Le prestazioni sono estremamente importanti in molti prodotti di consumo come e-commerce, sistemi di pagamento, giochi, app di trasporto e così via. Sebbene i database siano internamente ottimizzati attraverso molteplici meccanismi per soddisfare i loro requisiti di prestazioni nel mondo moderno, molto dipende anche dallo sviluppatore dell'applicazione:dopotutto, solo uno sviluppatore sa quali query deve eseguire l'applicazione.
Gli sviluppatori che si occupano di database relazionali hanno usato o almeno sentito parlare dell'indicizzazione, ed è un concetto molto comune nel mondo dei database. Tuttavia, la parte più importante è capire cosa indicizzare e come l'indicizzazione aumenterà il tempo di risposta della query. Per fare ciò è necessario capire come interrogare le tabelle del database. È possibile creare un indice corretto solo quando si conosce esattamente l'aspetto delle query e dei modelli di accesso ai dati.
In una terminologia semplice, un indice associa le chiavi di ricerca ai dati corrispondenti su disco utilizzando diverse strutture di dati in memoria e su disco. L'indice viene utilizzato per velocizzare la ricerca riducendo il numero di record da cercare.
Per lo più viene creato un indice sulle colonne specificate in WHERE clausola di una query poiché il database recupera e filtra i dati dalle tabelle in base a tali colonne. Se non crei un indice, il database esegue la scansione di tutte le righe, filtra le righe corrispondenti e restituisce il risultato. Con milioni di record, questa operazione di scansione può richiedere molti secondi e questo tempo di risposta elevato rende le API e le applicazioni più lente e inutilizzabili. Vediamo un esempio —
Utilizzeremo MySQL con un motore di database InnoDB predefinito, sebbene i concetti spiegati in questo articolo siano più o meno gli stessi in altri server di database come Oracle, MSSQL ecc.
Crea una tabella chiamata index_demo con il seguente schema:
CREATE TABLE index_demo (
name VARCHAR(20) NOT NULL,
age INT,
pan_no VARCHAR(20),
phone_no VARCHAR(20)
);Come verifichiamo che stiamo utilizzando il motore InnoDB?
Esegui il comando seguente:
SHOW TABLE STATUS WHERE name = 'index_demo' \G;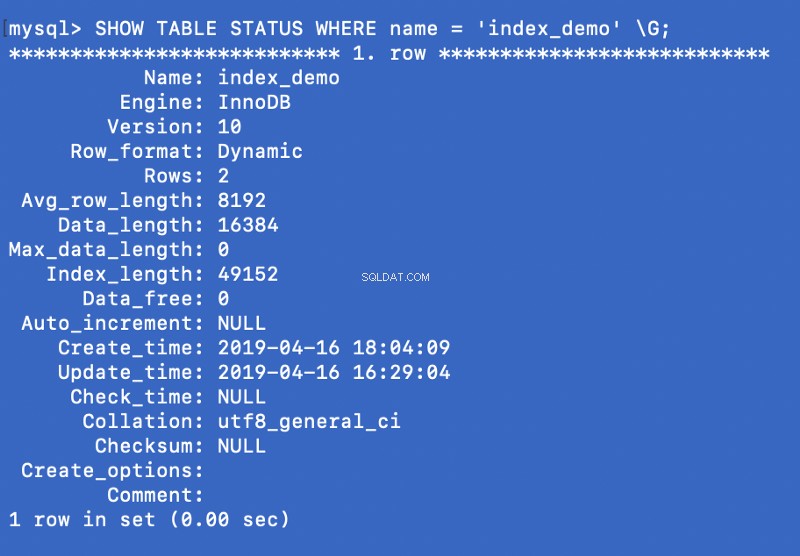
Il Engine la colonna nella schermata sopra rappresenta il motore utilizzato per creare la tabella. Qui InnoDB viene utilizzato.
Ora inserisci alcuni dati casuali nella tabella, la mia tabella con 5 righe è simile alla seguente:
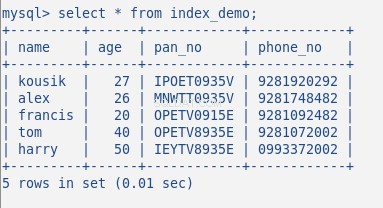
Non ho creato alcun indice fino ad ora su questa tabella. Verifichiamolo con il comando:SHOW INDEX . Restituisce 0 risultati.

In questo momento, se eseguiamo un semplice SELECT query, poiché non esiste un indice definito dall'utente, la query eseguirà la scansione dell'intera tabella per scoprire il risultato:
EXPLAIN SELECT * FROM index_demo WHERE name = 'alex';
EXPLAIN mostra come il motore di query prevede di eseguire la query. Nello screenshot sopra, puoi vedere che le rows la colonna restituisce 5 &possible_keys restituisce null . possible_keys rappresenta quali sono tutti gli indici disponibili che possono essere utilizzati in questa query. La key colonna rappresenta quale indice verrà effettivamente utilizzato tra tutti i possibili indici in questa query.
