In un precedente articolo di questa serie, abbiamo creato un cluster PostgreSQL 12 a due nodi nel cloud AWS. Abbiamo anche installato e configurato 2ndQuadrant OmniDB in un terzo nodo. L'immagine sotto mostra l'architettura:
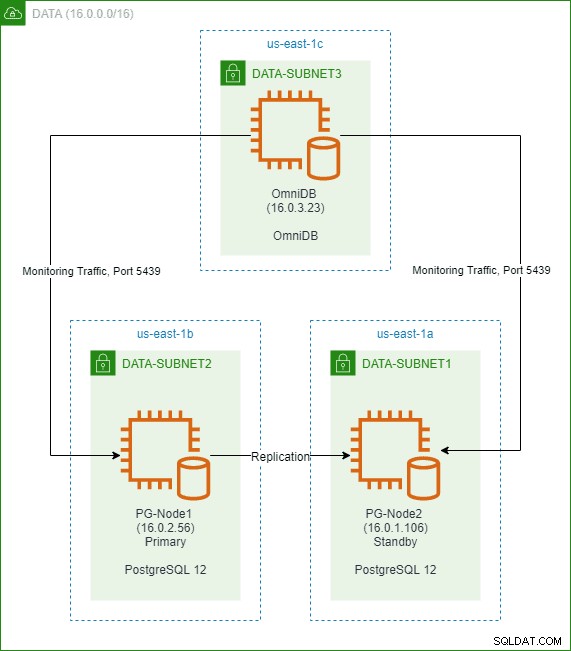
Potremmo connetterci sia al nodo primario che a quello di standby dall'interfaccia utente basata sul Web di OmniDB. Abbiamo quindi ripristinato un database di esempio chiamato "dvdrental" nel nodo primario che ha iniziato a replicarsi in standby.
In questa parte della serie impareremo come creare e utilizzare una dashboard di monitoraggio in OmniDB. I DBA e i team operativi spesso preferiscono strumenti grafici piuttosto che query complesse per ispezionare visivamente l'integrità del database. OmniDB viene fornito con una serie di importanti widget che possono essere facilmente utilizzati in una dashboard di monitoraggio. Come vedremo in seguito, consente anche agli utenti di scrivere i propri widget di monitoraggio.
Creazione di un dashboard per il monitoraggio delle prestazioni
Iniziamo con la dashboard predefinita con cui OmniDB viene fornito.
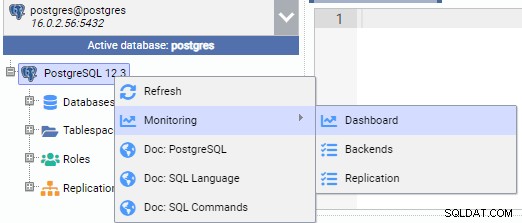
Nell'immagine sottostante, siamo collegati al nodo primario (PG-Node1). Facciamo clic con il pulsante destro del mouse sul nome dell'istanza, quindi dal menu a comparsa scegli "Monitor" e quindi "Dashboard".
