Con l'introduzione del database SQL di Azure e l'aggiunta di ulteriori funzionalità nella v12, gli amministratori di database iniziano a vedere le loro organizzazioni più interessate a spostare i database su questa piattaforma.
Di recente ho iniziato a immergermi maggiormente nel database SQL di Azure per vedere cosa c'è di drasticamente diverso dal supporto della versione box nei data center di tutto il mondo e nel database SQL di Azure. Nel mio articolo precedente, "Ottimizzazione:un buon punto di partenza", ho illustrato il mio approccio per iniziare con l'ottimizzazione di SQL Server. Ho deciso di esaminarlo rispetto al database SQL di Azure per scoprire le principali differenze.
Nel mio articolo originale, ho iniziato con impostazioni comuni a livello di istanza che vedo ignorate o lasciate come predefinite, nonché elementi di manutenzione. Questi includono memoria, maxdop, soglia di costo per il parallelismo, ottimizzazione per carichi di lavoro ad hoc e configurazione di tempdb. Con il database SQL di Azure non sei responsabile dell'istanza e non puoi modificare tali impostazioni. Il database SQL di Azure è una piattaforma come servizio (PaaS), il che significa che Microsoft gestisce l'istanza per te; sei semplicemente un inquilino con il tuo database o database.
Tuttavia, sei responsabile della manutenzione, quindi devi aggiornare le statistiche e gestire la frammentazione dell'indice come fai per il prodotto in scatola. Per queste attività, ho riscontrato che la maggior parte dei client gestisce tali processi con una macchina virtuale di Azure dedicata che esegue SQL Server e usa SQL Server Agent con processi pianificati.
Seguendo i passaggi del mio articolo, le aree successive che comincio a esaminare sono le statistiche sui file e sull'attesa e le query ad alto costo. Se ti stai chiedendo se questo aspetto del tuo lavoro come database di produzione con database locali cambierà quando lavori con il database SQL di Azure, la risposta è non proprio . Le statistiche di file e di attesa sono ancora lì, ma dobbiamo arrivarci in un modo leggermente diverso. Se sei abituato a utilizzare gli script di Paul Randal per le statistiche dei file e le statistiche di attesa (o le query per le statistiche dei file per un periodo di tempo e le statistiche di attesa per un periodo di tempo), dovrai apportare alcune modifiche in ordine per quegli script per lavorare con il database SQL di Azure.
Quando ho provato per la prima volta lo script delle statistiche dei file di Paul, non è riuscito a causa del database SQL di Azure che non supportava sys.master_files :
Nome oggetto 'sys.master_files' non valido.
Sono stato in grado di modificare lo script per utilizzare sys.databases nel join per ottenere il nome del database e rimuovere la parte dello script per ottenere i singoli nomi di file poiché avremo a che fare solo con un singolo file di dati e registro. Puoi vedere le modifiche che ho dovuto apportare nell'immagine seguente:
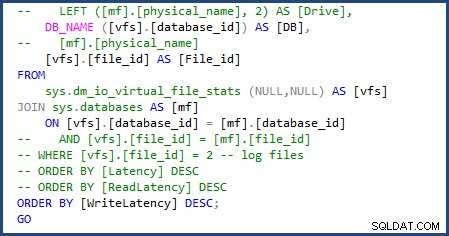
Quando ho eseguito lo script file-stats-over-a-period-of-time dopo, apportando la stessa modifica a sys.databases e rimuovendo i riferimenti a file_id nel join, non è riuscito a causa del database SQL di Azure v12 che non supporta le tabelle ##temp globali.
Dopo aver modificato tutte le tabelle ##temp globali in locali, ho riscontrato un altro problema con lo script incapace di eliminare le tabelle temporanee esistenti utilizzate, perché non è possibile fare riferimento direttamente alle tabelle #temp locali per nome come possono fare le tabelle ##temp globali, ma questo è stato facile da superare modificando tali controlli in OBJECT_ID('tempdb..#SQLskillsStats1') . Ho apportato la stessa modifica per la seconda tabella temporanea e aggiornato il blocco di codice all'inizio e alla fine dello script.
Ho dovuto apportare un'altra modifica e rimuovere [mf].[type_desc] e LEFT ([mf].[physical_name], 2) AS [Drive] poiché questi dipendono da sys.master_files . Lo script era quindi completo e pronto per l'uso con il database SQL di Azure.
