Diciamo che vuoi trovare tutti i pazienti che non hanno mai avuto un vaccino antinfluenzale. Oppure, in AdventureWorks2012 , una domanda simile potrebbe essere "mostrami tutti i clienti che non hanno mai effettuato un ordine". Espresso usando NOT IN , uno schema che vedo troppo spesso, che assomiglierebbe a questo (sto usando l'intestazione ingrandita e le tabelle dei dettagli di questo script di Jonathan Kehayias (@SQLPoolBoy)):
SELECT CustomerID FROM Sales.Customer WHERE CustomerID NOT IN ( SELECT CustomerID FROM Sales.SalesOrderHeaderEnlarged );
Quando vedo questo schema, rabbrividisco. Ma non per motivi di prestazioni, dopotutto, in questo caso crea un piano abbastanza decente:
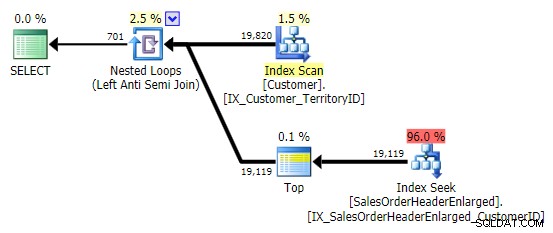
Il problema principale è che i risultati possono essere sorprendenti se la colonna di destinazione è NULLable (SQL Server lo elabora come un anti semi join sinistro, ma non può dirti in modo affidabile se un NULL sul lato destro è uguale a - o non uguale a – il riferimento a sinistra). Inoltre, l'ottimizzazione può comportarsi diversamente se la colonna è NULLable, anche se in realtà non contiene alcun valore NULL (Gail Shaw ne ha parlato nel 2010).
In questo caso, la colonna di destinazione non è nullable, ma volevo menzionare quei potenziali problemi con NOT IN – Potrei indagare su questi problemi in modo più approfondito in un post futuro.
TL;versione DR
Invece di NOT IN , usa un NOT EXISTS correlato per questo modello di query. Sempre. Altri metodi possono rivaleggiare in termini di prestazioni, quando tutte le altre variabili sono le stesse, ma tutti gli altri metodi introducono problemi di prestazioni o altre sfide.
Alternative
Quindi in quali altri modi possiamo scrivere questa query?
APPLICAZIONE ESTERNA
Un modo per esprimere questo risultato è utilizzare un OUTER APPLY correlato .
SELECT c.CustomerID FROM Sales.Customer AS c OUTER APPLY ( SELECT CustomerID FROM Sales.SalesOrderHeaderEnlarged WHERE CustomerID = c.CustomerID ) AS h WHERE h.CustomerID IS NULL;
Logicamente, anche questo è un anti semi join sinistro, ma nel piano risultante manca l'operatore anti semi join sinistro e sembra essere un po' più costoso di NOT IN equivalente. Questo perché non è più un anti semi join sinistro; in realtà viene elaborato in un modo diverso:un outer join porta tutte le righe corrispondenti e non corrispondenti, e *poi* viene applicato un filtro per eliminare le corrispondenze:
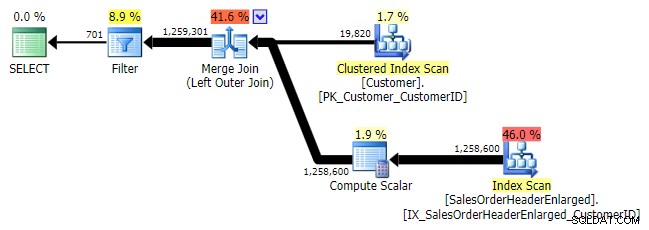
UNIONE ESTERNA SINISTRA
Un'alternativa più tipica è LEFT OUTER JOIN dove il lato destro è NULL . In questo caso la query sarebbe:
SELECT c.CustomerID FROM Sales.Customer AS c LEFT OUTER JOIN Sales.SalesOrderHeaderEnlarged AS h ON c.CustomerID = h.CustomerID WHERE h.CustomerID IS NULL;
Ciò restituisce gli stessi risultati; tuttavia, come OUTER APPLY, utilizza la stessa tecnica di unire tutte le righe e solo successivamente eliminare le corrispondenze:
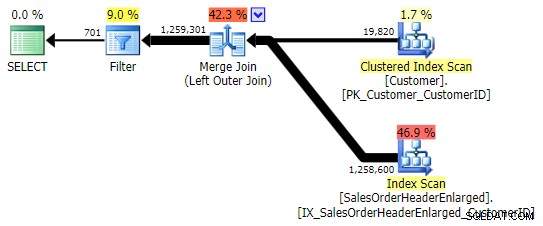
