service {
use generic-service
host_name postgres1
service_description Current Users
check_command check_nrpe!check_users
}E riavviamo il servizio nagios:
[example@sqldat.com ~]# systemctl start nagiosA questo punto, se andiamo nella sezione servizi nell'interfaccia web del nostro Nagios, dovremmo avere qualcosa di simile al seguente:
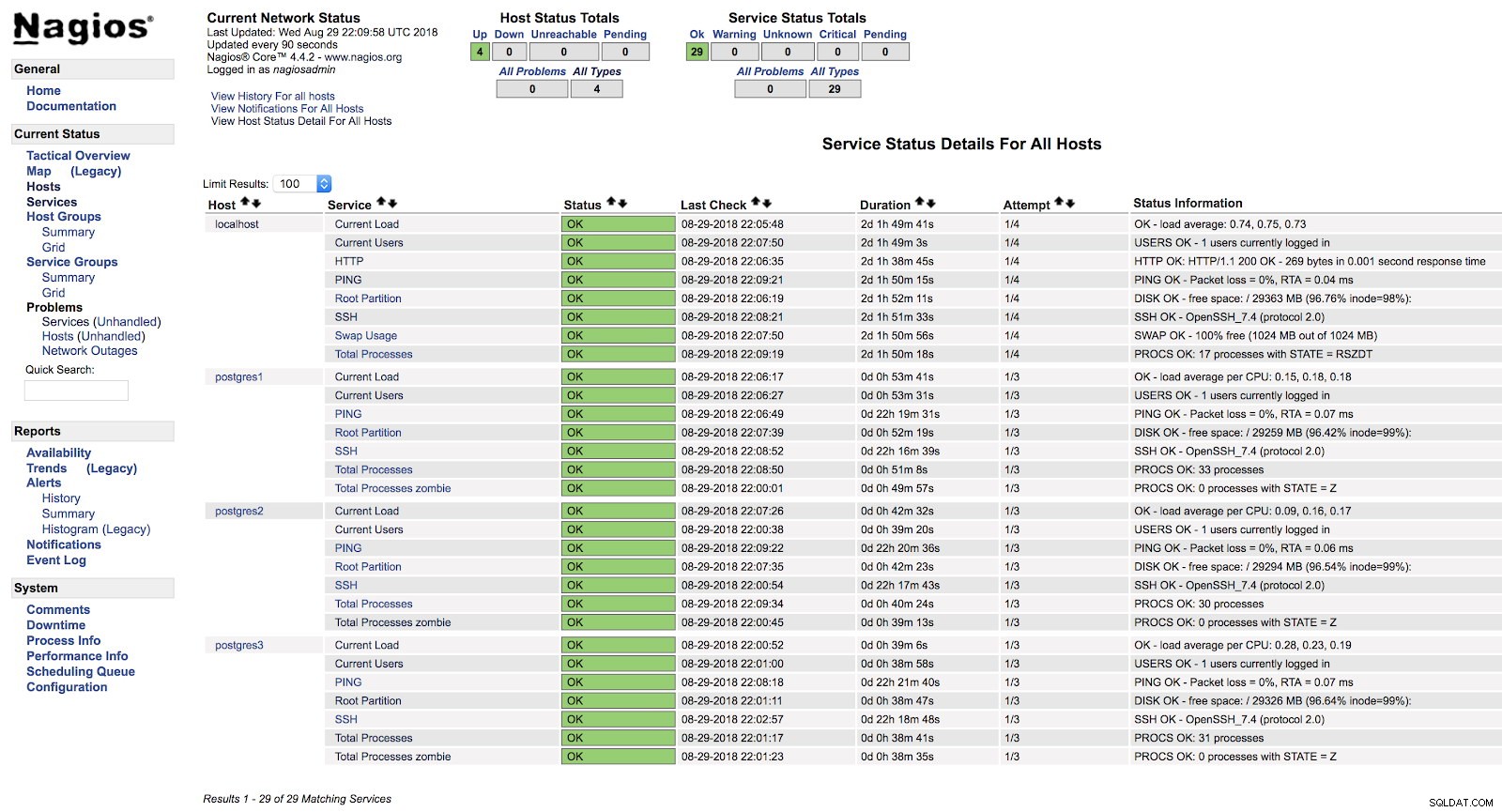 Avvisi host di Nagios
Avvisi host di Nagios In questo modo tratteremo i controlli di base del nostro server a livello di sistema operativo.
