SQL Server 2005 ha aggiunto la possibilità di includere colonne non chiave in un indice non cluster. In SQL Server 2000 e versioni precedenti, per un indice non cluster, tutte le colonne definite per un indice erano colonne chiave, il che significava che facevano parte di ogni livello dell'indice, dalla radice al livello foglia. Quando una colonna è definita come una colonna inclusa, fa parte solo del livello foglia. La documentazione in linea rileva i seguenti vantaggi delle colonne incluse:
- Possono essere tipi di dati non consentiti come colonne chiave di indice.
- Non vengono presi in considerazione dal Motore di database nel calcolo del numero di colonne della chiave di indice o della dimensione della chiave di indice.
Ad esempio, una colonna varchar(max) non può far parte di una chiave di indice, ma può essere una colonna inclusa. Inoltre, quella colonna varchar(max) non viene conteggiata nel limite di 900 byte (o 16 colonne) imposto per la chiave di indice.
La documentazione rileva anche il seguente vantaggio in termini di prestazioni:
Un indice con colonne non chiave può migliorare significativamente le prestazioni della query quando tutte le colonne della query sono incluse nell'indice come colonne chiave o non chiave. I guadagni in termini di prestazioni si ottengono perché Query Optimizer può individuare tutti i valori di colonna all'interno dell'indice; non si accede ai dati della tabella o dell'indice cluster con conseguente minor numero di operazioni di I/O del disco.Possiamo dedurre che se le colonne dell'indice sono colonne chiave o colonne non chiave, otteniamo un miglioramento delle prestazioni rispetto a quando tutte le colonne non fanno parte dell'indice. Ma c'è una differenza di prestazioni tra le due varianti?
La configurazione
Ho installato una copia del database AdventuresWork2012 e verificato gli indici per la tabella Sales.SalesOrderHeader utilizzando la versione di sp_helpindex di Kimberly Tripp:
USE [AdventureWorks2012]; GO EXEC sp_SQLskills_SQL2012_helpindex N'Sales.SalesOrderHeader';

Indici predefiniti per Sales.SalesOrderHeader
Inizieremo con una query semplice per il test che recupera i dati da più colonne:
SELECT [CustomerID], [SalesPersonID], [SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[SalesOrderHeader] WHERE [CustomerID] BETWEEN 11000 and 11200;
Se eseguiamo questa operazione sul database AdventureWorks2012 utilizzando SQL Sentry Plan Explorer e controlliamo il piano e l'output di I/O tabella, vediamo che otteniamo una scansione dell'indice cluster con 689 letture logiche:
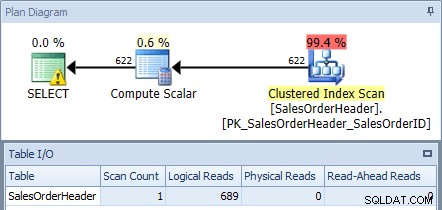
Piano di esecuzione dalla query originale
(In Management Studio, puoi vedere le metriche di I/O usando SET STATISTICS IO ON; .)