Tuttavia, devi fare attenzione a quale colonna controlli per NULL . In questo caso CustomerID è la scelta logica perché è la colonna di giunzione; capita anche di essere indicizzato. Avrei potuto scegliere SalesOrderID , che è la chiave di clustering, quindi è anche nell'indice su CustomerID . Ma avrei potuto scegliere un'altra colonna che non si trova (o che in seguito viene rimossa) dall'indice utilizzato per il join, portando a un piano diverso. O anche una colonna NULLable, che porta a risultati errati (o almeno imprevisti), poiché non c'è modo di distinguere tra una riga che non esiste e una riga che esiste ma dove quella colonna è NULL . E potrebbe non essere ovvio per il lettore/sviluppatore/risoluzione dei problemi che questo è il caso. Quindi testerò anche questi tre WHERE clausole:
WHERE h.SalesOrderID IS NULL; -- clustered, so part of index WHERE h.SubTotal IS NULL; -- not nullable, not part of the index WHERE h.Comment IS NULL; -- nullable, not part of the index
La prima variazione produce lo stesso piano di cui sopra. Gli altri due scelgono un hash join invece di un merge join e un indice più ristretto nel Customer tabella, anche se alla fine la query finisce per leggere lo stesso numero esatto di pagine e quantità di dati. Tuttavia, mentre il h.SubTotal la variazione produce i risultati corretti:
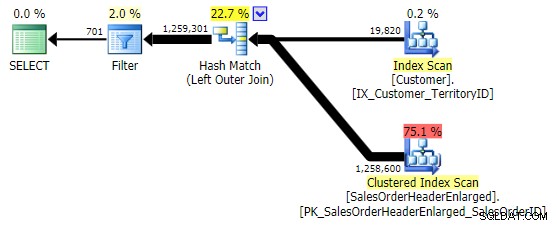
Il h.Comment la variazione non lo fa, poiché include tutte le righe in cui h.Comment IS NULL , nonché tutte le righe che non esistevano per nessun cliente. Ho evidenziato la sottile differenza nel numero di righe nell'output dopo l'applicazione del filtro:
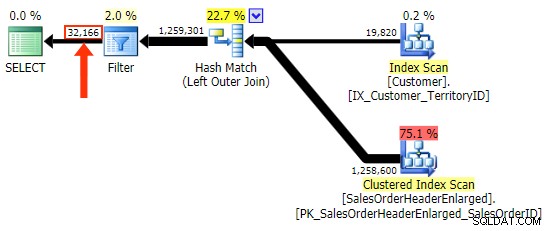
Oltre a dover fare attenzione alla selezione delle colonne nel filtro, l'altro problema che ho con il LEFT OUTER JOIN form è che non si auto-documenta, allo stesso modo di un inner join nella forma "vecchio stile" di FROM dbo.table_a, dbo.table_b WHERE ... non si autodocumenta. Con ciò intendo dire che è facile dimenticare i criteri di unione quando viene inviato a WHERE clausola, o per essere mescolato con altri criteri di filtro. Mi rendo conto che questo è abbastanza soggettivo, ma è così.
ECCETTO
Se tutto ciò che ci interessa è la colonna join (che per definizione è in entrambe le tabelle), possiamo usare EXCEPT – un'alternativa che non sembra emergere molto in queste conversazioni (probabilmente perché, di solito, è necessario estendere la query per includere le colonne che non stai confrontando):
SELECT CustomerID FROM Sales.Customer AS c EXCEPT SELECT CustomerID FROM Sales.SalesOrderHeaderEnlarged;
Questo si presenta con lo stesso identico piano di NOT IN variazione sopra:
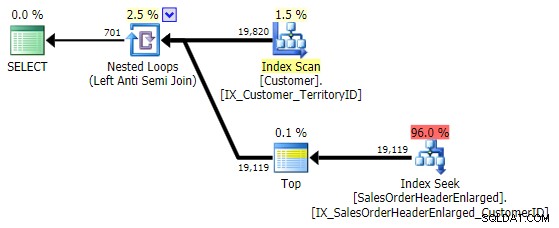
Una cosa da tenere a mente è che EXCEPT include un implicito DISTINCT – quindi se hai casi in cui desideri che più righe abbiano lo stesso valore nella tabella "sinistra", questo modulo eliminerà quei duplicati. Non è un problema in questo caso specifico, solo qualcosa da tenere a mente, proprio come UNION contro UNION ALL .