Abbiamo molti altri controlli che possiamo aggiungere e possiamo persino creare i nostri controlli (vedremo un esempio più avanti).
Ora vediamo come monitorare il nostro motore di database PostgreSQL utilizzando due dei principali plugin progettati per questo compito.
Check_postgres
Uno dei plugin più popolari per il controllo di PostgreSQL è check_postgres di Bucardo.
Vediamo come installarlo e come usarlo con il nostro database PostgreSQL.
Pacchetti richiesti
[example@sqldat.com ~]# yum install perl-develInstallazione
[example@sqldat.com ~]# wget https://bucardo.org/downloads/check_postgres.tar.gz
[example@sqldat.com ~]# tar zxvf check_postgres.tar.gz
[example@sqldat.com ~]# cp check_postgres-2.23.0/check_postgres.pl /usr/local/nagios/libexec/
[example@sqldat.com ~]# chown nagios.nagios /usr/local/nagios/libexec/check_postgres.pl
[example@sqldat.com ~]# cd /usr/local/nagios/libexec/
[example@sqldat.com libexec]# perl /usr/local/nagios/libexec/check_postgres.pl --symlinksQuest'ultimo comando crea i collegamenti per utilizzare tutte le funzioni di questo controllo, come check_postgres_connection, check_postgres_last_vacuum o check_postgres_replication_slots tra gli altri.
[example@sqldat.com libexec]# ls |grep postgres
check_postgres.pl
check_postgres_archive_ready
check_postgres_autovac_freeze
check_postgres_backends
check_postgres_bloat
check_postgres_checkpoint
check_postgres_cluster_id
check_postgres_commitratio
check_postgres_connection
check_postgres_custom_query
check_postgres_database_size
check_postgres_dbstats
check_postgres_disabled_triggers
check_postgres_disk_space
…Aggiungiamo nel nostro file di configurazione NRPE (/usr/local/nagios/etc/nrpe.cfg) la riga per eseguire il controllo che vogliamo utilizzare:
command[check_postgres_locks]=/usr/local/nagios/libexec/check_postgres_locks -w 2 -c 3
command[check_postgres_bloat]=/usr/local/nagios/libexec/check_postgres_bloat -w='100 M' -c='200 M'
command[check_postgres_connection]=/usr/local/nagios/libexec/check_postgres_connection --db=postgres
command[check_postgres_backends]=/usr/local/nagios/libexec/check_postgres_backends -w=70 -c=100Nel nostro esempio abbiamo aggiunto 4 controlli di base per PostgreSQL. Monitoreremo Lock, Bloat, Connection e Backend.
Nel file corrispondente al nostro database nel server Nagios (/usr/local/nagios/etc/objects/postgres1.cfg), aggiungiamo le seguenti voci:
define service {
use generic-service
host_name postgres1
service_description PostgreSQL locks
check_command check_nrpe!check_postgres_locks
}
define service {
use generic-service
host_name postgres1
service_description PostgreSQL Bloat
check_command check_nrpe!check_postgres_bloat
}
define service {
use generic-service
host_name postgres1
service_description PostgreSQL Connection
check_command check_nrpe!check_postgres_connection
}
define service {
use generic-service
host_name postgres1
service_description PostgreSQL Backends
check_command check_nrpe!check_postgres_backends
}E dopo aver riavviato entrambi i servizi (NRPE e Nagios) su entrambi i server, possiamo vedere i nostri avvisi configurati.
