Se si utilizza il partizionamento della tabella con una o più partizioni archiviate in un filegroup di sola lettura, le istruzioni di aggiornamento ed eliminazione SQL potrebbero non riuscire con un errore. Naturalmente, questo è il comportamento previsto se una qualsiasi delle modifiche richiedesse la scrittura in un filegroup di sola lettura; tuttavia è anche possibile riscontrare questa condizione di errore in cui le modifiche sono limitate ai filegroup contrassegnati come lettura-scrittura.
Banca dati campione
Per dimostrare il problema, creeremo un semplice database con un singolo filegroup personalizzato che in seguito contrassegneremo come di sola lettura. Tieni presente che dovrai aggiungere il percorso del nome del file per adattarlo alla tua istanza di test.
USE master;
GO
CREATE DATABASE Test;
GO
-- This filegroup will be marked read-only later
ALTER DATABASE Test
ADD FILEGROUP ReadOnlyFileGroup;
GO
-- Add a file to the new filegroup
ALTER DATABASE Test
ADD FILE
(
NAME = 'Test_RO',
FILENAME = '<...your path...>\MSSQL\DATA\Test_ReadOnly.ndf'
)
TO FILEGROUP ReadOnlyFileGroup; Funzione e schema di partizione
Creeremo ora una funzione di partizionamento di base e uno schema che dirigerà le righe con i dati prima del 1 gennaio 2000 alla partizione di sola lettura. I dati successivi verranno mantenuti nel filegroup primario di lettura-scrittura:
USE Test;
GO
CREATE PARTITION FUNCTION PF (datetime)
AS RANGE RIGHT
FOR VALUES ({D '2000-01-01'});
GO
CREATE PARTITION SCHEME PS
AS PARTITION PF
TO (ReadOnlyFileGroup, [PRIMARY]); La specifica dell'intervallo a destra significa che le righe con il valore limite 1 gennaio 2000 saranno nella partizione di lettura-scrittura.
Tabella e indici partizionati
Ora possiamo creare la nostra tabella di test:
CREATE TABLE dbo.Test
(
dt datetime NOT NULL,
c1 integer NOT NULL,
c2 integer NOT NULL,
CONSTRAINT PK_dbo_Test__c1_dt
PRIMARY KEY CLUSTERED (dt)
ON PS (dt)
)
ON PS (dt);
GO
CREATE NONCLUSTERED INDEX IX_dbo_Test_c1
ON dbo.Test (c1)
ON PS (dt);
GO
CREATE NONCLUSTERED INDEX IX_dbo_Test_c2
ON dbo.Test (c2)
ON PS (dt); La tabella ha una chiave primaria in cluster nella colonna datetime ed è anche partizionata su quella colonna. Ci sono indici non cluster sulle altre due colonne intere, che sono partizionate allo stesso modo (gli indici sono allineati con la tabella di base).
Dati di esempio
Infine, aggiungiamo un paio di righe di dati di esempio e facciamo in modo che la partizione dati precedente al 2000 sia di sola lettura:
INSERT dbo.Test WITH (TABLOCKX)
(dt, c1, c2)
VALUES
({D '1999-12-31'}, 1, 1), -- Read only
({D '2000-01-01'}, 2, 2); -- Writable
GO
ALTER DATABASE Test
MODIFY FILEGROUP
ReadOnlyFileGroup READ_ONLY;
È possibile utilizzare le seguenti istruzioni di aggiornamento del test per confermare che i dati nella partizione di sola lettura non possono essere modificati, mentre i dati con un dt il valore a partire dal 1 gennaio 2000 può essere scritto a:
-- Will fail, as expected
UPDATE dbo.Test
SET c2 = 1
WHERE dt = {D '1999-12-31'};
-- Will succeed, as expected
UPDATE dbo.Test
SET c2 = 999
WHERE dt = {D '2000-01-01'};
-- Reset the value of c2
UPDATE dbo.Test
SET c2 = 2
WHERE dt = {D '2000-01-01'}; Un errore imprevisto
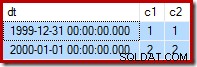
Abbiamo due righe:una di sola lettura (1999-12-31); e una lettura-scrittura (01-01-2000):

Ora prova la seguente query. Identifica la stessa riga scrivibile "2000-01-01" che abbiamo appena aggiornato correttamente, ma utilizza un predicato della clausola where diverso:
UPDATE dbo.Test SET c2 = 2 WHERE c1 = 2;
Il piano stimato (pre-esecuzione) è:

I quattro (!) Compute Scalar non sono importanti per questa discussione. Vengono utilizzati per determinare se l'indice non cluster deve essere mantenuto per ogni riga che arriva all'operatore Clustered Index Update.