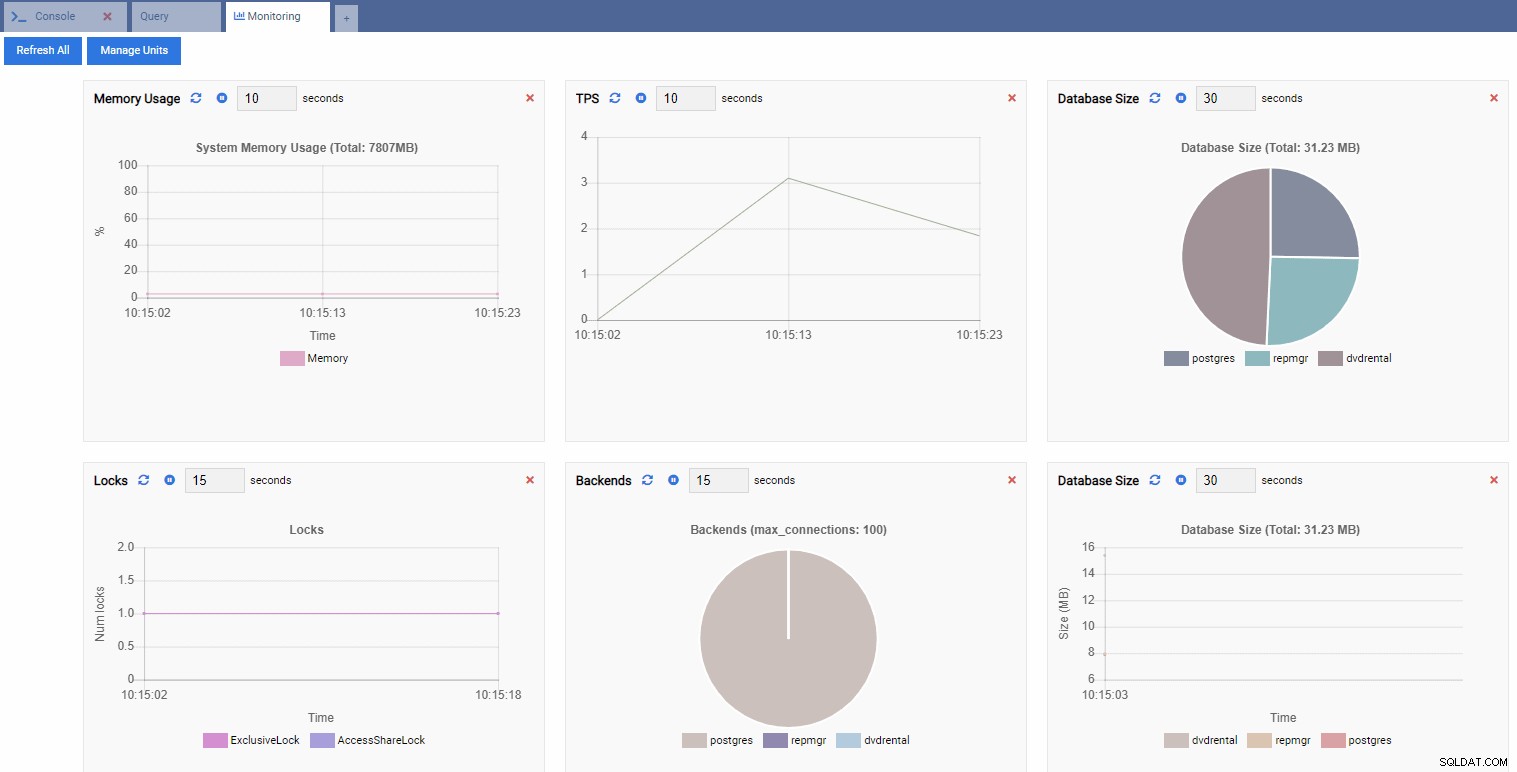
Si apre una dashboard con alcuni widget.
In termini OmniDB, i widget rettangolari nella dashboard sono chiamati Unità di monitoraggio . Ognuna di queste unità mostra una metrica specifica dall'istanza PostgreSQL a cui è connessa e aggiorna dinamicamente i suoi dati.
Comprendere le unità di monitoraggio
OmniDB viene fornito con quattro tipi di unità di monitoraggio:
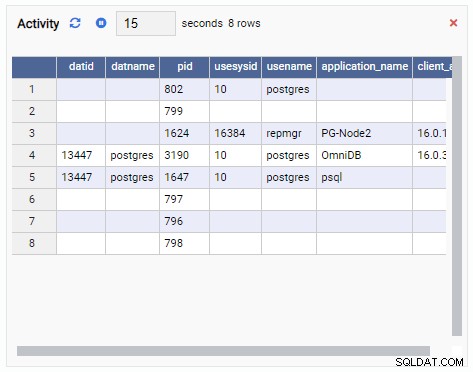
- Una Griglia è una struttura tabellare che mostra il risultato di una query. Ad esempio, questo può essere l'output di SELECT * FROM pg_stat_replication. Una griglia si presenta così:
- Un Grafico mostra i dati in formato grafico, come linee o grafici a torta. Quando si aggiorna, l'intero grafico viene ridisegnato sullo schermo con un nuovo valore e il vecchio valore scompare. Con queste unità di monitoraggio, possiamo vedere solo il valore corrente della metrica. Ecco un esempio di grafico:
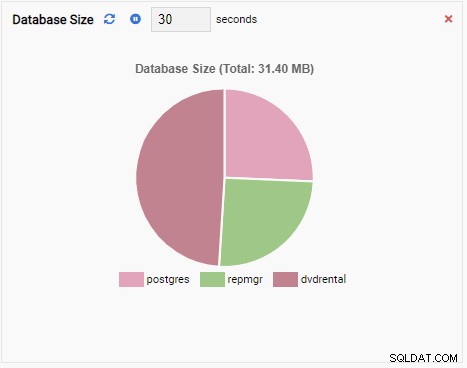
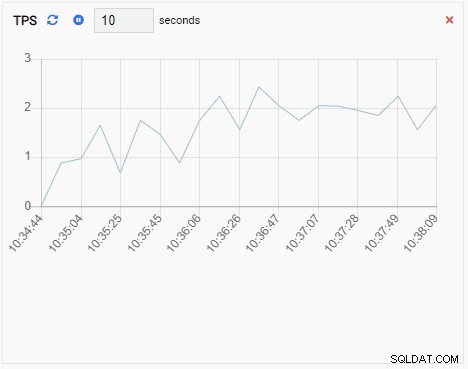
- Un aggiungere grafico è anche un'Unità di monitoraggio di tipo Grafico, tranne quando si aggiorna, aggiunge il nuovo valore alla serie esistente. Con Chart-Append, possiamo facilmente vedere le tendenze nel tempo. Ecco un esempio:
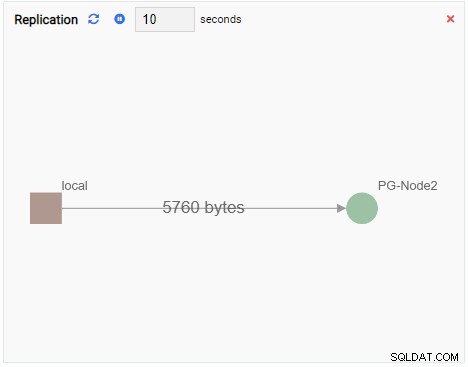
