Considera la seguente query AdventureWorks che restituisce gli ID transazione della tabella della cronologia per l'ID prodotto 421:
SELECT TH.TransactionID FROM Production.TransactionHistory AS TH WHERE TH.ProductID = 421;
Query Optimizer trova rapidamente un piano di esecuzione efficiente con una stima della cardinalità (numero di righe) esattamente corretta, come mostrato in SQL Sentry Plan Explorer:

Supponiamo ora di voler trovare gli ID transazione della cronologia per il prodotto AdventureWorks denominato "Metal Plate 2". Esistono molti modi per esprimere questa query in T-SQL. Una formulazione naturale è:
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID =
(
SELECT P.ProductID
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
); Il piano di esecuzione è il seguente:
La strategia è:
- Cerca l'ID prodotto nella tabella Prodotto dal nome fornito
- Individua le righe per quell'ID prodotto nella tabella Cronologia
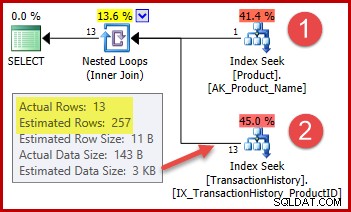
Il numero stimato di righe per il passaggio 1 è esattamente corretto perché l'indice utilizzato è dichiarato univoco e digitato solo sul nome del prodotto. Il test di uguaglianza su "Metal Plate 2" è quindi garantito per restituire esattamente una riga (o zero righe se specifichiamo un nome di prodotto che non esiste).
La stima di 257 righe evidenziata per il passaggio 2 è meno precisa:vengono effettivamente rilevate solo 13 righe. Questa discrepanza si verifica perché l'ottimizzatore non sa quale particolare ID prodotto è associato al prodotto denominato "Metal Plate 2". Tratta il valore come sconosciuto, generando una stima della cardinalità utilizzando le informazioni sulla densità media. Il calcolo utilizza elementi dell'oggetto statistiche mostrato di seguito:
DBCC SHOW_STATISTICS
(
'Production.TransactionHistory',
'IX_TransactionHistory_ProductID'
)
WITH STAT_HEADER, DENSITY_VECTOR;
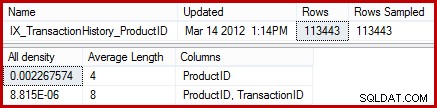
Le statistiche mostrano che la tabella contiene 113443 righe con 441 ID prodotto univoci (1 / 0,002267574 =441). Supponendo che la distribuzione delle righe tra gli ID prodotto sia uniforme, la stima della cardinalità prevede che un ID prodotto corrisponda (113443/441) =257,24 righe in media. A quanto pare, la distribuzione non è particolarmente uniforme; ci sono solo 13 righe per il prodotto "Metal Plate 2".
Una parentesi
Potresti pensare che la stima di 257 righe dovrebbe essere più accurata. Ad esempio, dato che gli ID prodotto ei nomi sono entrambi vincolati per essere univoci, SQL Server potrebbe mantenere automaticamente le informazioni su questa relazione uno-a-uno. Saprebbe quindi che "Metal Plate 2" è associato all'ID prodotto 479 e utilizzerà tale intuizione per generare una stima più accurata utilizzando l'istogramma ProductID:
DBCC SHOW_STATISTICS
(
'Production.TransactionHistory',
'IX_TransactionHistory_ProductID'
)
WITH HISTOGRAM;
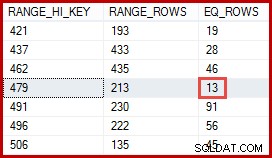
Una stima di 13 righe derivata in questo modo sarebbe stata esattamente corretta. Tuttavia, la stima di 257 righe non era irragionevole, date le informazioni statistiche disponibili e le normali ipotesi semplificative (come la distribuzione uniforme) applicate oggi dalla stima della cardinalità. Le stime esatte sono sempre utili, ma anche le stime "ragionevoli" sono perfettamente accettabili.