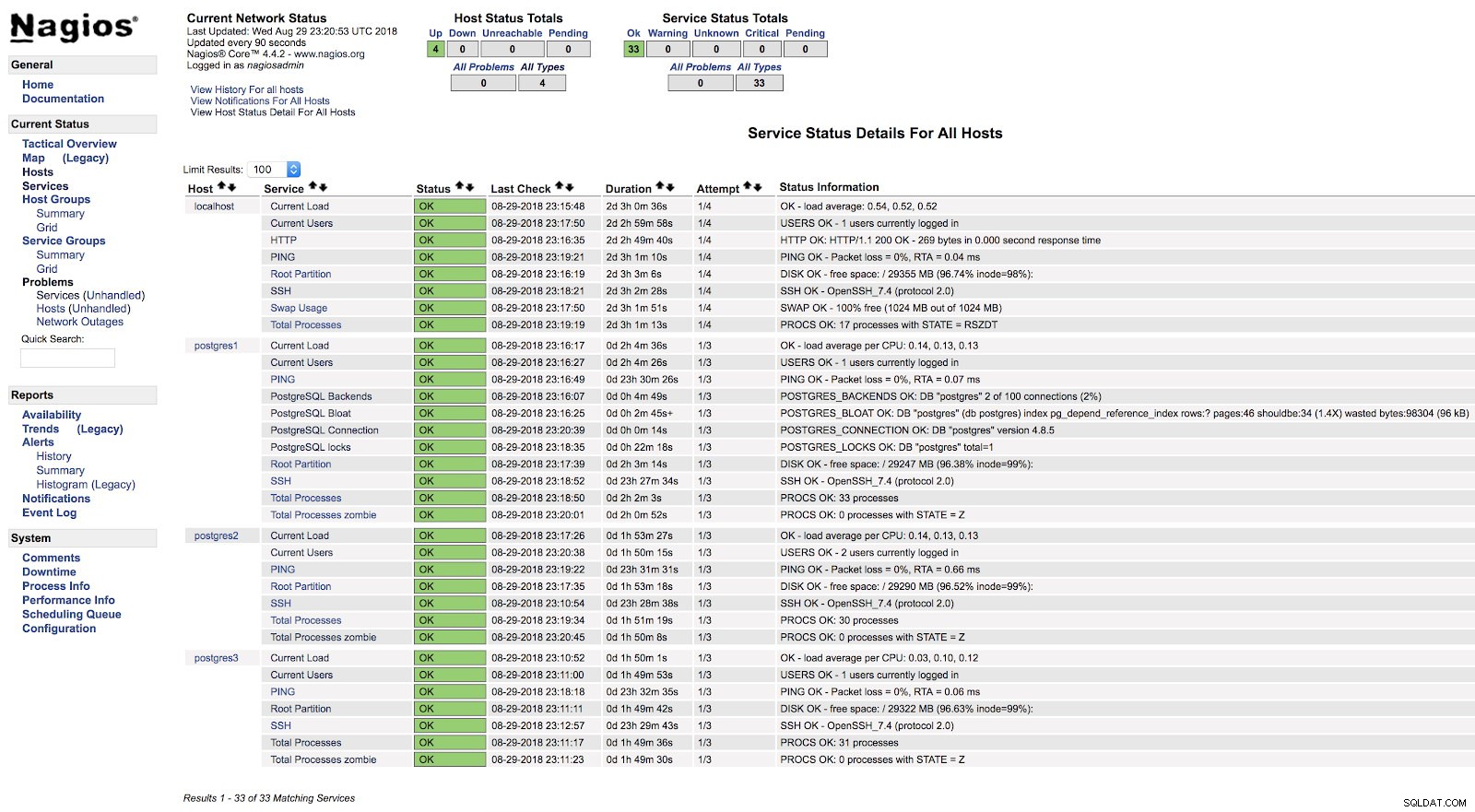 Nagios check_postgres Avvisi
Nagios check_postgres Avvisi Nella documentazione ufficiale del plug-in check_postgres, puoi trovare informazioni su cos'altro monitorare e come farlo.