- Un Grafico mostra le relazioni tra le istanze del cluster PostgreSQL e una metrica associata. Come l'unità di monitoraggio grafico, anche un'unità di monitoraggio grafico aggiorna il suo vecchio valore con uno nuovo. L'immagine seguente mostra che il nodo corrente (PG-Node1) sta replicando sul PG-Node2:
Ogni unità di monitoraggio ha una serie di elementi comuni:
- Il nome dell'unità di monitoraggio
- Un pulsante "aggiorna" per aggiornare manualmente l'unità
- Un pulsante di "pausa" per interrompere temporaneamente l'aggiornamento dell'unità di monitoraggio
- Una casella di testo che mostra l'intervallo di aggiornamento corrente. Questo può essere modificato
- Un pulsante "chiudi" (segno di una croce rossa) per rimuovere l'Unità di monitoraggio dalla dashboard
- L'area di disegno effettiva del Monitoraggio
Unità di monitoraggio predefinite
OmniDB viene fornito con una serie di unità di monitoraggio per PostgreSQL che possiamo aggiungere alla nostra dashboard. Per accedere a queste unità, facciamo clic sul pulsante "Gestisci unità" nella parte superiore della dashboard:
Questo apre l'elenco "Gestisci unità":
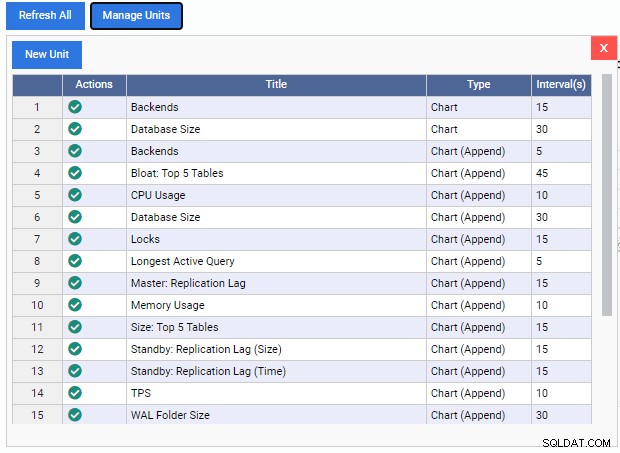
Come possiamo vedere, qui ci sono alcune unità di monitoraggio predefinite. I codici per queste unità di monitoraggio sono scaricabili gratuitamente dal repository GitHub di 2ndQuadrant. Ciascuna unità qui elencata mostra il nome, il tipo (Grafico, Appende grafico, Grafico o Griglia) e la frequenza di aggiornamento predefinita.