La cosa più interessante è che questa dichiarazione di aggiornamento non riesce con un errore simile a:
Msg 652, livello 16, stato 1L'indice "PK_dbo_Test__c1_dt" per la tabella "dbo.Test" (RowsetId 72057594039042048) risiede in un filegroup di sola lettura ("ReadOnlyFileGroup"), che non può essere modificato.
Non eliminazione partizione
Se hai già lavorato con il partizionamento, potresti pensare che "l'eliminazione della partizione" potrebbe essere il motivo. La logica sarebbe più o meno questa:
Nelle istruzioni precedenti, nella clausola where veniva fornito un valore letterale per la colonna di partizionamento, in modo che SQL Server potesse determinare immediatamente a quali partizioni accedere. Modificando la clausola where per non fare più riferimento alla colonna di partizionamento, abbiamo forzato SQL Server ad accedere a ogni partizione utilizzando una scansione dell'indice cluster.
Questo è tutto vero, in generale, ma non è il motivo per cui l'istruzione di aggiornamento non riesce qui.
Il comportamento previsto è che SQL Server dovrebbe essere in grado di leggere da qualsiasi partizione durante l'esecuzione della query. Un'operazione di modifica dei dati dovrebbe solo fallire se il motore di esecuzione tenta effettivamente di modificare una riga memorizzata su un filegroup di sola lettura.
Per illustrare, apportiamo una piccola modifica alla query precedente:
UPDATE dbo.Test
SET c2 = 2,
dt = dt
WHERE c1 = 2; La clausola where è esattamente la stessa di prima. L'unica differenza è che ora stiamo (deliberatamente) impostando la colonna di partizionamento uguale a se stessa. Ciò non cambierà il valore memorizzato in quella colonna, ma influirà sul risultato. L'aggiornamento ora è riuscito (anche se con un piano di esecuzione più complesso):

L'ottimizzatore ha introdotto nuovi operatori Dividi, Ordina e Comprimi e ha aggiunto i macchinari necessari per mantenere ogni indice non cluster potenzialmente interessato separatamente (utilizzando una strategia ampia o per indice).
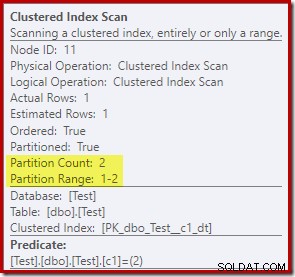
Le proprietà Clustered Index Scan mostrano che entrambe le partizioni della tabella sono stati acceduti durante la lettura:
Al contrario, l'aggiornamento dell'indice cluster mostra che è stato eseguito l'accesso solo alla partizione di lettura-scrittura per la scrittura:
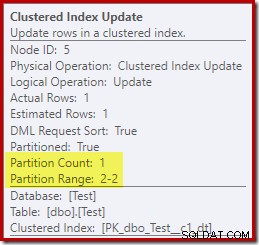
Ciascuno degli operatori di aggiornamento dell'indice non cluster mostra informazioni simili:solo la partizione scrivibile (n. 2) è stata modificata in fase di esecuzione, quindi non si è verificato alcun errore.
Il motivo rivelato
Il nuovo piano ha successo non perché gli indici non cluster vengono mantenuti separatamente; né è (direttamente) a causa della combinazione Dividi-Ordina-Comprimi necessaria per evitare errori transitori di chiave duplicata nell'indice univoco.