Verifica_pgattività
Ora è il turno di check_pgactivity, popolare anche per il monitoraggio del nostro database PostgreSQL.
Installazione
[example@sqldat.com ~]# wget https://github.com/OPMDG/check_pgactivity/releases/download/REL2_3/check_pgactivity-2.3.tgz
[example@sqldat.com ~]# tar zxvf check_pgactivity-2.3.tgz
[example@sqldat.com ~]# cp check_pgactivity-2.3check_pgactivity /usr/local/nagios/libexec/check_pgactivity
[example@sqldat.com ~]# chown nagios.nagios /usr/local/nagios/libexec/check_pgactivityAggiungiamo nel nostro file di configurazione NRPE (/usr/local/nagios/etc/nrpe.cfg) la riga per eseguire il controllo che vogliamo utilizzare:
command[check_pgactivity_backends]=/usr/local/nagios/libexec/check_pgactivity -h localhost -s backends -w 70 -c 100
command[check_pgactivity_connection]=/usr/local/nagios/libexec/check_pgactivity -h localhost -s connection
command[check_pgactivity_indexes]=/usr/local/nagios/libexec/check_pgactivity -h localhost -s invalid_indexes
command[check_pgactivity_locks]=/usr/local/nagios/libexec/check_pgactivity -h localhost -s locks -w 5 -c 10Nel nostro esempio aggiungeremo 4 controlli di base per PostgreSQL. Monitoreremo backend, connessione, indici non validi e blocchi.
Nel file corrispondente al nostro database nel server Nagios (/usr/local/nagios/etc/objects/postgres2.cfg), aggiungiamo le seguenti voci:
define service {
use generic-service ; Name of service template to use
host_name postgres2
service_description PGActivity Backends
check_command check_nrpe!check_pgactivity_backends
}
define service {
use generic-service ; Name of service template to use
host_name postgres2
service_description PGActivity Connection
check_command check_nrpe!check_pgactivity_connection
}
define service {
use generic-service ; Name of service template to use
host_name postgres2
service_description PGActivity Indexes