Per aggiungere un'unità di monitoraggio alla dashboard, dobbiamo solo fare clic sul segno di spunta verde nella colonna "Azioni" per quell'unità. Possiamo combinare e abbinare diverse unità di monitoraggio per creare la dashboard che desideriamo.
Nell'immagine seguente, abbiamo aggiunto le seguenti unità per la nostra dashboard di monitoraggio delle prestazioni e rimosso tutto il resto:
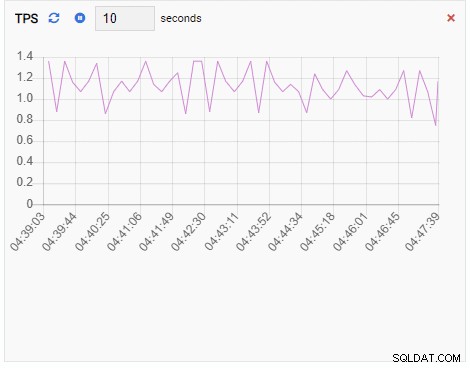
TPS (transazione al secondo):
Numero di serrature:
Numero di backend:
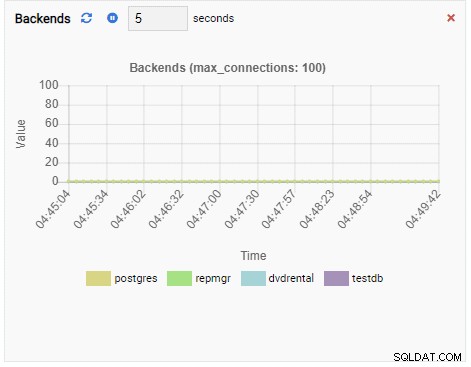
Poiché la nostra istanza è inattiva, possiamo vedere che i valori di TPS, Locks e Backend sono minimi.
Test del dashboard di monitoraggio
Ora eseguiremo pgbench nel nostro nodo primario (PG-Node1). pgbench è un semplice strumento di benchmarking fornito con PostgreSQL. Come la maggior parte degli altri strumenti del suo genere, pgbench crea uno schema e tabelle di sistemi OLTP di esempio in un database quando viene inizializzato. Successivamente, può emulare più connessioni client, ognuna delle quali esegue un numero di transazioni sul database. In questo caso, non faremo il benchmark del nodo primario di PostgreSQL; creeremo solo il database per pgbench e vedremo se le nostre unità di monitoraggio della dashboard rilevano la modifica dello stato del sistema.
Per prima cosa, stiamo creando un database per pgbench nel nodo primario:
[example@sqldat.com ~]$ psql -h PG-Node1 -U postgres -c "CREATE DATABASE testdb"; CREATE DATABASE
Successivamente, stiamo inizializzando il database "testdb" per pgbench:
[example@sqldat.com ~]$ /usr/pgsql-12/bin/pgbench -h PG-Node1 -p 5432 -I dtgvp -i -s 20 testdb dropping old tables... creating tables... generating data... 100000 of 2000000 tuples (5%) done (elapsed 0.02 s, remaining 0.43 s) 200000 of 2000000 tuples (10%) done (elapsed 0.05 s, remaining 0.41 s) … … 2000000 of 2000000 tuples (100%) done (elapsed 1.84 s, remaining 0.00 s) vacuuming... creating primary keys... done.
Con il database inizializzato, iniziamo ora il processo di caricamento vero e proprio. Nello snippet di codice di seguito, chiediamo a pgbench di iniziare con 50 connessioni client simultanee rispetto al database testdb, ciascuna connessione esegue 100000 transazioni sulle sue tabelle. Il test di carico verrà eseguito su due thread.
[example@sqldat.com ~]$ /usr/pgsql-12/bin/pgbench -h PG-Node1 -p 5432 -c 50 -j 2 -t 100000 testdb starting vacuum...end. … …
Se ora torniamo alla nostra dashboard OmniDB, vediamo che le unità di monitoraggio mostrano risultati molto diversi.
