Sono passati quasi due mesi da quando abbiamo rilasciato SCUMM (Severalnines ClusterControl Unified Management and Monitoring). SCUMM utilizza Prometheus come metodo sottostante per raccogliere dati di serie temporali da esportatori in esecuzione su istanze di database e bilanciatori di carico. Questo blog ti mostrerà come risolvere i problemi quando gli esportatori Prometheus non sono in esecuzione, o se i grafici non mostrano dati o mostrano "Nessun punto dati".
Cos'è Prometeo?
Prometheus è un sistema di monitoraggio open source con un modello di dati dimensionali, un linguaggio di query flessibile, un database di serie temporali efficiente e un moderno approccio di allerta. È una piattaforma di monitoraggio che raccoglie le metriche dalle destinazioni monitorate eseguendo lo scraping degli endpoint HTTP delle metriche su queste destinazioni. Fornisce dati dimensionali, query potenti, visualizzazione eccezionale, archiviazione efficiente, funzionamento semplice, avvisi precisi, molte librerie client e molte integrazioni.
Prometheus in azione per i dashboard SCUMM
Prometheus raccoglie i dati delle metriche dagli esportatori, con ogni esportatore in esecuzione su un database o un host di bilanciamento del carico. Il diagramma seguente mostra come questi esportatori sono collegati al server che ospita il processo Prometheus. Mostra che il nodo ClusterControl ha Prometheus in esecuzione dove esegue anche process_exporter e node_exporter.
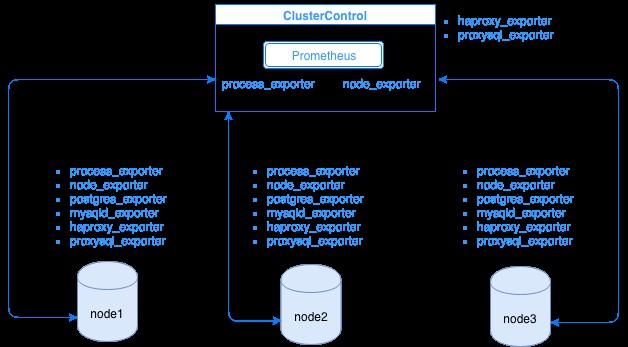
Il diagramma mostra che Prometheus è in esecuzione sull'host ClusterControl e sugli esportatori process_exporter e node_exporter sono in esecuzione anche per raccogliere le metriche dal proprio nodo. Facoltativamente, puoi anche impostare il tuo host ClusterControl come destinazione in cui puoi configurare HAProxy o ProxySQL.
Per i nodi del cluster sopra (nodo1, nodo2 e nodo3), può avere mysqld_exporter o postgres_exporter in esecuzione che sono gli agenti che estraggono i dati internamente in quel nodo e li passano al server Prometheus e li archiviano nel proprio archivio dati. Puoi individuare i suoi dati fisici tramite /var/lib/prometheus/data all'interno dell'host in cui è configurato Prometheus.
Quando si configura Prometheus, ad esempio, nell'host ClusterControl, dovrebbe avere le seguenti porte aperte. Vedi sotto:
[example@sqldat.com share]# netstat -tnvlp46|egrep 'ex[p]|prometheu[s]'
tcp6 0 0 :::9100 :::* LISTEN 16189/node_exporter
tcp6 0 0 :::9011 :::* LISTEN 19318/process_expor
tcp6 0 0 :::42004 :::* LISTEN 16080/proxysql_expo
tcp6 0 0 :::9090 :::* LISTEN 31856/prometheusSulla base dell'output, ho ProxySQL in esecuzione anche sull'host testccnode in cui è ospitato ClusterControl.
Problemi comuni con i dashboard SCUMM utilizzando Prometheus
Quando i dashboard sono abilitati, ClusterControl installerà e distribuirà file binari ed esportatori come node_exporter, process_exporter, mysqld_exporter, postgres_exporter e daemon. Questi sono gli insiemi comuni di pacchetti ai nodi del database. Quando questi sono impostati e installati, i seguenti comandi daemon vengono attivati ed eseguiti come mostrato di seguito:
[example@sqldat.com bin]# ps axufww|egrep 'exporte[r]'
prometh+ 3604 0.0 0.0 10828 364 ? S Nov28 0:00 daemon --name=process_exporter --output=/var/log/prometheus/process_exporter.log --env=HOME=/var/lib/prometheus --env=PATH=/usr/local/bin:/usr/bin:/sbin:/bin:/usr/sbin:/usr/bin --chdir=/var/lib/prometheus --pidfile=/var/run/prometheus/process_exporter.pid --user=prometheus -- process_exporter
prometh+ 3605 0.2 0.3 256300 14924 ? Sl Nov28 4:06 \_ process_exporter
prometh+ 3838 0.0 0.0 10828 564 ? S Nov28 0:00 daemon --name=node_exporter --output=/var/log/prometheus/node_exporter.log --env=HOME=/var/lib/prometheus --env=PATH=/usr/local/bin:/usr/bin:/sbin:/bin:/usr/sbin:/usr/bin --chdir=/var/lib/prometheus --pidfile=/var/run/prometheus/node_exporter.pid --user=prometheus -- node_exporter
prometh+ 3839 0.0 0.4 44636 15568 ? Sl Nov28 1:08 \_ node_exporter
prometh+ 4038 0.0 0.0 10828 568 ? S Nov28 0:00 daemon --name=mysqld_exporter --output=/var/log/prometheus/mysqld_exporter.log --env=HOME=/var/lib/prometheus --env=PATH=/usr/local/bin:/usr/bin:/sbin:/bin:/usr/sbin:/usr/bin --chdir=/var/lib/prometheus --pidfile=/var/run/prometheus/mysqld_exporter.pid --user=prometheus -- mysqld_exporter --collect.perf_schema.eventswaits --collect.perf_schema.file_events --collect.perf_schema.file_instances --collect.perf_schema.indexiowaits --collect.perf_schema.tableiowaits --collect.perf_schema.tablelocks --collect.info_schema.tablestats --collect.info_schema.processlist --collect.binlog_size --collect.global_status --collect.global_variables --collect.info_schema.innodb_metrics --collect.slave_status
prometh+ 4039 0.1 0.2 17368 11544 ? Sl Nov28 1:47 \_ mysqld_exporter --collect.perf_schema.eventswaits --collect.perf_schema.file_events --collect.perf_schema.file_instances --collect.perf_schema.indexiowaits --collect.perf_schema.tableiowaits --collect.perf_schema.tablelocks --collect.info_schema.tablestats --collect.info_schema.processlist --collect.binlog_size --collect.global_status --collect.global_variables --collect.info_schema.innodb_metrics --collect.slave_statusPer un nodo PostgreSQL,
[example@sqldat.com vagrant]# ps axufww|egrep 'ex[p]'
postgres 1901 0.0 0.4 1169024 8904 ? Ss 18:00 0:04 \_ postgres: postgres_exporter postgres ::1(51118) idle
prometh+ 1516 0.0 0.0 10828 360 ? S 18:00 0:00 daemon --name=process_exporter --output=/var/log/prometheus/process_exporter.log --env=HOME=/var/lib/prometheus --env=PATH=/usr/local/bin:/usr/bin:/sbin:/bin:/usr/sbin:/usr/bin --chdir=/var/lib/prometheus --pidfile=/var/run/prometheus/process_exporter.pid --user=prometheus -- process_exporter
prometh+ 1517 0.2 0.7 117032 14636 ? Sl 18:00 0:35 \_ process_exporter
prometh+ 1700 0.0 0.0 10828 572 ? S 18:00 0:00 daemon --name=node_exporter --output=/var/log/prometheus/node_exporter.log --env=HOME=/var/lib/prometheus --env=PATH=/usr/local/bin:/usr/bin:/sbin:/bin:/usr/sbin:/usr/bin --chdir=/var/lib/prometheus --pidfile=/var/run/prometheus/node_exporter.pid --user=prometheus -- node_exporter
prometh+ 1701 0.0 0.7 44380 14932 ? Sl 18:00 0:10 \_ node_exporter
prometh+ 1897 0.0 0.0 10828 568 ? S 18:00 0:00 daemon --name=postgres_exporter --output=/var/log/prometheus/postgres_exporter.log --env=HOME=/var/lib/prometheus --env=PATH=/usr/local/bin:/usr/bin:/sbin:/bin:/usr/sbin:/usr/bin --env=DATA_SOURCE_NAME=postgresql://postgres_exporter:example@sqldat.com:5432/postgres?sslmode=disable --chdir=/var/lib/prometheus --pidfile=/var/run/prometheus/postgres_exporter.pid --user=prometheus -- postgres_exporter
prometh+ 1898 0.0 0.5 16548 11204 ? Sl 18:00 0:06 \_ postgres_exporterHa gli stessi esportatori di un nodo MySQL, ma differisce solo su postgres_exporter poiché questo è un nodo di database PostgreSQL.