Chiave primaria:
La query di cui sopra è molto inefficiente. Ottimizziamo questa query. Faremo il phone_no colonna a PRIMARY KEY supponendo che nel nostro sistema non possano esistere due utenti con lo stesso numero di telefono. Tenere in considerazione quanto segue durante la creazione di una chiave primaria:
- Una chiave primaria dovrebbe far parte di molte query vitali nella tua applicazione.
- La chiave primaria è un vincolo che identifica in modo univoco ogni riga di una tabella. Se più colonne fanno parte della chiave primaria, tale combinazione dovrebbe essere univoca per ogni riga.
- La chiave primaria dovrebbe essere non Null. Non rendere mai i campi null-able come chiave primaria. Secondo gli standard ANSI SQL, le chiavi primarie dovrebbero essere comparabili tra loro e dovresti essere sicuramente in grado di dire se il valore della colonna della chiave primaria per una determinata riga è maggiore, minore o uguale allo stesso dall'altra riga. Da
NULLsignifica un valore non definito negli standard SQL, non puoi confrontare deterministicamenteNULLcon qualsiasi altro valore, quindi logicamenteNULLnon è consentito. - Il tipo di chiave primaria ideale dovrebbe essere un numero come
INToBIGINTpoiché i confronti interi sono più veloci, quindi attraversare l'indice sarà molto veloce.
Spesso definiamo un id campo come AUTO INCREMENT nelle tabelle e usala come chiave primaria, ma la scelta di una chiave primaria dipende dagli sviluppatori.
E se non crei tu stesso alcuna chiave primaria?
Non è obbligatorio creare tu stesso una chiave primaria. Se non hai definito alcuna chiave primaria, InnoDB ne crea implicitamente una per te perché InnoDB in base alla progettazione deve avere una chiave primaria in ogni tabella. Quindi, una volta creata una chiave primaria in seguito per quella tabella, InnoDB elimina la chiave primaria precedentemente definita automaticamente.
Dal momento che al momento non abbiamo alcuna chiave primaria definita, vediamo cosa InnoDB ha creato per noi di default:
SHOW EXTENDED INDEX FROM index_demo;
EXTENDED mostra tutti gli indici non utilizzabili dall'utente ma gestiti completamente da MySQL.
Qui vediamo che MySQL ha definito un indice composito (di cui parleremo più avanti) su DB_ROW_ID , DB_TRX_ID , DB_ROLL_PTR e tutte le colonne definite nella tabella. In assenza di una chiave primaria definita dall'utente, questo indice viene utilizzato per trovare i record in modo univoco.
Qual è la differenza tra chiave e indice?
Sebbene i termini key &index sono usati in modo intercambiabile, key significa un vincolo imposto al comportamento della colonna. In questo caso, il vincolo è che la chiave primaria è un campo non nullo che identifica in modo univoco ogni riga. D'altra parte, index è una struttura dati speciale che facilita la ricerca dei dati nella tabella.
Creiamo ora l'indice principale su phone_no &esamina l'indice creato:
ALTER TABLE index_demo ADD PRIMARY KEY (phone_no);
SHOW INDEXES FROM index_demo;
Nota che CREATE INDEX non può essere utilizzato per creare un indice primario, ma ALTER TABLE viene utilizzato.

Nello screenshot sopra, vediamo che viene creato un indice primario nella colonna phone_no . Le colonne delle seguenti immagini sono descritte come segue:
Table :la tabella su cui viene creato l'indice.
Non_unique :Se il valore è 1, l'indice non è univoco, se il valore è 0, l'indice è univoco.
Key_name :il nome dell'indice creato. Il nome dell'indice primario è sempre PRIMARY in MySQL, indipendentemente dal fatto che tu abbia fornito o meno un nome di indice durante la creazione dell'indice.
Seq_in_index :il numero di sequenza della colonna nell'indice. Se più colonne fanno parte dell'indice, il numero di sequenza verrà assegnato in base a come le colonne sono state ordinate durante il tempo di creazione dell'indice. Il numero di sequenza inizia da 1.
Collation :come è ordinata la colonna nell'indice. A significa ascendente, D significa discendente, NULL significa non ordinato.
Cardinality :il numero stimato di valori univoci nell'indice. Maggiore cardinalità significa maggiori possibilità che Query Optimizer scelga l'indice per le query.
Sub_part :Il prefisso dell'indice. È NULL se l'intera colonna è indicizzata. In caso contrario, mostra il numero di byte indicizzati nel caso in cui la colonna sia parzialmente indicizzata. Definiremo l'indice parziale in seguito.