Combinazione delle due query
Supponiamo ora di voler vedere tutti gli ID della cronologia delle transazioni in cui l'ID prodotto è 421 OR il nome del prodotto è "Metal Plate 2". Un modo naturale per combinare le due query precedenti è:
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = 421
OR TH.ProductID =
(
SELECT P.ProductID
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
); Il piano di esecuzione è ora un po' più complesso, ma contiene ancora elementi riconoscibili dei piani a predicato singolo:
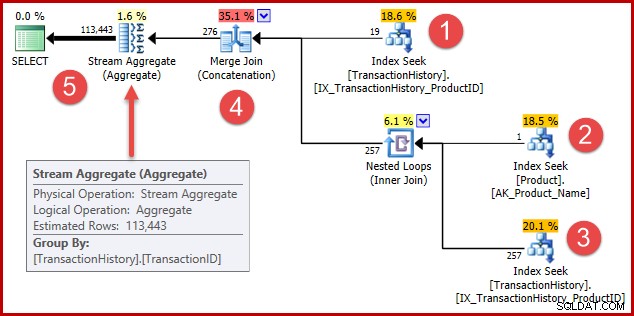
La strategia è:
- Trova i record della cronologia per il prodotto 421
- Cerca l'ID prodotto per il prodotto denominato "Metal Plate 2"
- Trova i record della cronologia per l'ID prodotto trovato nel passaggio 2
- Unisci le righe dei passaggi 1 e 3
- Rimuovi eventuali duplicati (perché il prodotto 421 potrebbe essere anche quello denominato "Metal Plate 2")
I passaggi da 1 a 3 sono esattamente gli stessi di prima. Le stesse stime sono prodotte per le stesse ragioni. Il passaggio 4 è nuovo, ma molto semplice:concatena 19 righe previste con 257 righe previste, per fornire una stima di 276 righe.
Il passaggio 5 è quello interessante. Lo Stream Aggregate per la rimozione dei duplicati ha un input stimato di 276 righe e un output stimato di 113443 righe. Un aggregato che genera più righe di quante ne riceve sembra impossibile, giusto?
* Se utilizzi il modello di stima della cardinalità precedente al 2014, vedrai una stima di 102099 righe.
Il bug della stima della cardinalità
L'impossibile stima di Stream Aggregate nel nostro esempio è causata da un bug nella stima della cardinalità. È un esempio interessante, quindi lo esploreremo un po' in dettaglio.
Rimozione sottoquery
Potrebbe sorprenderti apprendere che Query Optimizer di SQL Server non funziona direttamente con le sottoquery. Vengono rimossi dall'albero delle query logiche all'inizio del processo di compilazione e sostituiti con una costruzione equivalente con cui l'ottimizzatore è impostato per funzionare e su cui ragionare. L'ottimizzatore ha una serie di regole che rimuovono le sottoquery. Questi possono essere elencati per nome utilizzando la seguente query (il DMV di riferimento è minimamente documentato, ma non supportato):
SELECT name FROM sys.dm_exec_query_transformation_stats WHERE name LIKE 'RemoveSubq%';
Risultati (su SQL Server 2014):
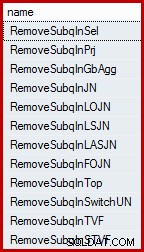
La query di test combinata ha due predicati ("selezioni" in termini relazionali) sulla tabella della cronologia, collegati da OR . Uno di questi predicati include una sottoquery. L'intero sottoalbero (sia i predicati che la sottoquery) viene trasformato dalla prima regola nell'elenco ("rimuovere la sottoquery nella selezione") in un semi-unione sull'unione dei singoli predicati. Sebbene non sia possibile rappresentare esattamente il risultato di questa trasformazione interna utilizzando la sintassi T-SQL, è abbastanza vicino a essere:
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE EXISTS
(
SELECT 1
WHERE TH.ProductID = 421
UNION ALL
SELECT 1
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
AND P.ProductID = TH.ProductID
)
OPTION (QUERYRULEOFF ApplyUAtoUniSJ); È un po' sfortunato che la mia approssimazione T-SQL dell'albero interno dopo la rimozione della sottoquery contenga una sottoquery, ma nel linguaggio del Query Processor non lo fa (è un semi join). Se preferisci vedere il modulo interno grezzo invece del mio tentativo di un equivalente T-SQL, ti assicuriamo che sarà momentaneamente disponibile.