Tuttavia, quando un nodo subisce un'interruzione di alimentazione, un arresto anomalo del sistema o un riavvio del sistema, questi programmi di esportazione smetteranno di funzionare. Prometheus riferirà che un esportatore è inattivo. ClusterControl campiona Prometheus stesso e richiede gli stati di esportatore. Quindi agisce in base a queste informazioni e riavvierà l'esportatore se è inattivo.
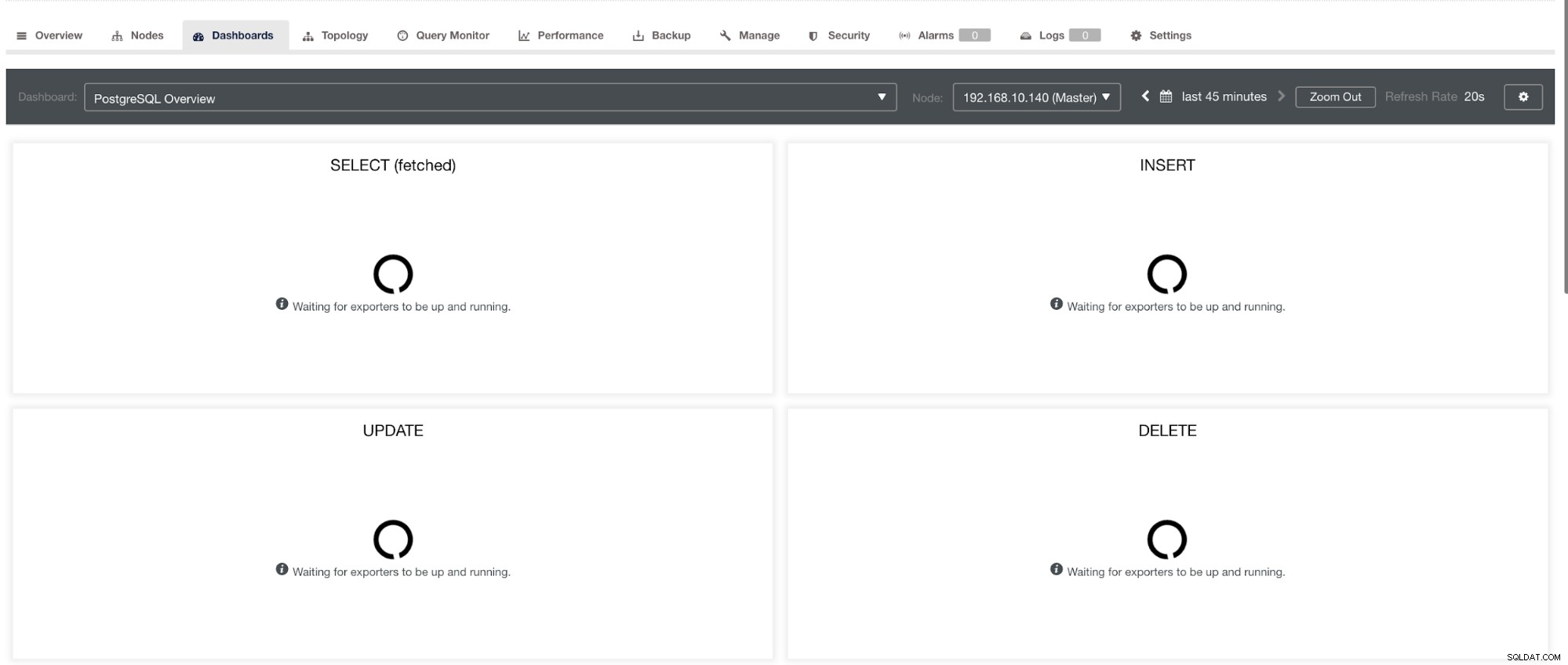
Tuttavia, si noti che per gli esportatori che non sono stati installati tramite ClusterControl, non verranno riavviati dopo un arresto anomalo. Il motivo è che non sono monitorati da systemd o da un demone che agisce come uno script di sicurezza che riavvierebbe un processo in caso di arresto anomalo o arresto anomalo. Quindi, lo screenshot qui sotto mostrerà come appare quando gli esportatori non sono in esecuzione. Vedi sotto:
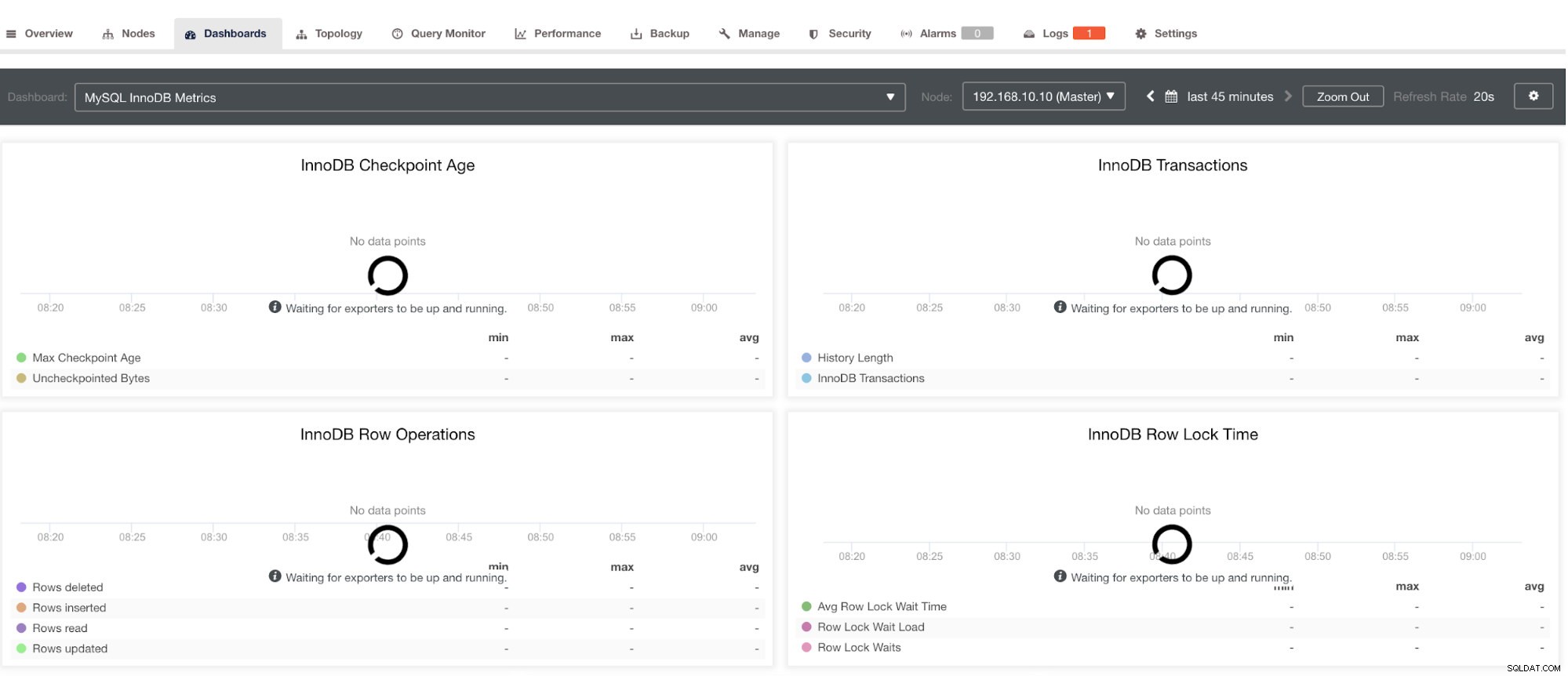
e in PostgreSQL Dashboard, avrà la stessa icona di caricamento con l'etichetta "Nessun punto dati" nel grafico. Vedi sotto:
Pertanto, questi possono essere risolti attraverso varie tecniche che seguiranno nelle sezioni seguenti.
Risoluzione dei problemi con Prometheus
Gli agenti Prometheus, noti come gli esportatori, utilizzano le seguenti porte:9100 (node_exporter), 9011 (process_exporter), 9187 (postgres_exporter), 9104 (mysqld_exporter), 42004 (proxysql_exporter) e il proprio 9090 che è di proprietà di un prometheus processi. Queste sono le porte per questi agenti utilizzati da ClusterControl.
Per iniziare a risolvere i problemi di SCUMM Dashboard, puoi iniziare controllando le porte aperte dal nodo del database. Puoi seguire gli elenchi seguenti:
-
Controlla se le porte sono aperte
es.
## Use netstat and check the ports [example@sqldat.com vagrant]# netstat -tnvlp46|egrep 'ex[p]' tcp6 0 0 :::9100 :::* LISTEN 5036/node_exporter tcp6 0 0 :::9011 :::* LISTEN 4852/process_export tcp6 0 0 :::9187 :::* LISTEN 5230/postgres_exporPotrebbe esserci la possibilità che le porte non siano aperte a causa di un firewall (come iptables o firewalld) che gli impedisce di aprire la porta o il demone del processo stesso non è in esecuzione.
-
Usa curl dal monitor host e verifica se la porta è raggiungibile e aperta.
es.