La metrica TPS mostra un valore piuttosto elevato. C'è un salto improvviso da meno di 2 a più di 2000:
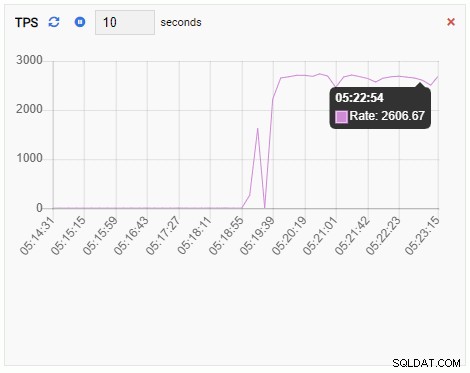
Il numero di backend è aumentato. Come previsto, testdb ha 50 connessioni contro di esso mentre altri database sono inattivi:
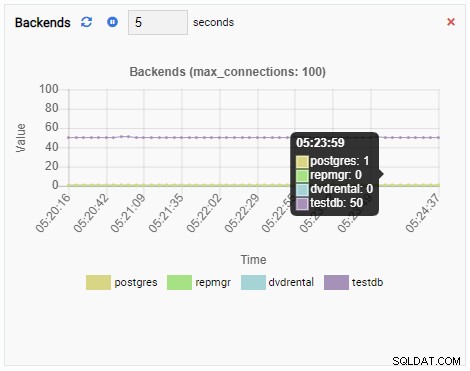
Infine, anche il numero di blocchi esclusivi di riga nel database testdb è elevato:
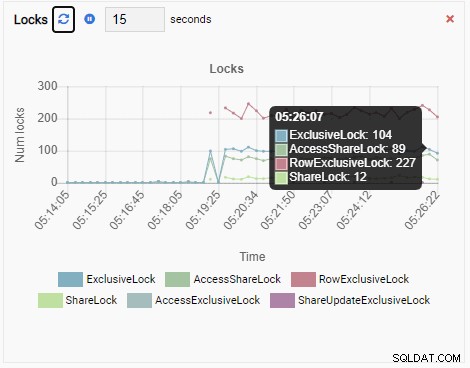
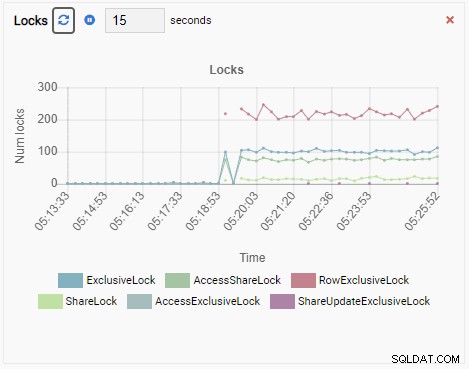
Ora immagina questo. Sei un DBA e utilizzi OmniDB per gestire un parco istanze PostgreSQL. Ricevi una chiamata per esaminare le prestazioni lente in una delle istanze.
Utilizzando una dashboard come quella che abbiamo appena visto (sebbene sia molto semplice), puoi facilmente trovare la causa principale. Puoi controllare il numero di backend, blocchi, memoria disponibile e così via per vedere la causa del problema.
Ed è qui che OmniDB può essere uno strumento davvero utile.
Creazione di unità di monitoraggio personalizzate
A volte avremo bisogno di creare le nostre unità di monitoraggio. Per scrivere una nuova unità di monitoraggio, fare clic sul pulsante "Nuova unità" nell'elenco "Gestisci unità". Si apre una nuova scheda con un'area vuota per la scrittura del codice:
Nella parte superiore dello schermo, dobbiamo specificare un nome per la nostra unità di monitoraggio, selezionarne il tipo e specificare l'intervallo di aggiornamento predefinito. Possiamo anche selezionare un'unità esistente come modello.
Sotto la sezione dell'intestazione, ci sono due caselle di testo. L'editor "Data Script" è il luogo in cui scriviamo il codice per ottenere i dati per la nostra unità di monitoraggio. Ogni volta che un'unità viene aggiornata, il codice dello script di dati verrà eseguito. L'editor "Chart Script" è dove scriviamo il codice per disegnare l'unità effettiva. Viene eseguito quando l'unità viene estratta per la prima volta.