Packed :Indica come è imballata la chiave; NULL se non lo è.
Null :YES se la colonna può contenere NULL valori e vuoto in caso contrario.
Index_type :indica quale struttura dati di indicizzazione viene utilizzata per questo indice. Alcuni possibili candidati sono — BTREE , HASH , RTREE o FULLTEXT .
Comment :le informazioni sull'indice non descritte nella propria colonna.
Index_comment :Il commento per l'indice specificato quando hai creato l'indice con il COMMENT attributo.
Ora vediamo se questo indice riduce il numero di righe che verranno cercate per un dato phone_no nel WHERE clausola di una query.
EXPLAIN SELECT * FROM index_demo WHERE phone_no = '9281072002';
In questa istantanea, nota che le rows la colonna ha restituito 1 solo, i possible_keys &key entrambi restituiscono PRIMARY . Quindi essenzialmente significa che usando l'indice primario chiamato PRIMARY (il nome viene assegnato automaticamente quando crei la chiave primaria), Query Optimizer va direttamente al record e lo recupera. È molto efficiente. Questo è esattamente lo scopo di un indice:ridurre al minimo l'ambito di ricerca al costo di spazio aggiuntivo.
Indice cluster:
Un clustered index è collocato con i dati nello stesso tablespace o nello stesso file su disco. Puoi considerare che un indice cluster è un B-Tree index i cui nodi foglia sono i blocchi di dati effettivi su disco, poiché l'indice e i dati risiedono insieme. Questo tipo di indice organizza fisicamente i dati su disco secondo l'ordine logico della chiave di indice.
Cosa significa organizzazione fisica dei dati?
Fisicamente, i dati sono organizzati su disco in migliaia o milioni di dischi/blocchi di dati. Per un indice cluster, non è obbligatorio che tutti i blocchi del disco siano archiviati in modo contagioso. I blocchi di dati fisici vengono continuamente spostati qua e là dal sistema operativo ogni volta che è necessario. Un sistema di database non ha alcun controllo assoluto su come viene gestito lo spazio fisico dei dati, ma all'interno di un blocco di dati, i record possono essere archiviati o gestiti nell'ordine logico della chiave di indice. Il seguente diagramma semplificato lo spiega:
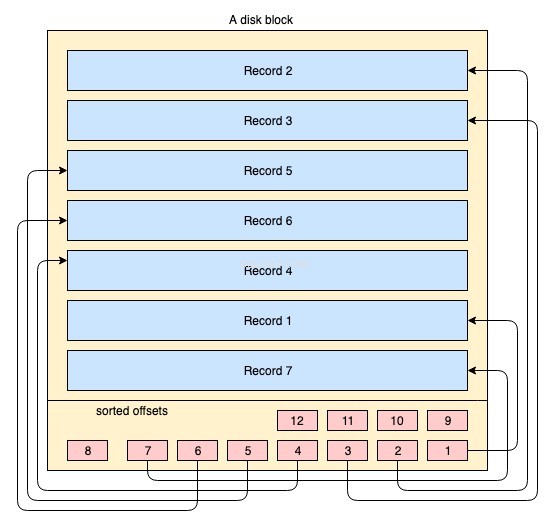
- Il grande rettangolo di colore giallo rappresenta un blocco disco/blocco dati
- i rettangoli di colore blu rappresentano i dati archiviati come righe all'interno di quel blocco
- l'area del piè di pagina rappresenta l'indice del blocco in cui risiedono piccoli rettangoli di colore rosso nell'ordine di una chiave particolare. Questi piccoli blocchi non sono altro che una sorta di puntatori che puntano a offset dei record.
I record vengono archiviati sul blocco del disco in qualsiasi ordine arbitrario. Ogni volta che vengono aggiunti nuovi record, vengono aggiunti nel successivo spazio disponibile. Ogni volta che un record esistente viene aggiornato, il sistema operativo decide se quel record può ancora rientrare nella stessa posizione o se deve essere assegnata una nuova posizione per quel record.
Quindi la posizione dei record è completamente gestita dal sistema operativo e non esiste alcuna relazione definita tra l'ordine di due record qualsiasi. Per recuperare i record nell'ordine logico della chiave, le pagine del disco contengono una sezione di indice nel piè di pagina, l'indice contiene un elenco di puntatori di offset nell'ordine della chiave. Ogni volta che un record viene modificato o creato, l'indice viene modificato.
In questo modo, non devi preoccuparti di organizzare effettivamente il record fisico in un certo ordine, ma viene mantenuta una piccola sezione di indice in quell'ordine e il recupero o il mantenimento dei record diventa molto semplice.