## Using curl and grep mysql list of available metric names used in PromQL. [example@sqldat.com prometheus]# curl -sv mariadb_g01:9104/metrics|grep 'mysql'|head -25 * About to connect() to mariadb_g01 port 9104 (#0) * Trying 192.168.10.10... * Connected to mariadb_g01 (192.168.10.10) port 9104 (#0) > GET /metrics HTTP/1.1 > User-Agent: curl/7.29.0 > Host: mariadb_g01:9104 > Accept: */* > < HTTP/1.1 200 OK < Content-Length: 213633 < Content-Type: text/plain; version=0.0.4; charset=utf-8 < Date: Sat, 01 Dec 2018 04:23:21 GMT < { [data not shown] # HELP mysql_binlog_file_number The last binlog file number. # TYPE mysql_binlog_file_number gauge mysql_binlog_file_number 114 # HELP mysql_binlog_files Number of registered binlog files. # TYPE mysql_binlog_files gauge mysql_binlog_files 26 # HELP mysql_binlog_size_bytes Combined size of all registered binlog files. # TYPE mysql_binlog_size_bytes gauge mysql_binlog_size_bytes 8.233181e+06 # HELP mysql_exporter_collector_duration_seconds Collector time duration. # TYPE mysql_exporter_collector_duration_seconds gauge mysql_exporter_collector_duration_seconds{collector="collect.binlog_size"} 0.008825006 mysql_exporter_collector_duration_seconds{collector="collect.global_status"} 0.006489491 mysql_exporter_collector_duration_seconds{collector="collect.global_variables"} 0.00324821 mysql_exporter_collector_duration_seconds{collector="collect.info_schema.innodb_metrics"} 0.008209824 mysql_exporter_collector_duration_seconds{collector="collect.info_schema.processlist"} 0.007524068 mysql_exporter_collector_duration_seconds{collector="collect.info_schema.tables"} 0.010236411 mysql_exporter_collector_duration_seconds{collector="collect.info_schema.tablestats"} 0.000610684 mysql_exporter_collector_duration_seconds{collector="collect.perf_schema.eventswaits"} 0.009132491 mysql_exporter_collector_duration_seconds{collector="collect.perf_schema.file_events"} 0.009235416 mysql_exporter_collector_duration_seconds{collector="collect.perf_schema.file_instances"} 0.009451361 mysql_exporter_collector_duration_seconds{collector="collect.perf_schema.indexiowaits"} 0.009568397 mysql_exporter_collector_duration_seconds{collector="collect.perf_schema.tableiowaits"} 0.008418406 mysql_exporter_collector_duration_seconds{collector="collect.perf_schema.tablelocks"} 0.008656682 mysql_exporter_collector_duration_seconds{collector="collect.slave_status"} 0.009924652 * Failed writing body (96 != 14480) * Closing connection 0Idealmente, ho praticamente trovato questo approccio fattibile per me perché posso eseguire facilmente grep ed eseguire il debug dal terminale.