SELECT ha un'icona di avviso, perché l'ottimizzatore consiglia un indice per questa query:
USE [AdventureWorks2012]; GO CREATE NONCLUSTERED INDEX [<Name of Missing Index, sysname,>] ON [Sales].[SalesOrderHeader] ([CustomerID]) INCLUDE ([OrderDate],[ShipDate],[SalesPersonID],[SubTotal]);
Test 1
Creeremo prima l'indice consigliato dall'ottimizzatore (denominato NCI1_included), nonché la variazione con tutte le colonne come colonne chiave (denominate NCI1):
CREATE NONCLUSTERED INDEX [NCI1] ON [Sales].[SalesOrderHeader]([CustomerID], [SubTotal], [OrderDate], [ShipDate], [SalesPersonID]); GO CREATE NONCLUSTERED INDEX [NCI1_included] ON [Sales].[SalesOrderHeader]([CustomerID]) INCLUDE ([SubTotal], [OrderDate], [ShipDate], [SalesPersonID]); GO
Se eseguiamo nuovamente la query originale, una volta suggerita con NCI1 e una volta suggerita con NCI1_included, vediamo un piano simile all'originale, ma questa volta c'è una ricerca dell'indice di ogni indice non cluster, con valori equivalenti per la tabella I/ O, e costi simili (entrambi circa 0,006):
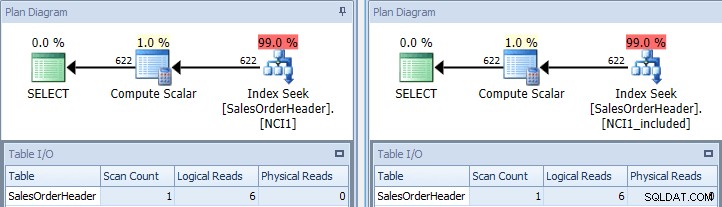
Query originale con ricerche di indice – chiave a sinistra, includi su il diritto
(Il conteggio delle scansioni è ancora 1 perché la ricerca dell'indice è in realtà una scansione dell'intervallo sotto mentite spoglie.)
Ora, il database AdventureWorks2012 non è rappresentativo di un database di produzione in termini di dimensioni e se osserviamo il numero di pagine in ciascun indice, vediamo che sono esattamente le stesse:
SELECT [Table] = N'SalesOrderHeader', [Index_ID] = [ps].[index_id], [Index] = [i].[name], [ps].[used_page_count], [ps].[row_count] FROM [sys].[dm_db_partition_stats] AS [ps] INNER JOIN [sys].[indexes] AS [i] ON [ps].[index_id] = [i].[index_id] AND [ps].[object_id] = [i].[object_id] WHERE [ps].[object_id] = OBJECT_ID(N'Sales.SalesOrderHeader');
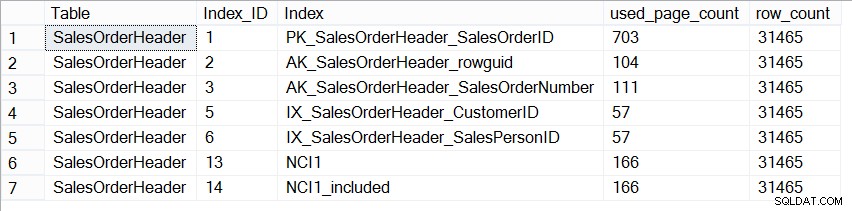
Dimensione degli indici su Sales.SalesOrderHeader
Se osserviamo le prestazioni, è l'ideale (e più divertente) testare con un set di dati più ampio.
Test 2
Ho una copia del database AdventureWorks2012 che ha una tabella SalesOrderHeader con oltre 200 milioni di righe (script QUI), quindi creiamo gli stessi indici non cluster in quel database ed eseguiamo nuovamente le query:
USE [AdventureWorks2012_Big]; GO CREATE NONCLUSTERED INDEX [Big_NCI1] ON [Sales].[Big_SalesOrderHeader](CustomerID, SubTotal, OrderDate, ShipDate, SalesPersonID); GO CREATE NONCLUSTERED INDEX [Big_NCI1_included] ON [Sales].[Big_SalesOrderHeader](CustomerID) INCLUDE (SubTotal, OrderDate, ShipDate, SalesPersonID); GO SELECT [CustomerID], [SalesPersonID],[SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[Big_SalesOrderHeader] WITH (INDEX (Big_NCI1)) WHERE [CustomerID] between 11000 and 11200; SELECT [CustomerID], [SalesPersonID],[SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[Big_SalesOrderHeader] WITH (INDEX (Big_NCI1_included)) WHERE [CustomerID] between 11000 and 11200;