Il vero motivo è qualcosa che ho menzionato brevemente nel mio precedente articolo, "Ottimizzazione delle query di aggiornamento", un'ottimizzazione interna nota come Condivisione di set di righe . Quando viene utilizzato, Clustered Index Update condivide lo stesso set di righe del motore di archiviazione sottostante come Clustered Index Scan, Seek o Key Lookup sul lato di lettura del piano.
Con l'ottimizzazione della condivisione del set di righe, SQL Server verifica la presenza di filegroup offline o di sola lettura durante la lettura. Nei piani in cui l'aggiornamento dell'indice cluster utilizza un set di righe separato, il controllo offline/sola lettura viene eseguito solo per ogni riga nell'iteratore di aggiornamento (o eliminazione).
Soluzioni alternative non documentate
Togliamo prima di mezzo le cose divertenti, stravaganti ma poco pratiche.
L'ottimizzazione del set di righe condiviso può essere applicata solo quando il percorso dalla ricerca dell'indice cluster, dalla scansione o dalla ricerca della chiave è una pipeline . Non sono ammessi operatori di blocco o semiblocco. In altre parole, ogni riga deve essere in grado di passare dall'origine di lettura alla destinazione di scrittura prima che venga letta la riga successiva.
Come promemoria, ecco i dati di esempio, la dichiarazione e il piano di esecuzione per il fallito aggiorna di nuovo:
--Change the read-write row UPDATE dbo.Test SET c2 = 2 WHERE c1 = 2;

Protezione di Halloween
Un modo per introdurre un operatore di blocco nel piano consiste nel richiedere una protezione di Halloween (HP) esplicita per questo aggiornamento. Separare la lettura dalla scrittura con un operatore di blocco impedirà l'utilizzo dell'ottimizzazione della condivisione del set di righe (nessuna pipeline). Il flag di traccia 8692 non documentato e non supportato (solo sistema di test!) aggiunge uno spool di tabella desideroso per HP esplicito:
-- Works (explicit HP) UPDATE dbo.Test SET c2 = 2 WHERE c1 = 2 OPTION (QUERYTRACEON 8692);
Il piano di esecuzione effettivo (disponibile perché l'errore non viene più generato) è:

La combinazione Ordina nella combinazione Dividi-Ordina-Comprimi vista nel precedente aggiornamento riuscito fornisce il blocco necessario per disabilitare la condivisione del set di righe in quell'istanza.
Il flag di traccia di condivisione anti-rowset
Esiste un altro flag di traccia non documentato che disabilita l'ottimizzazione della condivisione del set di righe. Questo ha il vantaggio di non introdurre un operatore di blocco potenzialmente costoso. Ovviamente non può essere utilizzato nella pratica (a meno che non contatti il supporto Microsoft e non ottenga qualcosa per iscritto che consiglia di abilitarlo, suppongo). Tuttavia, per scopi di intrattenimento, ecco il flag di traccia 8746 in azione:
-- Works (no rowset sharing) UPDATE dbo.Test SET c2 = 2 WHERE c1 = 2 OPTION (QUERYTRACEON 8746);
Il piano di esecuzione effettivo per tale istruzione è:

Sentiti libero di sperimentare valori diversi (quelli che cambiano effettivamente i valori memorizzati, se lo desideri) per convincerti della differenza qui. Come accennato nel mio post precedente, puoi anche utilizzare il flag di traccia non documentato 8666 per esporre la proprietà di condivisione del set di righe nel piano di esecuzione.
Se vuoi vedere l'errore di condivisione del set di righe con un'istruzione delete, sostituisci semplicemente le clausole update e set con una delete, usando la stessa clausola where.
Soluzioni alternative supportate
Esistono numerosi modi potenziali per garantire che la condivisione del set di righe non venga applicata nelle query del mondo reale senza utilizzare i flag di traccia. Ora che sai che il problema principale richiede un piano di lettura e scrittura dell'indice cluster condiviso e pipeline, probabilmente puoi inventarne uno tuo. Anche così, ci sono un paio di esempi che vale la pena guardare qui.