Il suggerimento per la query non documentato incluso in T-SQL sopra serve per impedire una successiva trasformazione per quelli di voi che vogliono vedere la logica trasformata nel modulo del piano di esecuzione. Le annotazioni seguenti mostrano le posizioni dei due predicati dopo la trasformazione:
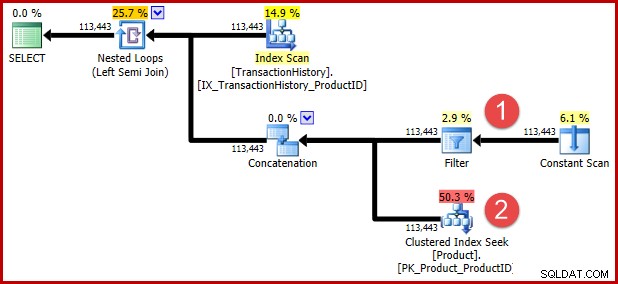
L'intuizione alla base della trasformazione è che una riga della cronologia si qualifica se uno dei predicati è soddisfatto. Indipendentemente da quanto tu possa trovare utile il mio T-SQL approssimativo e l'illustrazione del piano di esecuzione, spero che sia almeno ragionevolmente chiaro che la riscrittura esprima lo stesso requisito della query originale.
Dovrei sottolineare che l'ottimizzatore non genera letteralmente sintassi T-SQL alternativa o produce piani di esecuzione completi nelle fasi intermedie. Le rappresentazioni di T-SQL e del piano di esecuzione di cui sopra sono intese esclusivamente come ausilio alla comprensione. Se sei interessato ai dettagli grezzi, la rappresentazione interna promessa dell'albero delle query trasformato (leggermente modificato per chiarezza/spazio) è:
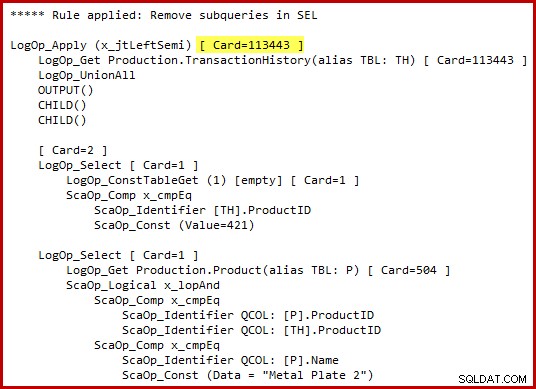
Si noti la stima della cardinalità di applicazione semi join evidenziata. Sono 113443 righe quando si utilizza lo stimatore di cardinalità 2014 (102099 righe se si utilizza il vecchio CE). Tieni presente che la tabella della cronologia di AdventureWorks contiene 113443 righe in totale, quindi questo rappresenta il 100% di selettività (90% per il vecchio CE).
Abbiamo visto in precedenza che l'applicazione di uno solo di questi predicati produce solo un piccolo numero di corrispondenze:19 righe per l'ID prodotto 421 e 13 righe (stimato 257) per "Metal Plate 2". Stima che la disgiunzione (OR) dei due predicati restituirà tutte le righe nella tabella di base sembra del tutto fuori di testa.