NON ESISTE
La mia preferenza per questo modello è sicuramente NOT EXISTS :
SELECT CustomerID
FROM Sales.Customer AS c
WHERE NOT EXISTS
(
SELECT 1
FROM Sales.SalesOrderHeaderEnlarged
WHERE CustomerID = c.CustomerID
);
(E sì, uso SELECT 1 invece di SELECT * ... non per motivi di prestazioni, poiché a SQL Server non interessa quali colonne usi all'interno di EXISTS e li ottimizza via, ma semplicemente per chiarire l'intento:questo mi ricorda che questa "subquery" in realtà non restituisce alcun dato.)
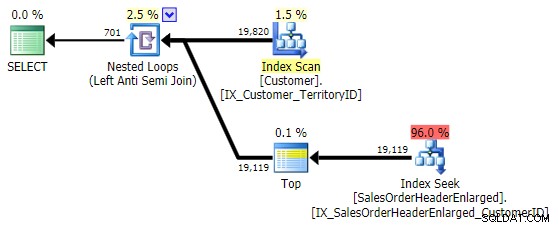
Le sue prestazioni sono simili a NOT IN e EXCEPT , e produce un piano identico, ma non è soggetto a potenziali problemi causati da NULL o duplicati:
Test delle prestazioni
Ho eseguito una moltitudine di test, sia con una cache fredda che calda, per convalidare che la mia percezione di vecchia data su NOT EXISTS essere la scelta giusta è rimasta vera. L'output tipico era simile a questo:
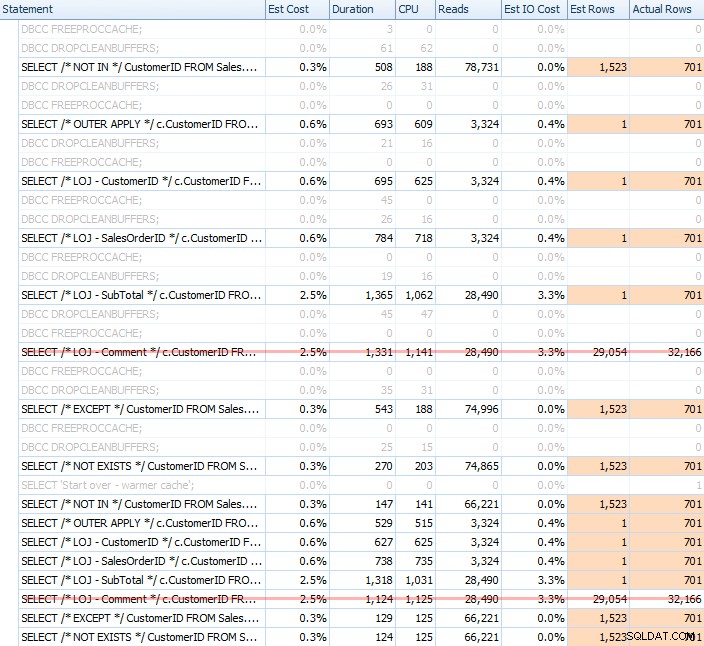
Toglierò il risultato errato dal mix quando mostro le prestazioni medie di 20 esecuzioni su un grafico (l'ho incluso solo per dimostrare quanto siano sbagliati i risultati) e ho eseguito le query in un ordine diverso tra i test per assicurarmi quella query non beneficiava costantemente del lavoro di una query precedente. Concentrandoci sulla durata, ecco i risultati:
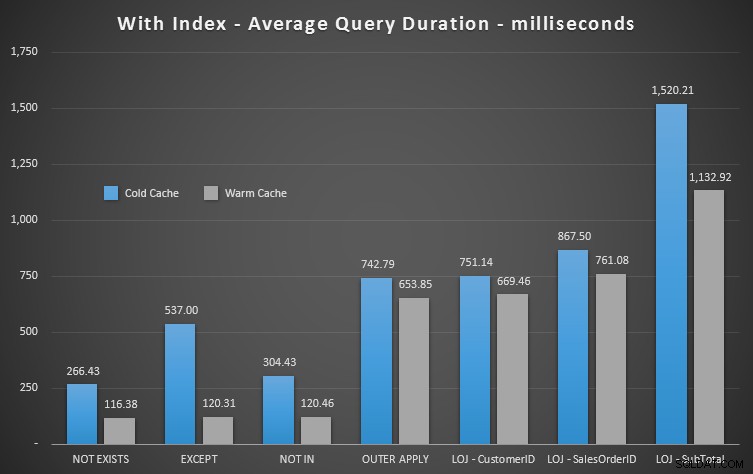
Se guardiamo alla durata e ignoriamo le letture, NOT EXISTS è il tuo vincitore, ma non di molto. EXCEPT e NOT IN non sono molto indietro, ma ancora una volta devi guardare più che alle prestazioni per determinare se queste opzioni sono valide e testare nel tuo scenario.