check_command check_nrpe!check_pgactivity_indexes
}
define service {
use generic-service ; Name of service template to use
host_name postgres2
service_description PGActivity Locks
check_command check_nrpe!check_pgactivity_locks
}E dopo aver riavviato entrambi i servizi (NRPE e Nagios) su entrambi i server, possiamo vedere i nostri avvisi configurati.
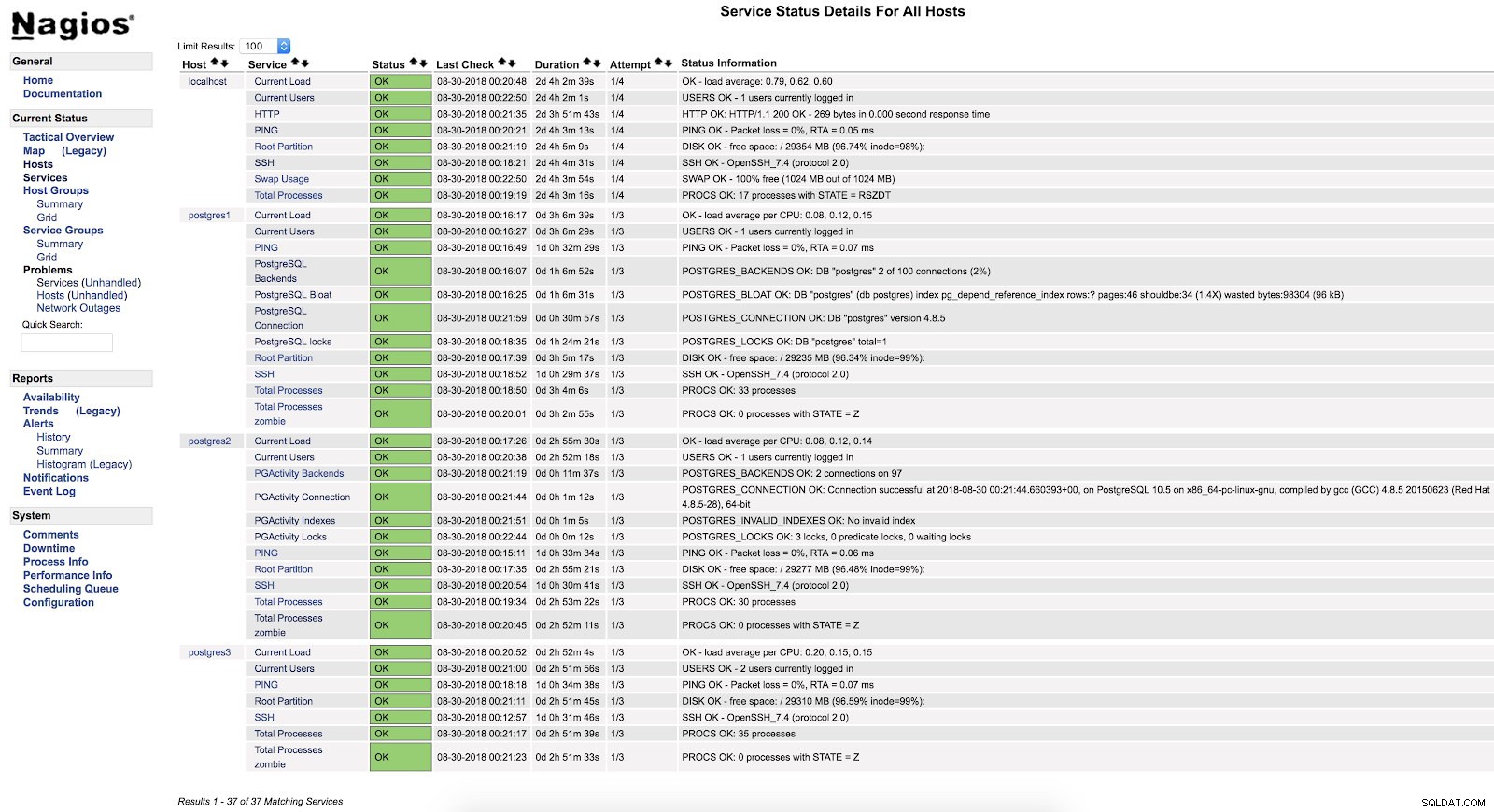 Nagios check_pgactivity Avvisi
Nagios check_pgactivity Avvisi Controlla registro errori
Uno dei controlli più importanti, o il più importante, è controllare il nostro registro degli errori.
Qui possiamo trovare diversi tipi di errori come FATAL o deadlock, ed è un buon punto di partenza per analizzare qualsiasi problema che abbiamo nel nostro database.
Per controllare il nostro registro degli errori, creeremo il nostro script di monitoraggio e lo integreremo nei nostri Nagios (questo è solo un esempio, questo script sarà di base e avrà molto margine di miglioramento).
Sceneggiatura
Creeremo il file /usr/local/nagios/libexec/check_postgres_log.sh sul nostro server PostgreSQL3.
[example@sqldat.com ~]# vi /usr/local/nagios/libexec/check_postgres_log.sh
#!/bin/bash
#Variables
LOG="/var/log/postgresql-$(date +%a).log"
CURRENT_DATE=$(date +'%Y-%m-%d %H')
ERROR=$(grep "$CURRENT_DATE" $LOG | grep "FATAL" | wc -l)
#States
STATE_CRITICAL=2
STATE_OK=0
#Check
if [ $ERROR -ne 0 ]; then
echo "CRITICAL - Check PostgreSQL Log File - $ERROR Error Found"
exit $STATE_CRITICAL
else
echo "OK - PostgreSQL without errors"
exit $STATE_OK
fiL'importante dello script è creare correttamente gli output corrispondenti a ciascuno stato. Queste uscite vengono lette da Nagios e ogni numero corrisponde a uno stato:
0=OK
1=WARNING
2=CRITICAL
3=UNKNOWNNel nostro esempio utilizzeremo solo 2 stati, OK e CRITICO, poiché ci interessa solo sapere se ci sono errori di tipo FATAL nel nostro registro errori nell'ora corrente.