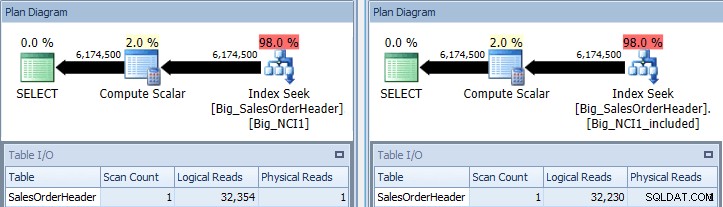
La query originale con index cerca Big_NCI1 (l) e Big_NCI1_Included ( r)
Ora otteniamo alcuni dati. La query restituisce oltre 6 milioni di righe e la ricerca di ciascun indice richiede poco più di 32.000 letture e il costo stimato è lo stesso per entrambe le query (31.233). Non ci sono ancora differenze di prestazioni e se controlliamo la dimensione degli indici, vediamo che l'indice con le colonne incluse ha 5.578 pagine in meno:
SELECT [Table] = N'Big_SalesOrderHeader', [Index_ID] = [ps].[index_id], [Index] = [i].[name], [ps].[used_page_count], [ps].[row_count] FROM [sys].[dm_db_partition_stats] AS [ps] INNER JOIN [sys].[indexes] AS [i] ON [ps].[index_id] = [i].[index_id] AND [ps].[object_id] = [i].[object_id] WHERE [ps].[object_id] = OBJECT_ID(N'Sales.Big_SalesOrderHeader');

Dimensione degli indici su Sales.Big_SalesOrderHeader
Se approfondiamo ulteriormente questo aspetto e controlliamo dm_dm_index_physical_stats, possiamo vedere che esiste una differenza nei livelli intermedi dell'indice:
SELECT
[ps].[index_id],
[Index] = [i].[name],
[ps].[index_type_desc],
[ps].[index_depth],
[ps].[index_level],
[ps].[page_count],
[ps].[record_count]
FROM [sys].[dm_db_index_physical_stats](DB_ID(),
OBJECT_ID('Sales.Big_SalesOrderHeader'), 5, NULL, 'DETAILED') AS [ps]
INNER JOIN [sys].[indexes] AS [i]
ON [ps].[index_id] = [i].[index_id]
AND [ps].[object_id] = [i].[object_id];
SELECT
[ps].[index_id],
[Index] = [i].[name],
[ps].[index_type_desc],
[ps].[index_depth],
[ps].[index_level],
[ps].[page_count],
[ps].[record_count]
FROM [sys].[dm_db_index_physical_stats](DB_ID(),
OBJECT_ID('Sales.Big_SalesOrderHeader'), 6, NULL, 'DETAILED') AS [ps]
INNER JOIN [sys].[indexes] [i]
ON [ps].[index_id] = [i].[index_id]
AND [ps].[object_id] = [i].[object_id];
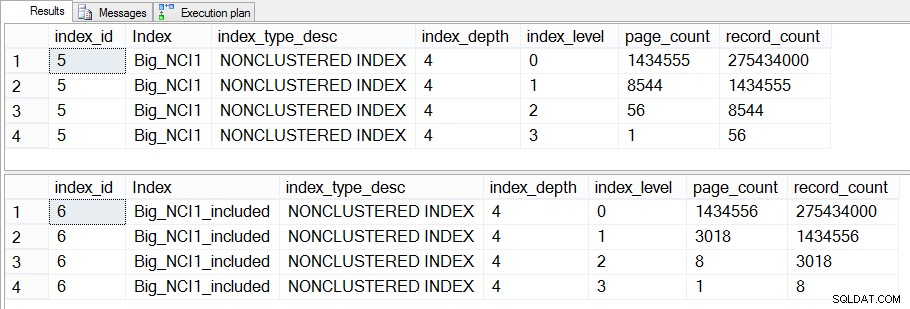
Dimensione degli indici (specifici del livello) su Sales.Big_SalesOrderHeader
La differenza tra i livelli intermedi dei due indici è di 43 MB, il che potrebbe non essere significativo, ma probabilmente sarei comunque propenso a creare l'indice con le colonne incluse per risparmiare spazio, sia su disco che in memoria. Dal punto di vista della query, non vediamo ancora un grande cambiamento nelle prestazioni tra l'indice con tutte le colonne nella chiave e l'indice con le colonne incluse.