Vantaggio dell'indice cluster:
Questo ordinamento o co-ubicazione dei dati correlati rende effettivamente più veloce un indice cluster. Quando i dati vengono recuperati dal disco, il blocco completo contenente i dati viene letto dal sistema poiché il nostro sistema di I/O del disco scrive e legge i dati in blocchi. Quindi, in caso di query di intervallo, è del tutto possibile che i dati collocati siano inseriti nel buffer in memoria. Supponi di attivare la seguente query:
SELECT * FROM index_demo WHERE phone_no > '9010000000' AND phone_no < '9020000000'
Un blocco di dati viene recuperato in memoria quando viene eseguita la query. Supponiamo che il blocco dati contenga phone_no nell'intervallo da 9010000000 a 9030000000 . Quindi, qualunque intervallo tu abbia richiesto nella query è solo un sottoinsieme dei dati presenti nel blocco. Se ora attivi la query successiva per ottenere tutti i numeri di telefono nell'intervallo, ad esempio da 9015000000 a 9019000000 , non è necessario recuperare altri blocchi dal disco. I dati completi possono essere trovati nel blocco di dati corrente, quindi clustered_index riduce il numero di IO del disco collocando i dati correlati il più possibile nello stesso blocco di dati. Questa riduzione dell'IO del disco provoca un miglioramento delle prestazioni.
Quindi, se hai una buona idea della chiave primaria e le tue query sono basate sulla chiave primaria, le prestazioni saranno super veloci.
Vincoli dell'indice cluster:
Poiché un indice cluster influisce sull'organizzazione fisica dei dati, può esserci un solo indice cluster per tabella.
Relazione tra chiave primaria e indice cluster:
Non è possibile creare manualmente un indice cluster utilizzando InnoDB in MySQL. MySQL lo sceglie per te. Ma come sceglie? I seguenti estratti provengono dalla documentazione di MySQL:
Quando definisci unaPRIMARY KEYsul tuo tavolo,InnoDBlo usa come indice cluster. Definisci una chiave primaria per ogni tabella che crei. Se non sono presenti colonne o set di colonne logiche univoche e non nulle, aggiungere una nuova colonna con incremento automatico, i cui valori vengono compilati automaticamente.
Se non si definisce unaPRIMARY KEYper la tua tabella, MySQL individua il primoUNIQUEindex dove tutte le colonne chiave sonoNOT NULLeInnoDBlo usa come indice cluster.
Se la tabella non haPRIMARY KEYoUNIQUEadatto indice,InnoDBgenera internamente un indice cluster nascosto denominatoGEN_CLUST_INDEXsu una colonna sintetica contenente valori ID riga. Le righe sono ordinate in base all'ID cheInnoDBassegna alle righe in tale tabella. L'ID riga è un campo di 6 byte che aumenta in modo monotono quando vengono inserite nuove righe. Pertanto, le righe ordinate in base all'ID riga sono fisicamente nell'ordine di inserimento.
In breve, il motore MySQL InnoDB gestisce effettivamente l'indice primario come indice cluster per migliorare le prestazioni, quindi la chiave primaria e il record effettivo su disco sono raggruppati insieme.
Struttura dell'indice della chiave primaria (cluster):
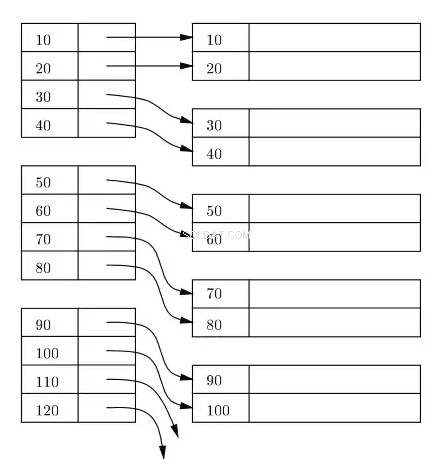
Un indice viene generalmente mantenuto come un albero B+ su disco e in memoria e qualsiasi indice viene archiviato in blocchi su disco. Questi blocchi sono chiamati blocchi di indice. Le voci nel blocco dell'indice sono sempre ordinate in base all'indice/chiave di ricerca. Il blocco dell'indice foglia dell'indice contiene un localizzatore di riga. Per l'indice primario, il localizzatore di riga si riferisce all'indirizzo virtuale della posizione fisica corrispondente dei blocchi di dati sul disco in cui risiedono le righe ordinate secondo la chiave dell'indice.
Nel diagramma seguente, i rettangoli di sinistra rappresentano i blocchi di indice a livello di foglia e i rettangoli di destra rappresentano i blocchi di dati. Logicamente i blocchi di dati sembrano essere allineati in un ordine ordinato, ma come già descritto in precedenza, le posizioni fisiche effettive potrebbero essere sparse qua e là.