Il testo che utilizziamo prima della nostra uscita verrà mostrato dall'interfaccia web del nostro Nagios, quindi dovrebbe essere il più chiaro possibile usarlo come guida al problema.
Una volta terminato il nostro script di monitoraggio, procederemo a dargli i permessi di esecuzione, ad assegnarlo all'utente nagios e ad aggiungerlo al nostro server di database NRPE così come ai nostri Nagios:
[example@sqldat.com ~]# chmod +x /usr/local/nagios/libexec/check_postgres_log.sh
[example@sqldat.com ~]# chown nagios.nagios /usr/local/nagios/libexec/check_postgres_log.sh
[example@sqldat.com ~]# vi /usr/local/nagios/etc/nrpe.cfg
command[check_postgres_log]=/usr/local/nagios/libexec/check_postgres_log.sh
[example@sqldat.com ~]# vi /usr/local/nagios/etc/objects/postgres3.cfg
define service {
use generic-service ; Name of service template to use
host_name postgres3
service_description PostgreSQL LOG
check_command check_nrpe!check_postgres_log
}Riavvia NRPE e Nagios. Quindi possiamo vedere il nostro controllo nell'interfaccia di Nagios:
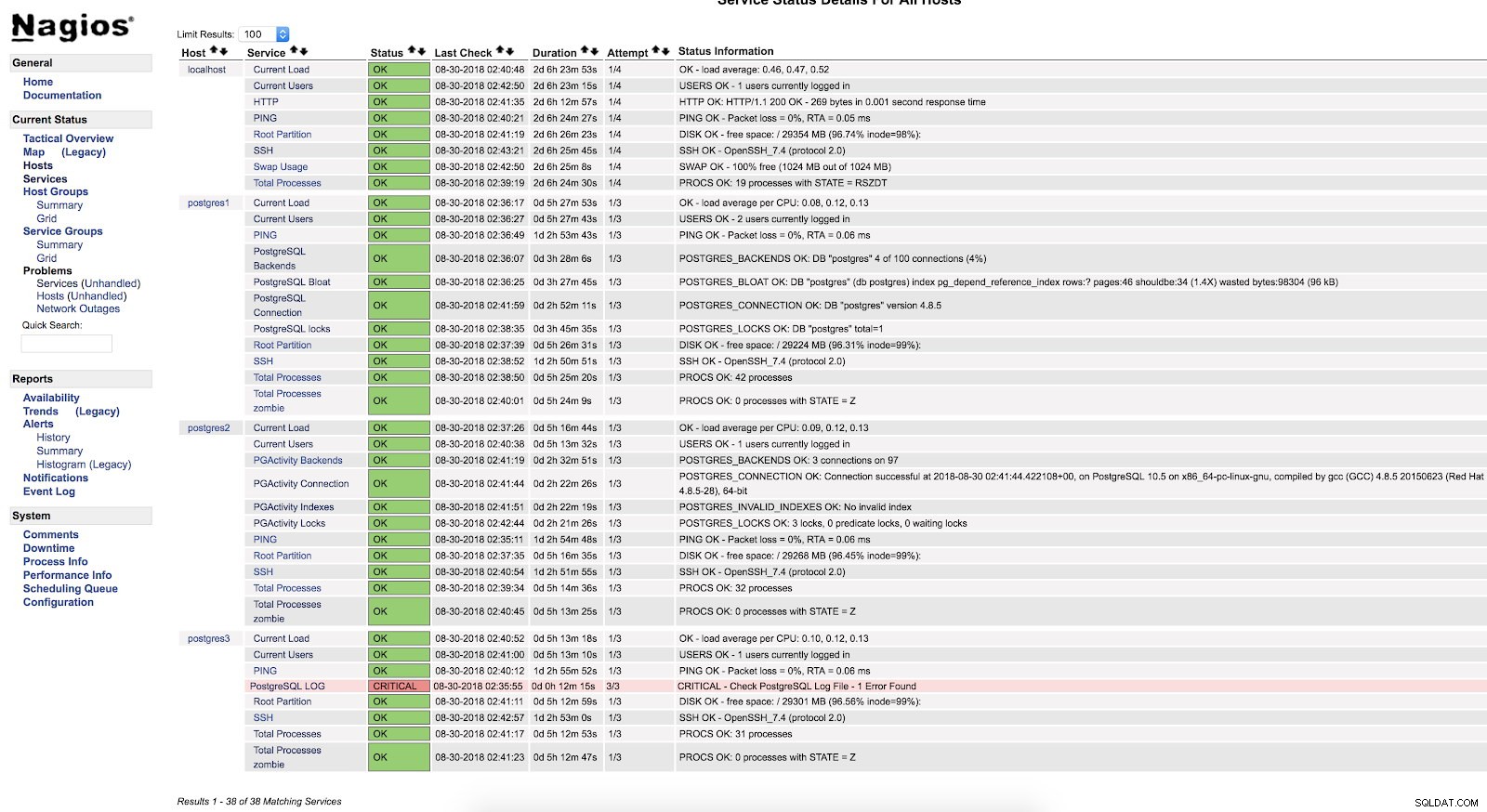 Avvisi script Nagios
Avvisi script Nagios Come possiamo vedere è in uno stato CRITICO, quindi se andiamo al log, possiamo vedere quanto segue:
2018-08-30 02:29:49.531 UTC [22162] FATAL: Peer authentication failed for user "postgres"
2018-08-30 02:29:49.531 UTC [22162] DETAIL: Connection matched pg_hba.conf line 83: "local all all peer"Per ulteriori informazioni su ciò che possiamo monitorare nel nostro database PostgreSQL, ti consiglio di controllare i nostri blog sulle prestazioni e sul monitoraggio o questo webinar sulle prestazioni di Postgres.
Sicurezza e prestazioni
Quando configuriamo qualsiasi monitoraggio, utilizzando i plug-in o il nostro script, dobbiamo prestare molta attenzione a 2 cose molto importanti:sicurezza e prestazioni.