Dettagli bug
I dettagli del calcolo della selettività per il semi join sono visibili solo in SQL Server 2014 quando si usa il nuovo stimatore di cardinalità con il flag di traccia (non documentato) 2363. Probabilmente è possibile vedere qualcosa di simile con gli eventi estesi, ma l'output del flag di traccia è più conveniente da usare qui. La sezione pertinente dell'output è mostrata di seguito:
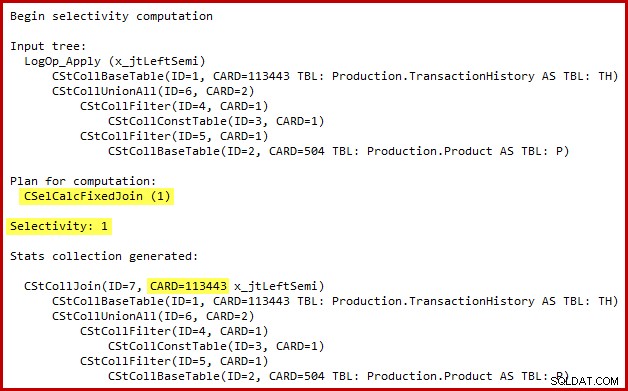
Lo stimatore di cardinalità utilizza il calcolatore Fixed Join con selettività del 100%. Di conseguenza, la cardinalità di output stimata del semi join è la stessa del suo input, il che significa che tutte le 113443 righe della tabella della cronologia dovrebbero essere qualificate.
L'esatta natura del bug è che il calcolo della selettività del semi join manca qualsiasi predicato posizionato oltre un'unione nell'albero di input. Nell'illustrazione seguente, la mancanza di predicati sul semi join stesso significa che ogni riga si qualificherà; ignora l'effetto dei predicati al di sotto della concatenazione (unione tutti).
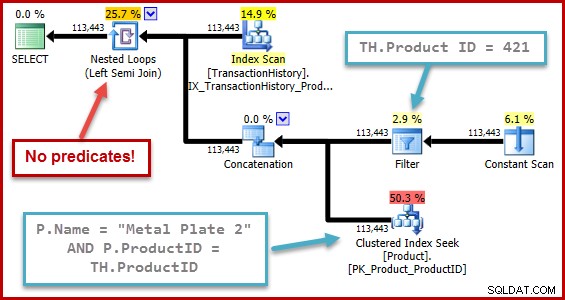
Questo comportamento è tanto più sorprendente se si considera che il calcolo della selettività sta operando su una rappresentazione ad albero che l'ottimizzatore stesso ha generato (la forma dell'albero e il posizionamento dei predicati è il risultato della rimozione della sottoquery).
Un problema simile si verifica con lo stimatore di cardinalità precedente al 2014, ma la stima finale è invece fissata al 90% dell'input di semi join stimato (per motivi divertenti relativi a una stima del predicato fissata inversa del 10% che è troppo di diversione per ottenere in).
Esempi
Come accennato in precedenza, questo bug si manifesta quando viene eseguita la stima per un semi join con predicati correlati posizionati oltre un union all. Se questa disposizione interna si verifica durante l'ottimizzazione della query dipende dalla sintassi T-SQL originale e dalla sequenza precisa delle operazioni di ottimizzazione interna. I seguenti esempi mostrano alcuni casi in cui il bug si verifica e non si verifica:
Esempio 1
Questo primo esempio incorpora una banale modifica alla query di test:
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = (SELECT 421) -- The only change
OR TH.ProductID =
(
SELECT P.ProductID
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
); Il piano di esecuzione stimato è:
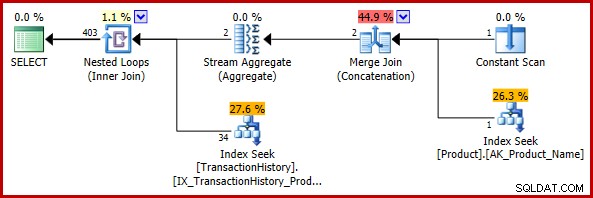
La stima finale di 403 righe non è coerente con le stime di input del join dei loop nidificati, ma è comunque ragionevole (nel senso discusso in precedenza). Se si fosse verificato il bug, la stima finale sarebbe 113443 righe (o 102099 righe quando si utilizza il modello CE precedente al 2014).