Tutto il codice dello script di dati è scritto in Python. Per l'Unità di monitoraggio del tipo di grafico, OmniDB necessita che lo script del grafico sia scritto in Chart.js.
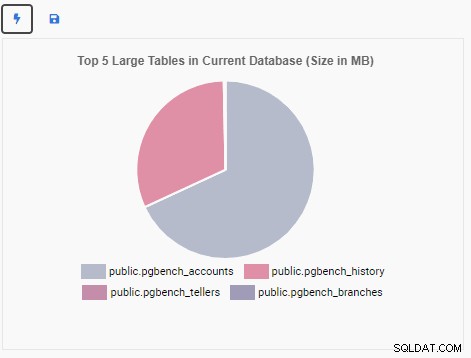
Creeremo ora un'unità di monitoraggio per mostrare le prime 5 tabelle di grandi dimensioni nel database corrente. In base al database selezionato in OmniDB, l'Unità di monitoraggio cambierà la sua visualizzazione per riflettere i nomi delle cinque tabelle più grandi in quel database.
Per scrivere una nuova unità, è meglio iniziare con un modello esistente e modificarne il codice. Ciò farà risparmiare tempo e fatica. Nell'immagine seguente, abbiamo chiamato la nostra unità di monitoraggio "Top 5 Large Tables". Abbiamo scelto che fosse di tipo Grafico (No Append) e fornito una frequenza di aggiornamento di 30 secondi. Abbiamo anche basato la nostra unità di monitoraggio sul modello Dimensione database:
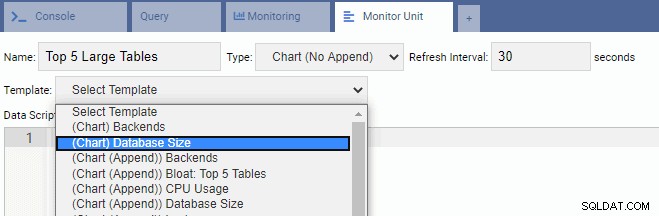
La casella di testo Script di dati viene compilata automaticamente con il codice per l'Unità di monitoraggio delle dimensioni del database:
from datetime import datetime
from random import randint
databases = connection.Query('''
SELECT d.datname AS datname,
round(pg_catalog.pg_database_size(d.datname)/1048576.0,2) AS size
FROM pg_catalog.pg_database d
WHERE d.datname not in ('template0','template1')
''')
data = []
color = []
label = []
for db in databases.Rows:
data.append(db["size"])
color.append("rgb(" + str(randint(125, 225)) + "," + str(randint(125, 225)) + "," + str(randint(125, 225)) + ")")
label.append(db["datname"])
total_size = connection.ExecuteScalar('''
SELECT round(sum(pg_catalog.pg_database_size(datname)/1048576.0),2)
FROM pg_catalog.pg_database
WHERE NOT datistemplate
''')
result = {
"labels": label,
"datasets": [
{
"data": data,
"backgroundColor": color,
"label": "Dataset 1"
}
],
"title": "Database Size (Total: " + str(total_size) + " MB)"
} E anche la casella di testo Script grafico è popolata con codice:
total_size = connection.ExecuteScalar('''
SELECT round(sum(pg_catalog.pg_database_size(datname)/1048576.0),2)
FROM pg_catalog.pg_database
WHERE NOT datistemplate
''')
result = {
"type": "pie",
"data": None,
"options": {
"responsive": True,
"title":{
"display":True,
"text":"Database Size (Total: " + str(total_size) + " MB)"
}
}
} Possiamo modificare lo script di dati per ottenere le prime 5 tabelle di grandi dimensioni nel database. Nello script seguente, abbiamo conservato la maggior parte del codice originale, ad eccezione dell'istruzione SQL:
from datetime import datetime
from random import randint
tables = connection.Query('''
SELECT nspname || '.' || relname AS "tablename",
round(pg_catalog.pg_total_relation_size(c.oid)/1048576.0,2) AS "table_size"
FROM pg_class C
LEFT JOIN pg_namespace N ON (N.oid = C.relnamespace)
WHERE nspname NOT IN ('pg_catalog', 'information_schema')
AND C.relkind <> 'i'
AND nspname !~ '^pg_toast'
ORDER BY 2 DESC
LIMIT 5;
''')
data = []
color = []
label = []
for table in tables.Rows:
data.append(table["table_size"])
color.append("rgb(" + str(randint(125, 225)) + "," + str(randint(125, 225)) + "," + str(randint(125, 225)) + ")")
label.append(table["tablename"])
result = {
"labels": label,
"datasets": [
{
"data": data,
"backgroundColor": color,
"label": "Top 5 Large Tables"
}
]
} Qui, otteniamo la dimensione combinata di ogni tabella e dei suoi indici nel database corrente. Stiamo ordinando i risultati in ordine decrescente e selezionando le prime cinque righe.