-
Perché non utilizzare l'interfaccia utente Web?
-
Prometheus espone la porta 9090 che viene utilizzata da ClusterControl nei nostri dashboard SCUMM. Oltre a questo, le porte che gli esportatori stanno esponendo possono anche essere utilizzate per risolvere i problemi e determinare i nomi delle metriche disponibili utilizzando PromQL. Nel server su cui è in esecuzione Prometheus, puoi visitare https://
:9090/targets . Lo screenshot qui sotto lo mostra in azione: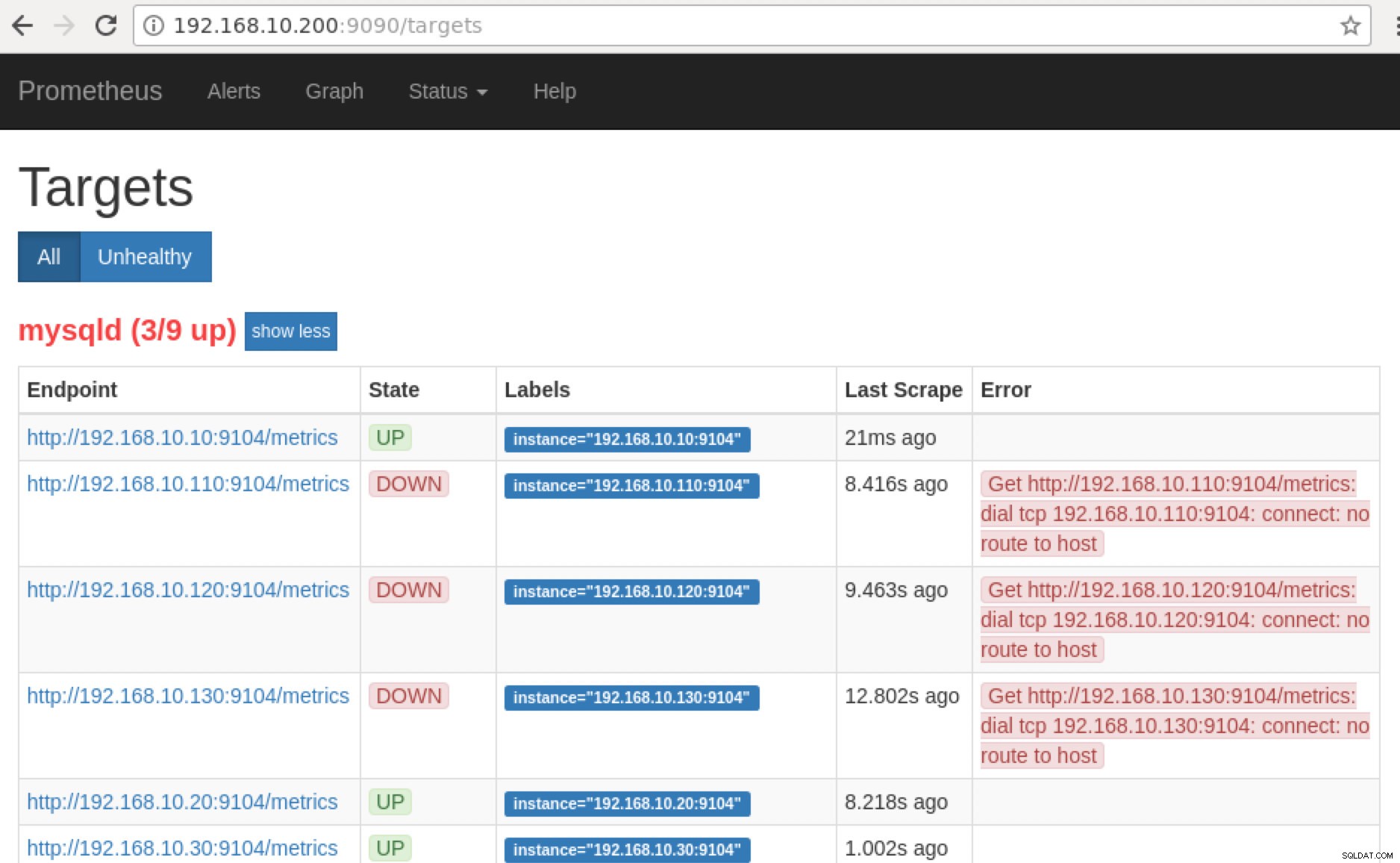
e facendo clic su "Endpoint", puoi verificare le metriche e lo screenshot qui sotto:
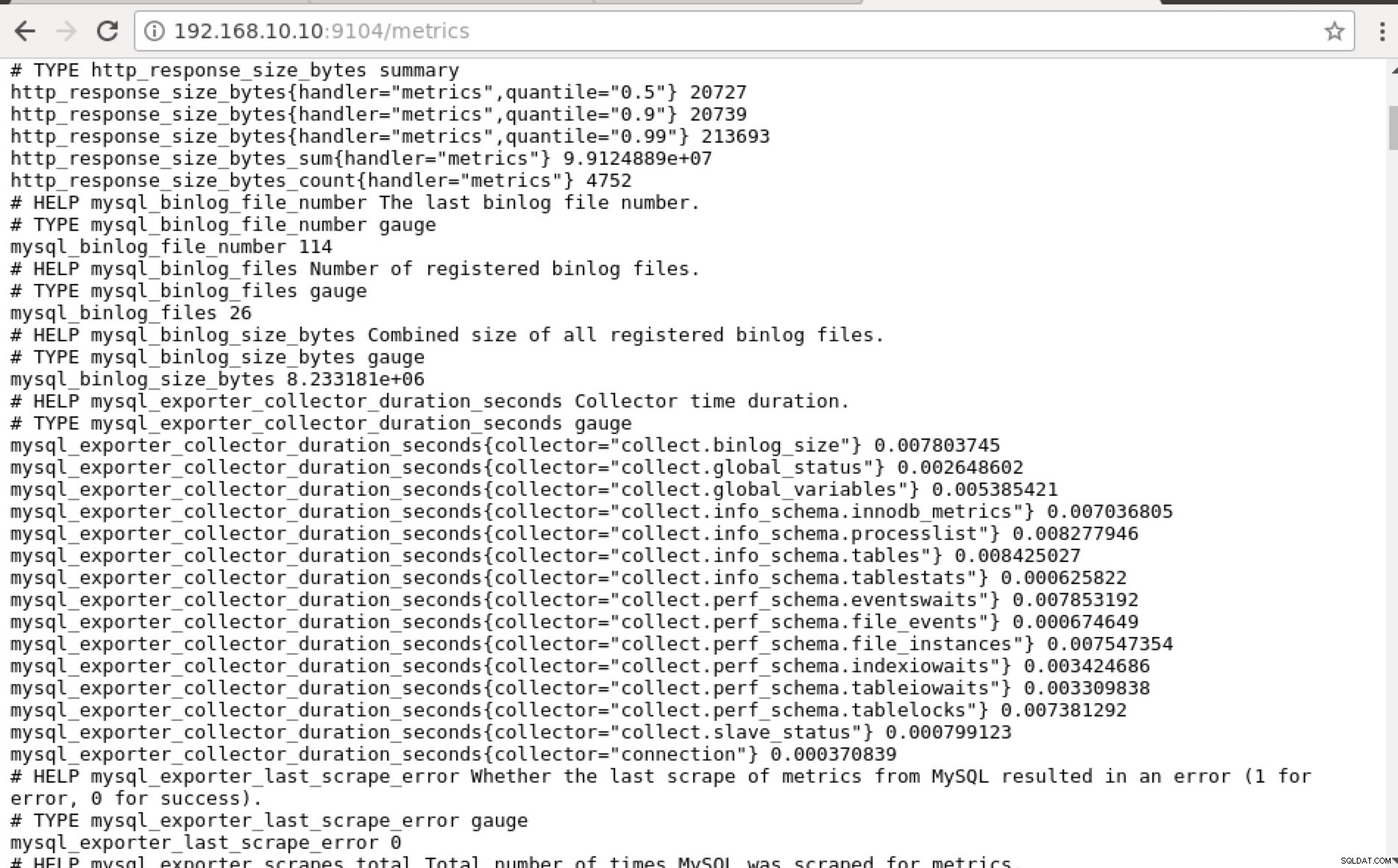
Invece di utilizzare l'indirizzo IP, puoi anche verificarlo localmente tramite localhost su quel nodo specifico, ad esempio visitando https://localhost:9104/metrics in un'interfaccia dell'interfaccia utente Web o utilizzando cURL.