Esempio 2
Nel caso in cui stavi per affrettarti a riscrivere tutti i tuoi confronti costanti come banali sottoquery per evitare questo bug, guarda cosa succede se apportiamo un'altra banale modifica, questa volta sostituendo il test di uguaglianza nel secondo predicato con IN. Il significato della query rimane invariato:
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = (SELECT 421) -- Change 1
OR TH.ProductID IN -- Change 2
(
SELECT P.ProductID
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
); Il bug ritorna:
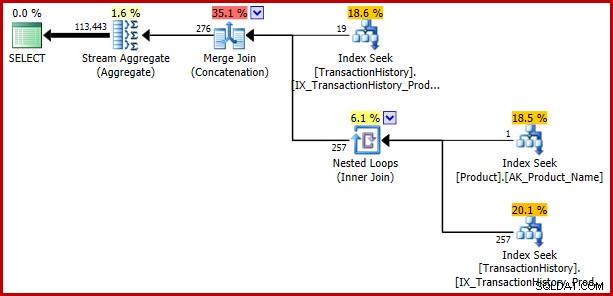
Esempio 3
Sebbene questo articolo si sia finora concentrato su un predicato disgiuntivo contenente una sottoquery, l'esempio seguente mostra che anche la stessa specifica di query espressa utilizzando EXISTS e UNION ALL è vulnerabile:
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE EXISTS
(
SELECT 1
WHERE TH.ProductID = 421
UNION ALL
SELECT 1
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
AND P.ProductID = TH.ProductID
); Piano di esecuzione:
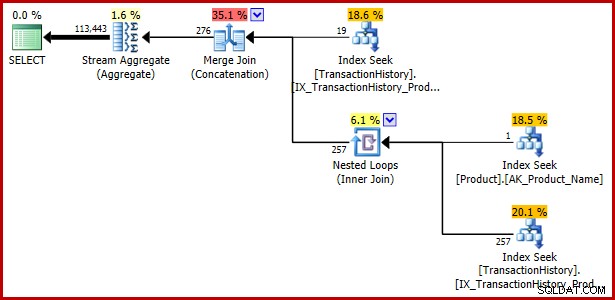
Esempio 4
Ecco altri due modi per esprimere la stessa query logica in T-SQL:
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = 421
UNION
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID =
(
SELECT P.ProductID
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
);
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = 421
UNION
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
JOIN Production.Product AS P
ON P.ProductID = TH.ProductID
AND P.Name = N'Metal Plate 2'; Nessuna delle query riscontra il bug ed entrambe producono lo stesso piano di esecuzione:
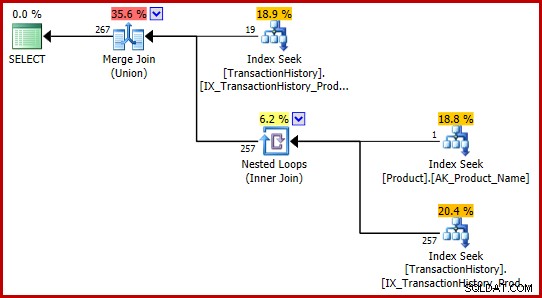
Queste formulazioni T-SQL producono un piano di esecuzione con stime del tutto coerenti (e ragionevoli).