È possibile creare un indice primario su una chiave non primaria?
In MySQL, viene creato automaticamente un indice primario e abbiamo già descritto in precedenza come MySQL sceglie l'indice primario. Ma nel mondo dei database, in realtà non è necessario creare un indice sulla colonna della chiave primaria:l'indice primario può essere creato anche su qualsiasi colonna della chiave non primaria. Ma quando vengono create sulla chiave primaria, tutte le voci di chiave sono univoche nell'indice, mentre nell'altro caso, anche l'indice primario potrebbe avere una chiave duplicata.
È possibile eliminare una chiave primaria?
È possibile eliminare una chiave primaria. Quando elimini una chiave primaria, l'indice cluster correlato e la proprietà di unicità di quella colonna vengono persi.
ALTER TABLE `index_demo` DROP PRIMARY KEY;
- If the primary key does not exist, you get the following error:
"ERROR 1091 (42000): Can't DROP 'PRIMARY'; check that column/key exists"Vantaggi dell'indice primario:
- Le query di intervallo basate sull'indice primario sono molto efficienti. Potrebbe esserci la possibilità che il blocco del disco che il database ha letto dal disco contenga tutti i dati appartenenti alla query, poiché l'indice primario è raggruppato e i record sono ordinati fisicamente. Quindi la località dei dati può essere fornita dall'indice primario.
- Qualsiasi query che sfrutti la chiave primaria è molto veloce.
Svantaggi dell'indice primario:
- Poiché l'indice primario contiene un riferimento diretto all'indirizzo del blocco dati tramite lo spazio degli indirizzi virtuali e i blocchi del disco sono organizzati fisicamente nell'ordine della chiave dell'indice, ogni volta che il sistema operativo esegue una divisione della pagina del disco a causa di
DMLoperazioni comeINSERT/UPDATE/DELETE, anche l'indice primario deve essere aggiornato. QuindiDMLoperazioni esercita una certa pressione sulla performance dell'indice primario.
Indice secondario:
Qualsiasi indice diverso da un indice cluster viene chiamato indice secondario. Gli indici secondari non influiscono sulle posizioni di archiviazione fisiche a differenza degli indici primari.
Quando hai bisogno di un indice secondario?
Potresti avere diversi casi d'uso nella tua applicazione in cui non esegui query sul database con una chiave primaria. Nel nostro esempio phone_no è la chiave primaria ma potrebbe essere necessario interrogare il database con pan_no o name . In questi casi sono necessari indici secondari su queste colonne se la frequenza di tali query è molto alta.
Come creare un indice secondario in MySQL?
Il comando seguente crea un indice secondario nel name colonna nella index_demo tabella.
CREATE INDEX secondary_idx_1 ON index_demo (name);
Struttura dell'indice secondario:
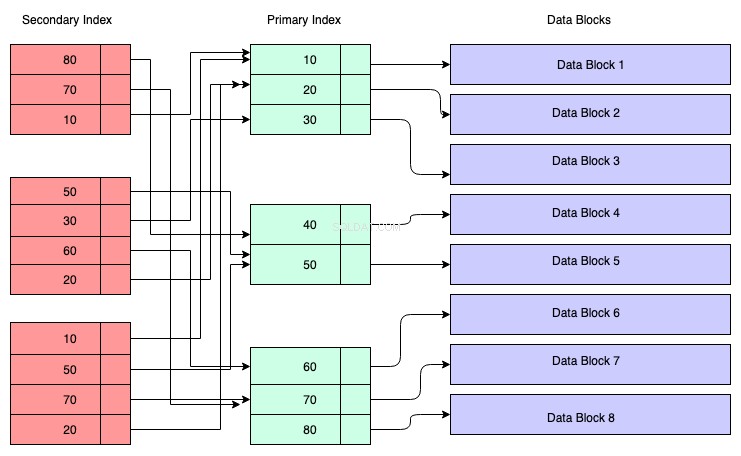
Nel diagramma seguente, i rettangoli di colore rosso rappresentano i blocchi di indice secondari. Anche l'indice secondario viene mantenuto nell'albero B+ ed è ordinato in base alla chiave su cui è stato creato l'indice. I nodi foglia contengono una copia della chiave dei dati corrispondenti nell'indice primario.
Quindi, per capire, puoi presumere che l'indice secondario abbia riferimento all'indirizzo della chiave primaria, sebbene non sia il caso. Il recupero dei dati tramite l'indice secondario significa che devi attraversare due alberi B+:uno è l'albero B+ dell'indice secondario stesso e l'altro è l'albero B+ dell'indice primario.
Vantaggi di un indice secondario:
Logicamente puoi creare tutti gli indici secondari che vuoi. Ma in realtà quanti indici sono effettivamente necessari richiede un serio processo di riflessione poiché ogni indice ha la sua penalità.