Successivamente, stiamo popolando tre array Python eseguendo un'iterazione sul set di risultati.
Infine, stiamo costruendo una stringa JSON basata sui valori degli array.
Nella casella di testo Script grafico, abbiamo modificato il codice per rimuovere il comando SQL originale. Qui specifichiamo solo l'aspetto estetico del grafico. Definiamo il grafico come tipo di torta e gli forniamo un titolo:
result = {
"type": "pie",
"data": None,
"options": {
"responsive": True,
"title":{
"display":True,
"text":"Top 5 Large Tables in Current Database (Size in MB)"
}
}
} Ora possiamo testare l'unità facendo clic sull'icona del fulmine. Questo mostrerà la nuova unità di monitoraggio nell'area di disegno dell'anteprima:
Successivamente, salviamo l'unità facendo clic sull'icona del disco. Una finestra di messaggio conferma che l'unità è stata salvata:

Ora torniamo alla nostra dashboard di monitoraggio e aggiungiamo la nuova unità di monitoraggio:
Nota come abbiamo altre due icone nella colonna "Azioni" per la nostra unità di monitoraggio personalizzata. Uno serve per modificarlo, l'altro per rimuoverlo da OmniDB.
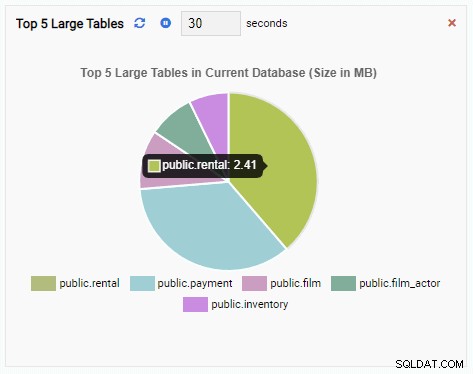
L'unità di monitoraggio "Prime 5 tabelle di grandi dimensioni" ora mostra le cinque tabelle più grandi nel database corrente:
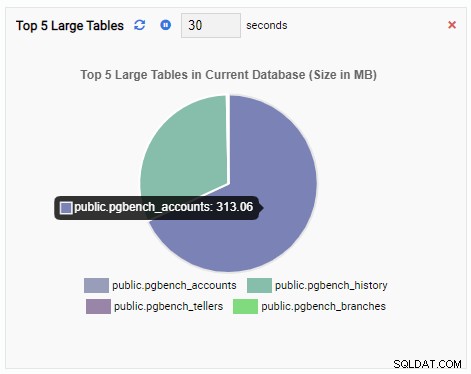
Se chiudiamo la dashboard, passiamo a un altro database dal riquadro di navigazione e apriamo nuovamente la dashboard, vedremo che l'unità di monitoraggio è cambiata per riflettere le tabelle di quel database:
Le ultime parole
Questo conclude la nostra serie in due parti su OmniDB. Come abbiamo visto, OmniDB ha alcune unità di monitoraggio ingegnose che i DBA di PostgreSQL troveranno utili per il monitoraggio delle prestazioni. Abbiamo visto come possiamo utilizzare queste unità per identificare potenziali colli di bottiglia nel server. Abbiamo anche visto come creare le nostre unità personalizzate. I lettori sono incoraggiati a creare e testare le unità di monitoraggio delle prestazioni per i loro carichi di lavoro specifici. 2ndQuadrant accoglie con favore qualsiasi contributo al repository GitHub di OmniDB Monitoring Unit.