Test 3
Per questo test, cambiamo la query e aggiungiamo un filtro per [SubTotal] >= 100 alla clausola WHERE:
SELECT [CustomerID],[SalesPersonID],[SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[Big_SalesOrderHeader] WITH (INDEX (Big_NCI1)) WHERE CustomerID = 11091 AND [SubTotal] >= 100; SELECT [CustomerID], [SalesPersonID],[SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[Big_SalesOrderHeader] WITH (INDEX (Big_NCI1_included)) WHERE CustomerID = 11091 AND [SubTotal] >= 100;
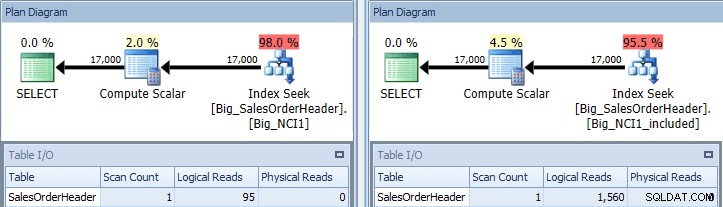
Piano di esecuzione della query con predicato SubTotal su entrambi gli indici
Ora vediamo una differenza nell'I/O (95 letture contro 1.560), nel costo (0,848 contro 1,55) e una differenza sottile ma degna di nota nel piano di query. Quando si utilizza l'indice con tutte le colonne della chiave, il predicato di ricerca è CustomerID e SubTotal:
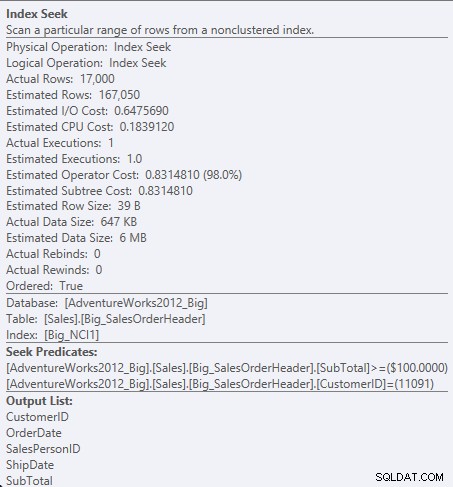
Cerca un predicato contro NCI1
Poiché SubTotal è la seconda colonna nella chiave dell'indice, i dati vengono ordinati e il SubTotal esiste nei livelli intermedi dell'indice. Il motore è in grado di cercare direttamente il primo record con CustomerID 11091 e SubTotal maggiore o uguale a 100, quindi leggere l'indice fino a quando non esistono più record per CustomerID 11091.
Per l'indice con le colonne incluse, SubTotal esiste solo a livello foglia dell'indice, quindi CustomerID è il predicato di ricerca e SubTotal è un predicato residuo (solo elencato come Predicate nella schermata):
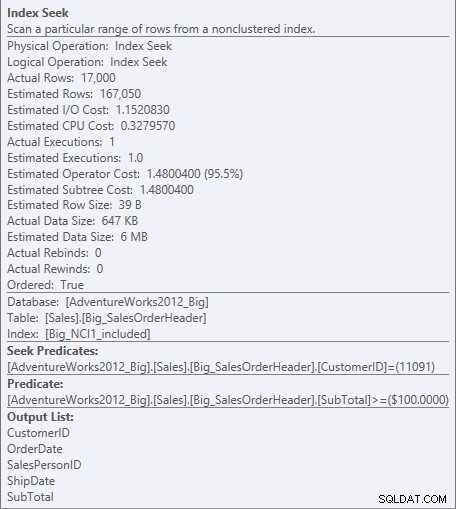
Cerca predicato e predicato residuo contro NCI1_included
Il motore può cercare direttamente il primo record in cui CustomerID è 11091, ma poi deve esaminare ogni record per CustomerID 11091 per vedere se il SubTotal è 100 o superiore, perché i dati sono ordinati per CustomerID e SalesOrderID (chiave di cluster).