Ora, se torniamo a "Target ” pagina, puoi vedere l'elenco dei nodi in cui potrebbe esserci un problema con la porta. I motivi che potrebbero causare ciò sono elencati di seguito:
- Il server è inattivo
- La rete è irraggiungibile o le porte non sono aperte a causa di un firewall in esecuzione
- Il demone non è in esecuzione dove
_exporter non sta correndo. Ad esempio, mysqld_exporter non è in esecuzione.
-
Quando questi programmi di esportazione sono in esecuzione, puoi avviare ed eseguire il processo utilizzando daemon comando. Puoi fare riferimento ai processi in esecuzione disponibili che avevo utilizzato nell'esempio sopra o menzionati nella sezione precedente di questo blog.
Che dire di quei grafici "Nessun punto dati" nella mia dashboard?
I dashboard SCUMM presentano uno scenario di casi d'uso generale comunemente utilizzato da MySQL. Tuttavia, ci sono alcune variabili quando si richiama tale metrica potrebbe non essere disponibile in una particolare versione di MySQL o in un fornitore di MySQL, come MariaDB o Percona Server.
Lascia che ti mostri un esempio qui sotto:
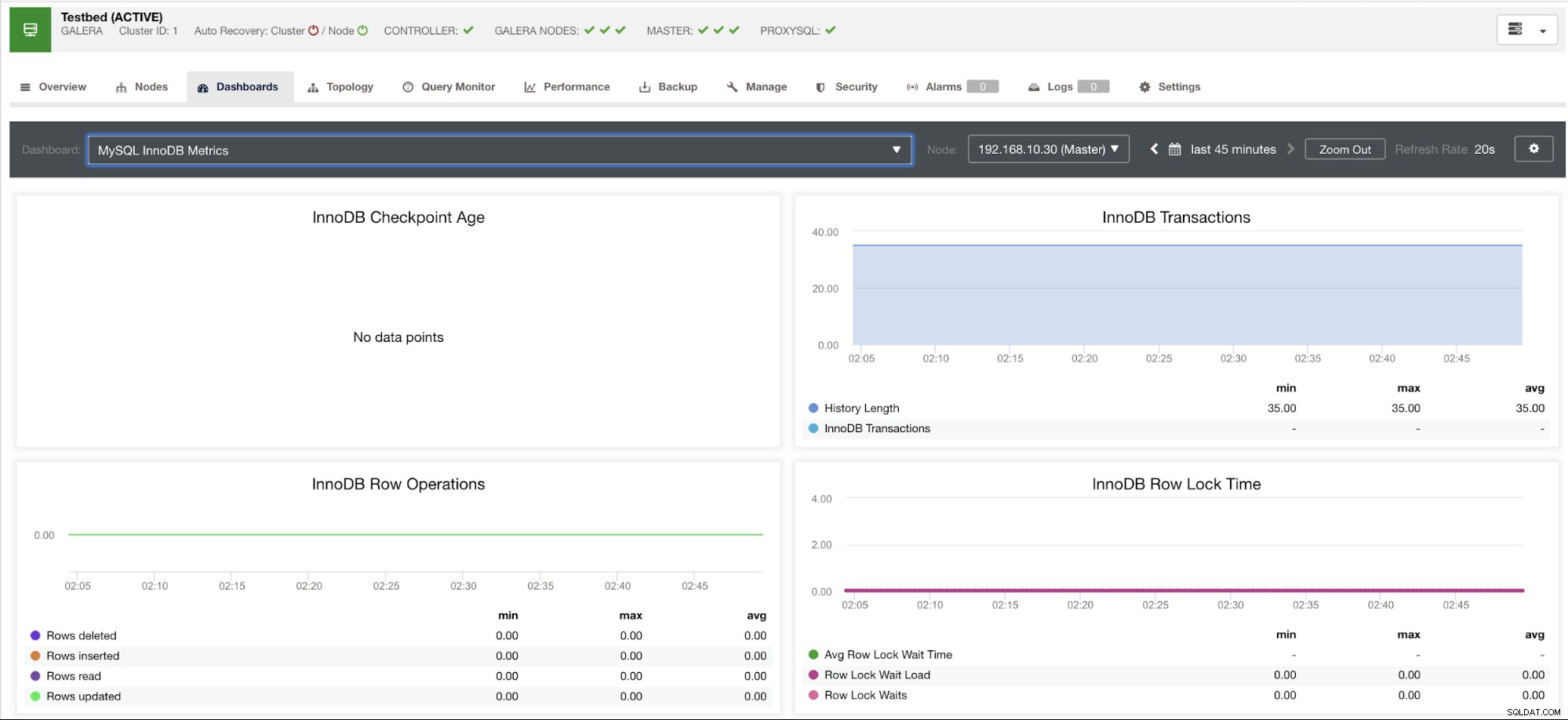
Questo grafico è stato eseguito su un server di database in esecuzione su una versione 10.3.9-MariaDB-log MariaDB Server con wsrep_patch_version dell'istanza wsrep_25.23. Ora la domanda è:perché non vengono caricati punti dati? Bene, quando ho interrogato il nodo per uno stato dell'età del checkpoint, rivela che è vuoto o non è stata trovata alcuna variabile. Vedi sotto:
MariaDB [(none)]> show global status like 'Innodb_checkpoint_max_age';
Empty set (0.000 sec)Non ho idea del perché MariaDB non abbia questa variabile (facci sapere nella sezione commenti di questo blog se hai la risposta). Ciò è in contrasto con un Percona XtraDB Cluster Server in cui esiste la variabile Innodb_checkpoint_max_age. Vedi sotto:
mysql> show global status like 'Innodb_checkpoint_max_age';
+---------------------------+-----------+
| Variable_name | Value |
+---------------------------+-----------+
| Innodb_checkpoint_max_age | 865244898 |
+---------------------------+-----------+
1 row in set (0.00 sec)Ciò significa però che possono esserci grafici che non hanno punti dati raccolti perché non sono stati raccolti dati su quella particolare metrica quando è stata eseguita una query Prometheus.