Svantaggi di un indice secondario:
Con DML operazioni come DELETE / INSERT , anche l'indice secondario deve essere aggiornato in modo da poter eliminare/inserire la copia della colonna della chiave primaria. In questi casi, l'esistenza di molti indici secondari può creare problemi.
Inoltre, se una chiave primaria è molto grande come un URL , poiché gli indici secondari contengono una copia del valore della colonna della chiave primaria, può essere inefficiente in termini di spazio di archiviazione. Più chiavi secondarie significano un numero maggiore di copie duplicate del valore della colonna della chiave primaria, quindi più spazio di archiviazione in caso di una chiave primaria di grandi dimensioni. Anche la chiave primaria stessa memorizza le chiavi, quindi l'effetto combinato sulla memoria sarà molto elevato.
Considerazione prima di eliminare un indice primario:
In MySQL, puoi eliminare un indice primario eliminando la chiave primaria. Abbiamo già visto che un indice secondario dipende da un indice primario. Quindi, se elimini un indice primario, tutti gli indici secondari devono essere aggiornati per contenere una copia della nuova chiave dell'indice primario che MySQL regola automaticamente.
Questo processo è costoso quando esistono diversi indici secondari. Anche altre tabelle potrebbero avere un riferimento di chiave esterna alla chiave primaria, quindi è necessario eliminare quei riferimenti di chiave esterna prima di eliminare la chiave primaria.
Quando una chiave primaria viene eliminata, MySQL crea automaticamente un'altra chiave primaria internamente e si tratta di un'operazione costosa.
Indice chiave UNICO:
Come le chiavi primarie, anche le chiavi univoche possono identificare i record in modo univoco con una differenza:la colonna della chiave univoca può contenere null valori.
A differenza di altri server di database, in MySQL una colonna chiave univoca può avere altrettanti null valori possibili. Nello standard SQL, null indica un valore indefinito. Quindi se MySQL deve contenere solo un null valore in una colonna chiave univoca, deve presumere che tutti i valori null siano gli stessi.
Ma logicamente questo non è corretto poiché null significa indefinito — e i valori indefiniti non possono essere confrontati tra loro, è la natura di null . Poiché MySQL non può affermare se tutto null significa lo stesso, consente più null valori nella colonna.
Il comando seguente mostra come creare un indice di chiave univoco in MySQL:
CREATE UNIQUE INDEX unique_idx_1 ON index_demo (pan_no);
Indice composito:
MySQL ti consente di definire indici su più colonne, fino a 16 colonne. Questo indice è chiamato indice multicolonna/composito/composto.
Supponiamo di avere un indice definito su 4 colonne — col1 , col2 , col3 , col4 . Con un indice composto, abbiamo capacità di ricerca su col1 , (col1, col2) , (col1, col2, col3) , (col1, col2, col3, col4) . Quindi possiamo usare qualsiasi prefisso sul lato sinistro delle colonne indicizzate, ma non possiamo omettere una colonna dal centro e usarla come — (col1, col3) o (col1, col2, col4) o col3 o col4 ecc. Queste sono combinazioni non valide.
I seguenti comandi creano 2 indici compositi nella nostra tabella:
CREATE INDEX composite_index_1 ON index_demo (phone_no, name, age);
CREATE INDEX composite_index_2 ON index_demo (pan_no, name, age);
Se hai domande contenenti un WHERE clausola su più colonne, scrivi la clausola nell'ordine delle colonne dell'indice composito. L'indice gioverà a quella query. Infatti, mentre decidi le colonne per un indice composito, puoi analizzare diversi casi d'uso del tuo sistema e provare a trovare l'ordine delle colonne che andrà a vantaggio della maggior parte dei tuoi casi d'uso.
Gli indici compositi possono aiutarti in JOIN &SELECT anche le domande. Esempio:nel seguente SELECT * query, composite_index_2 viene utilizzato.

Quando vengono definiti diversi indici, Query Optimizer MySQL sceglie l'indice che elimina il maggior numero di righe o esegue la scansione del minor numero possibile di righe per una migliore efficienza.
Perché usiamo indici compositi ? Perché non definire più indici secondari sulle colonne che ci interessano?
MySQL utilizza un solo indice per tabella per query eccetto UNION. (In una UNION, ogni query logica viene eseguita separatamente e i risultati vengono uniti.) Quindi la definizione di più indici su più colonne non garantisce che tali indici verranno utilizzati anche se fanno parte della query.
MySQL mantiene qualcosa chiamato statistiche dell'indice che aiuta MySQL a dedurre come appaiono i dati nel sistema. Tuttavia, le statistiche dell'indice sono una generalizzazione, ma sulla base di questi metadati, MySQL decide quale indice è appropriato per la query corrente.