Esempio 5
Ti starai chiedendo se la stima imprecisa è importante. Nei casi presentati finora, non lo è, almeno non direttamente. I problemi sorgono quando il bug si verifica in una query più ampia e la stima errata influisce sulle decisioni dell'ottimizzatore altrove. Come esempio minimamente esteso, considera di restituire i risultati della nostra query di test in un ordine casuale:
SELECT TH.TransactionID
FROM Production.TransactionHistory AS TH
WHERE TH.ProductID = 421
OR TH.ProductID =
(
SELECT P.ProductID
FROM Production.Product AS P
WHERE P.Name = N'Metal Plate 2'
)
ORDER BY NEWID(); -- New Il piano di esecuzione mostra che la stima errata influisce sulle operazioni successive. Ad esempio, è la base per la concessione di memoria riservata all'ordinamento:
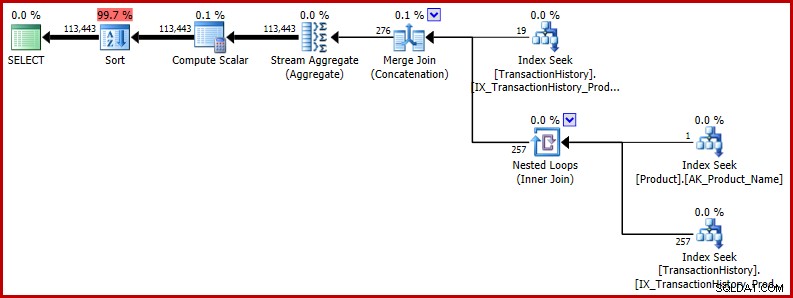
Se desideri vedere un esempio più reale del potenziale impatto di questo bug, dai un'occhiata a questa recente domanda di Richard Mansell sul sito di domande e risposte di SQLPerformance.com, answer.SQLPerformance.com.
Riepilogo e considerazioni finali
Questo bug viene attivato quando l'ottimizzatore esegue la stima della cardinalità per un semi join, in circostanze specifiche. È un bug difficile da individuare e aggirare per una serie di motivi:
- Non esiste una sintassi T-SQL esplicita per specificare un semi join, quindi è difficile sapere in anticipo se una particolare query sarà vulnerabile a questo bug.
- L'ottimizzatore può introdurre un semi join in un'ampia varietà di circostanze, non tutte ovvie candidate a semi join.
- Il problematico semi join viene spesso trasformato in qualcos'altro dalla successiva attività di ottimizzazione, quindi non possiamo nemmeno fare affidamento sulla presenza di un'operazione di semi join nel piano di esecuzione finale.
- Non tutte le stime di cardinalità dall'aspetto strano sono causate da questo bug. In effetti, molti esempi di questo tipo sono un effetto collaterale atteso e innocuo del normale funzionamento dell'ottimizzatore.
- La stima errata della selettività di semi join sarà sempre del 90% o del 100% del suo input, ma questo di solito non corrisponderà alla cardinalità di una tabella utilizzata nel piano. Inoltre, la cardinalità di input semi join utilizzata nel calcolo potrebbe non essere nemmeno visibile nel piano di esecuzione finale.
- In genere ci sono molti modi per esprimere la stessa query logica in T-SQL. Alcuni di questi attiveranno il bug, mentre altri no.
Queste considerazioni rendono difficile offrire consigli pratici per individuare o aggirare questo bug. Vale sicuramente la pena controllare i piani di esecuzione per stime "oltraggiose" e indagare su query con prestazioni molto peggiori del previsto, ma entrambi potrebbero avere cause non correlate a questo bug. Detto questo, vale la pena controllare in particolare le query che includono una disgiunzione di predicati e una sottoquery. Come mostrano gli esempi in questo articolo, questo non è l'unico modo per riscontrare il bug, ma mi aspetto che sia comune.
Se sei abbastanza fortunato da eseguire SQL Server 2014, con il nuovo stimatore di cardinalità abilitato, potresti essere in grado di confermare il bug controllando manualmente l'output del flag di traccia 2363 per una stima della selettività fissa del 100% su un semi join, ma questo è poco conveniente. Non vorrai utilizzare flag di traccia non documentati su un sistema di produzione, naturalmente.
La segnalazione di bug di User Voice per questo problema può essere trovata qui. Vota e commenta se desideri che questo problema venga esaminato (e possibilmente risolto).