Tuttavia, un grafico che non ha punti dati non significa che la versione corrente di MySQL o la sua variante non lo supportino. Ad esempio, ci sono alcuni grafici che richiedono determinate variabili che devono essere impostate correttamente o abilitate.
La sezione seguente mostrerà quali sono questi grafici.
Grafico ICP (Index Condition Pushdown)

Questo grafico è stato menzionato nel mio blog precedente. Si basa su una variabile globale MySQL denominata innodb_monitor_enable. Questa variabile è dinamica, quindi puoi impostarla senza un riavvio forzato del tuo database MySQL. Richiede anche innodb_monitor_enable =module_icp oppure puoi impostare questa variabile globale su innodb_monitor_enable =all. In genere, per evitare tali casi e confusione sul motivo per cui tale grafico non mostra alcun punto dati, potrebbe essere necessario utilizzarli tutti ma con cautela. Può esserci un certo sovraccarico quando questa variabile è attivata e impostata su tutto.
Grafici dello schema delle prestazioni MySQL
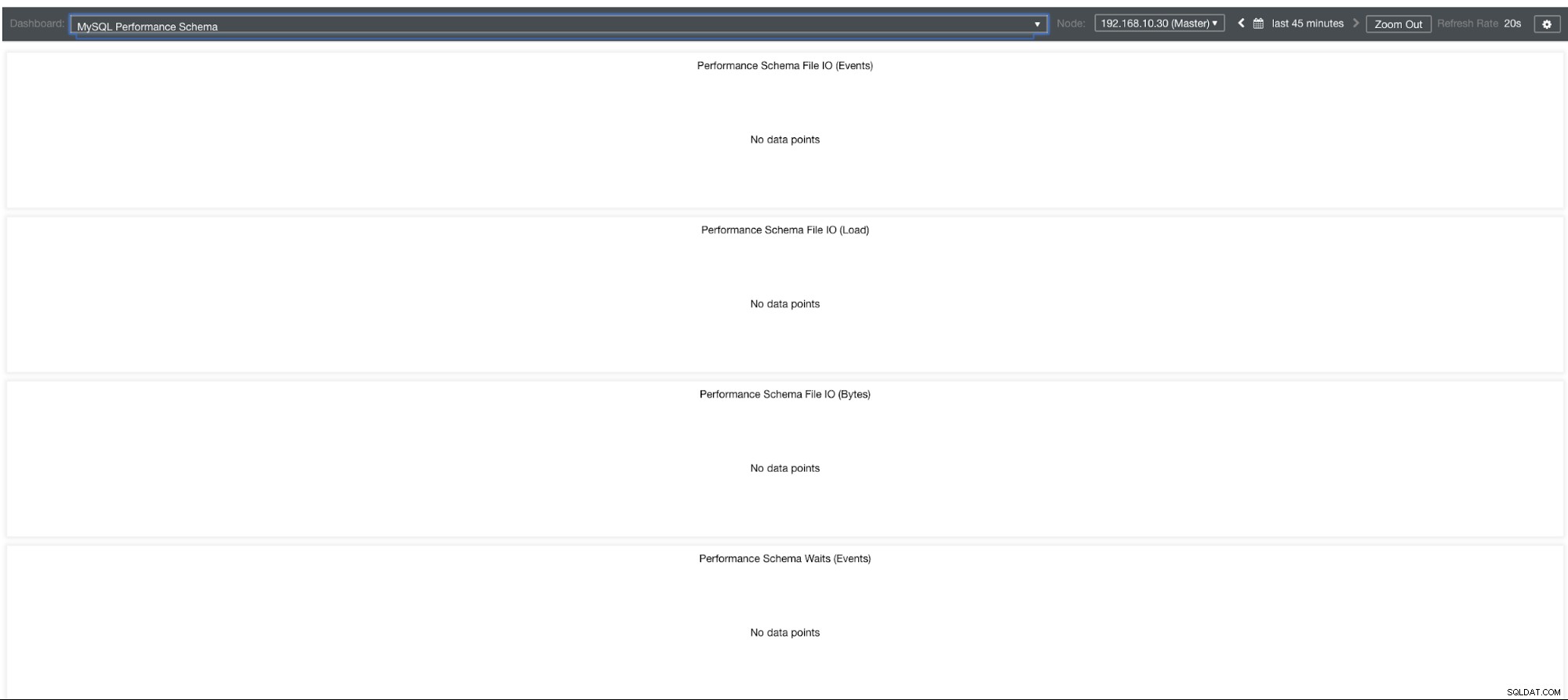
Allora perché questi grafici mostrano "Nessun punto dati"? Quando crei un cluster utilizzando ClusterControl utilizzando i nostri modelli, per impostazione predefinita definirà le variabili performance_schema. Ad esempio, vengono impostate le seguenti variabili:
performance_schema = ON
performance-schema-max-mutex-classes = 0
performance-schema-max-mutex-instances = 0Tuttavia, se performance_schema =OFF, questo è il motivo per cui i relativi grafici visualizzerebbero "Nessun punto dati".
Ma ho performance_schema abilitato, perché altri grafici sono ancora un problema?