Uso regolarmente le statistiche dei file per un periodo di tempo durante la risoluzione dei problemi di prestazioni. I dati cumulativi hanno il loro scopo, ma sono più interessato a specifici segmenti di tempo in cui vengono eseguiti i carichi di lavoro degli utenti.
Con le statistiche dei file, ci preoccupiamo della nostra latenza per file di database e di come possiamo ottimizzare per ridurre l'I/O complessivo. L'approccio è lo stesso di SQL Server, in cui è necessario ottimizzare le query correttamente e disporre degli indici corretti. Se il carico di lavoro è troppo grande, è necessario passare a un livello di database DTU con prestazioni più veloci. Per me, questo è fantastico:ci si lancia semplicemente l'hardware; ma non è proprio hardware nel senso tradizionale. Con il database SQL di Azure, puoi iniziare con un livello meno costoso e scalare man mano che la tua attività e le richieste di I/O crescono, essenzialmente semplicemente spostando un interruttore.
Cercare di trovare il metodo migliore per ottenere le statistiche di attesa è stato più semplice. Lo script standard che molti di noi usano ancora funziona, tuttavia estrae statistiche di attesa per il contenitore in cui è in esecuzione il database. Tali attese si applicano ancora al tuo sistema, ma possono includere le attese sostenute da altri database nello stesso contenitore. Il database SQL di Azure contiene un nuovo DMV, sys.dm_db_wait_stats , che filtra nel database corrente. Se sei come me e utilizzi principalmente lo script delle statistiche di attesa di Paul che omette tutte le attese benigne, cambia semplicemente sys.dm_os_wait_stats a sys.dm_db_wait_stats . La stessa modifica funziona anche per lo script waits-over-a-period-of-time, ma devi anche apportare la modifica dalle variabili globali a quelle locali.
Quando si tratta di trovare query ad alto costo, uno dei miei script preferiti da eseguire trova i piani di esecuzione più utilizzati. In base alla mia esperienza, l'ottimizzazione di una query che viene chiamata 100.000 volte al giorno è in genere una vittoria maggiore rispetto all'ottimizzazione di una query che ha l'IO più alto ma viene eseguita solo una volta alla settimana. La seguente query è ciò che utilizzo per trovare i piani più utilizzati:
SELECT usecounts ,
cacheobjtype ,
objtype ,
[text]
FROM sys.dm_exec_cached_plans
CROSS APPLY sys.dm_exec_sql_text(plan_handle)
WHERE usecounts > 1
AND objtype IN ( N'Adhoc', N'Prepared' )
ORDER BY usecounts DESC;
Quando utilizzo questa query nelle demo, svuota sempre la cache del mio piano per reimpostare i valori. Quando ho provato a eseguire DBCC FREEPROCCACHE nel database SQL di Azure, mi è stato visualizzato il seguente errore:
Si scopre che DBCC FREEPROCCACHE non è supportato nel database SQL di Azure. Questo era preoccupante per me, e se fossi in produzione e avessi dei piani sbagliati e volessi svuotare la cache delle procedure come posso con la versione box. Una piccola ricerca su Google/Bing mi ha portato a trovare l'articolo di Microsoft, "Capire la cache delle procedure in SQL Azure", che afferma:
Discutendo di questo con Kimberly Tripp dopo non aver visto il comportamento descritto, non svuota il piano dalla cache, ma invalida il piano (e quindi il piano verrà eventualmente ritirato dalla cache). Anche se questo è utile in determinate situazioni, non era quello di cui avevo bisogno. Per la mia demo volevo ripristinare i contatori in sys.dm_exec_cached_plans. Generare un nuovo piano non mi darebbe i risultati sperati. Ho contattato il mio team e Glenn Berry mi ha detto di provare il seguente script:
ALTER DATABASE SCOPED CONFIGURATION CLEAR PROCEDURE_CACHE;
Questo comando ha funzionato; Sono stato in grado di svuotare la cache delle procedure per il database specifico. Configurazioni con ambito database è una nuova funzionalità aggiunta in SQL Server 2016 RC0; Glenn ne ha scritto un blog qui:Utilizzo di ALTER DATABASE SCOPED CONFIGURATION in SQL Server 2016.
Sono entusiasta di spostare molti dei miei database nel database SQL di Azure e di continuare a conoscere le nuove funzionalità e opzioni di scalabilità. Non vedo l'ora di lavorare anche con SentryOne DB Sentry, una recente aggiunta alla piattaforma SentryOne. Sono molto interessato a sperimentare la dashboard di utilizzo DTU, che Mike Wood ha descritto nel suo recente post.