Quando assegniamo le autorizzazioni necessarie per il monitoraggio, dobbiamo essere il più restrittivi possibile, limitando l'accesso solo localmente o dal nostro server di monitoraggio, utilizzando chiavi sicure, crittografando il traffico, consentendo la connessione al minimo necessario per il funzionamento del monitoraggio.
Per quanto riguarda le prestazioni, il monitoraggio è necessario, ma è anche necessario utilizzarlo in sicurezza per i nostri sistemi.
Dobbiamo fare attenzione a non generare accessi al disco irragionevolmente elevati o eseguire query che influiscono negativamente sulle prestazioni del nostro database.
Se abbiamo molte transazioni al secondo che generano gigabyte di log e continuiamo a cercare continuamente errori, probabilmente non è il massimo per il nostro database. Quindi dobbiamo mantenere un equilibrio tra ciò che monitoriamo, la frequenza e l'impatto sulle prestazioni.
Conclusione
Esistono diversi modi per implementare il monitoraggio o per configurarlo. Possiamo arrivare a farlo nel modo più complesso o semplice che vogliamo. L'obiettivo di questo blog era di introdurti al monitoraggio di PostgreSQL utilizzando uno degli strumenti open source più utilizzati. Abbiamo anche visto che la configurazione è molto flessibile e può essere adattata alle diverse esigenze.
E non dimenticare che possiamo sempre contare sulla community, quindi lascio alcuni link che potrebbero essere di grande aiuto.
Forum di supporto:https://support.nagios.com/forum/
Problemi noti:https://github.com/NagiosEnterprises/nagioscore/issues
Plugin Nagios:https://exchange.nagios.org/directory/Plugins
Plugin Nagios per ClusterControl:https://diversealnines.com/blog/nagios-plugin-clustercontrol