Bene, ci sono ancora grafici che richiedono l'impostazione di più variabili. Questo è già stato trattato nel nostro blog precedente. Pertanto, è necessario impostare innodb_monitor_enable =all e userstat=1. Il risultato sarebbe simile a questo:
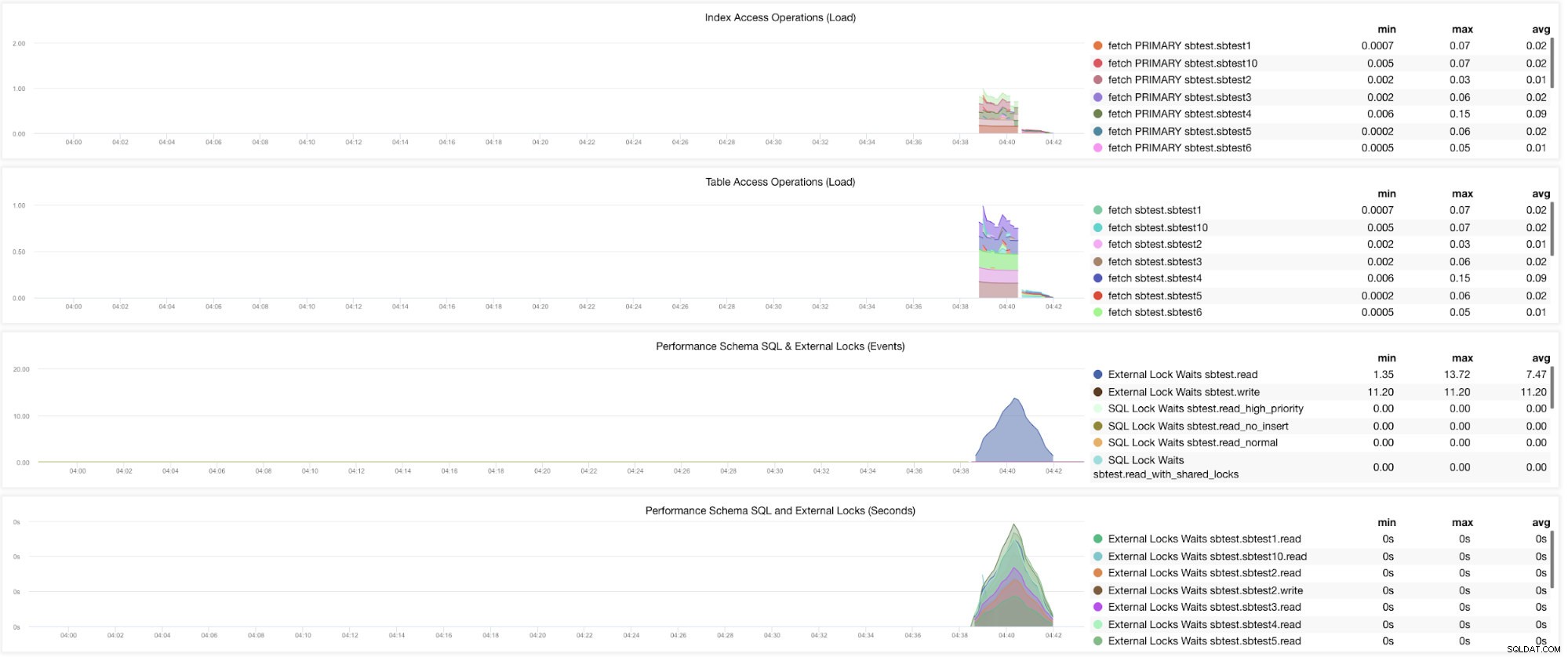
Tuttavia, noto che nella versione di MariaDB 10.3 (in particolare 10.3.11), l'impostazione performance_schema=ON popolerà le metriche necessarie per MySQL Performance Schema Dashboard. Questo è un grande vantaggio perché non è necessario impostare innodb_monitor_enable=ON che aggiungerebbe un sovraccarico aggiuntivo sul server del database.
Risoluzione dei problemi avanzata
C'è qualche risoluzione anticipata che posso consigliare? Si C'è! Tuttavia, hai almeno bisogno di alcune abilità JavaScript. Poiché i dashboard SCUMM che utilizzano Prometheus si basano su highcharts, il modo in cui le metriche utilizzate per le richieste PromQL possono essere determinate tramite lo script app.js mostrato di seguito:
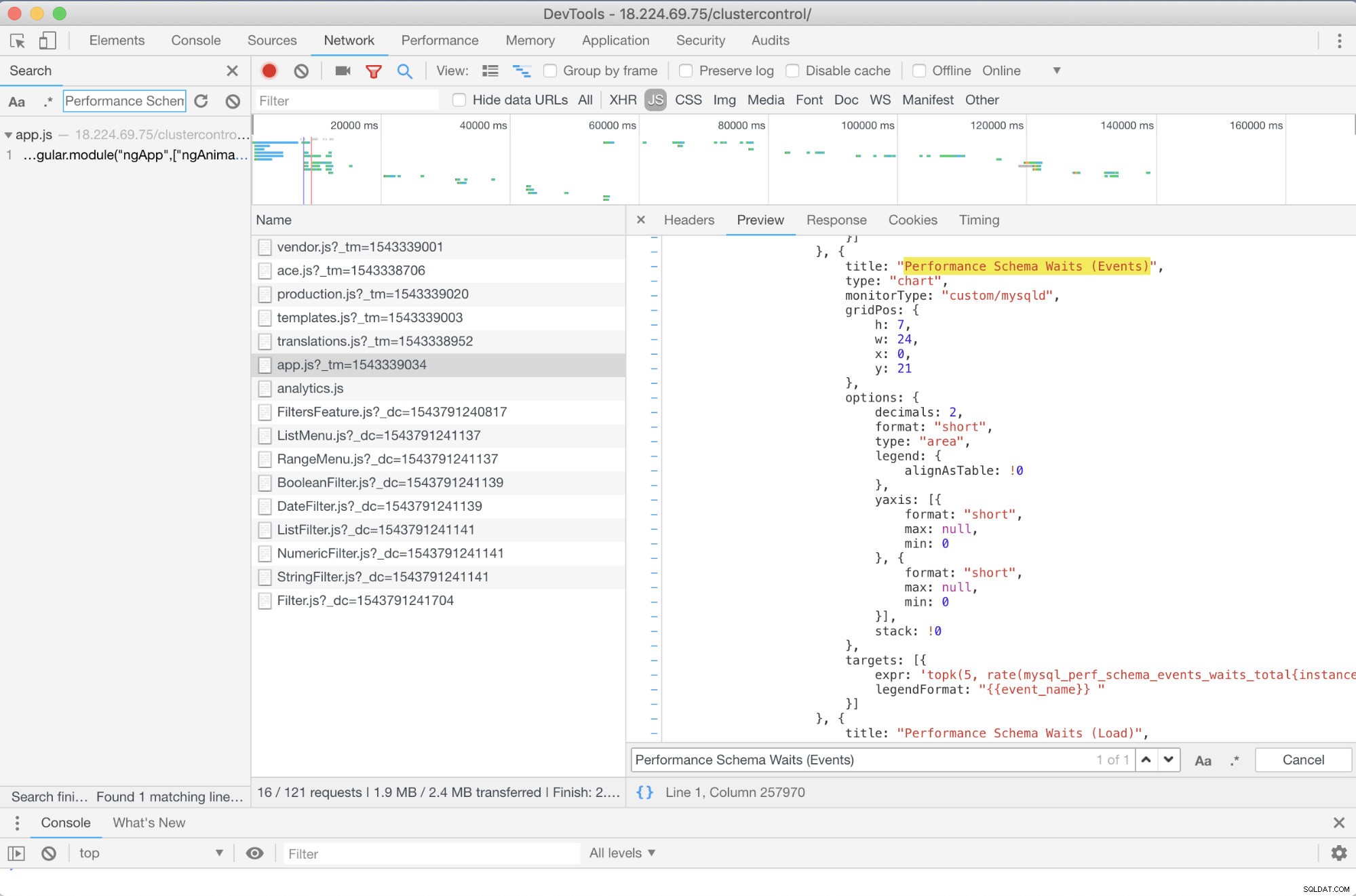
Quindi, in questo caso, sto utilizzando DevTools di Google Chrome e ho provato a cercare Prestazioni Schema Waits (Events) . In che modo questo può aiutare? Bene, se guardi gli obiettivi, vedrai:
targets: [{
expr: 'topk(5, rate(mysql_perf_schema_events_waits_total{instance="$instance"}[$interval])>0) or topk(5, irate(mysql_perf_schema_events_waits_total{instance="$instance"}[5m])>0)',
legendFormat: "{{event_name}} "