Test 4
Proveremo un'altra variante della nostra query e questa volta aggiungeremo un ORDINE PER:
SELECT [CustomerID],[SalesPersonID],[SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[Big_SalesOrderHeader] WITH (INDEX (Big_NCI1)) WHERE CustomerID = 11091 ORDER BY [SubTotal]; SELECT [CustomerID],[SalesPersonID],[SalesOrderID], DATEDIFF(DAY, [OrderDate], [ShipDate]) AS [DaysToShip], [SubTotal] FROM [Sales].[Big_SalesOrderHeader] WITH (INDEX (Big_NCI1_included)) WHERE CustomerID = 11091 ORDER BY [SubTotal];
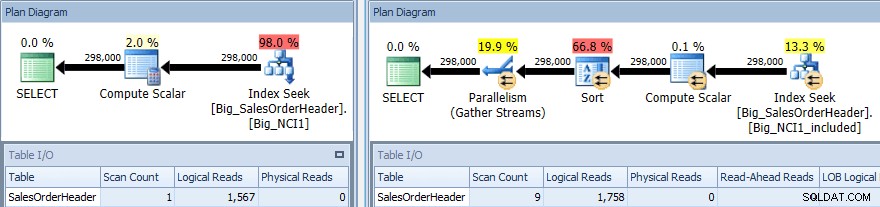
Piano di esecuzione della query con SORT su entrambi gli indici
Anche in questo caso abbiamo un cambiamento nell'I/O (sebbene molto lieve), un cambiamento nel costo (1,5 vs 9,3) e un cambiamento molto più grande nella forma del piano; vediamo anche un numero maggiore di scansioni (1 vs 9). La query richiede che i dati siano ordinati per SubTotal; quando SubTotal fa parte della chiave di indice viene ordinato, quindi quando vengono recuperati i record per CustomerID 11091, sono già nell'ordine richiesto.
Quando SubTotal esiste come colonna inclusa, i record per CustomerID 11091 devono essere ordinati prima di poter essere restituiti all'utente, pertanto l'ottimizzatore interpone un operatore di ordinamento nella query. Di conseguenza, la query che utilizza l'indice Big_NCI1_included richiede (e riceve) anche una concessione di memoria di 29.312 KB, che è notevole (e si trova nelle proprietà del piano).
Riepilogo
La domanda originale a cui volevamo rispondere era se avremmo riscontrato una differenza di prestazioni quando una query utilizzava l'indice con tutte le colonne nella chiave, rispetto all'indice con la maggior parte delle colonne incluse nel livello foglia. Nella nostra prima serie di test non c'era differenza, ma nel nostro terzo e quarto test c'era. Alla fine dipende dalla query. Abbiamo esaminato solo due varianti:una aveva un predicato aggiuntivo, l'altra aveva un ORDER BY:ne esistono molte di più.
Quello che gli sviluppatori e i DBA devono capire è che ci sono alcuni grandi vantaggi nell'includere le colonne in un indice, ma non sempre avranno le stesse prestazioni degli indici che hanno tutte le colonne nella chiave. Potrebbe essere allettante spostare le colonne che non fanno parte di predicati e join fuori dalla chiave e includerle semplicemente per ridurre le dimensioni complessive dell'indice. Tuttavia, in alcuni casi ciò richiede più risorse per l'esecuzione della query e può ridurre le prestazioni. Il degrado può essere insignificante; potrebbe non essere... non lo saprai finché non esegui il test. Pertanto, quando si progetta un indice, è importante pensare alle colonne dopo quella principale e capire se devono far parte della chiave (ad es. perché mantenere i dati ordinati fornirà vantaggi) o se possono servire al loro scopo in quanto inclusi colonne.
Come è tipico con l'indicizzazione in SQL Server, è necessario testare le query con gli indici per determinare la strategia migliore. Rimane un'arte e una scienza:cercare di trovare il numero minimo di indici per soddisfare il maggior numero possibile di query.