Come funziona l'indice composito?
Le colonne utilizzate negli indici compositi vengono concatenate insieme e le chiavi concatenate vengono archiviate in ordine utilizzando un albero B+. Quando si esegue una ricerca, la concatenazione delle chiavi di ricerca viene confrontata con quelle dell'indice composto. Quindi, se c'è una discrepanza tra l'ordine delle chiavi di ricerca e l'ordine delle colonne dell'indice composito, l'indice non può essere utilizzato.
Nel nostro esempio, per il record seguente, viene formata una chiave di indice composita concatenando pan_no , name , age — HJKXS9086Wkousik28 .
+--------+------+------------+------------+
name
age
pan_no
phone_no
+--------+------+------------+------------+
kousik
28
HJKXS9086W
9090909090Come identificare se hai bisogno di un indice composito:
- Analizza prima le tue query in base ai tuoi casi d'uso. Se vedi che determinati campi vengono visualizzati insieme in molte query, potresti prendere in considerazione la creazione di un indice composito.
- Se stai creando un indice in
col1&un indice composto in (col1,col2), quindi solo l'indice composito dovrebbe andare bene.col1da solo può essere servito dall'indice composito stesso poiché è un prefisso sul lato sinistro dell'indice. - Considera la cardinalità. Se le colonne utilizzate nell'indice composito finiscono per avere insieme un'elevata cardinalità, sono buone candidate per l'indice composito.
Indice di copertura:
Un indice di copertura è un tipo speciale di indice composto in cui tutte le colonne specificate nella query esistono da qualche parte nell'indice. Quindi Query Optimizer non ha bisogno di raggiungere il database per ottenere i dati, ma ottiene il risultato dall'indice stesso. Esempio:abbiamo già definito un indice composito su (pan_no, name, age) , quindi ora considera la seguente query:
SELECT age FROM index_demo WHERE pan_no = 'HJKXS9086W' AND name = 'kousik'
Le colonne menzionate in SELECT &WHERE le clausole fanno parte dell'indice composito. Quindi, in questo caso, possiamo effettivamente ottenere il valore di age colonna dall'indice composito stesso. Vediamo cos'è il EXPLAIN comando mostra per questa query:
EXPLAIN FORMAT=JSON SELECT age FROM index_demo WHERE pan_no = 'HJKXS9086W' AND name = '111kousik1';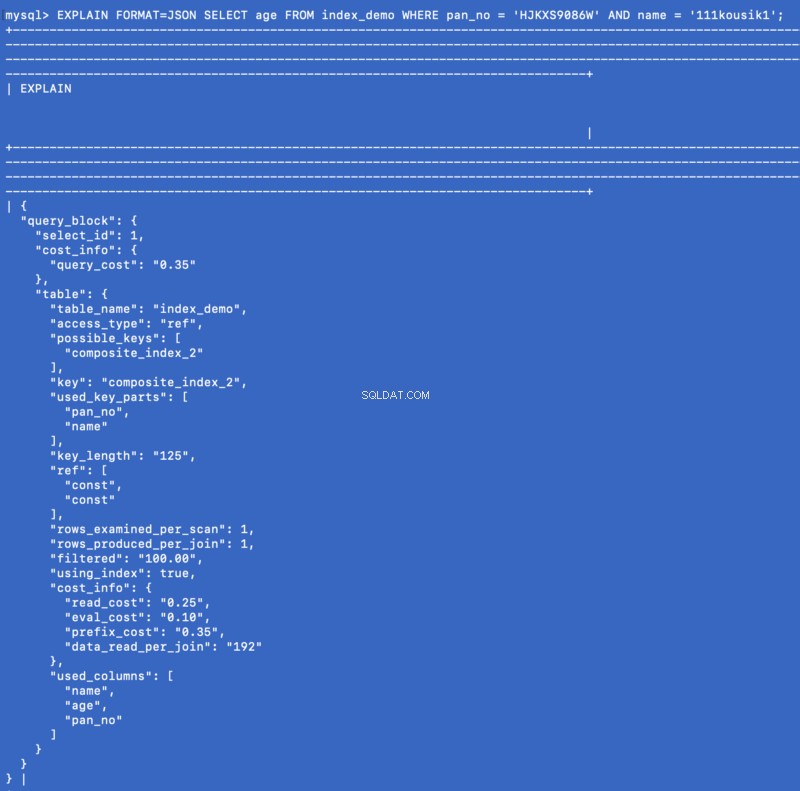
Nella risposta sopra, nota che c'è una chiave:using_index che è impostato su true il che significa che l'indice di copertura è stato utilizzato per rispondere alla query.
Non so quanto gli indici di copertura siano apprezzati negli ambienti di produzione, ma a quanto pare sembra essere una buona ottimizzazione nel caso in cui la query si adatti al conto.