}]
Ora puoi utilizzare le metriche richieste che sono mysql_perf_schema_events_waits_total. Puoi verificarlo, ad esempio, tramite https://
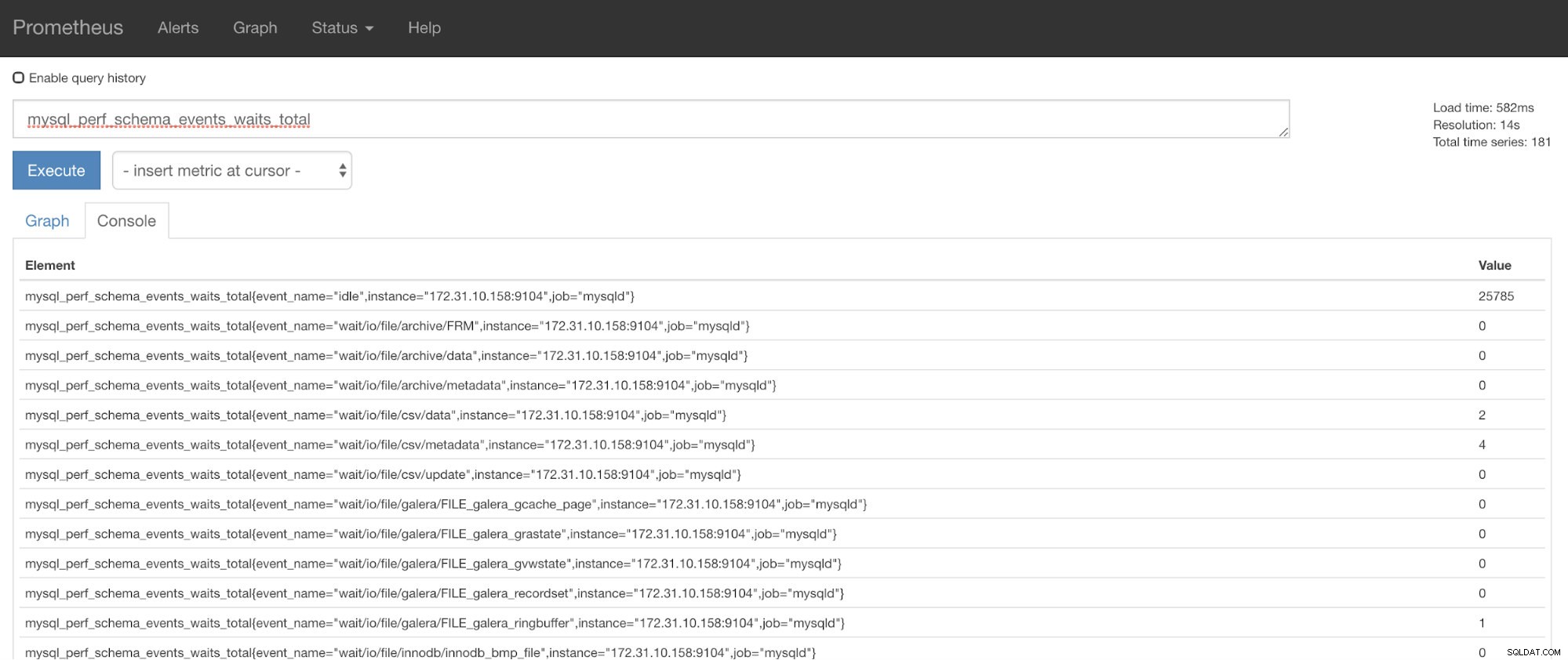
Recupero automatico di ClusterControl in soccorso!
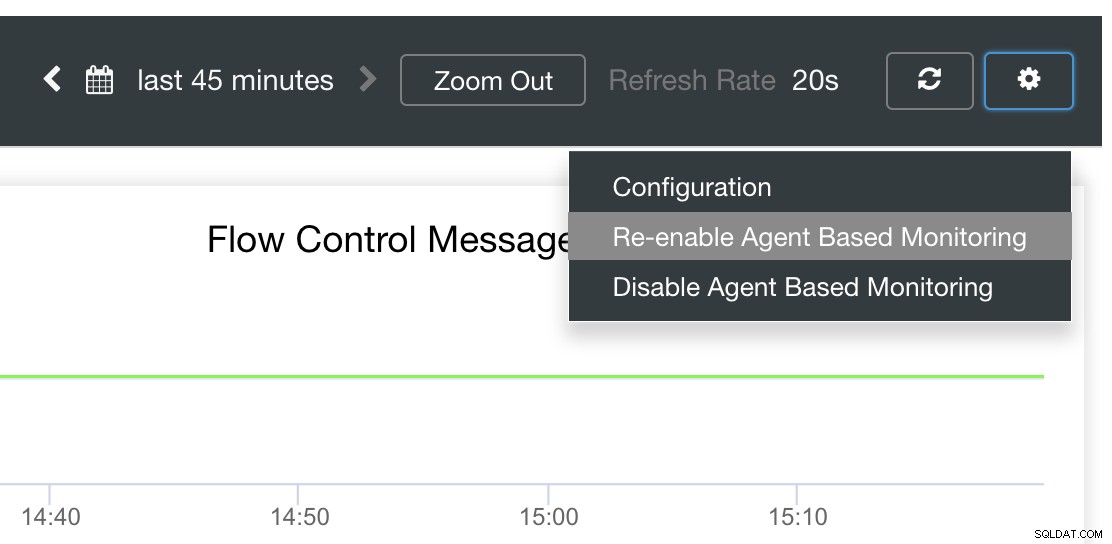
Infine, la domanda principale è:esiste un modo semplice per riavviare gli esportatori falliti? Sì! Abbiamo accennato in precedenza che ClusterControl controlla lo stato delle esportazioni e le riavvia se necessario. Nel caso in cui noti che i dashboard SCUMM non caricano i grafici normalmente, assicurati di aver abilitato il ripristino automatico. Vedi l'immagine qui sotto:

Quando è abilitato, ciò garantirà che
È anche possibile reinstallare o riconfigurare gli esportatori.
Conclusione
In questo blog, abbiamo visto come ClusterControl utilizza Prometheus per offrire dashboard SCUMM. Fornisce un potente set di funzionalità, da dati di monitoraggio ad alta risoluzione e grafici ricchi. Hai appreso che con PromQL puoi determinare e risolvere i problemi dei nostri dashboard SCUMM che ti consentono di aggregare i dati delle serie temporali in tempo reale. Puoi anche generare grafici o visualizzare tramite Console tutte le metriche che sono state raccolte.
Hai anche imparato come eseguire il debug dei nostri dashboard SCUMM, soprattutto quando non vengono raccolti punti dati.
Se hai domande, aggiungi i tuoi commenti o faccelo sapere attraverso i nostri forum della community.