Indice forzato/Indice di copertura
Un'idea naturale è forzare il lato lettura del piano a utilizzare un indice non cluster invece dell'indice cluster. Non è possibile aggiungere un suggerimento di indice direttamente alla query di test come è stata scritta, ma l'aliasing della tabella consente questo:
UPDATE T SET c2 = 2 FROM dbo.Test AS T WITH (INDEX(IX_dbo_Test_c1)) WHERE c1 = 2;
Questa potrebbe sembrare la soluzione che Query Optimizer avrebbe dovuto scegliere in primo luogo, dal momento che abbiamo un indice non cluster sulla colonna del predicato della clausola where c1. Il piano di esecuzione mostra perché l'ottimizzatore ha scelto come ha fatto:
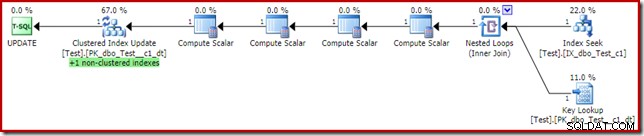
Il costo della ricerca chiave è sufficiente per convincere l'ottimizzatore a utilizzare l'indice cluster per la lettura. La ricerca è necessaria per recuperare il valore corrente della colonna c2, in modo che Compute Scalar possa decidere se l'indice non cluster deve essere mantenuto.
L'aggiunta della colonna c2 all'indice non cluster (chiave o inclusione) eviterebbe il problema. L'ottimizzatore sceglierà l'indice di copertura ora invece dell'indice cluster.
Detto questo, non è sempre possibile anticipare quali colonne saranno necessarie, o includerle tutte anche se l'insieme è noto. Ricorda, la colonna è necessaria perché c2 è nella clausola set della dichiarazione di aggiornamento. Se le query sono ad hoc (ad es. inviate dagli utenti o generate da uno strumento), ogni indice non cluster dovrebbe includere tutte le colonne per rendere questa opzione affidabile.
Una cosa interessante del piano con la ricerca chiave sopra è che non generare un errore. Questo nonostante la ricerca chiave e l'aggiornamento dell'indice cluster utilizzino un set di righe condiviso. Il motivo è che Index Seek non cluster individua la riga con c1 =2 prima la ricerca chiave tocca l'indice cluster. Il controllo del set di righe condiviso per i filegroup offline/di sola lettura viene ancora eseguito durante la ricerca, ma non tocca la partizione di sola lettura, quindi non viene generato alcun errore. Come ultimo punto di interesse (correlato), tieni presente che Index Seek tocca entrambe le partizioni, ma Key Lookup ne colpisce solo una.
Esclusa la partizione di sola lettura
Una soluzione banale è affidarsi all'eliminazione della partizione in modo che il lato di lettura del piano non tocchi mai la partizione di sola lettura. Questo può essere fatto con un predicato esplicito, ad esempio uno di questi:
UPDATE dbo.Test
SET c2 = 2
WHERE c1 = 2
AND dt >= {D '2000-01-01'};
UPDATE dbo.Test
SET c2 = 2
WHERE c1 = 2
AND $PARTITION.PF(dt) > 1; -- Not partition #1 Laddove è impossibile o scomodo modificare ogni query per aggiungere un predicato di eliminazione delle partizioni, potrebbero essere adatte altre soluzioni come l'aggiornamento tramite una vista. Ad esempio:
CREATE VIEW dbo.TestWritablePartitions
WITH SCHEMABINDING
AS
-- Only the writable portion of the table
SELECT
T.dt,
T.c1,
T.c2
FROM dbo.Test AS T
WHERE
$PARTITION.PF(dt) > 1;
GO
-- Succeeds
UPDATE dbo.TestWritablePartitions
SET c2 = 2
WHERE c1 = 2; Uno svantaggio dell'utilizzo di una vista è che un aggiornamento o un'eliminazione che ha come destinazione la parte di sola lettura della tabella di base avrà esito positivo senza che le righe siano interessate, anziché con un errore. Un trigger invece di un trigger sul tavolo o una vista potrebbe essere una soluzione alternativa per questo in alcune situazioni, ma potrebbe anche introdurre più problemi... ma sto divagando.
Come accennato in precedenza, ci sono molte potenziali soluzioni supportate. Lo scopo di questo articolo è mostrare in che modo la condivisione del set di righe ha causato l'errore di aggiornamento imprevisto.