Indice parziale:
Sappiamo già che gli indici velocizzano le nostre query a scapito dello spazio. Più indici hai, maggiore è il requisito di archiviazione. Abbiamo già creato un indice chiamato secondary_idx_1 nella colonna name . La colonna name può contenere valori grandi di qualsiasi lunghezza. Anche nell'indice, i metadati dei localizzatori di riga o dei puntatori di riga hanno le proprie dimensioni. Quindi, nel complesso, un indice può avere una memoria e un carico di memoria elevati.
In MySQL è anche possibile creare un indice sui primi byte di dati. Esempio:il comando seguente crea un indice sui primi 4 byte di nome. Sebbene questo metodo riduca l'overhead di memoria di una certa quantità, l'indice non può eliminare molte righe, poiché in questo esempio i primi 4 byte possono essere comuni a molti nomi. Di solito questo tipo di indicizzazione del prefisso è supportato su CHAR ,VARCHAR , BINARY , VARBINARY tipo di colonne.
CREATE INDEX secondary_index_1 ON index_demo (name(4));Cosa succede sotto il cofano quando definiamo un indice?
Eseguiamo SHOW EXTENDED comando di nuovo:
SHOW EXTENDED INDEXES FROM index_demo;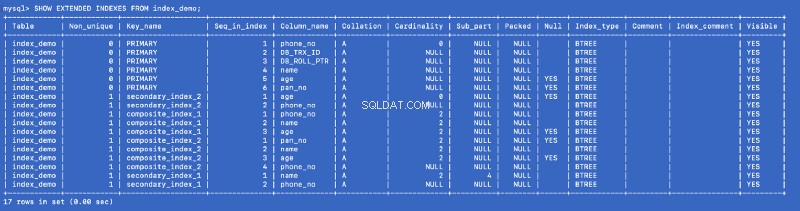
Abbiamo definito secondary_index_1 su name , ma MySQL ha creato un indice composito su (name , phone_no ) dove phone_no è la colonna della chiave primaria. Abbiamo creato secondary_index_2 su age &MySQL ha creato un indice composito su (age , phone_no ). Abbiamo creato composite_index_2 su (pan_no , name , age ) e MySQL ha creato un indice composito su (pan_no , name , age , phone_no ). L'indice composito composite_index_1 ha già phone_no come parte di esso.
Quindi, qualunque sia l'indice che creiamo, MySQL in background crea un indice composito di supporto che a sua volta punta alla chiave primaria. Ciò significa che la chiave primaria è un cittadino di prima classe nel mondo dell'indicizzazione MySQL. It also proves that all the indexes are backed by a copy of the primary index —but I am not sure whether a single copy of the primary index is shared or different copies are used for different indexes.
There are many other indices as well like Spatial index and Full Text Search index offered by MySQL. I have not yet experimented with those indices, so I’m not discussing them in this post.
General Indexing guidelines:
- Since indices consume extra memory, carefully decide how many &what type of index will suffice your need.
- With
DMLoperations, indices are updated, so write operations are quite costly with indexes. The more indices you have, the greater the cost. Indexes are used to make read operations faster. So if you have a system that is write heavy but not read heavy, think hard about whether you need an index or not. - Cardinality is important — cardinality means the number of distinct values in a column. If you create an index in a column that has low cardinality, that’s not going to be beneficial since the index should reduce search space. Low cardinality does not significantly reduce search space.
Example:if you create an index on a boolean (int1or0only ) type column, the index will be very skewed since cardinality is less (cardinality is 2 here). But if this boolean field can be combined with other columns to produce high cardinality, go for that index when necessary. - Indices might need some maintenance as well if old data still remains in the index. They need to be deleted otherwise memory will be hogged, so try to have a monitoring plan for your indices.
In the end, it’s extremely important to understand the different aspects of database indexing. It will help while doing low level system designing. Many real-life optimizations of our applications depend on knowledge of such intricate details. A carefully chosen index will surely help you boost up your application’s performance.
Please do clap &share with your friends &on social media if you like this article. :)
References:
- https://dev.mysql.com/doc/refman/5.7/en/innodb-index-types.html
- https://www.quora.com/What-is-difference-between-primary-index-and-secondary-index-exactly-And-whats-advantage-of-one-over-another
- https://dev.mysql.com/doc/refman/8.0/en/create-index.html
- https://www.oreilly.com/library/view/high-performance-mysql/0596003064/ch04.html
- https://www.unofficialmysqlguide.com/covering-indexes.html
- https://dev.mysql.com/doc/refman/8.0/en/multiple-column-indexes.html
- https://dev.mysql.com/doc/refman/8.0/en/show-index.html
- https://dev.mysql.com/doc/refman/8.0/en/create-index.html