Cosa succede se non c'è un indice di supporto?
Le query di cui sopra beneficiano, ovviamente, dell'indice su Sales.SalesOrderHeaderEnlarged.CustomerID . Come cambiano questi risultati se eliminiamo questo indice? Ho eseguito di nuovo la stessa serie di test, dopo aver eliminato l'indice:
DROP INDEX [IX_SalesOrderHeaderEnlarged_CustomerID] ON [Sales].[SalesOrderHeaderEnlarged];
Questa volta c'è stata una deviazione molto minore in termini di prestazioni tra i diversi metodi. Per prima cosa mostrerò i piani per ciascun metodo (la maggior parte dei quali, non a caso, indica l'utilità dell'indice mancante che abbiamo appena eliminato). Quindi mostrerò un nuovo grafico che illustra il profilo delle prestazioni sia con una cache fredda che con una cache calda.
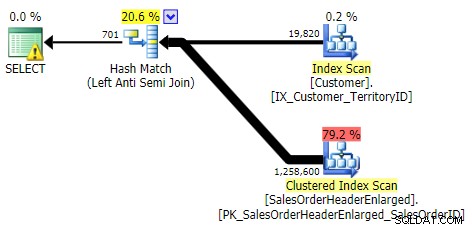
NON IN, TRANNE, NON ESISTE (tutti e tre erano identici)
APPLICAZIONE ESTERNA
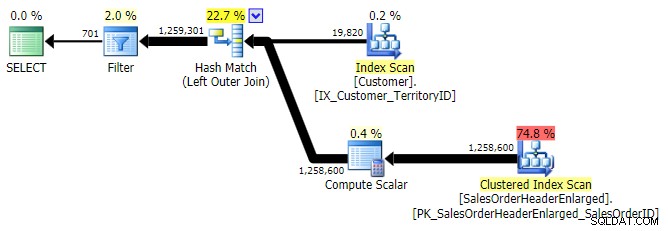
LEFT OUTER JOIN (tutti e tre erano identici tranne il numero di righe)
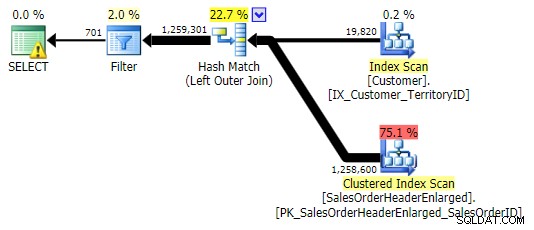
Risultati delle prestazioni
Possiamo immediatamente vedere quanto sia utile l'indice quando osserviamo questi nuovi risultati. In tutti i casi tranne uno (il join esterno sinistro che va comunque al di fuori dell'indice), i risultati sono chiaramente peggiori quando abbiamo eliminato l'indice:
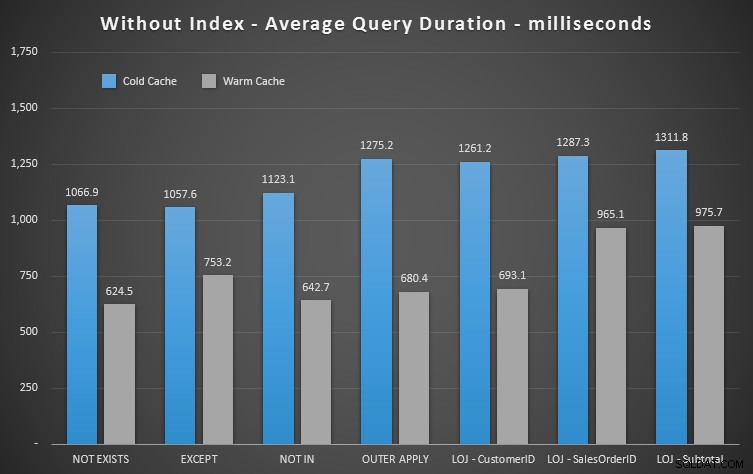
Quindi possiamo vedere che, sebbene l'impatto sia meno evidente, NOT EXISTS è ancora il tuo vincitore marginale in termini di durata. E nelle situazioni in cui gli altri approcci sono soggetti alla volatilità dello schema, è anche la tua scelta più sicura.
Conclusione
Questo era solo un modo prolisso per dirti che, per il modello di trovare tutte le righe nella tabella A in cui alcune condizioni non esistono nella tabella B, NOT EXISTS in genere sarà la scelta migliore. Ma, come sempre, devi testare questi modelli nel tuo ambiente, utilizzando lo schema, i dati e l'hardware, e mescolandoli con i tuoi carichi di lavoro.